python 斗图图片爬虫
捣鼓了三小时,有一些小Bug,望大佬指导
废话不说,直接上代码:
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
import os,re,requests
from urllib import request,parse class Doutu_api(object):
def __init__(self):
self.api_html = r'http://www.doutula.com/search?keyword=%s'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
self.path = os.path.dirname(os.path.realpath(__file__))+'\\temp' def make_path(self,path=''):#返回假为已创建,否则创建新文件夹
self.path = self.path+'\\'+path
if os.path.exists(self.path): # 判断文件夹是否存在
return False
else:
os.mkdir(self.path) # 创建文件夹
return True def get_img_html(self,html):
self.make_path(path=html)
html = self.api_html%parse.quote(html)
pattern = re.compile(u'<a.*?class="col-xs-6 col-md-2".*?href="(.*?)".*?style="padding:5px;">.*?</a>',re.S)
pattern_img = re.compile(u'<td>.*?<img.*?src="(.*?)".*?alt="(.*?)".*?onerror=".*?">.*?</td>',re.S)
try:
req = request.Request(html, headers=self.headers)
imgs = request.urlopen(req)
imgs = imgs.read().decode('utf-8')
imgs = re.findall(pattern, imgs)
for img in imgs:
req = request.Request(img, headers=self.headers)
imgurl = request.urlopen(req).read().decode('utf-8')
imgurl =re.findall(pattern_img, imgurl)
with open(self.path+'\\{}.png'.format(imgurl[0][1].replace('/','-')), 'wb') as file:
response = requests.get(imgurl[0][0]).content # 下载图片
file.write(response) # 读取图片
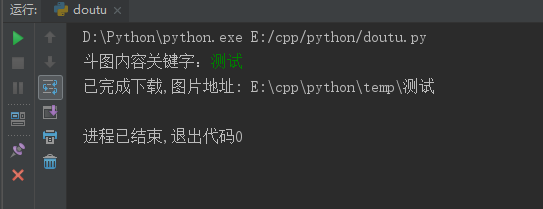
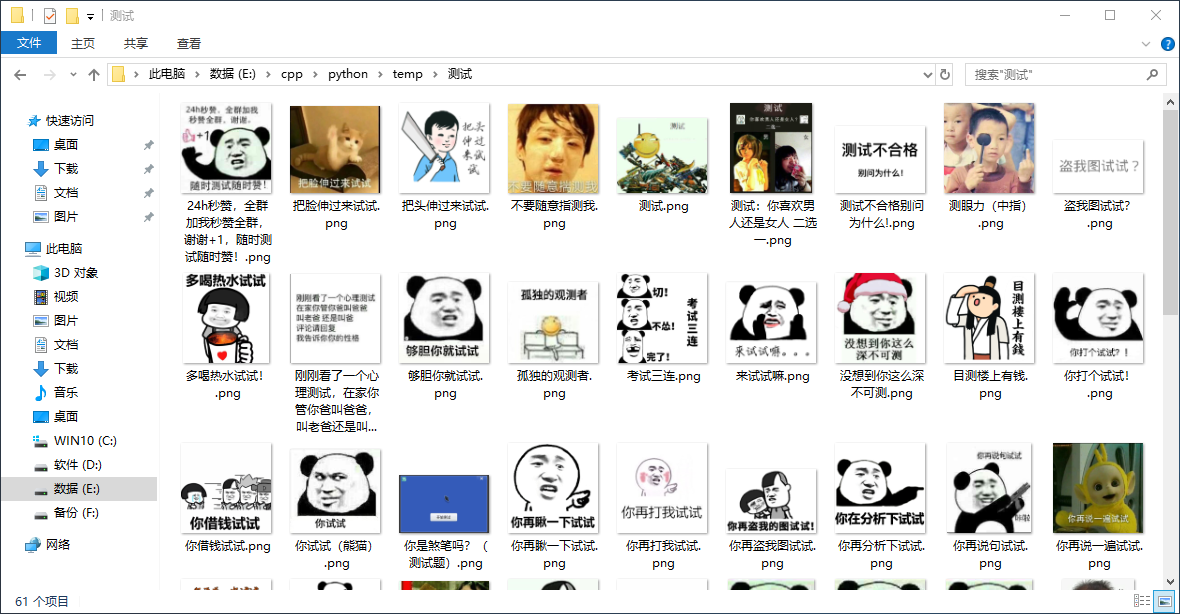
print('已完成下载,图片地址:',self.path)
except Exception as e:
print(e)
return None doutu = Doutu_api()
doutu.get_img_html(input('斗图内容关键字:'))
测试成功
python 斗图图片爬虫的更多相关文章
- py3+requests+urllib+bs4+threading,爬取斗图图片
实现原理及思路请参考我的另外几篇爬虫实践博客 py3+urllib+bs4+反爬,20+行代码教你爬取豆瓣妹子图:http://www.cnblogs.com/UncleYong/p/6892688. ...
- python+tkinter+动画图片+爬虫(查询天气)的GUI图形界面设计
1.完整代码: import time import urllib.request #发送网络请求,获取数据 import gzip #压缩和解压缩模块 import json #解析获得的数据 fr ...
- 【Python】:简单爬虫作业
使用Python编写的图片爬虫作业: #coding=utf-8 import urllib import re def getPage(url): #urllib.urlopen(url[, dat ...
- python多线程爬虫+批量下载斗图啦图片项目(关注、持续更新)
python多线程爬虫项目() 爬取目标:斗图啦(起始url:http://www.doutula.com/photo/list/?page=1) 爬取内容:斗图啦全网图片 使用工具:requests ...
- python爬虫我是斗图之王
python爬虫我是斗图之王 本文会以斗图啦网站为例,爬取所有表情包. 阅读之前需要对线程池.连接池.正则表达式稍作了解. 分析网站 页面url分析 打开斗图啦网站,简单翻阅之后发现最新表情每页包含的 ...
- Python爬虫入门教程 13-100 斗图啦表情包多线程爬取
斗图啦表情包多线程爬取-写在前面 今天在CSDN博客,发现好多人写爬虫都在爬取一个叫做斗图啦的网站,里面很多表情包,然后瞅了瞅,各种实现方式都有,今天我给你实现一个多线程版本的.关键技术点 aioht ...
- 【Python爬虫实战】 图片爬虫-淘宝图片爬虫--千图网图片爬虫
所谓图片爬虫,就是从互联网中自动把对方服务器上的图片爬下来的爬虫程序.有些图片是直接在html文件里面,有些是隐藏在JS文件中,在html文件中只需要我们分析源码就能得到如果是隐藏在JS文件中,那么就 ...
- python 爬虫系列09-异步斗图来一波
斗图斗图,妈妈再也不怕我都不赢了 import requests from lxml import etree from urllib import request import os import ...
- python多线程爬取斗图啦数据
python多线程爬取斗图啦网的表情数据 使用到的技术点 requests请求库 re 正则表达式 pyquery解析库,python实现的jquery threading 线程 queue 队列 ' ...
随机推荐
- (转)深入浅出linux系统umask值及其对应的文件权限讲解
浅出linux系统umask值及其对应的文件权限讲解 原文:http://blog.51cto.com/oldboy/1060032 缘起:1.此文的撰写特别为感谢51cto的博客工作人员和领导,老男 ...
- 四,JVM 自带工具之jvisualvm
http://www.ibm.com/developerworks/cn/java/j-lo-visualvm/index.html?ca=drs- https://visualvm.java.net ...
- DM设备的创建与管理
DM(Device Mapper)即设备映射(逻辑设备). MD和DM是Linux内核上2种工作机制(实现逻辑设备)不同的模块. Physical Volume(PV): 物理卷 底层 ...
- ElasticSearch 全文检索— ElasticSearch 安装部署
ElasticSearch 规划-集群规划 ElasticSearch 规划-集群规划 ElasticSearch 规划-用户规划 ElasticSearch 规划-目录规划 ElasticSearc ...
- pat1083. List Grades (25)
1083. List Grades (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Given a l ...
- zookeeper的简单搭建,java使用zk的例子和一些坑
一 整合 由于本人的码云太多太乱了,于是决定一个一个的整合到一个springboot项目里面. 附上自己的github项目地址 https://github.com/247292980/spring- ...
- 初识MAC(由window到mac的转变适应)
* Windows上的软件可以拿到Mac上面安装吗? Windows上面的软件不能拿到Mac的操作系统上安装,除此之外,Windows里的 exe文件,在Mac下面也是无法运行的,要特別注意.如果你要 ...
- HTTP原理及状态码汇总
什么是HTTP: HTTP(HyperText Transfer Protocol超文本传输协议)是互联网上应用最为广泛的一种网络协议.所有的WWW文件都必须遵守这个标准,为了提供一种发布和接收HTM ...
- 使用random函数实现randint函数的功能
首先说明一下 random函数是random模块中的一个函数 首先要导入random模块 import random random函数的功能 #生成某一范围(0-1)内的随机小数print(rando ...
- F5-WAF-12.0
平台: CentOS 类型: 虚拟机镜像 软件包: f5bigip basic software security waf 服务优惠价: 按服务商许可协议 云服务器费用:查看费用 立即部署 产品详情 ...