LinkedList 基本示例及源码解析
一、JavaDoc 简介
- LinkedList双向链表,实现了List的 双向队列接口,实现了所有list可选择性操作,允许存储任何元素(包括null值)
- 所有的操作都可以表现为双向性的,遍历的时候会从首部到尾部进行遍历,直到找到最近的元素位置
- 注意这个实现不是线程安全的, 如果多个线程并发访问链表,并且至少其中的一个线程修改了链表的结构,那么这个链表必须进行外部加锁。(结构化的操作指的是任何添加或者删除至少一个元素的操作,仅仅对已有元素的值进行修改不是结构化的操作)。
- List list = Collections.synchronizedList(new LinkedList(…)),可以用这种链表做同步访问,但是最好在创建的时间就这样做,避免意外的非同步对链表的访问
- 迭代器返回的iterators 和 listIterator方法会造成fail-fast机制:如果链表在生成迭代器之后被结构化的修改了,除了使用iterator独有的remove方法外,都会抛出并发修改的异常。因此,在面对并发修改的时候,这个迭代器能够快速失败,从而避免非确定性的问题
二、LinkedList 继承接口和实现类介绍
java.util.LinkedList 继承了 AbstractSequentialList 并实现了List , Deque , Cloneable 接口,以及Serializable 接口
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}
类之间的继承体系如下:
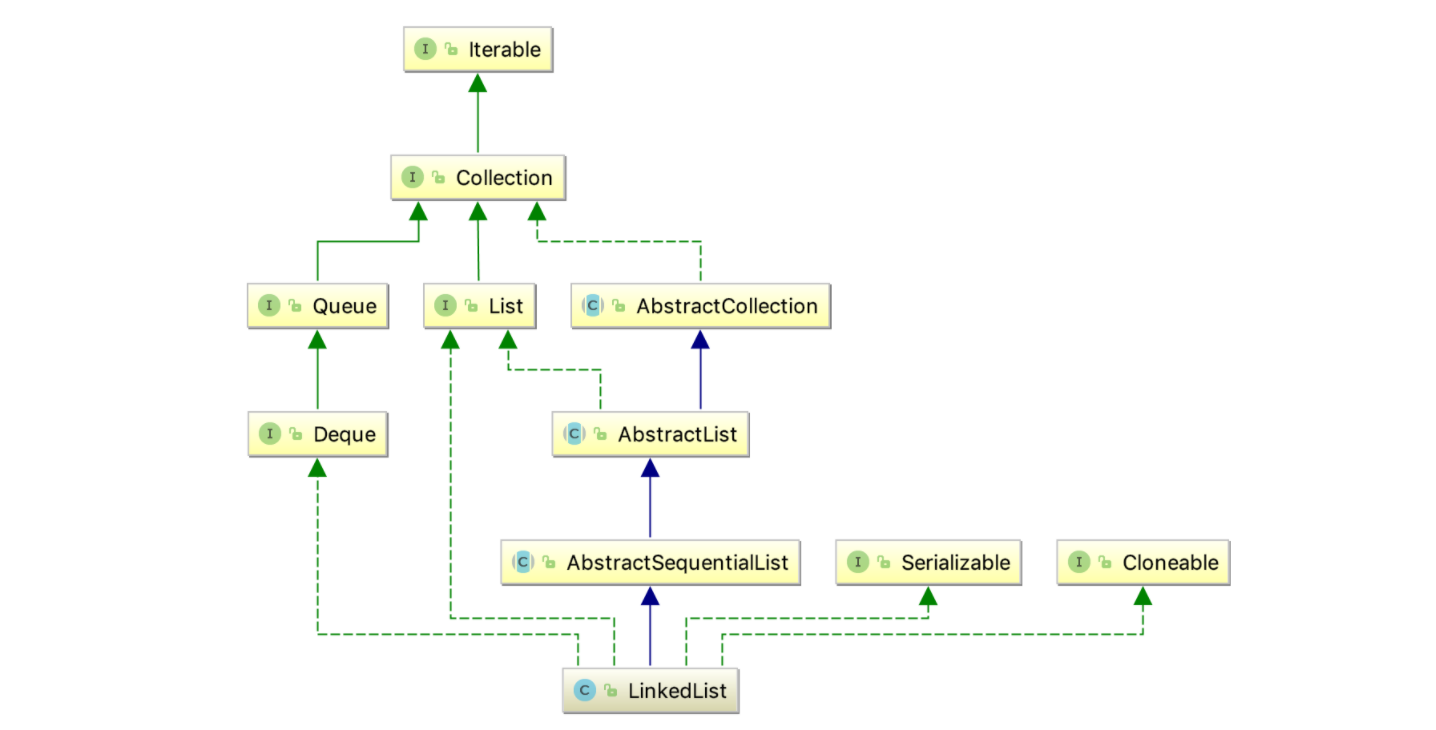
下面就对继承树中的部分节点进行大致介绍:
AbstractSequentialList 介绍:
这个接口是List一系列子类接口的核心接口,以求最大限度的减少实现此接口的工作量,由顺序访问数据存储(例如链接链表)支持。对于随机访问的数据(像是数组),AbstractList 应该优先被使用这个接口可以说是与AbstractList类相反的,它实现了随机访问方法,提供了get(int index),set(int index,E element), add(int index,E element) and remove(int index)方法对于程序员来说:
要实现一个列表,程序员只需要扩展这个类并且提供listIterator 和 size方法即可。
对于不可修改的列表来说, 程序员需要实现列表迭代器的 hasNext(), next(), hasPrevious(),
previous 和 index 方法
AbstractList 介绍:
这个接口也是List继承类层次的核心接口,以求最大限度的减少实现此接口的工作量,由顺序访问
数据存储(例如链接链表)支持。对于顺序访问的数据(像是链表),AbstractSequentialList 应该优先被使用,
如果需要实现不可修改的list,程序员需要扩展这个类,list需要实现get(int) 方法和List.size()方法
如果需要实现可修改的list,程序员必须额外重写set(int,Object) set(int,E)方法(否则会抛出
UnsupportedOperationException的异常),如果list是可变大小的,程序员必须额外重写add(int,Object) , add(int, E) and remove(int) 方法
AbstractCollection 介绍:
这个接口是Collection接口的一个核心实现,尽量减少实现此接口所需的工作量
为了实现不可修改的collection,程序员应该继承这个类并提供呢iterator和size 方法
为了实现可修改的collection,程序团需要额外重写类的add方法,iterator方法返回的Iterator迭代器也必须实现remove方法
三、LinkedList 基本方法介绍
上面看完了LinkedList 的继承体系之后,来看看LinkedList的基本方法说明
添加
add():
----> 1. add(E e) : 直接在'末尾'处添加元素
----> 2. add(int index,E element) : 在'指定索引处添'加元素
----> 3. addAll(Collections<? extends E> c) : 在'末尾'处添加一个collection集合
----> 4. addAll(int index,Collections<? extends E> c):在'指定位置'添加一个collection集合
----> 5. addFirst(E e): 在'头部'添加指定元素
----> 6. addLast(E e): 在'尾部'添加指定元素
offer():
----> 1. offer(E e): 在链表'末尾'添加元素
----> 2. offerFirst(E e): 在'链表头'添加指定元素
----> 3. offerLast(E e): 在'链表尾'添加指定元素
push(E e): 在'头部'压入元素
移除
poll():
----> 1. poll(): 访问并移除'首部'元素
----> 2. pollFirst(): 访问并移除'首部'元素
----> 3. pollLast(): 访问并移除'尾部'元素
pop(): 从列表代表的堆栈中弹出元素,从'头部'弹出
remove():
----> 1. remove(): 移除并返回'首部'元素
----> 2. remove(int index) : 移除'指定索引'处的元素
----> 3. remove(Object o): 移除指定元素
----> 4. removeFirst(): 移除并返回'第一个'元素
----> 5. removeFirstOccurrence(Object o): 从头到尾遍历,移除'第一次'出现的元素
----> 6. removeLast(): 移除并返回'最后一个'元素
----> 7. removeLastOccurrence(Object o): 从头到尾遍历,移除'最后一次'出现的元素
clear(): 清空所有元素
访问
peek():
----> 1. peek(): 只访问,不移除'首部'元素
----> 2. peekFirst(): 只访问,不移除'首部'元素,如果链表不包含任何元素,则返回null
----> 3. peekLast(): 只访问,不移除'尾部'元素,如果链表不包含任何元素,返回null
element(): 只访问,不移除'头部'元素
get():
----> 1. get(int index): 返回'指定索引'处的元素
----> 2. getFirst(): 返回'第一个'元素
----> 3. getLast(): 返回'最后一个'元素
indexOf(Object o): 检索某个元素'第一次'出现所在的位置
LastIndexOf(Object o): 检索某个元素'最后一次'出现的位置
其他
clone() : 返回一个链表的拷贝,返回值为Object 类型
contains(Object o): 判断链表是否包含某个元素
descendingIterator(): 返回一个迭代器,里面的元素是倒叙返回的
listIterator(int index) : 在指定索引处创建一个'双向遍历迭代器'
set(int index, E element): 替换某个位置处的元素
size() : 返回链表的长度
spliterator(): 创建一个后期绑定并快速失败的元素
toArray(): 将链表转变为数组返回
四、LinkedList 基本方法使用
学以致用,熟悉了上面基本方法之后,来简单做一个demo测试一下上面的方法:
/**
* 此方法描述
* LinedList 集合的基本使用
*/
public class LinkedListTest {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("111");
list.add("222");
list.add("333");
list.add(1,"123");
// 分别在头部和尾部添加元素
list.addFirst("top");
list.addLast("bottom");
System.out.println(list);
// 数组克隆
Object listClone = list.clone();
System.out.println(listClone);
// 创建一个首尾互换的迭代器
Iterator<String> it = list.descendingIterator();
while (it.hasNext()){
System.out.print(it.next() + " ");
}
System.out.println();
list.clear();
System.out.println("list.contains('111') ? " + list.contains("111"));
Collection<String> collec = Arrays.asList("123","213","321");
list.addAll(collec);
System.out.println(list);
System.out.println("list.element = " + list.element());
System.out.println("list.get(2) = " + list.get(2));
System.out.println("list.getFirst() = " + list.getFirst());
System.out.println("list.getLast() = " + list.getLast());
// 检索指定元素出现的位置
System.out.println("list.indexOf(213) = " + list.indexOf("213"));
list.add("123");
System.out.println("list.lastIndexOf(123) = " + list.lastIndexOf("123"));
// 在首部和尾部添加元素
list.offerFirst("first");
list.offerLast("999");
System.out.println("list = " + list);
list.offer("last");
// 只访问,不移除指定元素
System.out.println("list.peek() = " + list.peek());
System.out.println("list.peekFirst() = " + list.peekFirst());
System.out.println("list.peekLast() = " + list.peekLast());
// 访问并移除元素
System.out.println("list.poll() = " + list.poll());
System.out.println("list.pollFirst() = " + list.pollFirst());
System.out.println("list.pollLast() = " + list.pollLast());
System.out.println("list = " + list);
// 从首部弹出元素
list.pop();
// 压入元素
list.push("123");
System.out.println("list.size() = " + list.size());
System.out.println("list = " + list);
// remove操作
System.out.println(list.remove());
System.out.println(list.remove(1));
System.out.println(list.remove("999"));
System.out.println(list.removeFirst());
System.out.println("list = " + list);
list.addAll(collec);
list.addFirst("123");
list.addLast("123");
System.out.println("list = " + list);
list.removeFirstOccurrence("123");
list.removeLastOccurrence("123");
list.removeLast();
System.out.println("list = " + list);
list.addFirst("top");
list.addLast("bottom");
list.set(2,"321");
System.out.println("list = " + list);
System.out.println("--------------------------");
// 创建一个list的双向链表
ListIterator<String> listIterator = list.listIterator();
while(listIterator.hasNext()){
// 移到list的末端
System.out.println(listIterator.next());
}
System.out.println("--------------------------");
while (listIterator.hasPrevious()){
// 移到list的首端
System.out.println(listIterator.previous());
}
}
}
Console:
-------1------- [top, 111, 123, 222, 333, bottom]
-------2-------[top, 111, 123, 222, 333, bottom]
bottom 333 222 123 111 top
list.contains('111') ? false
[123, 213, 321]
list.element = 123
list.get(2) = 321
list.getFirst() = 123
list.getLast() = 321
list.indexOf(213) = 1
list.lastIndexOf(123) = 3
-------4------- [first, 123, 213, 321, 123, 999]
list.peek() = first
list.peekFirst() = first
list.peekLast() = last
list.poll() = first
list.pollFirst() = 123
list.pollLast() = last
-------5------- [213, 321, 123, 999]
list.size() = 4
-------6------- [123, 321, 123, 999]
123
123
true
321
-------7------- []
-------8------- [123, 123, 213, 321, 123]
list = [123, 213]
-------9------- [top, 123, 321, bottom]
--------------------------
top
123
321
bottom
--------------------------
bottom
321
123
top
五、LinkedList 内部结构以及基本元素声明
- LinkedList内部结构是一个双向链表,具体示意图如下
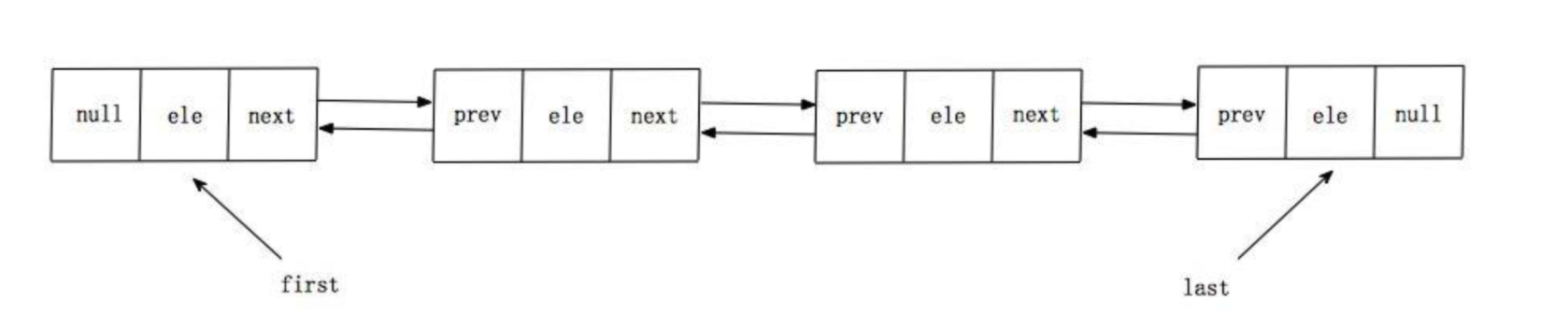
每一个链表都是一个Node节点,由三个元素组成
private static class Node<E> {
// Node节点的元素
E item;
// 指向下一个元素
Node<E> next;
// 指向上一个元素
Node<E> prev;
// 节点构造函数
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
first 节点也是头节点, last节点也是尾节点
- LinkedList 中有三个元素,分别是
transient int size = 0; // 链表的容量
transient Node<E> first; // 指向第一个节点
transient Node<E> last; // 指向最后一个节点
- LinkedList 有两个构造函数,一个是空构造函数,不添加任何元素,一种是创建的时候就接收一个Collection集合。
/**
* 空构造函数
*/
public LinkedList() {}
/**
* 创建一个包含指定元素的构造函数
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
六、LinkedList 具体源码分析
前言: 此源码是作者根据上面的代码示例一步一步跟进去的,如果有哪些疑问或者讲的不正确的地方,请与作者联系。
添加
添加的具体流程示意图:
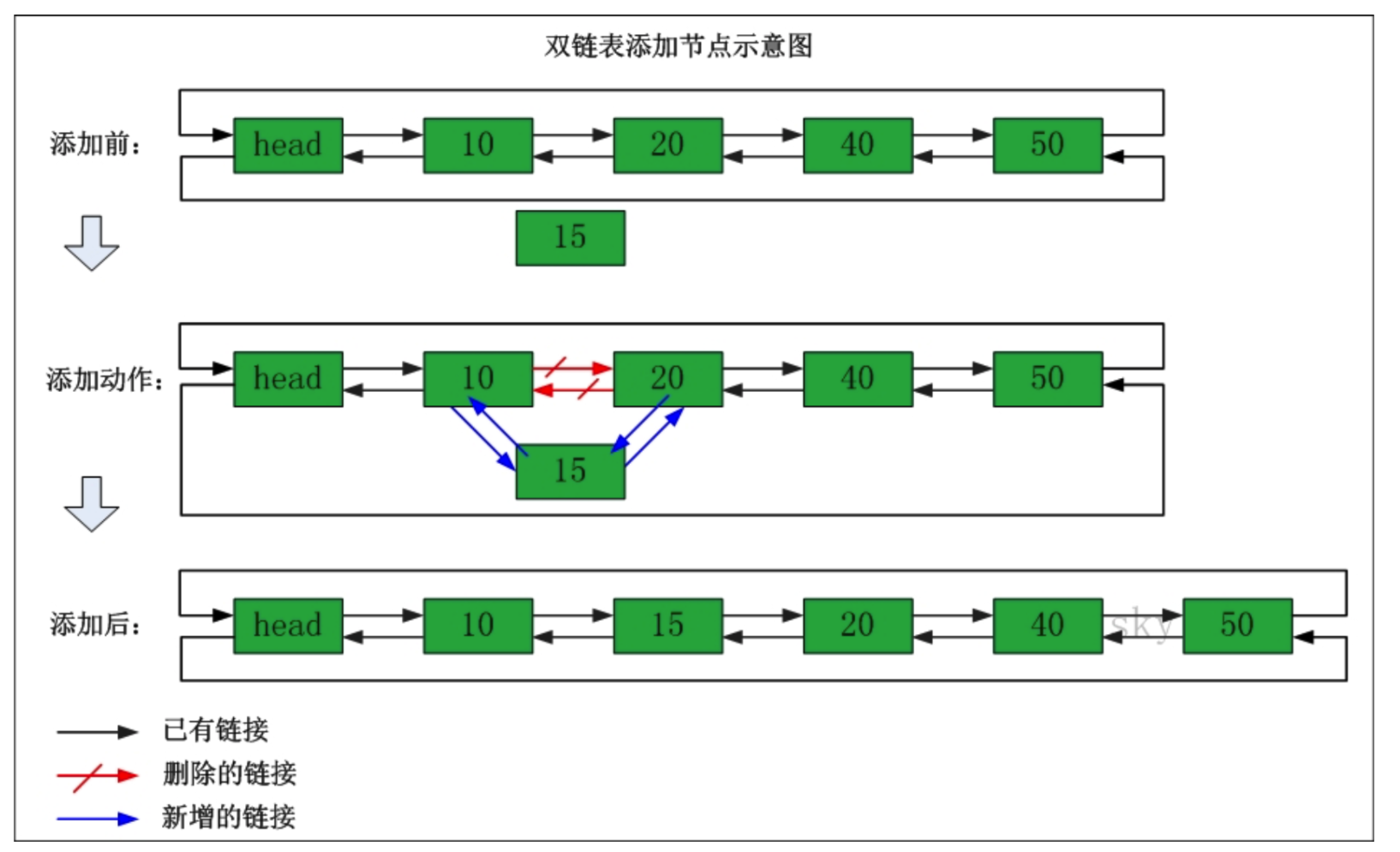
包括方法有:
add(E e)
add(int index, E element)
addAll(Collection<? extends E> c)
addAll(int index, Collection<? extends E> c)
addFirst(E e)
addLast(E e)
offer(E e)
offerFirst(E e)
offerLast(E e)
下面对这些方法逐个分析其源码:
**add(E e) : **
// 添加指定元素至list末尾
public boolean add(E e) {
linkLast(e);
return true;
}
// 真正添加节点的操作
void linkLast(E e) {
final Node<E> l = last;
// 生成一个Node节点
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
// 如果l = null,代表的是第一个节点,所以这个节点即是头节点
// 又是尾节点
if (l == null)
first = newNode;
else
// 如果不是的话,那么就让该节点的next 指向新的节点
l.next = newNode;
size++;
modCount++;
}
- **比如第一次添加的是111,此时链表中还没有节点,所以此时的尾节点last 为null, 生成新的节点,所以 此时的尾节点也就是111,所以这个 111 也是头节点,再进行扩容,修改次数对应增加 **
- **第二次添加的是 222, 此时链表中已经有了一个节点,新添加的节点会添加到尾部,刚刚添加的111 就当作头节点来使用,222被添加到111的节点后面。 **
**add(int index,E e) : **
/**
*在指定位置插入指定的元素
*/
public void add(int index, E element) {
// 下标检查
checkPositionIndex(index);
if (index == size)
// 如果需要插入的位置和链表的长度相同,就在链表的最后添加
linkLast(element);
else
// 否则就链接在此位置的前面
linkBefore(element, node(index));
}
// 越界检查
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 判断参数是否是有效位置(对于迭代或者添加操作来说)
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
// linkLast 上面已经介绍过
// 查找索引所在的节点
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 在非空节点插入元素
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// succ 即是插入位置的节点
// 查找该位置处的前面一个节点
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
- 例如在位置为1处添加值为123 的元素,首先对下标进行越界检查,判断这个位置是否等于链表的长度,如果与链表长度相同,就往最后插入,如果不同的话,就在索引的前面插入。
- 下标为1 处并不等于索引的长度,所以在索引前面插入,首先对查找 1 这个位置的节点是哪个,并获取这个节点的前面一个节点,在判断这个位置的前一个节点是否为null,如果是null,那么这个此处位置的元素就被当作头节点,如果不是的话,头节点的next 节点就指向123
addFirst(E e) :
// 在头节点插入元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
// 先找到first 节点
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
// f 为null,也就代表着没有头节点
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
例如要添加top 元素至链表的首部,需要先找到first节点,如果first节点为null,也就说明没有头节点,如果不为null,则头节点的prev节点是新插入的节点。
**addLast(E e) : **
public void addLast(E e) {
linkLast(e);
}
// 链接末尾处的节点
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
方法逻辑与在头节点插入基本相同
**addAll(Collections<? extends E> c) : **
/**
* 在链表中批量添加数据
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
// 越界检查
checkPositionIndex(index);
// 把集合转换为数组
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
// 直接在末尾添加,所以index = size
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
// 遍历每个数组
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
// 先对应生成节点,再进行节点的链接
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
Collection<String> collec = Arrays.asList("123","213","321");
list.addAll(collec);
- 例如要插入一个Collection为123,213,321 的集合,没有指定插入元素的位置,默认是向链表的尾部进行链接,首先会进行数组越界检查,然后会把集合转换为数组,在判断数组的大小是否为0,为0返回,不为0,继续下面操作
- 因为是直接向链尾插入,所以index = size,然后遍历每个数组,首先生成对应的节点,在对节点进行链接,因为succ 是null,此时last 节点 = pred,这个时候的pred节点就是遍历数组完成后的最后一个节点
- 然后再扩容数组,增加修改次数
**addAll(Collections<? extends E> c) : ** 这个方法的源码同上
offer也是对元素进行添加操作,源码和add方法相同
offerFirst(E e)和addFirst(E e) 源码相同
offerLast(E e)和addLast(E e) 源码相同)
push(E e) 和addFirst(E e) 源码相同
取出元素
包括方法有:
- peek()
- peekFirst()
- peekLast()
- element()
- get(int index)
- getFirst()
- getLast()
- indexOf(Object o)
- lastIndexOf(Object o)
peek()
/**
* 只是访问,但是不移除链表的头元素
*/
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
peek() 源码比较简单,直接找到链表的第一个节点,判断是否为null,如果为null,返回null,否则返回链首的元素
peekFirst() : 源码和peek() 相同
peekLast():
/**
* 访问,但是不移除链表中的最后一个元素
* 或者返回null如果链表是空链表
*/
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
源码也比较好理解
element() :
/**
* 只是访问,但是不移除链表的第一个元素
*/
public E element() {
return getFirst();
}
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
与peek()相同的地方都是访问链表的第一个元素,不同是element元素在链表为null的时候会报空指针异常
****get**(int index) : **
/*
* 返回链表中指定位置的元素
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 返回指定索引下的元素的非空节点
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
get(int index)源码也是比较好理解,首先对下标进行越界检查,没有越界的话直接找到索引位置对应的node节点,进行返回
getFirst() :源码和element()相同
getLast(): 直接找到最后一个元素进行返回,和getFist几乎相同
indexOf(Object o) :
/*
* 返回第一次出现指定元素的位置,或者-1如果不包含指定元素。
*/
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
两种情况:
- 如果需要检索的元素是null,对元素链表进行遍历,返回x的元素为空的位置
- 如果需要检索的元素不是null,对元素的链表遍历,直到找到相同的元素,返回元素下标
**lastIndexOf(Object o) : **
/*
* 返回最后一次出现指定元素的位置,或者-1如果不包含指定元素。
*/
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
从IndexOf(Object o)源码反向理解
删除
删除节点的示意图如下:
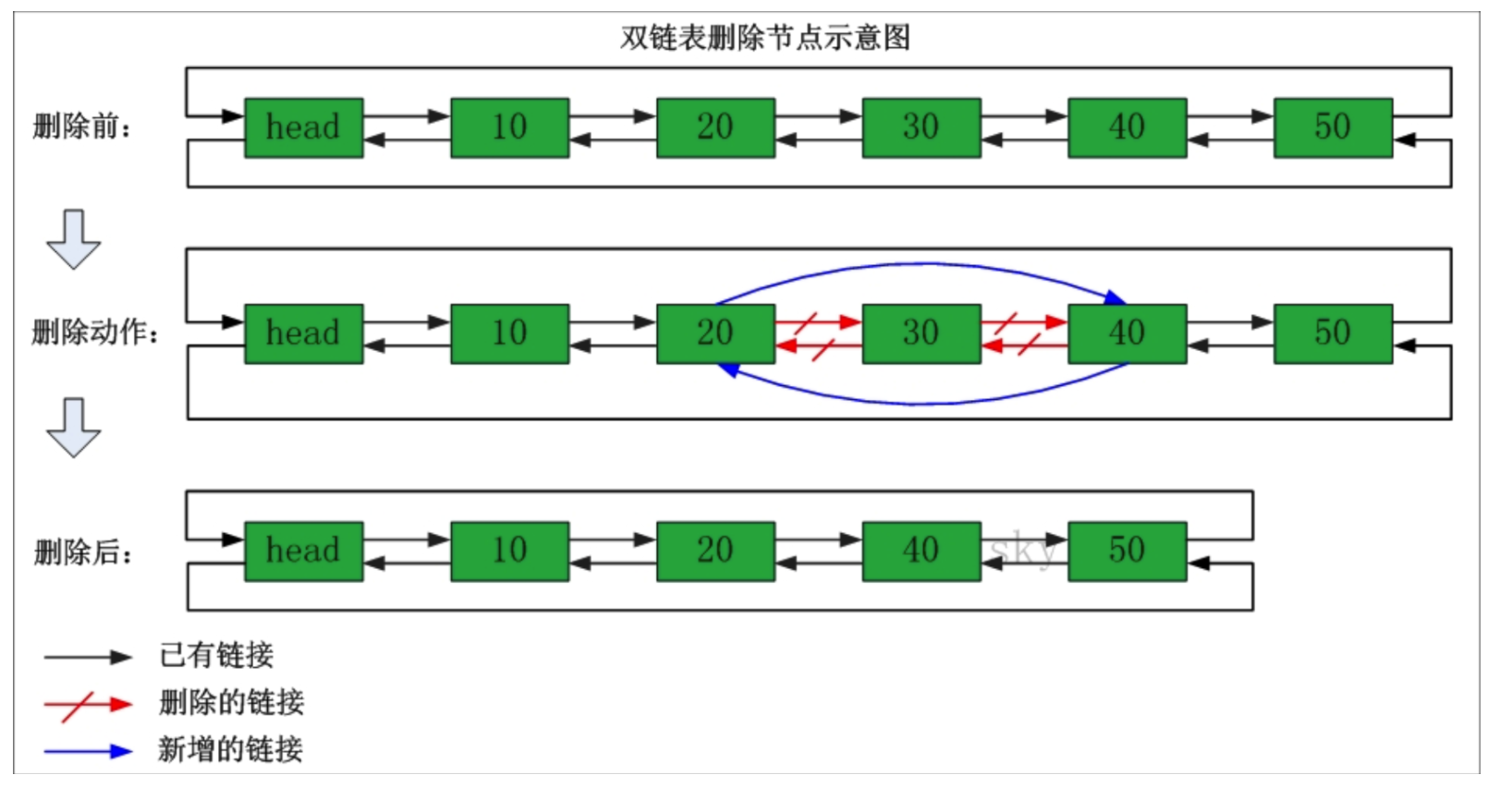
包括的方法有:
- poll()
- pollFirst()
- pollLast()
- pop()
- remove()
- remove(int index)
- remove(Object o)
- removeFirst()
- removeFirstOccurrence(Object o)
- removeLast()
- removeLastOccurrence(Object o)
- clear()
**poll() : **
/*
* 访问并移除链表中指定元素
*/
public E poll() {
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
// 断开第一个非空节点
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
poll()方法也比较简单直接,首先通过Node方法找到第一个链表头,然后把链表的元素和链表头指向的next元素置空,再把next节点的元素变为头节点的元素
pollFirst() : 与poll() 源码相同
pollLast(): 与poll() 源码很相似,不再解释
pop()
/*
* 弹出链表的指定元素,换句话说,移除并返回链表中第一个元素
*/
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
// unlinkFirst 源码上面
LinkedList 基本示例及源码解析的更多相关文章
- ArrayList、LinkedList和Vector的源码解析,带你走近List的世界
java.util.List接口是Java Collections Framework的一个重要组成部分,List接口的架构图如下: 本文将通过剖析List接口的三个实现类——ArrayList.Li ...
- Django 之 admin组件使用&源码解析
admin组件使用 Django 提供了基于 web 的管理工具. Django 自动管理工具是 django.contrib 的一部分.可以在项目的 settings.py 中的 INSTALLED ...
- [源码解析]PyTorch如何实现前向传播(2) --- 基础类(下)
[源码解析]PyTorch如何实现前向传播(2) --- 基础类(下) 目录 [源码解析]PyTorch如何实现前向传播(2) --- 基础类(下) 0x00 摘要 0x01 前文回顾 0x02 Te ...
- [源码解析] PyTorch如何实现前向传播(3) --- 具体实现
[源码解析] PyTorch如何实现前向传播(3) --- 具体实现 目录 [源码解析] PyTorch如何实现前向传播(3) --- 具体实现 0x00 摘要 0x01 计算图 1.1 图的相关类 ...
- [源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎
[源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎 目录 [源码解析] Pytorch 如何实现后向传播 (1)---- 调用引擎 0x00 摘要 0x01 前文回顾 1.1 训 ...
- [源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构
[源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构 目录 [源码解析] Pytorch 如何实现后向传播 (2)---- 引擎静态结构 0x00 摘要 0x01 Engine ...
- [源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑
[源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑 目录 [源码解析] Pytorch 如何实现后向传播 (3)---- 引擎动态逻辑 0x00 摘要 0x01 前文回顾 0 ...
- [源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法
[源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法 目录 [源码解析] PyTorch 如何实现后向传播 (4)---- 具体算法 0x00 摘要 0x01 工作线程主体 1.1 ...
- [源码解析] PyTorch 分布式(1)------历史和概述
[源码解析] PyTorch 分布式(1)------历史和概述 目录 [源码解析] PyTorch 分布式(1)------历史和概述 0x00 摘要 0x01 PyTorch分布式的历史 1.1 ...
随机推荐
- Docker Daemon 连接方式详解
前言 在 Docker 常用详解指令 一文中粗粗提了一下, Docker 是分为客户端和服务端两部分的, 本文将介绍客户端是如何连接服务端的. 连接方式 1. UNIX域套接字 默认就是这种方式, 会 ...
- [AGC06D] Median Pyramid Hard (玄学)
Description 现在有一个N层的方块金字塔,从最顶层到最底层分别标号为1...N. 第i层恰好有2i−1个方块,且每一层的中心都是对齐的. 这是一个N=4的方块金字塔 现在,我们首先在最底层填 ...
- 【转】CentOS 6.0 系统 LAMP(Apache+MySQL+PHP)安装步骤
一.安装 MySQL 首先来进行 MySQL 的安装.打开超级终端,输入: [root@localhost ~]# yum install mysql mysql-server 安装完毕,让 MySQ ...
- 转:C#制作ORM映射学习笔记二 配置类及Sql语句生成类
在正式开始实现ORM之前还有一点准备工作需要完成,第一是实现一个配置类,这个很简单的就是通过静态变量来保存数据库的一些连接信息,等同于.net项目中的web.config的功能:第二需要设计实现一个s ...
- hdu 2739(尺取法)
Sum of Consecutive Prime Numbers Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 22876 ...
- 无法启动Visual Studio的localhost web服务器,端口"xxxx"已被使用
解决方法:项目属性-Web里面有web服务器端口的设置,换个端口即可.项目属性->web->服务器,不要选择“自动分配端口”,选择“使用指定端口”,后面输入一个端口号
- A Wasserstein Distance[贪心/模拟]
链接:https://www.nowcoder.com/acm/contest/91/A来源:牛客网 最近对抗生成网络(GAN)很火,其中有一种变体WGAN,引入了一种新的距离来提高生成图片的质量.这 ...
- 安全性测试入门 (四):Session Hijacking 用户会话劫持的攻击和防御
本篇继续对于安全性测试话题,结合DVWA进行研习. Session Hijacking用户会话劫持 1. Session和Cookies 这篇严格来说是用户会话劫持诸多情况中的一种,通过会话标识规则来 ...
- JUC线程池深入刨析
JDK默认提供了四种线程池:SingleThreadExecutor.FiexdThreadPool.CachedThreadPool.ScheduledThreadPoolExecutor. 本文会 ...
- advanced-performance-troubleshooting-waits-latches-spinlocks
https://www.sqlskills.com/blogs/paul/advanced-performance-troubleshooting-waits-latches-spinlocks/