Prometheus监控学习笔记之360基于Prometheus的在线服务监控实践
0x00 初衷
最近参与的几个项目,无一例外对监控都有极强的要求,需要对项目中各组件进行详细监控,如服务端API的请求次数、响应时间、到达率、接口错误率、分布式存储中的集群IOPS、节点在线情况、偏移量等。
比较常见的方式是写日志,将日志采集到远端进行分析和绘图,或写好本地监控脚本进行数据采集后,通过监控系统客户端push到监控系统中进行打点。基本上我们需要的都能覆盖,但仍然有一些问题在使用上不太舒服,如在大规模请求下日志采集和分析的效率比较难控制,或push打点的粒度和纬度以及查询不够灵活等。
后来在同事对《Google SRE》这本书中的一些运维思想进行一番安利后,抱着试一试的态度,开始尝试使用Prometheus做为几个项目的监控解决方案。
0x01 Prometheus的特点
多维数据模型(时序数据由 metric 名和一组K/V标签构成)。
灵活强大的查询语句(PromQL)。
不依赖存储,支持local和remote(OpenTSDB、InfluxDB等)不同模型。
采用 HTTP协议,使用Pull模式采集数据。
监控目标,可以采用服务发现或静态配置的方式。
支持多种统计数据模型,图形化友好(Grafana)。
0x02 数据类型
- Counter
Counter表示收集的数据是按照某个趋势(增加/减少)一直变化的。
- Gauge
Gauge表示搜集的数据是瞬时的,可以任意变高变低。
- Histogram
Histogram可以理解为直方图,主要用于表示一段时间范围内对数据进行采样,(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计。
- Summary
Summary和Histogram十分相似,主要用于表示一段时间范围内对数据进行采样,(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
Summary和Histogram十分相似,主要用于表示一段时间范围内对数据进行采样,(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。
在我们的使用场景中,大部分监控使用Counter来记录,例如接口请求次数、消息队列数量、重试操作次数等。比较推荐多使用Counter类型采集,因为Counter类型不会在两次采集间隔中间丢失信息。
一小部分使用Gauge,如在线人数、协议流量、包大小等。Gauge模式比较适合记录无规律变化的数据,而且两次采集之间可能会丢失某些数值变化的情况。随着时间周期的粒度变大,丢失关键变化的情况也会增多。
还有一小部分使用Histogram和Summary,用于统计平均延迟、请求延迟占比和分布率。另外针对Historgram,不论是打点还是查询对服务器的CPU消耗比较高,通过查询时查询结果的返回耗时会有十分直观的感受。
0x03 时序数据-打点-查询
我们知道每条时序数据都是由 metric(指标名称),一个或一组label(标签),以及float64的值组成的。
标准格式为 <metric name>{<label name>=<label value>,...}
例如:
rpc_invoke_cnt_c{code="0",method="Session.GenToken",job="Center"} 5
rpc_invoke_cnt_c{code="0",method="Relation.GetUserInfo",job="Center"} 12
rpc_invoke_cnt_c{code="0",method="Message.SendGroupMsg",job="Center"} 12
rpc_invoke_cnt_c{code="4",method="Message.SendGroupMsg",job="Center"} 3
rpc_invoke_cnt_c{code="0",method="Tracker.Tracker.Get",job="Center"} 70
这是一组用于统计RPC接口处理次数的监控数据。
其中rpc_invoke_cnt_c为指标名称,每条监控数据包含三个标签:code 表示错误码,service表示该指标所属的服务,method表示该指标所属的方法,最后的数字代表监控值。
针对这个例子,我们共有四个维度(一个指标名称、三个标签),这样我们便可以利用Prometheus强大的查询语言PromQL进行极为复杂的查询。
0x04 PromQL
PromQL(Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,支持条件查询、操作符,并且内建了大量内置函,供我们针对监控数据的各种维度进行查询。
我们想统计Center组件Router.Logout的频率,可使用如下Query语句:
rate(rpc_invoke_cnt_c{method="Relation.GetUserInfo",job="Center"}[1m])
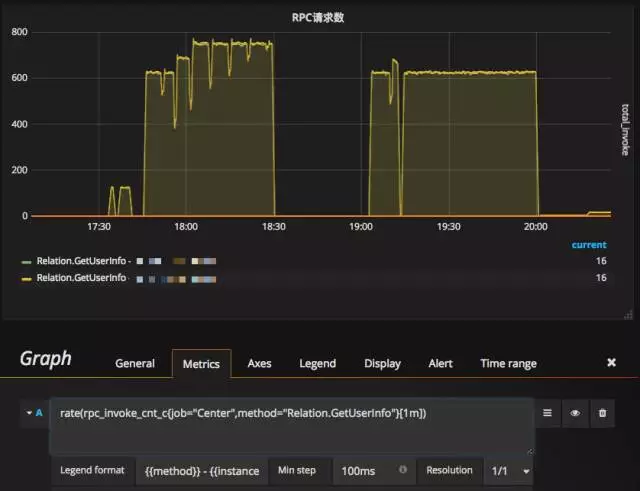
或者基于方法和错误码统计Center的整体RPC请求错误频率:
sum by (method, code)(rate(rpc_invoke_cnt_c{job="Center",code!="0"}[1m]))
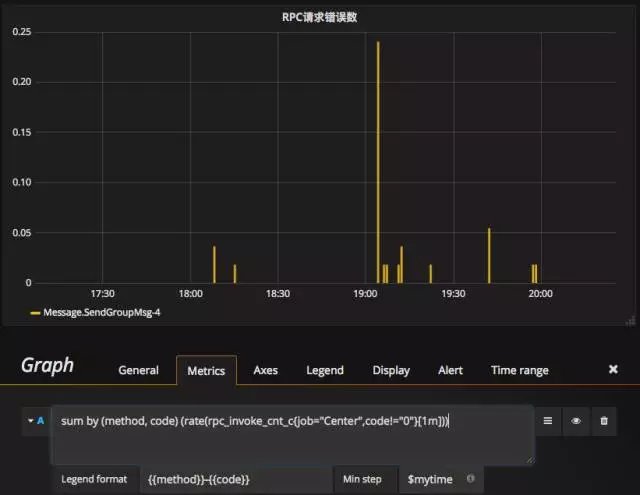
如果我们想统计Center各方法的接口耗时,使用如下Query语句即可:
rate(rpc_invoke_time_h_sum{job="Center"}[1m]) / rate(rpc_invoke_time_h_count{job="Center"}[1m])
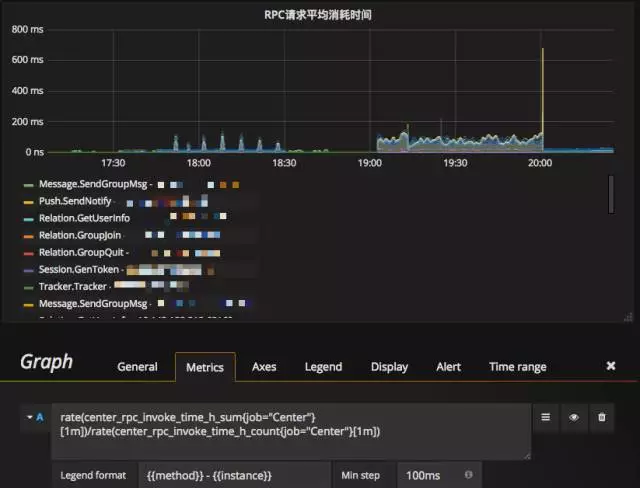
更多的内建函数这里不展开介绍了。函数使用方法和介绍可以详细参见官方文档中的介绍:https://prometheus.io/docs/querying/functions/
另外,配合查询,在打点时metric和labal名称的定义也有一定技巧。
比如在我们的项目中:
rpc_invoke_cnt_c 表示rpc调用统计
api_req_num_cv 表示httpapi调用统计
msg_queue_cnt_c 表示队列长度统计
尽可能使用各服务或者组件通用的名称定义metric然后通过各种lable进行区分。
最开始我们的命名方式是这样的,比如我们有三个组件center、gateway、message。RPC调用统计的metric相应的命名成了三个:
center_rpc_invoke_cnt_c
gateway_rpc_invoke_cnt_c
message_rpc_invoke_cnt_c
这种命名方式,对于各组件的开发同学可能读起来会比较直观,但是在实际查询过程中,这三个metric相当于三个不同的监控项。
例如我们查询基于method统计所有组件RPC请求错误频率,如果我们使用通用名称定义metric名,查询语句是这样的
sum by (method, code) (rate(rpc_invoke_cnt_c{code!="0"}[1m]))
但如果我们各个组件各自定义名称的话,这条查询需要写多条。虽然我们可以通过 {__name__=~".*rpc_invoke_cnt_c"} 的方式来规避这个问题,但在实际使用和操作时体验会差很多。
例如在Grafana中,如果合理命名相对通用的metric名称,同样一个Dashboard可以套用给多个相同业务,只需简单修改template匹配一下label选择即可。不然针对各个业务不同的metric进行针对性的定制绘图也是一个十分痛苦的过程。
同时通过前面的各类查询例子也会发现,我们在使用label时也针对不同的含义进行了区分如 method=GroupJoin|GetUserInfo|PreSignGet|... 来区分调用的函数方法,code=0|1|4|1004|...来区分接口返回值,使查询的分类和结果展示更加方便直观,并且label在Grafana中是可以直接作为变量进行更复杂的模版组合。
更多的metric和label相关的技巧可以参考官方文档:https://prometheus.io/docs/practices/naming/
0x05 服务发现
在使用初期,参与的几个项目的Prometheus都是各自独立部署和维护的。其配置也是按照官方文档中的标准配置来操作。机器数量少的时候维护简单,增删机器之后简单reload一下即可。例如:
但随着服务器量级增长,业务整合到同一组Prometheus时,每次上下线实例都是一个十分痛苦的过程,配置文件庞大,列表过长,修改的过程极其容易眼花导致误操作。所以我们尝试使用了Prometheus的服务发现功能。
从配置文档中不难发现Prometheus对服务发现进行了大量的支持,例如大家喜闻乐见的Consul、etcd和K8S。
<scrape_config> <tls_config> <azure_sd_config> <Consul_sd_config> <dns_sd_config> <ec2_sd_config> <openstack_sd_config> <file_sd_config> <gce_sd_config> <kubernetes_sd_config> <marathon_sd_config> <nerve_sd_config> <serverset_sd_config> <triton_sd_config>
详细的服务发现配置请参照官网: https://prometheus.io/docs/prometheus/latest/configuration/configuration/
由于最近参与的几个项目深度使用公司内部的配置管理服务gokeeper,虽然不是Prometheus原生支持,但是通过简单适配也是同样能满足服务发现的需求。我们最终选择通过file_sd_config进行服务发现的配置。
file_sd_config 接受json格式的配置文件进行服务发现。每次json文件的内容发生变更,Prometheus会自动刷新target列表,不需要手动触发reload操作。所以针对我们的gokeeper编写了一个小工具,定时到gokeeper中采集服务分类及分类中的服务器列表,并按照file_sd_config的要求生成对应的json格式。
下面是一个测试服务生成的json文件样例。
[
{
"targets": [
"10.10.10.1:65160",
"10.10.10.2:65160"
],
"labels": {
"job":"Center",
"service":"qtest"
}
},
{
"targets": [
"10.10.10.3:65110",
"10.10.10.4:65110"
],
"labels": {
"job":"Gateway",
"service":"qtest"
}
}
]
Prometheus配置文件中将file_sd_configs的路径指向json文件即可。
-job_name: 'qtest'
scrape_interval: 5s
file_sd_configs:
- files: ['/usr/local/prometheus/qtestgroups/*.json']
如果用etcd作为服务发现组件也可以使用此种方式,结合confd配合模版和file_sd_configs可以极大地减少配置维护的复杂度。只需要关注一下Prometheus后台采集任务的分组和在线情况是否符合期望即可。社区比较推崇Consul作为服务发现组件,也有非常直接的内部配置支持。
0x06 高可用
高可用目前暂时没有太好的方案。官方给出的方案可以对数据做Shard,然后通过federation来实现高可用方案,但是边缘节点和Global节点依然是单点,需要自行决定是否每一层都要使用双节点重复采集进行保活。
使用方法比较简单,例如我们一个机房有三个Prometheus节点用于Shard,我们希望Global节点采集归档数据用于绘图。首先需要在Shard节点进行一些配置。
Prometheus.yml:
global:
external_labels:
slave: 0 #给每一个节点指定一个编号 三台分别标记为0,1,2
rule_files:
- node_rules/zep.test.rules #指定rulefile的路径
scrape_configs:
- job_name: myjob
file_sd_configs:
- files: ['/usr/local/prometheus/qtestgroups/*.json']
relabel_configs:
- source_labels: [__address__]
modulus: 3 # 3节点
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$ # 表示第一个节点
action: keep
编辑规则文件:
node_rules/zep.test.rules:
job:rpc_invoke_cnt:rate:1m=rate(rpc_invoke_cnt_c{code!="0"}[1m])
在这里job:rpc_invoke_cnt:rate:1m 将作为metric名,用来存放查询语句的结果。
在Global节点Prometheus.yml也需要进行修改。
-job_name: slaves
honor_labels: true
scrape_interval: 5s
metrics_path: /federate
params:
match[]:
- '{__name__=~"job:.*"}'
static_configs:
- targets:
- 10.10.10.150:9090
- 10.10.10.151:9090
- 10.10.10.152:9090
在这里我们只采集了执行规则后的数据用于绘图,不建议将Shard节点的所有数据采集过来存储再进行查询和报警的操作。这样不但会使Shard节点计算和查询的压力增大(通过HTTP读取原始数据会造成大量IO和网络开销),同时所有数据写入Global节点也会使其很快达到单Prometheus节点的承载能力上限。
另外部分敏感报警尽量不要通过global节点触发,毕竟从Shard节点到Global节点传输链路的稳定性会影响数据到达的效率,进而导致报警实效降低。例如服务updown状态,API请求异常这类报警我们都放在s hard节点进行报警。
此外我们还编写了一个实验性质的Prometheus Proxy工具,代替Global节点接收查询请求,然后将查询语句拆解,到各shard节点抓取基础数据,然后再在Proxy这里进行Prometheus内建的函数和聚合操作,最后将计算数据抛给查询客户端。这样便可以直接节约掉Global节点和大量存储资源,并且Proxy节点由于不需要存储数据,仅接受请求和计算数据,横向扩展十分方便。
当然问题还是有的,由于每次查询Proxy到shard节点拉取的都是未经计算的原始数据,当查询的metric数据量比较大时,网络和磁盘IO开销巨大。因此在绘图时我们对查询语句限制比较严格,基本不允许进行无label限制的模糊查询。
0x07 报警
Prometheus的报警功能目前来看相对计较简单。主要是利用Alertmanager这个组件。已经实现了报警组分类,按标签内容发送不同报警组、报警合并、报警静音等基础功能。配合rules_file中编辑的查询触发条件,Prometheus会主动通知Alertmanager然后发出报警。由于我们公司内使用的自研的Qalarm报警系统,接口比较丰富,和Alertmanager的webhook简单对接即可使用。
Alertmanager也内建了一部分报警方式,如Email和第三方的Slack,初期我们的存储集群报警使用的就是Slack,响应速度还是很不错的。
需要注意的是,如果报警已经触发,但是由于一些原因,比如删除业务监控节点,使报警恢复的规则一直不能触发,那么已出发的报警会按照Alertmanager配置的周期一直重复发送,要么从后台silence掉,要么想办法使报警恢复。例如前段时间我们缩容Ceph集群,操作前没有关闭报警,触发了几个osddown的报警,报警刷新周期2小时,那么每过两小时Alertmanager都会发来一组osddown的报警短信。
对应编号的osd由于已经删掉已经不能再写入up对应的监控值,索性停掉osddown报警项,直接重启ceph_exporter,再调用Prometheus API删掉对应osd编号的osdupdown监控项,随后在启用osddown报警项才使报警恢复。
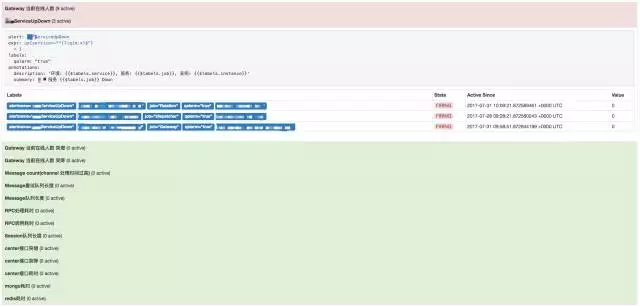
如下图的报警详情页面,红色的是已触发的报警,绿色的是未触发报警:
0x08 绘图展示
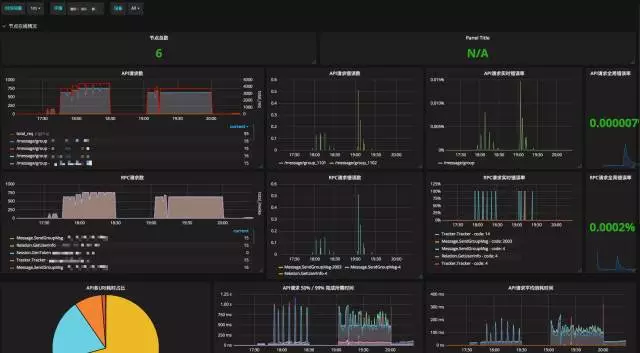
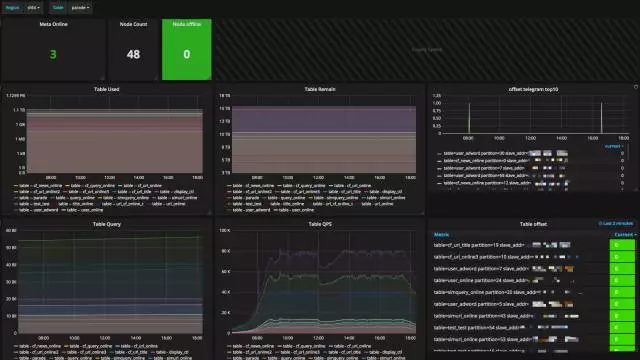
对于页面展示,我们使用的是Grafana,如下面两张图,是两个不同服务的Dashboard,可以做非常多的定制化,同时Grafana的template也可以作为参数传到查询语句中,对多维度定制查询提供了极大的便利。
0x09 Q&A
Q1:Promethues Alertmanager,能结合案例来一个么?
A1:直接演示一条报警规则吧。
ALERT SlowRequest
IF ceph_slow_requests{service="ceph"} > 10
FOR 1m
LABELS { qalarm = "true" }
ANNOTATIONS {
summary = "Ceph Slow Requests",
description = "slow requests count: {{ $value }} - Region:{{ $labels.group }}",
}
这条规则在查询到ceph slow_request > 10并且超过1分钟时触发一条报警。
Q2:exporter的编写及使用方法,以及 promethues 如何结合 grafana使用和promethues 是如何进行报警的。
A2:exporter的编写可以单独拿出来写一篇文章了。我们这边主要使用的Prometheus Golang SDK,在项目中注册打点,并通过Http接口暴露出来。报警没有结合Grafana,不过大多数Grafana中使用的查询语句,简单修改即可成为Alertmanager的报警规则。
Q3:删除配置文件job,但是通过查询还有job记录,怎么删除job记录?
A3:直接通过Prometheus接口处理即可
curl -X "DELETE" "http://prometheus:9090/api/v1/series?match[]={job="your job"}"
和查询接口的使用方式类似
以上转载 https://mp.weixin.qq.com/s/lcjZzjptxrUBN1999k_rXw
Prometheus监控学习笔记之360基于Prometheus的在线服务监控实践的更多相关文章
- Prometheus监控学习笔记之全面学习Prometheus
0x00 概述 Prometheus是继Kubernetes后第2个正式加入CNCF基金会的项目,容器和云原生领域事实的监控标准解决方案.在这次分享将从Prometheus的基础说起,学习和了解Pro ...
- Prometheus监控学习笔记之prometheus的federation机制
0x00 概述 有时候对于一个公司,k8s集群或是所谓的caas只是整个技术体系的一部分,往往这个时候监控系统不仅仅要k8s集群以及k8s中部署的应用,而且要监控传统部署的项目.也就是说整个监控系统不 ...
- Prometheus监控学习笔记之Prometheus存储
0x00 概述 Prometheus之于kubernetes(监控领域),如kubernetes之于容器编排.随着heapster不再开发和维护以及influxdb 集群方案不再开源,heapster ...
- Prometheus监控学习笔记之Prometheus不完全避坑指南
0x00 概述 Prometheus 是一个开源监控系统,它本身已经成为了云原生中指标监控的事实标准,几乎所有 k8s 的核心组件以及其它云原生系统都以 Prometheus 的指标格式输出自己的运行 ...
- Prometheus监控学习笔记之Prometheus监控简介
0x00 Prometheus容器监控解决方案 Prometheus(普罗米修斯)是一个开源系统监控和警报工具,最初是在SoundCloud建立的.它是一个独立的开放源码项目,并且独立于任何公司.不同 ...
- Prometheus监控学习笔记之初识PromQL
0x00 概述 Prometheus 提供了一种功能表达式语言 PromQL,允许用户实时选择和汇聚时间序列数据.表达式的结果可以在浏览器中显示为图形,也可以显示为表格数据,或者由外部系统通过 HTT ...
- Prometheus监控学习笔记之解读prometheus监控kubernetes的配置文件
0x00 概述 Prometheus 是一个开源和社区驱动的监控&报警&时序数据库的项目.来源于谷歌BorgMon项目.现在最常见的Kubernetes容器管理系统中,通常会搭配Pro ...
- Prometheus监控学习笔记之Prometheus普罗米修斯监控入门
0x00 概述 视频讲解通过链接网易云课堂·IT技术快速入门学院进入,更多关于Prometheus的文章. Prometheus是最近几年开始流行的一个新兴监控告警工具,特别是kubernetes的流 ...
- Prometheus监控学习笔记之Prometheus查询无数据或者Grafana不显示数据的诡异问题
0x00 概述 Prometheus和Grafana部署完成后,网络正常,配置文件正常,抓取agent运行正常,使用curl命令获取监控端口数据正常,甚至Prometheus内的targets列表内都 ...
随机推荐
- 《全栈性能Jmeter》-5JMeter负载与监听
- [LeetCode] 492. Construct the Rectangle_Easy tag: Math
For a web developer, it is very important to know how to design a web page's size. So, given a speci ...
- Python的Matplotlib库简述
Matplotlib 库是 python 的数据可视化库import matplotlib.pyplot as plt 1.字符串转化为日期 unrate = pd.read_csv("un ...
- js不能拦截302
302跳转是浏览器自动处理并跳转 You can't handle redirects with XHR callbacks because the browser takes care of the ...
- CentOS下samba配置心得(smb和nmb都要启动)
印象中以前多次配置成功过,重新配置就把以前的资料找出来: yum安装 samba samba-client samba-swat,然后配置参见:http://www.cnblogs.com/mchin ...
- AsssetBunlder打包
unity3d,资源过多的话.可以压缩成一个资源包.加载出来后.可以解压.找到自己需要的资源 就想.net网站.很多图标都是放一个大图片上.而不是一个图标就是一个图片 因为是在项目编辑时候给资源打包. ...
- ssdb使用笔记
ssdb是一款类似于redis的nosql数据库,不过redis是基于内存的,服务器比较昂贵,ssdb则是基于硬盘存储的,很容易扩展,对于一些对速度要求不是太高的应用,还是不错的选择. 先记录一个比较 ...
- 连接mysql && ERROR 2003 (HY000): Can't connect to MySQL server on 'localhost' (10061)
上一篇:mysql服务正在启动 mysql服务无法启动 && mysql启动脚本 mysql关闭脚本 此篇目编写一个核心目的: 1.mysql连接 先抛出一个问题 这是因为mysql服 ...
- 从0开始搭建vue+webpack脚手架(四)
之前1-3部分是webpack最基本的配置, 接下来会把项目结构和配置文件重新设计,可以扩充更多的功能模块. 一.重构webpack的配置项 1. 新建目录build,存放webpack不同的配置文件 ...
- Unity3d之如何截屏
Unity3d中有时有截屏的需求,那如何截屏呢,代码如下: /// <summary> /// 截屏 /// </summary> /// <param name=&qu ...