centos6.6安装hadoop-2.5.0(二、伪分布式部署)
操作系统:centos6.6(一台服务器)
环境:selinux disabled;iptables off;java 1.8.0_131
安装包:hadoop-2.5.0.tar.gz
伪分布式环境(适用于学习环境)
安装步骤:
1、解压安装包
# tar zxvf hadoop-2.5.0.tar.gz -C /data/hadoop/hadoopfake/
2、配置hadoop参数
1)设置环境变量 #vim /etc/profile

追加下面两行:
export HADOOP_HOME=/data/hadoop/hadoopfake/hadoop-2.5.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
#source /etc/profile 使环境变量生效
#echo $HADOOP_HOME 验证hadoop参数

2)设置JAVA_HOME参数
分别修改/data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/下的hadoop-env.sh、mapred-env.sh、yarn-env.sh文件的JAVA_HOME参数
(如果JAVA_HOME在/etc/expofile或者~/.bashrc设置了环境变量export JAVA_HOME,那以上文件不用修改JAVA_HOME的参数)
3)配置core-site.xml文件
#vim /data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/core-site.xml
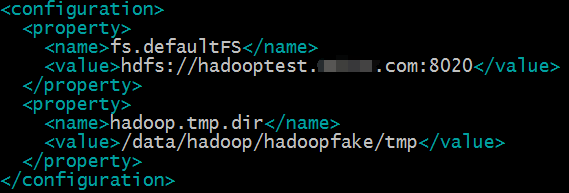
fs.defaultFS参数设置的是hdfs的地址;
hadoop.tmp.dir设置的是hadoop的临时目录,例如namenode的数据都会默认存放在这个目录;如果不配置这个参数,namenode数据会默认放在/tmp/hadoop*目录下,操作系统重启这个目录的所有数据都会清空,namenode的元数据会丢失,所以最好新建目录存放namenode的元数据。
4)配置hdfs-site.xml文件
#vim /data/hadoop/hadoopfake/hadoop-2.5.0/etc/hadoop/hdfs-site.xml

dfs.replication配置的是HDFS存储时的备份数量,伪分布式环境只有一个节点,所以设置为1就可以。
3、格式化、启动HDFS
#/data/hadoop/hadoopfake/hadoop-2.5.0/bin/hdfs namenode -format 格式化hdfs
#ll /data/hadoop/hadoopfake/tmp/dfs/name/current 查看格式化后的目录

格式化是对分布式文件系统HDFS中的datanode进行分块,统计所有分块后的初始元数据存储在namenode中
格式化后hadoop.tmp.dir下面有dfs目录则格式化成功
fsimage是namenode元数据在内存满了后,持久化保存到文件
fsimage*md5是校验文件,用于校验fsimage的完整性
seen_txid是hadoop的版本
VERSION:namespaceID是namenode的唯一ID
clusterID是集群的ID,namenode和datanode集群ID一致时表明是一个集群
4、启动namenode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start namenode

5、启动datanode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start datanode

6、启动secondarynamenode
#/data/hadoop/hadoopfake/hadoop-2.5.0/sbin/hadoop-daemon.sh start secondarynamenode

7、使用jps命令查看node是否启动
#jps
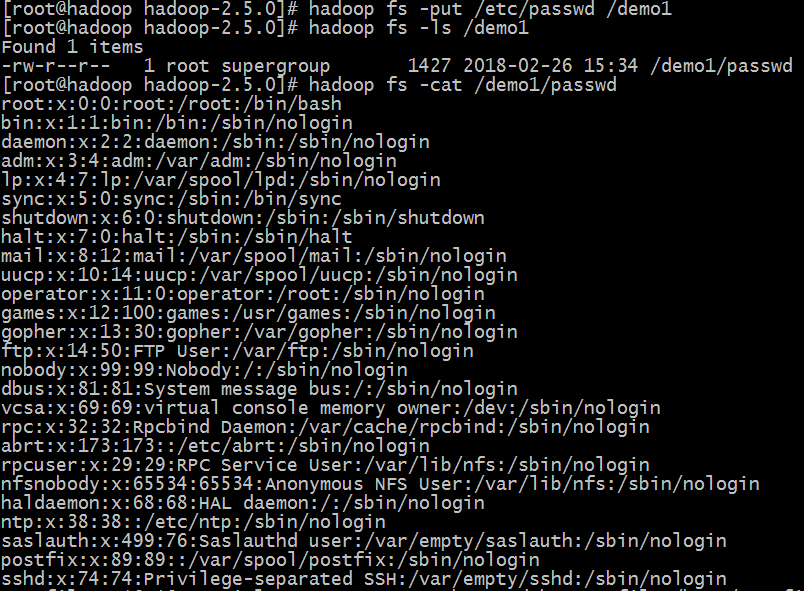
8、测试创建目录,上传文件
#hadoop fs -mkdir /demo1

#hadoop fs -put /etc/passwd /demo1
#hadoop fs -cat /demo1/passwd 读取文件内容
#hadoop fs -get /demo1/passwd

9、配置启动YARN
1)配置mapred-site.xml
#cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
#vim etc/hadoop/mapred-site.xml
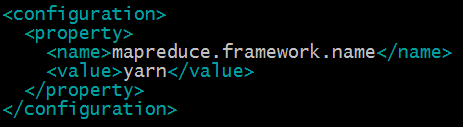
指定mapreduce运行在yarn框架上
2)配置yarn-site.xml
#vim etc/hadoop/yarn-site.xml
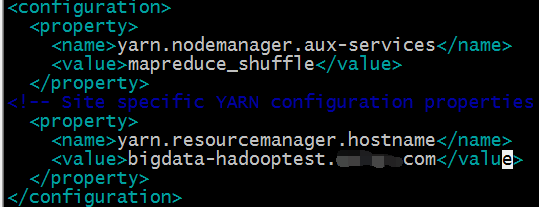
yarn.nodemanager.aux-services配置了yarn的默认混洗方式,选择为mapreduce的默认混洗算法
yarn.resourcemanager.hostname指定了Resourcemanager运行在哪个节点上
3)启动Resourcemanager
#vim /etc/hosts

#/sbin/yarn-daemon.sh start resourcemanager

#jps

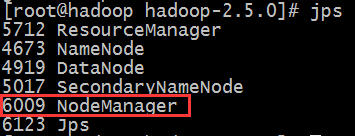
4)启动nodemanager
#/sbin/yarn-daemon.sh start nodemanager

#jps
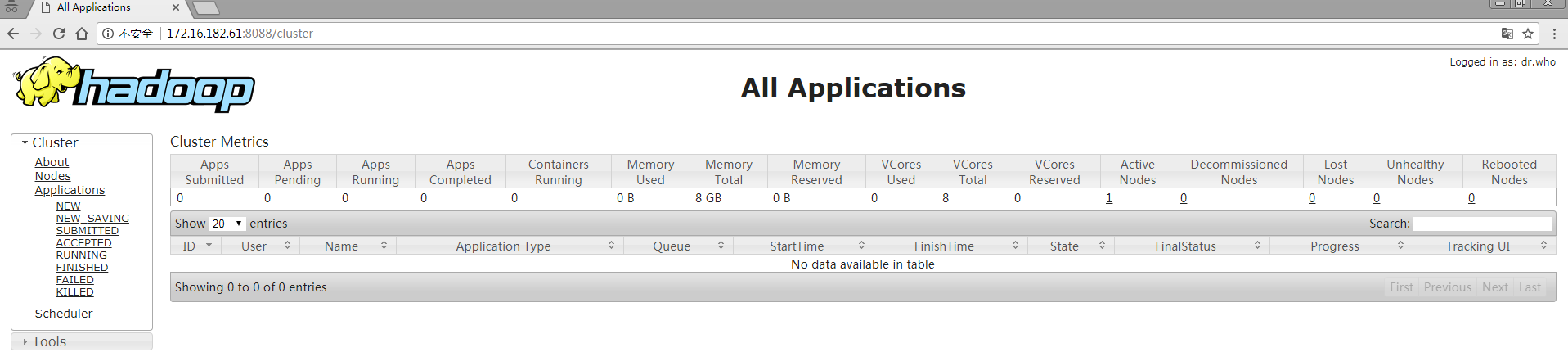
5)web界面
10、运行mapreduce job
1)创建输入目录
#hadoop fs -mkdir -p /wordcountdemo/input

2)创建文件并上传到/wordcountdemo/input目录中
#cat wc.input
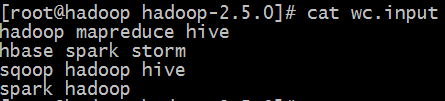
#hadoop fs -put wc.input /wordcountdemo/input/

3)运行wordcount mapreduce job
#bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-example-2.5.0.jar wordcount /wordcountdemo/input /wordcountdemo/output
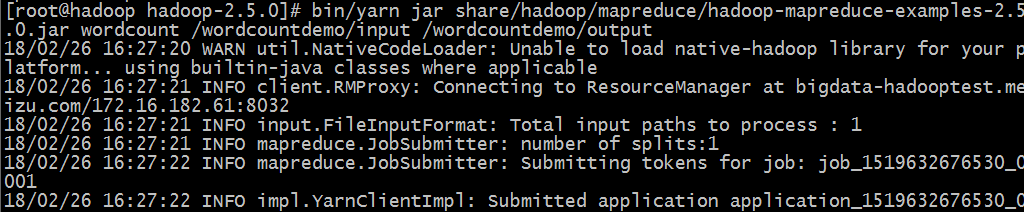
#hadoop fs -ls /wordcountdemo/output 查看输出结果

_SUCCESS文件是个空文件,只是来说明job执行成功
part-r-00000是结果文件,-r-说明这个文件是reduce阶段产生的结果,如没有reduce则应该是-m-
#hadoop fs -cat /wordcountdemo/output/part-r-00000 查看输出文件内容

11、停止hadoop
#sbin/hadoop-daemon.sh stop namenode
#sbin/hadoop-daemon.sh stop datanode
#sbin/hadoop-daemon.sh stop secondarynode
#sbin/yarn-daemon.sh stop resourcemanager
#sbin/yarn-daemon.sh stop nodemanager
12、开启历史服务
开启历史服务可在web界面上查看yarn上执行的job情况等信息
#sbin/mr-jobhistory-daemon.sh start historyserver
正在执行中的任务


centos6.6安装hadoop-2.5.0(二、伪分布式部署)的更多相关文章
- Ubuntu 14.04 LTS 安装 spark 1.6.0 (伪分布式)-26号开始
需要下载的软件: 1.hadoop-2.6.4.tar.gz 下载网址:http://hadoop.apache.org/releases.html 2.scala-2.11.7.tgz 下载网址:h ...
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- CentOS7.0分布式安装HADOOP 2.6.0笔记-转载的
三台虚拟机,IP地址通过路由器静态DHCP分配 (这样就无需设置host了). 三台机器信息如下 - 1. hadoop-a: 192.168.0.20 #master 2. ha ...
- 安装hadoop 2.2.0
安装环境为 CentOS 64位系统, 大概分下面几个步奏, 0. 安装JDK1. 配置SSH2. 配置/etc/hosts3. 拷贝hadoop包到没台机器上4. 修改hadoop配置文件5. 关闭 ...
- hadoop 2.6.0 伪分布式部署安装遇到的问题
之前读到了一篇关于配置安装hadoop的博文(地址:http://www.powerxing.com/install-hadoop/)能正确安装和运行,但是在网页进行Jobtracker监控时,输入l ...
- Ubuntu 13.10下Hadoop 2.2 安装、配置、编译(伪分布式)
1.安装JDK.在此不做解说,上篇博文里已介绍过.http://www.cnblogs.com/lifeinsmile/p/3578677.html 2.配置ssh. ssh服务,用于管理远程Hado ...
- Hadoop1.0.4伪分布式安装
前言: 目前,学习hadoop的目的是想配合其它两个开源软件Hbase(一种NoSQL数据库)和Nutch(开源版的搜索引擎)来搭建一个知识问答系统,Nutch从指定网站爬取数据存储在Hbase数据库 ...
- hadoop2.2.0 单机伪分布式(含64位hadoop编译) 及 eclipse hadoop开发环境搭建
hadoop中文镜像地址:http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.2.0/ 第一步,下载 wget 'http://archive ...
随机推荐
- CentOS7 下源代码安装php7
安装PHP7: php-7.1.2.tar.gz:下载:wget http://cn2.php.net/get/php-7.1.2.tar.gz/from/this/mirror 安装php: # t ...
- 卸载WPS后怎么WORD的图标还是WPS
在电脑中选择使用Microsoft Office并将之前安装的WPS Office办公软件卸载了.但是卸载之后发现电脑系统中的Word.Excel等文件无法正常显示图标.在这样的情况下,我们应该如何解 ...
- 【Oracle】【5】主键、外键管理
前言: 1,事实上我是不使用外键的,所以本文只介绍主键 正文: (1)创建表的同时创建主键约束 create table STUDENT ( ID int , NAME varchar(8), AGE ...
- 【Oracle】【1】查询N分钟之前的数据
--查询距离现在N分钟前的数据 1440:表示一天有1440分钟 SYSDATE - 10 :表示10天前 参考博客: 1,oracle 查询十分钟之前的数据 - 胡金水的博客 - CSDN博客 ht ...
- java把类似a=1&b=2&c=3的String类型数据转成map集合
public static Map<String, Object> transStringToMap(String mapString, String separator, String ...
- element-ui table中排序 取消表格默认排序问题
sortTable 设置为 custom 一定要设置在列上
- kohana导入和导出
一.导入 ini_set('memory_limit', '512M'); require_once(Kohana::find_file('vendor', 'PHPExcel/PHPExcel/IO ...
- Spring Boot的数据访问:CrudRepository接口的使用
示例 使用CrudRepository接口访问数据 创建一个新的Maven项目,命名为crudrepositorytest.按照Maven项目的规范,在src/main/下新建一个名为resource ...
- 【LeetCode】矩阵操作
1. 矩阵旋转 将 n × n 矩阵顺时针旋转 90°. 我的思路是 “ 从外到内一层一层旋转 ”. 一个 n × n 矩阵有 (n + 1) / 2 层,每层有 4 部分,将这 4 部分旋转. 顺时 ...
- 在Eclipse中无法链接到svn,出现Previous operation has not finished; run 'cleanup' if it was interrupted异常
由于使用了clean或是clean up导致和svn断开链接 1.下载一个sqlite3.exe 2.将sqlite3.exe放到本项目的.svn同级目录下(.svn默认是隐藏,让.svn文件夹显示查 ...