Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码
题记:
11月14日早晨8点,人人网发布公告,宣布人人公司将人人网社交平台业务相关资产以2000万美元的现金加4000万美元的股票对价出售予北京多牛传媒,自此,人人公司将专注于境内的二手车业务和在美国的投资业务。
人人网CEO陈一舟说:“很高兴为人人网找到一个新的归宿和起点。”
然而对于人人网曾经近2亿的注册用户来说,哪有什么新的开始,故事已经到了尽头。
彼时,他们还是刚刚逃离高考噩梦的青涩大学生,抓住人人网这个宣泄口乐此不疲地表达着自我;现在,他们苦思冥想记忆中的账号密码,费力登上网站,发布最后一条状态:再见,人人。
还有更多的人登陆了人人网的手机客户端,结果发现连发布状态的按钮都找不到,一个明晃晃的“我要开播”,和首页上让人眼花缭乱的美女短视频,显示出在移动互联网时代,人人网早已从一个社交App,转型为短视频和直播应用。
他们只能压抑住心中的不舍,卸载了这个承载青春记忆的网站,转而去微博上说出那句告别的话语,和千千万的人一起来缅怀过往,“人人网被卖了”迅速站上热搜榜第一。
曾经活跃在人人上的那些青年们,如今都走入社会结婚生子,他们中的许多人,正是在人人上认识了自己的人生伴侣;而新的大学年轻人被琳琅满目的App牵着走,睁眼微信,早饭抖音,上课豆瓣,下课B站,午饭微博,晚饭头条,一个个分散在各自的小圈子里,十年前全国的青年汇聚在校内网上谈论星辰大海的场景,终究会消逝在一代人的记忆当中。
此次案例:
Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地
逆向思维来
以自己的人人网主页为例http://www.renren.com/23231****/profile,其中23231****是人人网给每个人分配的id号(用****隐去了后面四位)
因为需要使用账户名和密码,本程序使用了cookie登陆(每天需要更换cookie)
第一步:下载某个相册内的所有照片到本地
打开自己的某个相册,我的以http://photo.renren.com/photo/23231****/album-252396640/v7,为例。多开几个相册观察相册的连接可以发现,album-后面的字符串代表了相册的id
人人网存储了两种大小的照片,一种是缩略图,一种是点开某个照片显示的原图(当然不可能跟你拍的原图是一样大小的,为节省空间,上传的过程中系统会进行同比例的压缩处理),我们这个脚本下载较大尺寸的照片
按F12打开开发者工具,找到某个照片的连接,分别copy到浏览器看一下哪个是大尺寸的照片连接,可以看到标红的即为我们需要的
那么接下来就是使用python赶紧着把这些url获取到吧
but!
xpath爬出来是空,why?查询源代码后发现上一段代码是写在<script>标签内的
那么就用正则匹配试了下是ok哒
but!
抓取出来的url数量比相册内的照片数量少啊,看了几个相册发现,源代码中的url最多有40个,如果你的相册中照片数量大于40就会不全,心塞!
爬虫写的多了,到这里就知道应该去哪里找了,当然是动态加载文件啊
开发者工具切换到network页签选择XHR,然后刷新一下网页并滑动到相册最下面,可以看到左下侧出现了很多,点击红色框线内的随意一个文件,在右侧选中Headers看RequestURL

把这段字符串粘贴到浏览器中,发现显示是json数据
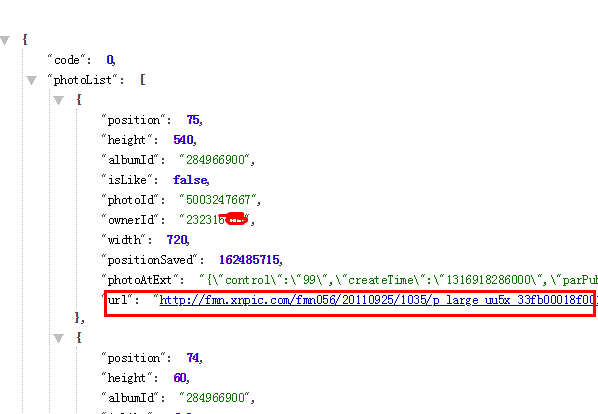
经测试可知,去掉&requestToken=-1989347373&_rtk=552df62d也可,并且前面的pageSize可以更改大小(最大是100)
遍历输出的时候需要注意:相册内数量、pageSize和page三者是有关联的
那么问题来了,我还需要获取到相册数量这个参数!
def download_photo(each_album_link,album_photoNumber,album_name,album_id,person):
"""
按照相册下载内部所有照片到同名文件夹
:param each_album_link:<str> 各个相册链接
:param album_photoNumber: <int> 每个相册内的照片数量
:param album_name: <str>相册名称,用来创建同名的文件夹
:param album_id:<str>相册id,用来创建同名文件夹
:param person: <str>所属人名字,用来创建一级文件夹名称
:return: none
"""
n = 0
while n < album_photoNumber:
#例如个人某个相册链接为http://photo.renren.com/photo/23231****/album-284966900/v7
#需要构建出来以下形式的相册网页(json格式)
# 'http://photo.renren.com/photo/23231****/album-284966900/bypage/ajax/v7?page=1&pageSize=100' ,经测试最多pageSize=100
link_para = 'bypage/ajax/v7?page={}&pageSize=100'.format(int((n/100)+1))
js_link = each_album_link.replace('v7',link_para)#构建相册网页(json格式)
print(js_link) file_path = make_file(person,album_name,album_id)#调用函数make_file
#print(file_path) html_data = requests.get(js_link, headers=headers)
try:
json_data = html_data.json()['photoList']
for i in range(0,len(json_data)):
link = json_data[i]['url']#获取相册中每张照片的下载链接
#print(link)
if file_path is None:
return
else:
if os.path.exists(file_path +'/'+str(i+n+1)+'.jpg'):
pass
else:
with open(file_path +'/'+str(i+n+1)+'.jpg','wb') as f:
f.write(requests.get(link, headers=headers).content)
except:
print('访问受限,需要密码!') n = n + 100#根据Pagesize设置步长
第一步小结:
通过相册的id或者连接+相册内的照片数量共同构建json格式的相册链接,通过这个链接可以获取到照片的下载地址,通过write写入本地
注意一点,有的相册是需要访问密码的,虽说能获取相册的一些信息,但是没有json数据的
那么怎么获取各个相册的id或者连接和照片数量呢?请看第二步
第二步:获取每个相册的id、内含照片数量、相册名称等信息
在个人的“相册”下就能够获取这些信息,例如我的相册http://photo.renren.com/photo/23231***/albumlist/v7?offset=0&limit=40#或者http://photo.renren.com/photo/23231****/albumlist/v7均可访问
注意一下,页面右下角有个按钮“查看全部”
,一定要点击一下看看是否页面发生了变化。反正我的是变了,一些相册也展现了出来。这时在看下网页链接是否发生了变化
结果,多了“showAll=1#”
因此,这一步骤的个人相册网页可以直接变为:http://photo.renren.com/photo/24422****/albumlist/v7?showAll=1
跟步骤一一样,相册的一些信息也是写在<stript>标签内的,看网址中有个limit=40猜想应该也是限制了源代码中只有40个相册的信息
因为我的相册不够40个,因此无法获取动态加载的文件,索性就直接正则匹配吧
如果你的相册数量大于40,可以安装步骤一的思路来获取
def get_album_data(album_link):
"""
在个人相册链接的网页源代码中,正则匹配相册数量和所有相册的名称、id、相册内包含的照片数
:param album_link: <str> 个人相册链接,点开显示全部可看完整的相册展示,因此连接中需要写明showAll=1
例如http://photo.renren.com/photo/24422****/albumlist/v7?showAll=1
:return: <list> 相册名称、id、内含照片数以及相册数量和所属人名字
"""
html_data = requests.get(album_link, headers=headers)
album_name = re.findall('"albumName":"(.*?)"', html_data.text,re.S)
print('直接正则匹配出来的相册名称,不一定显示中文:',album_name)
album_id = re.findall('"albumId":"(.*?)"', html_data.text,re.S)
album_photoNumber = re.findall('"photoCount":(.*?),', html_data.text,re.S)
album_number = re.findall("albumCount': (.*?),",html_data.text,re.S)
person = re.findall('<title>人人网 - (.*?)的相册</title>',html_data.text,re.S)#人人网所属人
#print('各相册信息:',album_name,album_id,album_photoNumber,album_number,person)
return album_name,album_id,album_photoNumber,album_number,person
这里有个坑就是获取到album_name的字段,打印出来看有时候显示中文,有时候显示'\\u660e\\u660e\\u7684\\u5feb\\u4e50\\u751f\\u6d3b'这种鬼样子……
还有的时候本来相册的名字是“我的大学——朋友”,中间有个——,那么若是全部显示成Unicode形式倒也没问题,直接整体做个转换就行
but有时候直接显示出来我的大学\u2014\u2014朋友,这个坑我暂时还没想到怎么处理……
第二步小结:通过个人相册的连接打开,用正则匹配出每个相册的名称、id、内含照片数量、相册数量(包含照片数量为0的相册)和所属人
这一步只获取了各个相册的id,并没有直接返回相册的连接(这一步操作在主函数中进行)
那么怎么获取个人相册的连接呢?请看第三步
第三步:通过个人主页获取个人相册链接
这一步就很简单了,啥方法都行,别忘了后面加上'?showAll=1'才能显示全部相册
def get_album_link(user_link):
"""
通过个人主页正则匹配"个人相册"按钮链接
:param user_link: 个人主页网址,例如http://www.renren.com/24422****/profile
:return: <str>个人相册链接,例如http://photo.renren.com/photo/24422****/albumlist/v7?showAll=1
"""
html_data = requests.get(user_link, headers=headers)
#print(html_data.text)
album_link = re.findall('"(.*?)">相册', html_data.text)[0]+'?showAll=1'#获取个人相册的连接
print('个人相册链接:',album_link)
return album_link
第三步没啥可总结的,个人主页就手动找手动输入吧
第四步:创建文件夹
思路是手动提前建立《人人网相册》,然后在此文件夹下按照所属人姓名建立一级文件夹,在一级文件夹下按照文件夹名称同名建立文件夹保存照片
既然要建立文件夹并命名,就少不了命名方面的规范,我这里没有做严格的筛选,若无法新建则直接pass
因为读取的是第二步返回的相册名称,因此有同样的相册显示问题,我这里认为显示的是unicode形式,然后做了.encode("utf-8").decode("unicode_escape"),这样可以保证显示出来的是中文;
若读取出来的直接是中文,经过.encode("utf-8").decode("unicode_escape")后显示的是乱码(也能创建文件夹成功),此时重新运行直到显示的是unicode即可
这一步没有找到很好的解决方案
def make_file(person,album_name,album_id):
"""
创建一级文件夹(以个人名字为文件名称)和二级文件夹(以相册名称命名),若存在则不重复建立
若存在或者创建成功key=1并返回路径,否则key=0
对文件命名规范不做限制,若失败直接pass
注意事项:读出的相册名称有时候显示中文,有时候显示成unicode形式,有时候两者均有;album_id是为了区别人人网上有重名的文件夹
:param person: <str> 个人名字,用来生成个人名下的一级文件夹
:param album_name: <str> 相册名字,用来生成同名文件夹
:param album_id:<str>相册id,用来创建同名文件夹
:return:<str> 相册所在路径
""" file_path=''
album_name = album_name.encode("utf-8").decode("unicode_escape")
#按个人名字生成一级文件夹,成功创建或者已存在则key=1,否则key=0
if os.path.exists((os.getcwd() + '\人人网相册'+'/' + person)):
key = 1
else:
try:
os.mkdir(os.getcwd() + '\人人网相册'+'/' + person)
key = 1
except:
key = 0
print(key,'文件夹《' + person + '》创建失败,请查看命名方式!') #在一级文件夹下(以key=1进行判断)生成各个相册的文件夹
if key == 1:
file_path = os.getcwd() + '/人人网相册' + '/' + person + '/' + album_name+'_'+ album_id#加id是为了解决文件夹重名问题
if os.path.exists(file_path):
pass
else:
try:
os.mkdir(file_path)
except:
print(key, '文件夹《' + album_name +'_'+ album_id+'》创建失败,请查看命名方式!')
key = 0
if key == 1:
#print(file_path)
return file_path
else:
#print('文件夹创立失败,请排查错误!')
return None
第四步小结:
如果简单点来做的话,可以用个人id和相册的id作为文件夹名称,因为都是数字肯定不会出错,但是就是对于读者不太友好
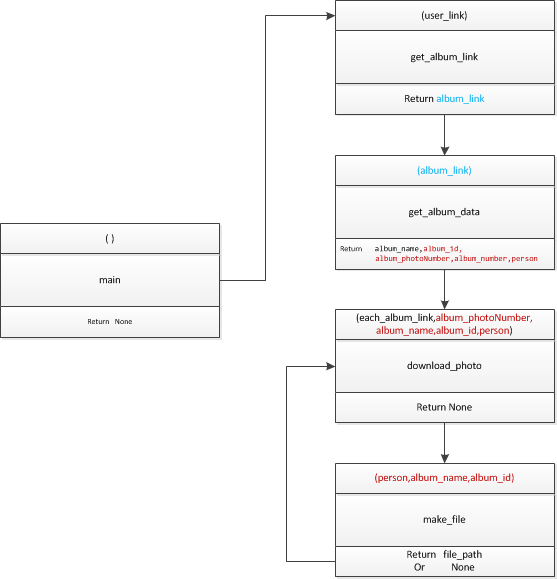
所有功能的函数都已调试好之后,需要主函数调用各个模块啦,为了方便理解,先画个图吧(画的不专业,意思意思)
if __name__=='__main__':
Host_url= 'http://www.renren.com/23231****/profile'#个人主页
Host_id = Host_url.split('/')[-2]
data = get_album_data(get_album_link(Host_url))
person = data[4][0]
#print(person)
album_number = int(data[3][0])#相册数量
for i in range(0,album_number):
each_album_link = 'http://photo.renren.com/photo/'+Host_id+'/album-' + data[1][i] + '/v7' # 构造各个相册链接,data[1][i]是相册id
#each_album_link = 'http://photo.renren.com/photo/24422****/album-' + data[1][i] + '/v7' #构造各个相册链接,data[1][i]是相册id
print(each_album_link)
album_name = data[0][i] #相册名称
album_photoNumber = int(data[2][i])
download_photo(each_album_link, album_photoNumber, album_name,data[1][i],person)
输出结果:

总结:
1. 如果登陆自己的账户,不仅可以爬下自己的照片,还可以爬其他人的
因为人人网是相对来说公开的,只有你能浏览到的就可以爬,如果有些人设置了好友可见(那么你如果作为非好友是看不到也爬不下来的)
2. 其实可以用打包软件生成可执行文件,这样小伙伴们就可以用自己的账号或者cookie下载自己的啦
3. 免登陆的方式有很多种,我这里使用的是cookie方式,每天都需要更改cookie,不太友好,以后会专门写一篇关于这种账号登陆的网站怎么爬取的文章吧
4. 其实每张照片都有评论的,评论也是可以有方法爬取的呦
5. 运行的时候,观察一下打印出来的相册名称,若是中文请重新运行直到是显示成\\u****的unicode形式
源代码:
'''
Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地
免登陆的方式有很多种,我这里使用的是cookie方式,每天都需要更改cookie
如果登陆自己的账户,不仅可以爬下自己的照片,还可以爬其他人的
因为人人网是相对来说公开的,只有你能浏览到的就可以爬,如果有些人设置了好友可见(那么你如果作为非好友是看不到也爬不下来的)
''' import requests,re,os headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'cookie':你的cookie,自行填写
} def download_photo(each_album_link,album_photoNumber,album_name,album_id,person):
"""
按照相册下载内部所有照片到同名文件夹
:param each_album_link:<str> 各个相册链接
:param album_photoNumber: <int> 每个相册内的照片数量
:param album_name: <str>相册名称,用来创建同名的文件夹
:param album_id:<str>相册id,用来创建同名文件夹
:param person: <str>所属人名字,用来创建一级文件夹名称
:return: none
"""
n = 0
while n < album_photoNumber:
#例如个人某个相册链接为http://photo.renren.com/photo/23231****/album-284966900/v7
#需要构建出来以下形式的相册网页(json格式)
# 'http://photo.renren.com/photo/23231****/album-284966900/bypage/ajax/v7?page=1&pageSize=100' ,经测试最多pageSize=100
link_para = 'bypage/ajax/v7?page={}&pageSize=100'.format(int((n/100)+1))
js_link = each_album_link.replace('v7',link_para)#构建相册网页(json格式)
print(js_link) file_path = make_file(person,album_name,album_id)#调用函数make_file
#print(file_path) html_data = requests.get(js_link, headers=headers)
try:
json_data = html_data.json()['photoList']
for i in range(0,len(json_data)):
link = json_data[i]['url']#获取相册中每张照片的下载链接
#print(link)
if file_path is None:
return
else:
if os.path.exists(file_path +'/'+str(i+n+1)+'.jpg'):
pass
else:
with open(file_path +'/'+str(i+n+1)+'.jpg','wb') as f:
f.write(requests.get(link, headers=headers).content)
except:
print('访问受限,需要密码!') n = n + 100#根据Pagesize设置步长 def get_album_data(album_link):
"""
在个人相册链接的网页源代码中,正则匹配相册数量和所有相册的名称、id、相册内包含的照片数
:param album_link: <str> 个人相册链接,点开显示全部可看完整的相册展示,因此连接中需要写明showAll=1
例如http://photo.renren.com/photo/24422****/albumlist/v7?showAll=1
:return: <list> 相册名称、id、内含照片数以及相册数量
"""
html_data = requests.get(album_link, headers=headers)
album_name = re.findall('"albumName":"(.*?)"', html_data.text,re.S)
print('直接正则匹配出来的相册名称,不一定显示中文:',album_name)
album_id = re.findall('"albumId":"(.*?)"', html_data.text,re.S)
album_photoNumber = re.findall('"photoCount":(.*?),', html_data.text,re.S)
album_number = re.findall("albumCount': (.*?),",html_data.text,re.S)
person = re.findall('<title>人人网 - (.*?)的相册</title>',html_data.text,re.S)#人人网所属人
print('各相册信息:',album_name,album_id,album_photoNumber,album_number,person)
return album_name,album_id,album_photoNumber,album_number,person def make_file(person,album_name,album_id):
"""
创建一级文件夹(以个人名字为文件名称)和二级文件夹(以相册名称命名),若存在则不重复建立
若存在或者创建成功key=1并返回路径,否则key=0
对文件命名规范不做限制,若失败直接pass
注意事项:读出的相册名称有时候显示中文,有时候显示成unicode形式,有时候两者均有;album_id是为了区别人人网上有重名的文件夹
:param person: <str> 个人名字,用来生成个人名下的一级文件夹
:param album_name: <str> 相册名字,用来生成同名文件夹
:param album_id:<str>相册id,用来创建同名文件夹
:return:<str> 相册所在路径
""" file_path=''
album_name = album_name.encode("utf-8").decode("unicode_escape")
#按个人名字生成一级文件夹,成功创建或者已存在则key=1,否则key=0
if os.path.exists((os.getcwd() + '\人人网相册'+'/' + person)):
key = 1
else:
try:
os.mkdir(os.getcwd() + '\人人网相册'+'/' + person)
key = 1
except:
key = 0
print(key,'文件夹《' + person + '》创建失败,请查看命名方式!') #在一级文件夹下(以key=1进行判断)生成各个相册的文件夹
if key == 1:
file_path = os.getcwd() + '/人人网相册' + '/' + person + '/' + album_name+'_'+ album_id#加id是为了解决文件夹重名问题
if os.path.exists(file_path):
pass
else:
try:
os.mkdir(file_path)
except:
print(key, '文件夹《' + album_name +'_'+ album_id+'》创建失败,请查看命名方式!')
key = 0
if key == 1:
#print(file_path)
return file_path
else:
#print('文件夹创立失败,请排查错误!')
return None def get_album_link(user_link):
"""
通过个人主页正则匹配"个人相册"按钮链接
:param user_link: 个人主页网址,例如http://www.renren.com/24422****/profile
:return: <str>个人相册链接,例如http://photo.renren.com/photo/24422****/albumlist/v7?showAll=1
"""
html_data = requests.get(user_link, headers=headers)
#print(html_data.text)
album_link = re.findall('"(.*?)">相册', html_data.text)[0]+'?showAll=1'#获取个人相册的连接
print('个人相册链接:',album_link)
return album_link if __name__=='__main__':
Host_url= 'http://www.renren.com/23231****/profile'#个人主页
Host_id = Host_url.split('/')[-2]
data = get_album_data(get_album_link(Host_url))
person = data[4][0]
#print(person)
album_number = int(data[3][0])#相册数量
for i in range(0,album_number):
each_album_link = 'http://photo.renren.com/photo/'+Host_id+'/album-' + data[1][i] + '/v7' # 构造各个相册链接,data[1][i]是相册id
#each_album_link = 'http://photo.renren.com/photo/24422****/album-' + data[1][i] + '/v7' #构造各个相册链接,data[1][i]是相册id
print(each_album_link)
album_name = data[0][i] #相册名称
album_photoNumber = int(data[2][i])
download_photo(each_album_link, album_photoNumber, album_name,data[1][i],person)
Python3爬取人人网(校内网)个人照片及朋友照片,并一键下载到本地~~~附源代码的更多相关文章
- python3通过Beautif和XPath分别爬取“小猪短租-北京”租房信息,并对比时间效率(附源代码)
爬虫思路分析: 1. 观察小猪短租(北京)的网页 首页:http://www.xiaozhu.com/?utm_source=baidu&utm_medium=cpc&utm_term ...
- Python爬取中国天气网
Python爬取中国天气网 基于requests库制作的爬虫. 使用方法:打开终端输入 “python3 weather.py 北京(或你所在的城市)" 程序正常运行需要在同文件夹下加入一个 ...
- Python爬虫训练:爬取酷燃网视频数据
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 项目目标 爬取酷燃网视频数据 https://krcom.cn/ 环境 Py ...
- python3爬取网页
爬虫 python3爬取网页资源方式(1.最简单: import'http://www.baidu.com/'print2.通过request import'http://www.baidu.com' ...
- 爬取西刺网的免费IP
在写爬虫时,经常需要切换IP,所以很有必要自已在数据维护库中维护一个IP池,这样,就可以在需用的时候随机切换IP,我的方法是爬取西刺网的免费IP,存入数据库中,然后在scrapy 工程中加入tools ...
- python3爬取女神图片,破解盗链问题
title: python3爬取女神图片,破解盗链问题 date: 2018-04-22 08:26:00 tags: [python3,美女,图片抓取,爬虫, 盗链] comments: true ...
- python爬虫基础应用----爬取校花网视频
一.爬虫简单介绍 爬虫是什么? 爬虫是首先使用模拟浏览器访问网站获取数据,然后通过解析过滤获得有价值的信息,最后保存到到自己库中的程序. 爬虫程序包括哪些模块? python中的爬虫程序主要包括,re ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
随机推荐
- Access 将SQL查询结果强制转换为某种类型
每个函数都可以强制将一个表达式转换成某种特定数据类型. 语法 CBool(expression) CByte(expression) CCur(expression) CDate(expression ...
- Solr7.x介绍安装和配置(单机版)
之前学的是4.x,然后一看官网,奶奶的都7.x了.于是查了一番资料..... 1)下载和安装 wget http://mirror.bit.edu.cn/apache/lucene/solr/7.3. ...
- HDU 5496——Beauty of Sequence——————【考虑局部】
Beauty of Sequence Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Other ...
- php 转码函数 你还在用iconv吗?-- 解决sqlserver插入中文失败问题
文章来源 :http://www.veryhuo.com/a/view/41348.html 这次给客户同步sqlserver数据,临时搭的 PHP Query Analyzer 插入某些中文一直有些 ...
- 学习笔记:SVG和Canvas
SVG SVG 与 Flash 类似,都是用于二维矢量图形,二者的区别在于,SVG 是一个 W3C 标准,基于 XML,是开放的.因为是 W3C 标准,SVG 与其他的 W3C 标准,比如 CSS.D ...
- 【迷你微信】基于MINA、Hibernate、Spring、Protobuf的即时聊天系统:5.技术简介之Hibernate
目录 序言 配置 hibernate.cfg.xml配置文件 加载hibernate.cfg.html配置文件并获取Session 对象的注解配置 增删改查 具体的增删改查代码 数据库操作的封装 连接 ...
- 报错:无法打开"cocos-ext.h" /添加第三方库
参考原文:http://lin-jianlong.diandian.com/post/2012-11-05/40042951271 1.项目属性->配置属性->C/C++->常规-& ...
- Centos内核调优参考
net.ipv4.tcp_syn_retries = 1 net.ipv4.tcp_synack_retries = 1 net.ipv4.tcp_keepalive_time = 600 net.i ...
- springMvc-reset风格和对静态资源的管理
1.所谓rest风格及比较优雅的,没有一大堆后缀的风格 2.对静态资源的管理,及样式.图片等不需要springMvc过滤 代码: 1.在springMvc的配置文件中添加mvc标签 <?xml ...
- 工作中碰到的css问题解决方法
好久都没来这写东西了,都长草了.刚解决的两个小问题,先记下来 textarea横向没有滚动条加上 wrap="off"这个属性 英文单词不断行加上这个 word-break:bre ...