爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码。。。算是一份测试版的代码。大牛大神别喷。。。
通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配。
List<string> todo :进行抓取的网址的集合
List<string> visited :已经访问过的网址的集合
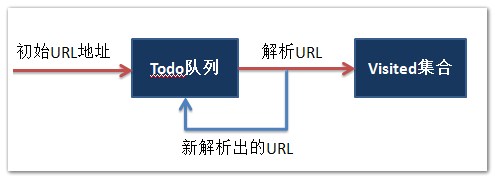
下面实现的是,给定一个初始地址,然后进行爬虫,输出正在访问的网址和已经访问的网页的个数。
需要注意的是,下面代码实现的链接匹配页面的内容如图一、图二所示:
- 图一:

- 图二:

简单代码示范如下:(测试版)

using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Web.Security;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web; namespace Demo1
{ public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
} private void button1_Click(object sender, EventArgs e)
{
Test1 a = new Test1();
a.getCurrentURL();
} public class Test1
{
List<string> todo = new List<string>();
List<string> visited = new List<string>();
string startPoint = "http://www.cnblogs.com/lmei/";
public void getCurrentURL()
{
RequestSite(startPoint); while (todo.Count > 0)
{
string currentURL = todo[0]; RequestSite(currentURL); if (visited.Contains(currentURL)) //注释1
{
Console.WriteLine("已经访问过了" + currentURL);
todo.Remove((currentURL));
}
else
{
Console.WriteLine("现在正在访问:===> " + currentURL);
visited.Add(currentURL); Console.WriteLine("目前已经访问了:===> " + visited.Count + "个网页" );
todo.Remove((currentURL));
}
}
} public void RequestSite(string url)
{
WebRequest req = WebRequest.Create(url);
HttpWebResponse res;
try{
res = (HttpWebResponse)(req.GetResponse());
}
catch (WebException ex) { res = (HttpWebResponse)ex.Response; } Stream st = res.GetResponseStream();
StreamReader rdr = new StreamReader(st);
string s = rdr.ReadToEnd();
todo.AddRange(GetLink(s));
} List<string> GetLink(string htmlPage)
{ Regex regx =
new Regex("http://www\\.cnblogs\\.com\\/lmei\\/p\\/[0-9a-zA-Z]+\\.html*" ,RegexOptions.IgnoreCase);
MatchCollection matches = regx.Matches(htmlPage); List<string> results = new List<string>();
foreach (Match match in matches)
{
if (!visited.Contains(match.Value)) //注释2
{
results.Add(match.Value);
}
}
return results;
}
} }
}
注释1 :是将已经访问过的网址排除。
注释2 :是将已经访问过的网址排除,但是可能由于同个网页中包含的两个(或两个以上)相同的链接,而且都没被访问过的,这样使得todo队列中会有相同的网址,所以需要注释1那部分进行再次过滤排除。其实也可以将注释2那部分删去,直接让注释1过滤就行。
接下来会进一步补充爬虫抓取的内容。。。
爬虫技术(四)-- 简单爬虫抓取示例(附c#代码)的更多相关文章
- 【Python3 爬虫】01_简单页面抓取
运行平台:Winodows 10 Python版本:Python 3.4.2 IDE:Sublime text3 网络爬虫 网络爬虫,也叫网络蜘蛛(Web Spider),如果把互联网比喻成一个蜘蛛网 ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
- iOS—网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用java语言抓取网络数据
网络爬虫-使用java语言抓取网络数据 前提:熟悉java语法(能看懂就行) 准备阶段:从网页中获取html代码 实战阶段:将对应的html代码使用java语言解析出来,最后保存到plist文件 上一 ...
- 爬虫学习一系列:urllib2抓取网页内容
爬虫学习一系列:urllib2抓取网页内容 所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地.我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程 ...
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- Python网络爬虫(Get、Post抓取方式)
简单的抓取网页 import urllib.request url="http://google.cn/" response=urllib.request.urlopen(url) ...
- arpspoof+driftnet+ ARP欺骗简单图片抓取
arpspoof+driftnet+ ARP欺骗简单图片抓取 driftnet是一款简单而使用的图片捕获工具,可以很方便的在网络数据包中抓取图片.该工具可以实时和离线捕获指定数据包中是图片 环境 受害 ...
- [python应用]python简单图片抓取
前言 emmmm python简单图片抓取 1 import requests 2 import threading 3 import queue 4 from subprocess import P ...
- 抓取oschina上面的代码分享python块区下的 标题和对应URL
# -*- coding=utf-8 -*- import requests,re from lxml import etree import sys reload(sys) sys.setdefau ...
随机推荐
- 【bzoj1013】[JSOI2008]球形空间产生器sphere
1013: [JSOI2008]球形空间产生器sphere Time Limit: 1 Sec Memory Limit: 162 MBSubmit: 4530 Solved: 2364[Subm ...
- 一个包的TcpServer流程
上次说到对于那种有内容的包 bool TCPServer::on_receive_data(int channel_id, void* data, int len) { packet pkt; { p ...
- MySQL 5.7 reference about JSON
最近需要用到MySQL 5.7中的JSON,总结一下MySQL中关于JSON的内容 参考: 11.6 The JSON Data Type 12.16 JSON Functions JSON Func ...
- SQLite中的日期基础
SQLite包含了如下时间/日期函数: datetime().......................产生日期和时间 date()...........................产生日期 t ...
- php中用于接受表单数据的$_request与$_post、$_get
一.$_request与$_post.$_get的区别和特点 $_REQUEST[]具用$_POST[] $_GET[]的功能,但是$_REQUEST[]比较慢.通过post和get方法提交的所有数据 ...
- Unity 3D 游戏上线之后的流水总结
原地址:http://tieba.baidu.com/p/2817057297?pn=1 首先.unity 灯光烘焙 :Unity 3D FBX模型导入.选项Model 不导入资源球.Rig 不导入骨 ...
- BZOJ2463: [中山市选2009]谁能赢呢?
感慨下汉堡的找水题能力… /************************************************************** Problem: 2463 User: zhu ...
- Lucene教程--转载
Lucene教程 1 lucene简介1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来 ...
- C#编程使用Managed Wifi API连接无线SSID
C#编程使用Managed Wifi API连接无线SSIDhttp://www.2cto.com/kf/201307/227623.html Managed Wifi API - Homehttp: ...
- 正则表达式(RegExp)
正则表达式(RegExp) 如何按一定规则快速查找到需要找寻的内容,js的设计者们给我们提供了一个叫正则表达式(RegExp对象),专门用于处理类似问题. RegExp对象表示正则表达式,它是对字符串 ...