Redis实现之RDB持久化(一)
RDB持久化
Redis是一个键值对数据库服务器,服务器中通常包含着任意个非空数据库,而每个非空数据库中又可以包含任意个键值对,为了方便起见,我们将服务器中的非空数据库以及它们的键值对统称为数据库状态。举个栗子,图1-1展示了一个包含三个非空数据库的Redis服务器,这三个数据库以及数据库中的键值对就是该服务器的数据库状态
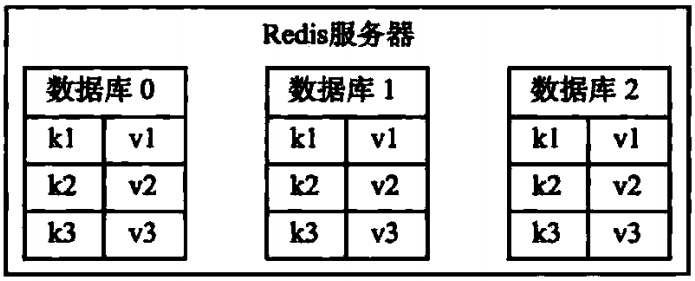
图1-1 数据库状态示例
因为Redis是内存数据库,它将自己的数据库状态存储在内存里面,所以如果不想办法将存储在内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器中的数据库状态也会消失。为了解决这个问题,Redis提供了RDB持久化功能,可以将Redis内存中的数据库状态保存到磁盘中,避免数据意外丢失
RDB持久化既可以手动执行,也可以根据服务器配置选项定期执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中,如图1-2所示
图1-2 将数据库状态保存为RDB文件
RDB持久化功能所生成的RDB文件是一个经压缩的二进制文件,通过该文件可以还原生成RDB文件时的数据库状态,如图1-3所示
图1-3 用RDB文件来还原数据库状态
因为RDB文件是保存在硬盘中的,所以即使Redis服务器进程退出,甚至运行Redis服务器的计算机停机,但只要RDB文件还在,Redis服务器就可以用它来还原数据库状态
RDB文件的创建和载入
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE。SAVE命令会阻塞Redis服务器,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求:
127.0.0.1:6379> SAVE #等待直到RDB文件创建完毕
OK
和SAVE命令直接阻塞服务器进程的做法不同,BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求:
127.0.0.1:6379> BGSAVE #派生子进程,并由子进程创建RDB文件
Background saving started
创建RDB文件的实际工作由rdb.c/rdbSave函数完成,SAVE命令和BGSAVE命令会以不同的方式调用这个函数,通过以下伪代码可以明显看出这两个命令之间的区别:
def SAVE():
#创建RDB文件
rdbSave() def BGSAVE():
#创建子进程
pid = fork()
if pid == 0:
#子进程负责创建RDB文件
rdbSave()
#完成之后向父进程发出信号
signal_parent()
elif pid > 0:
#父进程继续处理命令请求,并通过轮询等待子进程信号
handle_request_and_wait_signal()
else:
#处理出错情况
handle_fork_error()
和使用SAVE命令或者BGSAVE命令创建RDB文件不同,RDB文件的载入工作是在服务器启动时自动执行的,所以Redis并没有专门用于载入RDB文件的命令,只要Redis服务器在启动时检测到RDB文件的存在,它就会自动载入RDB文件
以下是Redis服务器启动时打印的日志记录其中第二条DB loaded from disk:……就是服务器成功载入RDB文件之后打印的:
17859:S 18 Aug 11:26:16.363 # Server started, Redis version 3.0.0
17859:S 18 Aug 11:26:56.802 * DB loaded from disk: 36.336 seconds
17859:S 18 Aug 11:26:56.802 * The server is now ready to accept connections on port 6379
另外值得一提的是,因为AOF文件的更新频率通常比RDB文件的更新频率高,所以:
- 如果服务器开启了AOF持久化功能,那么服务器就会优先使用AOF文件来还原数据库状态
- 只有在AOF持久化功能处于关闭状态时,服务器才会使用RDB文件来还原数据库状态
服务器判断该用哪个文件来还原数据库状态的流程如图1-4所示
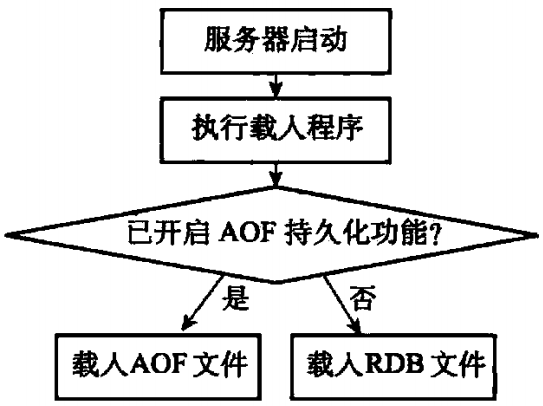
图1-4 服务器载入文件时的判断流程
载入RDB文件的实际工作由rdb.c/rdbLoad函数完成,这个函数和rdbSave函数之间的关系可以用图1-5表示
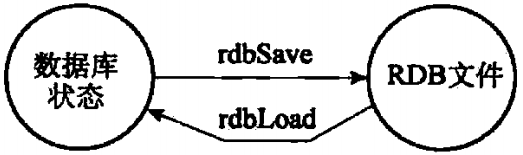
图1-5 创建和载入RDB文件
SAVE命令执行时的服务器状态
前面提到过,当SAVE命令执行时,Redis服务器会被阻塞,所以当SAVE命令正在执行时,客户端发送的所有命令请求都会被拒绝。只有在服务器完成SAVE命令、重新开始接受命令请求之后,客户端发送的命令才会被处理
BGSAVE命令执行时的服务器状态
因为BGSAVE命令的保存工作是由子进程执行的,所以在子进程创建RDB文件的过程中,Redis服务器仍然可以继续处理客户端的命令请求,但是,在BGSAVE命令执行期间,服务器处理SAVE、BGSAVE、BGREWRITEAOF三个命令的方式会和平时有所不同
首先,在BGSAVE命令执行期间,客户端发送的BGSAVE命令会被服务器拒绝,因为同时执行两个BGSAVE命令也会产生竞争条件。然后,BGREWRITEAOF和BGSAVE两个命令不能同时执行:
- 如果BGSAVE命令正在执行,那么客户端发送的BGREWRITEAOF命令会被延迟到BGSAVE命令执行完毕之后再执行
- 如果BGREWRITEAOF命令正在执行,那么客户端发送的BGSAVE命令会被服务器拒绝
因为BGSAVE和BGREWRITEAOF两个命令的实际工作都由子进程执行,所以这两个命令在操作方面并没有什么冲突的地方,不能同时执行它们只是一个性能方面的考虑——并发处两个子进程,并且两个子进程都同时执行大量的磁盘写入操作,对CPU是极大的消耗,要是数据库存储的键值对庞大,对内存的消耗想想都觉得恐怖
RDB文件载入时的服务器状态
服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止
自动间隔性保存
在上一节,我们介绍了SAVE命令和BGSAVE的实现方法,并且说明了这两个命令在实现方面的主要区别:SAVE命令由服务器进程执行保存工作,BGSAVE命令则由子进程执行保存工作,所以SAVE命令会阻塞服务器,而BGSAVE命令则不会
因为BGSAVE命令可以在不阻塞服务器的情况下执行,所以Redis允许用户通过没设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令。用户可以通过save选项设置多个保存条件,但只要其中一个条件被满足,服务器就会执行BGSAVE命令。举个栗子,如果我们向服务器提供以下配置:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行:
- 服务器在900秒内对数据库进行了至少一次的修改
- 服务器在300秒内对数据库进行了至少十次的修改
- 服务器在60秒内对数据库进行了至少一万次的修改
设置保存条件
当Redis启动时,用户可以通过指定配置文件或传入启动参数的方式设置save选项,如果用户没有主动设置save选项,那么服务器会为save选项设置默认条件:
save 900 1
save 300 10
save 60 10000
接着,服务器会根据save选项所设置的保存条件,设置服务器状态redisServer结构体的saveparams属性:
redis.h
struct redisServer {
……
//记录了保存条件的数组
struct saveparam *saveparams;
……
};
saveparams属性是一个数组,数组中每个元素都是一个saveparam结构体,每个saveparam结构体都保存了一个save选项设置的保存条件:
redis.h
struct saveparam {
//秒数
time_t seconds;
//修改数
int changes;
};
比如说,如果save选项的值为以下条件:
save 900 1
save 300 10
save 60 10000
那么服务器状态中的saveparams数组将会是图1-6所示的样子
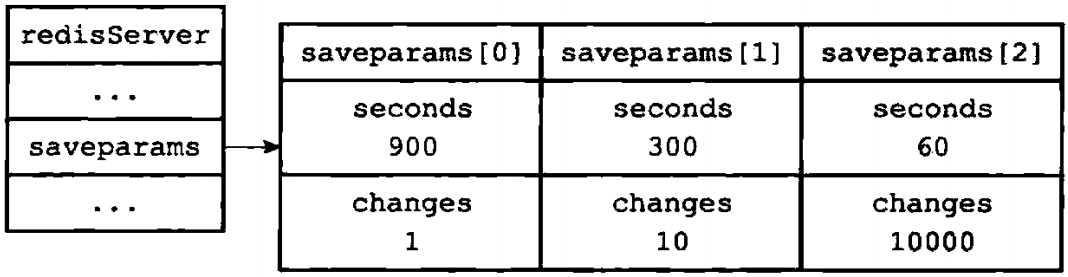
图1-6 服务器状态中的保存条件
dirty计数器和lastsave属性
除了saveparams数组之外,服务器状态还维持着一个dirty计数器,以及一个lastsave属性:
- dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)
- lastsave属性是一个Unix时间戳,记录了服务器上一次成功执行SAVE命令或BGSAVE命令的时间
redis.h
struct redisServer {
……
//修改计数器
long long dirty;
……
//上一次执行保存的时间
time_t lastsave;
……
};
当服务器成功执行一个数据库修改命令后,程序就会对dirty计数器进行更新:命令修改了多少次数据库,dirty计数器的值就会增加多少。例如,如果我们为一个字符串键设置值:
127.0.0.1:6379> SET message "hello"
OK
那么程序会将dirty计数器的值加1。又比如,如果我们向一个集合键增加三个元素:
127.0.0.1:6379> SADD database Redis MongoDB MariaDB
(integer) 3
那么程序会将dirty计数器的值加3
图1-7展示了服务器状态中包含的dirty计数器和lastsave属性,说明如下:
- dirty计数器的值为123,表示服务器在上次保存之后,对数据库状态共进行了123次修改
- lastsave属性则记录了服务器上次执行保存操作的时间1378270800(2013年9月4日零时)
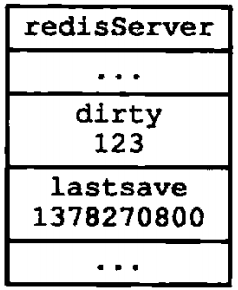
图1-7 服务器状态示例
检查保存条件是否满足
Redis的服务器周期性操作函数serverCron默认每隔100毫秒就会执行一次,该函数用于对正在运行的服务进行维护,它的其中一项工作就是检查save选项所设置的保存条件是否满足,如果满足,就执行BGSAVE命令
以下伪代码展示了serverCron函数检查保存条件的过程:
def serverCron():
# …
# 遍历所有保存条件
for saveparam in server.saveparams:
# 计算距离上次执行保存操作有多少秒
save_interval = unixtime_now()-server.lastsave # 如果数据库状态的修改次数超过条件所设置的次数
# 并且距离上次保存的时间超过条件所设置的时间
# 那么执行保存操作
if server.dirty >= saveparam.changes and \
save_interval > saveparam.seconds: BGSAVE();
# ...
程序会遍历并检查saveparams数组中的所有保存条件,只要有任意一个条件被满足时,那么服务器就会执行BGSAVE命令。举个栗子,如果Redis服务器的当前状态如图1-8所示
图1-8 服务器状态
那么当时间来到1378271101,也即是1378270800的301秒之后,服务器将自动执行一次BGSAVE命令,因为saveparams数组的第二个保存条件——300秒内有至少十次修改的条件已满足
假设BGSAVE在执行五秒后完成,那么图1-8所示的服务器状态将更新为图1-9所示,其中dirty计数器被重置为0,而lastsave属性也被更新为1378271106

图1-9 执行BGSAVE之后的服务器状态
以上就是Redis服务器根据save选项所设置的保存条件,自动执行BGSAVE命令,进行间隔性数据保存的实现原理
Redis实现之RDB持久化(一)的更多相关文章
- Redis实现之RDB持久化(二)
RDB文件结构 在Redis实现之RDB持久化(一)这一章中,我们介绍了Redis服务器保存和载入RDB文件的方法,在这一节,我们将对RDB文件本身进行介绍,并详细说明文件各个部分的结构和意义.图1- ...
- redis 笔记03 RDB 持久化、AOF持久化、事件、客户端
RDB 持久化 1. RDB文件用于保存和还原Redis服务器所有数据库中的所有键值对数据. 2. SAVE命令由服务器进程直接执行保存操作,所以该命令会阻塞服务器. 3. BGSAVE由子进程执行保 ...
- redis系列:RDB持久化与AOF持久化
前言 什么是持久化? 持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘).持久化的主要应用是将内存中的对象存储在数据库中,或者存储在磁盘文件中.XML数 ...
- Redis AOF、RDB持久化
持久化一:RDB方式 默认配置: save 900 1save 300 10save 60 10000 持久化二:AOF方式 默认配置:appendonly no,appendfilename &qu ...
- redis之RDB持久化与AOF持久化
Redis是一个键值对数据库服务器,服务器中通常包含着任意个非空数据库,而每个非空数据库中又可以包含任意个键值对,为了方便起见,我们将服务器中的非空数据库以及它们的键值对统称为数据库状态. 因为Red ...
- Redis学习笔记(八) RDB持久化
Redis是内存数据库,它将自己的数据库状态存储在内存里面,所以如果不想办法将存储在内存中的数据库状态保存到磁盘,那么服务器 进程一旦退出,服务器中的数据库状态也会消失不见. 为了解决这个问题,Red ...
- 第10章 RDB持久化
Redis是一种内存数据库,掉电即失,为了解决这个问题Redis提供了RDB持久化功能,该功能可以把Redis中的内容以RDB文件的形式存储在硬盘上,并且每次RedisServer启动的时候都会尝试从 ...
- Linux--6 redis订阅发布、持久化、集群cluster、nginx入门
一.redis发布订阅 Redis 通过 PUBLISH .SUBSCRIBE 等命令实现了订阅与发布模式. 其实从Pub/Sub的机制来看,它更像是一个广播系统,多个Subscriber可以订阅多个 ...
- redis命令总结与持久化
上篇redis文章为大家介绍了redis与它的部署工作.这次我们来说一下redis的操作命令与持久化 一.命令总结 1)String操作 6379> set k1 v1 #设定值 6379> ...
随机推荐
- 如何将js导入时的小红叉去掉
右键WebRoot-Myeclipse-Exclude From Validation
- vue-cli脚手架构建了项目如何去除Eslint验证(语法格式验证)
Eslint是一个语法检查工具,但是限制很严格,在vue文件里面很多空格都会导致红线,取消的方式如下: 1.创建工程的时候,提示是否启用eslint检测的. Use ESLint to lint yo ...
- 常用的CSS属性列表汇总
常用的CSS属性列表汇总 近期教学给学员总结常用的CSS属性,方便学习查询,正好发上来也给大家分享一下. 表格最右列的数字标识支持的CSS最低版本. 01. CSS背景属性(Background) 属 ...
- w3cschool中jQuery测试结果总结
1.jQuery 是 W3C 标准. 2.$("div#intro .head") 选择器选取:class="intro" 的任何 div 元素中的首个 id= ...
- Excel2Dataset
//获取用户打开的Excel文档路径 private stringkkk() { OpenFileDialog selectFile = new OpenFileDialog(); selectFil ...
- COGS 750. 栅格网络流
★★☆ 输入文件:flowa.in 输出文件:flowa.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述] Bob 觉得一般图的最大流问题太难了,他不知道如何解决 ...
- java Vamei快速教程21 事件响应
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 在GUI中,我们看到了如何用图形树来组织一个图形界面.然而,这样的图形界面是静态的 ...
- java Vamei快速教程09 类数据和类方法
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 我们一直是为了产生对象而定义类(class)的.对象是具有功能的实体,而类是对象的 ...
- 2018.5.24 Oracle下的sqlplus编程 块结构
1.语句结构模板 declare --声明 begin dbms_output.put_line('Legend Hello world'); end; 2.变量使用 & 是输入符号 decl ...
- IntelliJ IDEA中激活JRebel插件
1. 下载激活软件:https://github.com/ilanyu/ReverseProxy/releases/tag/v1.0 我下载的是 2. 双击文件运行 3. 点击change licen ...