【原创】开发Kafka通用数据平台中间件
开发Kafka通用数据平台中间件
(含本次项目全部代码及资源)
目录:
一. Kafka概述
二. Kafka启动命令
三.我们为什么使用Kafka
四. Kafka数据平台中间件设计及代码解析
五.未来Kafka开发任务
一. Kafka概述
Kafka是Linkedin于2010年12月份创建的开源消息系统,它主要用于处理活跃的流式数据。活跃的流式数据在web网站应用中非常常见,这些活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。 这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计分析。
传统的日志分析系统是一种离线处理日志信息的方式,但若要进行实时处理,通常会有较大延迟。而现有的消息队列系统能够很好的处理实时或者近似实时的应用,但未处理的数据通常不会写到磁盘上,这对于Hadoop之类,间隔时间较长的离线应用而言,在数据安全上会出现问题。Kafka正是为了解决以上问题而设计的,它能够很好地进行离线和在线应用。
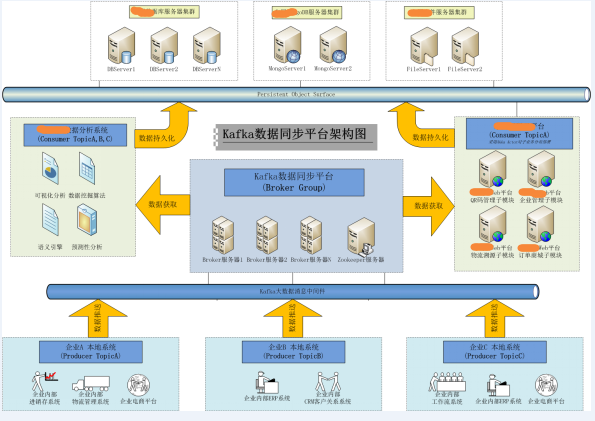
1.1 Kfka部署结构:
(图1)
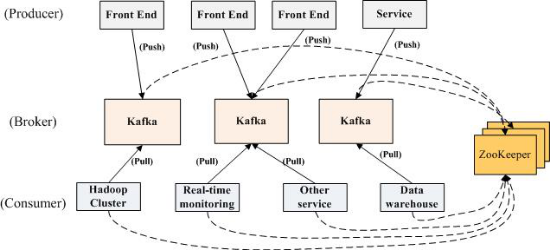
1.2 Kafka关键字:
•Broker : Kafka消息服务器,消息中心。一个Broker可以容纳多个Topic。
•Producer :消息生产者,就是向Kafka broker发消息的客户端。
•Consumer :消息消费者,向Kafka broker取消息的客户端。
•Zookeeper :管理Producer,Broker,Consumer的动态加入与离开。
•Topic :可以为各种消息划分为多个不同的主题,Topic就是主题名称。Producer可以针对某个主题进行生产,Consumer可以针对某个主题进行订阅。
•Consumer Group: Kafka采用广播的方式进行消息分发,而Consumer集群在消费某Topic时, Zookeeper会为该集群建立Offset消费偏移量,最新Consumer加入并消费该主题时,可以从最新的Offset点开始消费。
•Partition:Kafka采用对数据文件切片(Partition)的方式可以将一个Topic可以分布存储到多个Broker上,一个Topic可以分为多个Partition。在多个Consumer并发访问一个partition会有同步锁控制。
(图2)
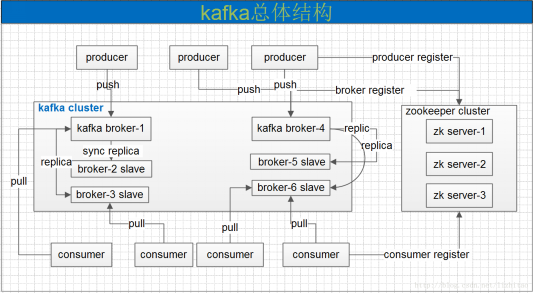
1.3 消息收发流程:
•启动Zookeeper及Broker.
•Producer连接Broker后,将消息发布到Broker中指定Topic上(可以指定Patition)。
•Broker集群接收到Producer发过来的消息后,将其持久化到硬盘,并将消息该保留指定时长(可配置),而不关注消息是否被消费。
•Consumer连接到Broker后,启动消息泵对Broker进行侦听,当有消息到来时,会触发消息泵循环获取消息,获取消息后Zookeeper将记录该Consumer的消息Offset。
1.4 Kafka特性:
•高吞吐量
•负载均衡:通过zookeeper对Producer,Broker,Consumer的动态加入与离开进行管理。
•拉取系统:由于kafka broker会持久化数据,broker没有内存压力,因此,consumer非常适合采取pull的方式消费数据
•动态扩展:当需要增加broker结点时,新增的broker会向zookeeper注册,而producer及consumer会通过zookeeper感知这些变化,并及时作出调整。
•消息删除策略:数据文件将会根据broker中的配置要求,保留一定的时间之后删除。kafka通过这种简单的手段,来释放磁盘空间。
二. Kafka启动命令:
启动Zookeeper服务:
zookeeper-server-start.bat ../../config/zookeeper.properties
启动Broker服务:
kafka-server-start.bat ../../config/server.properties
通过Zookeeper的协调在Broker中创建一个Topic(主题)
kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic
查询当前Broker中某个指定主题的配置信息
kafka-run-class.bat kafka.admin.TopicCommand --describe --zookeeper localhost:2181 --topic testTopic
启动一个数据生产者Producer
kafka-console-producer.bat --broker-list localhost:9092 --topic testTopic
启动一个数据消费者Consumer
kafka-console-consumer.bat --zookeeper localhost:2181 --topic testTopic --from-beginning
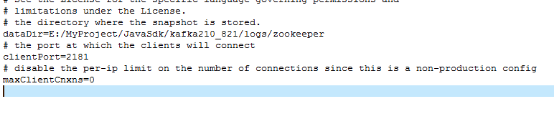
Zookeeper配置文件,zookeeper.properties配置片段
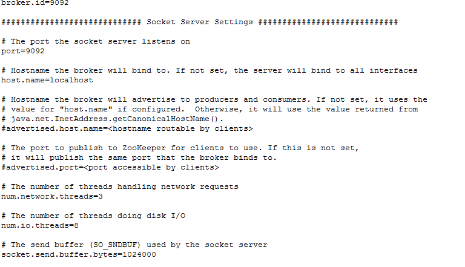
Broker配置文件,server.properties配置片段
关于kafka收发消息相关的配置项
1.在Broker Server中属性(这些属性需要在Server启动时加载):
//每次Broker Server能够接收的最大包大小,该参数要与consumer的fetch.message.max.bytes属性进行匹配使用
* message.max.bytes 1000000(默认)
//Broker Server中针对Producer发送方的数据缓冲区。Broker Server会利用该缓冲区循环接收来至Producer的数据 包,缓冲区过小会导致对该数据包的分段数量增加,但不会影响数据包尺寸限制问题。
socket.send.buffer.bytes 100 * 1024(默认)
//Broker Server中针对Consumer接收方的数据缓冲区。意思同上。
socket.receive.buffer.bytes 100 * 1024(默认)
//Broker Server中针对每次请求最大的缓冲区尺寸,包括Prodcuer和Consumer双方。该值必须大于 message.max.bytes属性
* socket.request.max.bytes 100 * 1024 * 1024(默认)
2.在Consumer中的属性(这些属性需要在程序中配置Consumer时设置)
//Consumer用于接收来自Broker的数据缓冲区,意思同socket.send.buffer.bytes。
socket.receive.buffer.bytes 64 * 1024(默认)
//Consumer用于每次接收消息包的最大尺寸,该属性需要与Broker中的message.max.bytes属性配对使用
* fetch.message.max.bytes 1024 * 1024(默认)
3.在Producer中的属性(这些属性需要在程序中配置Consumer时设置)
//Producer用于发送数据缓冲区,意思同socket.send.buffer.bytes。
send.buffer.bytes 100 * 1024(默认)
三. 我们为什么使用Kafka
当前项目中,我们更希望从企业获得尽可能多的有价值数据。最直接获取大数据的方式是采用写应用直连目标企业数据库来获得数据。但这种方式在实际应用中,会由于企业担心开放本地数据库而导致的安全隐患很难实施。另外,这种方式会与企业本地数据库结构耦合度过高,会出现多家企业多个应用的情况,缺少统一的数据交互平台,导致后期维护困难。
3.1 Kafka在当前项目中问题:
当前案例,我们想把某企业的本地数据实时同步到数据中心中,之后对这些数据进行二次分析处理。我们的目标是建立统一的数据同步平台,便于在日后的多企业多系统中能有统一的实施标准,所以选用了Kafka消息系统作为支撑。
Producer(数据发送方)以独立线程方式常驻某企业内部应用中,依靠一定的时间周期,从本地数据库获得数据并推送至Broker中。而Consumer(快销组数据接收方)也是独立与WEB框架常驻内存,获得数据消息后保存至数据中心中。
但目前Kafka在实施中面临以下问题:
1.Producer/Consumer均独立于Web框架,Producer依靠消息片轮询检索/发送最新数据,执行效率低。
2.Producer会直接针对某企业内部数据库表结构操作,导致代码与企业业务耦合度过高,而无法平滑移植到其他企业系统中。
3.由于Producer/Consumer是独立于Web框架的,在外围负责数据的采集及推送,与Web项目主程序无切合度。
4.目前针对Kafka的数据传输异常处理比较简陋,当Broker或 Zookeeper等出现异常时,有可能会导致数据安全性问题。
3.2实现目标:
针对以上问题,我们要实现如下目标:
1.把Producer/Consumer的数据推送/获取的过程封装成Class或者Jar包的形式,供Java Web框架调用,从而形成与企业内部Web应用或计算中心数据分析Web应用融合一体。
2.数据的推送/获取只针对Java Object对象,不要针对数据库表结构,不能与企业特有数据耦合度过高,形成通用的数据接口。Producer需要对Object进行序列化,Consumer需要对序列化后的二进制信息进行反序列化重建Object返回给调用者。
3.消息的推送/获取的整个生命周期中,要把重要事件通知给外部调用者,比如:Broker,Zookeeper是否有异常,数据推送/获取是否成功,如果失败需要保留失败记录便于进行后期数据恢复等。(需要在中间件中建立回调机制通知调用者)
4.可对多企业多应用进行平滑移植,移植过程中尽可能保持整体Kafka数据平台结构的零修改。
四. Kafka数据平台中间件设计
4.1解决方案:
基于以上待完成目标,我们有了以下解决方案。
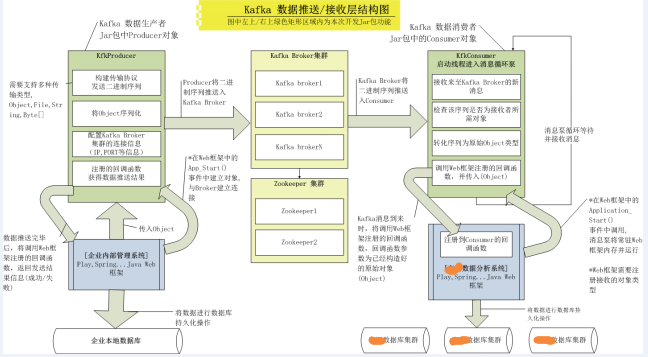
3.2 实现要点:
KfkProducer(数据生产者)
•KfkProducer对象需要在Web框架中的Application_OnStart()中启动,常驻进程,只与Broker连接一次,数据发送过程不能与Broker建立连接。(实践中发现Kafka的 Broker如果有异常,重启Broker后Producer不用再次连接即可发送)
•Web框架可以随时调用推送接口将对象(Object)推送至Broker.
•Object序列化后形成二进制信息,并且要保证在Consumer所处框架中能顺利还原.
•可发送多种对象(Object,File ,Byte[]等),简化外围框架针对待发送数据所做操作,简化调用接口。
•数据发送使用Kafka中最新的异步式数据发送API,不能由于发送时间过长或Broker异常等问题阻塞调用者。
•需要对整个发送生命期进行跟踪反馈异常信息,若发送失败,需要将待发送数据使用回调机制通知到框架调用者。
•详细测试Broker,或Zookeeper产生异常时,Producer可能会出现的情况。
•在针对多企业多应用中,可依靠Topic进行区分数据主题,这样可实现多应用部署时框架零修改问题。
KfkConsumer(数据消费者)
•KfkConsumer需要在计算中心内部Web框架中的Application_OnStart()中启动,常驻进程,只与Broker连接一次,并启动消息泵等待消息到来。(实践中发现Kafka的 Broker如果有异常,重启Broker后Consumer不用再次连接即可正常获取消息)
•需要定义回调接口,该回调接口由外围框架程序注册处理程序,当数据消息到来时,Consumer需要把数据发送至该接口,之后由调用者处理。
•调用者需要注册所接受的对象类型,因为Broker中同一Topic下会有各种数据对象(UserInfo,CompanyInfo,ProductInfo...)存在,所以必须提供接收对象的注册接口,以方便调用者有针对性的获取。
•数据到来时,要针对发送方序列化的二进制信息进行反序列化操作,并能准确还原成原始对象。
•需要对整个接收生命期进行跟踪反馈异常信息,若消息泵停止或异常,需要通知到框架调用者。
实现以上要点后,需要将KfkProducer及KfkConsumer对象打包成Jar包的形式,更灵活的部署到企业本地Web框架及计算中心内部Web框架中。
3.3 代码实现及分析:
3.3.1 KfkProducer 对象:数据生产者对象,封装了关于数据发送的相关功能。
|
接口函数/子对象 |
说明 |
|
KfkProducer () |
构造函数中需要调用者提供Broker集群的Ip,Port等信息。 Kafka支持Broker集群列表。(127.0.0.1:9092,127.0.0.1:9093) |
|
Connect() |
该函数需要完成对Broker集群的连接。 |
|
Send() |
该函数入口为Object对象,需要对该对象进行Serialize操作,根据待发送数据构造KfkMsg对象,并取得由KfkMsg序列化后的Byte[]数组,之后调用Kafka的异步发送方式及挂接回调处理函数。 要实现多个Send()接口,需要提供对Object,File ,Byte[]等多种数据类型的支持,方便调用者操作。 |
|
Close() |
该函数完成对Broker连接进行关闭。 |
|
SendCallback发送回调对象 onCompletion()发送回调接口 |
在kafka异步发送函数send()中注册,在收到Broker返回的发送是否成功信息后,会触发该函数,并调用ProducerEvent对象的onSendMsg()函数,向调用者发送成功与否结果。 成功则返回调用者RecordMetadata信息(BrokerServer中的数据offset,Partition位置ID,Topic主题) 失败者返回调用者原始数据信息,便于日后恢复。 |
|
ProducerEvent接口对象 onSendMsg() |
为调用者提供的回调接口,调用者在注册后,即可重写onSendMsg()函数,以便接到通知后,处理当前事件(发送数据成功与否)状态。 |
3.3.2 KfkConsumer对象:数据消费者对象,封装了关于数据接收的相关功能。
|
接口函数/子对象 |
说明 |
|
KfkConsumer() |
构造函数中需要调用者提供Zookeeper集群的Ip,Port等信息。(即将推出的Kafka0.9.X版本将支持直连Broker集群的机制) 该对象继承至Thread对象,为线程对象。 |
|
connect() |
配置Zookeeper连接相关属性,并连接Zookeeper服务器。 |
|
run() |
线程主函数,该函数将启动Kafka消息泵等待Broker的消息到来。 消息到来后,将调用KfkMsg对象对二进制序列化信息进行还原对象操作(KfkMsg将对序列化数据进行反序列化操作,并重新还原原始对象操作)。 对象还原后,将调用调用者注册的回调接口,将对象传出。 |
|
close() |
关闭Consumer与Broker,Zookeeper的Socket连接。 |
|
ConsumerEvent接收回调对象 onRecvMsg()接收回调函数 |
为调用者提供的回调接口,调用者在注册后,即可重写onRecvMsg()函数,以便接到通知后,收取对象或处理当前事件。 |
3.3.3 KfkMsg对象:数据消息对象,封装了数据对象的序列化/反序列化操作,构造多种类型的发送对象,封装发送协议等操作。
|
接口函数/子对象 |
说明 |
|
MsgBase对象 |
消息包基类,可以在Consumer接到数据消息后,形成多种对象的反序列化多态性。 |
|
MsgObject对象 serializeMsg()序列化函数 deserializeMsg()反序列化函数 |
针对Object数据的序列化和反序列化操作,及消息体封装,通讯协议构造等操作。 |
|
MsgByteArr对象 serializeMsg()序列化函数 deserializeMsg()反序列化函数 |
针对Byte[]数据的序列化和反序列化操作,及消息体封装,通讯协议构造等操作。 |
|
MsgFile对象 serializeMsg()序列化函数 deserializeMsg()反序列化函数 |
针对二进制文件的序列化和反序列化操作,及消息体封装,通讯协议构造等操作。 |
|
getMsgType()函数 |
负责对Consumer接收的序列化信息进行首次协议解析,判断对象类型(Object,File,byte[])之后构造对应的MsgXXX对象,以便使调用者进行反序列化多态功能。 |
3.3.4 SerializeUtils对象:序列化操作工具类,完成在Jar包内部对外部对象的序列化/反序列化基础从操作。
|
接口函数/子对象 |
说明 |
|
deserialize()函数 |
将序列化后的二进制数组byte[]还原成原始Object. 由于如果使用默认的ObjectInputStream对象进行反序列化操作,在Jar内将无法找到外部调用者定义的对象名,也即无法反序列化成功,报无法找到外部对象的异常。 所以必须重写resolveClass()函数,加载当前线程范围内的Class上下文。 |
|
Serialize()函数 |
将Object序列化成二进制数组,byte[]。 |
3.3.5 调用者Web框架部署:
KfkProducer部署:
|
部署要点 |
说明 |
|
1.注册发送消息回调函数 |
在WEB框架中的Application_OnStart()事件中向Jar注册发送消息回调函数。并重写onSendMsg()回调接口,用于接受发送成功/失败消息,发送失败后,可以在Web框架中针对返回的原始数据信息做备份/恢复处理。 |
|
2.建立与Broker之间的连接 |
在WEB框架中的 Application_OnStart()事件中调用KfkProducer connect()函数,连接远程Broker。 |
|
3.将KfkProducer传入框架 |
经过前两步操作后,我们已经顺利建立KfkProducer对象,现在我们需要把该对象传入Web框架中后续页面处理类中,以方便调用其send()函数进行数据发送。 在Play中我们使用了cache对象机制,可以在Play Web App全生命期内获得KfkProducer对象实例。 |
|
4.关闭与Broker之间的连接 |
在WEB框架中的Application_OnStop()事件中调用KfkProducer的close()函数,关闭远程Broker连接。 |
KfkConsumer部署:
|
部署要点 |
说明 |
|
1.注册发送消息回调函数 |
在WEB框架中的Application_OnStart()事件中向Jar注册消息接收回调函数。并重写onRecvMsg()回调接口,用于接受来自Broker的数据信息。 在onRecvMsg()函数中,还需针对传入的Object对象进行instanceof比对操作,区分特定对象。 |
|
2.注册需要接收的Object类型 |
向Jar包中注册需要接收的对象类型,比如本应用需要接收(UserInfo,CompanyInfo,ProdcutInfo等对象)。 注册后,来自Broker的广播消息将被Jar包过滤,只返回调用者所需的对象数据。 |
|
3.建立与Zookeeper(Broker)之间的连接 |
在WEB框架中的 Application_OnStart()事件中调用KfkConsumer connect()函数,连接远程Zookeeper/Broker。 |
|
4.启动消息泵线程 |
经过前两步操作后,我们已经顺利建立与Zookeeper/Broker建立连接。 我们需要启动消息泵来收听消息的到来,这里需要调用KfkConsumer对象的start()函数启动消息泵线程常驻内存。 |
|
4.关闭与Zookeeper之间的连接 |
在WEB框架中的Application_OnStop()事件中调用KfkConsumer的close()函数,关闭远程Zookeeper/Broker连接。 |
五. 未来Kafka中间件
目前该中间件只完成了初级阶段功能,很多功能都不完善不深入,随着应用业务的拓展及Kafka未来版本功能支持,。以Kafka消息中间件为中心的大数据处理平台还有很多任务去实现。
一般在互联网中所流动的数据由以下几种类型:
•需要实时响应的交易数据,用户提交一个表单,输入一段内容,这种数据最后是存放在关系数据库(Oracle, MySQL)中的,有些需要事务支持。
•活动流数据,准实时的,例如页面访问量、用户行为、搜索情况等。我们可以针对这些数据广播、排序、个性化推荐、运营监控等。这种数据一般是前端服务器先写文件,然后通过批量的方式把文件倒到Hadoop(离线数据分析平台)这种大数据分析器里面,进行慢慢的分析。
•各个层面程序产生的日志,例如http的日志、tomcat的日志、其他各种程序产生的日志。这种数据一个是用来监控报警,还有就是用来做分析。
谢谢观赏!
注:基于全球开源共享理念,本人会分享更多原创及译文,让更多的IT人从中受益,与大家一起进步!
基因Cloud 原创,转发请注明出处
1738387@qq.com (工作繁忙,有事发邮件,QQ不加,非要事勿扰,多谢!)
2015 / 06 / 14

【原创】开发Kafka通用数据平台中间件的更多相关文章
- 一个大数据平台省了20个IT人力——敦奴数据平台建设案例分享
认识敦奴 敦奴集团创立于1987年,主营服装.酒店.地产,总部位于中国皮都-海宁.浙江敦奴联合实业股份有限公司(以下简称"敦奴")是一家集开发.设计.生产.销售于一体的大型专业服装 ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
- 用Apache Kafka构建流数据平台的建议
在<流数据平台构建实战指南>第一部分中,Confluent联合创始人Jay Kreps介绍了如何构建一个公司范围的实时流数据中心.InfoQ前期对此进行过报道.本文是根据第二部分整理而成. ...
- 大数据平台R语言web UI应用架构 设计与开发
1. 系统拓扑图 在日常业务分析中,R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据处理框架,采用内存计算,可以短时间内完成大量的数据的处理 ...
- [原创].NET 分布式架构开发实战之三 数据访问深入一点的思考
原文:[原创].NET 分布式架构开发实战之三 数据访问深入一点的思考 .NET 分布式架构开发实战之三 数据访问深入一点的思考 前言:首先,感谢园子里的朋友对文章的支持,感谢大家,希望本系列的文章能 ...
- GoldenGate实时投递数据到大数据平台(5) - Kafka
Oracle GoldenGate是Oracle公司的实时数据复制软件,支持关系型数据库和多种大数据平台.从GoldenGate 12.2开始,GoldenGate支持直接投递数据到Kafka等平台, ...
- 国内物联网平台(7):Ablecloud物联网自助开发和大数据云平台
国内物联网平台(7)——Ablecloud物联网自助开发和大数据云平台 马智 平台定位 面向IoT硬件厂商,提供设备联网与管理.远程查看控制.定制化云端功能开发.海量硬件数据存储与分析等基础设施,加速 ...
- 详解Kafka: 大数据开发最火的核心技术
详解Kafka: 大数据开发最火的核心技术 架构师技术联盟 2019-06-10 09:23:51 本文共3268个字,预计阅读需要9分钟. 广告 大数据时代来临,如果你还不知道Kafka那你就真 ...
- 用Apache Kafka构建流数据平台
近来,有许多关于“流处理”和“事件数据”的讨论,它们往往都与像Kafka.Storm或Samza这样的技术相关.但并不是每个人都知道如何将这种技术引入他们自己的技术栈.于是,Confluent联合创始 ...
随机推荐
- 单调递增最长子序列(南阳理工ACM)
描述 求一个字符串的最长递增子序列的长度如:dabdbf最长递增子序列就是abdf,长度为4 输入 第一行一个整数0<n<20,表示有n个字符串要处理随后的n行,每行有一个字符串,该字符串 ...
- [C]判断一个文件是否是jpg格式
同学要帮忙写的,用opencv的imread打开文件看抛出的异常来判断这种抖机灵的姿势就不写了… 首先知道jpg文件是以0xFFD8开始,以0xFFD9结尾的.所以直接拿来fseek fread,异或 ...
- leetcode:Unique Binary Search Trees
Given n, how many structurally unique BST's (binary search trees) that store values 1...n? For examp ...
- 阿里云yum源
wget -O /etc/yum.repos.d/CentOS-Base-aliyun.repo http://mirrors.aliyun.com/repo/Centos-6.repo 参考:htt ...
- STL笔记(3) copy()之绝版应用
STL笔记(3) copy()之绝版应用 我选用了一个稍稍复杂一点的例子,它的大致功能是:从标准输入设备(一般是键盘)读入一些整型数据,然后对它们进行排序,最终将结果输出到标准输出设备(一般是显示器屏 ...
- WP7 MD5加密
WP7不支持MD5加密,在网上找了一个实现MD5加密的算法. //Copyright (c) Microsoft Corporation. All rights reserved. using Sys ...
- 深入理解Java对象的序列化与反序列化的应用
当两个进程在进行远程通信时,彼此可以发送各种类型的数据.无论是何种类型的数据,都会以二进制序列的形式在网络上传送.发送方需要把这个Java对象转换为字节序列,才能在网络上传送:接收方则需要把字节序列再 ...
- IE6,7下li标签的间隙
1.在IE6,7下li本身没浮动,但是li内容有浮动的时候,li下边就会产生3px的间隙. 解决办法: 1.给li加浮动 2.给li加vertical-align:top; eg: <!DOCT ...
- Asp.Net判断字符是否为汉字的方法大全
判断一个字符是不是汉字通常有三种方法: 第一种用 ASCII 码判断,缺点:把全角逗号“,”当汉字处理 第二种用汉字的 UNICODE 编码范围判 断, 第三种用正则表达式判断 1.用ASCII码判断 ...
- [转] POJ图论入门
最短路问题此类问题类型不多,变形较少 POJ 2449 Remmarguts' Date(中等)http://acm.pku.edu.cn/JudgeOnline/problem?id=2449题意: ...