L1 正则为什么会使参数偏向稀疏
2018-12-09 22:18:43
假设费用函数 L 与某个参数 x 的关系如图所示:
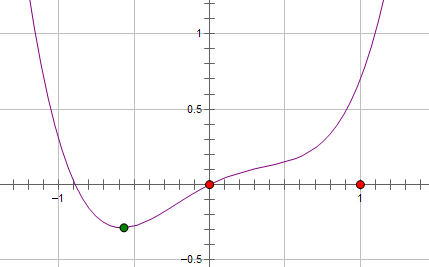
则最优的 x 在绿点处,x 非零。
现在施加 L2 regularization,新的费用函数()如图中蓝线所示:
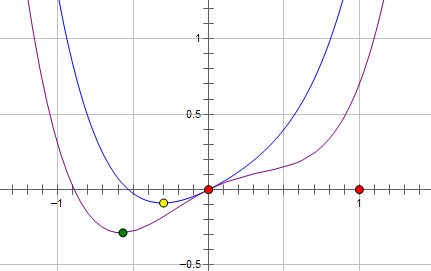
 最优的 x 在黄点处,x 的绝对值减小了,但依然非零。
最优的 x 在黄点处,x 的绝对值减小了,但依然非零。
而如果施加 L1 regularization,则新的费用函数()如图中粉线所示:

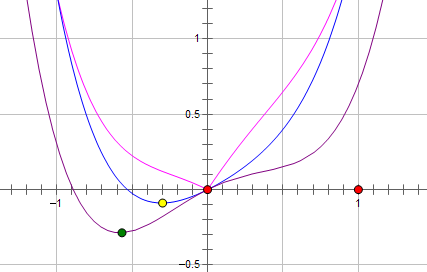
两种 regularization 能不能把最优的 x 变成 0,取决于原先的费用函数在 0 点处的导数。
如果本来导数不为 0,那么施加 L2 regularization 后导数依然不为 0,最优的 x 也不会变成 0。
而施加 L1 regularization 时,只要 regularization 项的系数 C 大于原先费用函数在 0 点处的导数的绝对值,x = 0 就会变成一个极小值点。原因是我们可以对0两边进行求导分别得到f'(0) - C和f‘(0) + C,如果C > f'(0),那么左右两边就会异号,这样的话,0就成了极小值点了。
上面只分析了一个参数 x。事实上 L1 regularization 会使得许多参数的最优值变成 0,这样模型就稀疏了。
L1 正则为什么会使参数偏向稀疏的更多相关文章
- L1正则和L2正则的比较分析详解
原文链接:https://blog.csdn.net/w5688414/article/details/78046960 范数(norm) 数学上,范数是一个向量空间或矩阵上所有向量的长度和大小的求和 ...
- 笔记︱范数正则化L0、L1、L2-岭回归&Lasso回归(稀疏与特征工程)
机器学习中的范数规则化之(一)L0.L1与L2范数 博客的学习笔记,对一些要点进行摘录.规则化也有其他名称,比如统计学术中比较多的叫做增加惩罚项:还有现在比较多的正则化. -------------- ...
- 【机器学习】--鲁棒性调优之L1正则,L2正则
一.前述 鲁棒性调优就是让模型有更好的泛化能力和推广力. 二.具体原理 1.背景 第一个更好,因为当把测试集带入到这个模型里去.如果测试集本来是100,带入的时候变成101,则第二个模型结果偏差很大, ...
- 一种利用 Cumulative Penalty 训练 L1 正则 Log-linear 模型的随机梯度下降法
Log-Linear 模型(也叫做最大熵模型)是 NLP 领域中使用最为广泛的模型之一,其训练常采用最大似然准则,且为防止过拟合,往往在目标函数中加入(可以产生稀疏性的) L1 正则.但对于这种带 L ...
- L1 正则 和 L2 正则的区别
L1,L2正则都可以看成是 条件限制,即 $\Vert w \Vert \leq c$ $\Vert w \Vert^2 \leq c$ 当w为2维向量时,可以看到,它们限定的取值范围如下图: 所以它 ...
- L1正则与L2正则
L1正则是权值的绝对值之和,重点在于可以稀疏化,使得部分权值等于零. L1正则的含义是 ∥w∥≤c,如下图就可以解释为什么会出现权值为零的情况. L1正则在梯度下降的时候不可以直接求导,可以有以下几种 ...
- 【机器学习】--线性回归中L1正则和L2正则
一.前述 L1正则,L2正则的出现原因是为了推广模型的泛化能力.相当于一个惩罚系数. 二.原理 L1正则:Lasso Regression L2正则:Ridge Regression 总结: 经验值 ...
- 贝叶斯先验解释l1正则和l2正则区别
这里讨论机器学习中L1正则和L2正则的区别. 在线性回归中我们最终的loss function如下: 那么如果我们为w增加一个高斯先验,假设这个先验分布是协方差为 的零均值高斯先验.我们在进行最大似然 ...
- 正则-匹配获取url参数
1.根据指定参数名获取参数值 A页面向连接到B页面的url为: http://www.189dg.com/ajax/sms_query.ashx?action=smsdetail&sid=22 ...
随机推荐
- Zookeeper .Net客户端代码
本来此客户端可以通过NuGet获取,如果会使用NuGet, 则可以使用命令Install-Package ZooKeeperNet(需要最新版本的NuGet) 如果不会,就去 NuGet官网了解htt ...
- 细数php里的那些“坑”
Part 1 Grammer 尽管PHP的语法已经很松散,写起来很“爽”.但是对于学过 Java 的“完全面向对象程序员“来说,PHP程序设计语言里,还是有一些的坑的.下面请让我来盘点一下. Pars ...
- android学习:apiDemos导入时R.java无法生成的问题
准备导入apiDemos研究一下别人的代码,发现导入后不能正常build,无法生成R.java,发现res/layout/progressbar_2.xml里有几个 <ProgressBar a ...
- 压测freeswitch--安装sipp
1.sipp下载 下载链接:https://sourceforge.net/projects/sipp/files/ 此处我们下载sipp3.3为例 2.linux系统下编译sipp 安装sipp 可 ...
- mysql的 深度使用 - 游标 , 定时器, 触发器 的使用 ?
游标 叶叫做 光标; 只能使用在 mysql的 存储过程 或函数中! 游标的概念? 为什么要使用 游标? 什么叫 定时器, 就是事件 event! 是在 mysql 5.0以上的版本中, 才能使用支持 ...
- IDEA配置SVN,Git,GitLab
集成GitLab插件:http://baijiahao.baidu.com/s?id=1602987918454762059&wfr=spider&for=pc 使用IDEA集成Git ...
- 函数嵌套函数传递this值
<button onclick="demo()(this)">test</button> function demo(){ return function ...
- 用spring tool suite插件创建spring boot项目时报An internal error occurred during: "Building UI model". com/google/common/
本文为博主原创,未经允许不得转载 在用spring tool suite创建spring boot项目时,报一下异常: 查阅很多资料之后发现是因为装的spring tool suite的版本与ecli ...
- js精度误差
之前虽然有看到过 js 精度相关的文章.但也都没有“印象深刻” ,但是今天"有幸"遇到了. 做一个项目,进行页面调试的时候, 当数量增加到3时总价格变得好长好长 立马在控制台验证了 ...
- Shell 脚本批量创建数据库表
使用 Shell 脚本批量创建数据表 系统:Centos6.5 64位 MySQL版本:5.1.73 比如下面这个脚本: #!/bin/bash #批量新建数据表 for y in {0..199}; ...