python 搭建一个简单的 搜索引擎
我把代码和爬好的数据放在了git上,欢迎大家来参考
https://github.com/linyi0604/linyiSearcher
我是在 manjaro linux下做的, 使用python3 语言, 爬虫部分涉及到 安装ChromeDriver 可以参考我之前写的博文。
建立索引部分参考: https://baijiahao.baidu.com/s?id=1597426056496128414&wfr=spider&for=pc
检索过程,衡量文档相似度使用了余弦相似度,参考:https://www.cnblogs.com/liangjf/p/8283519.html
为了完成我的信息检索选修课大作业,写下了这个简单的小项目。 这里是一个python3 实现的简易的搜索引擎 我把它取名叫linyiSearcher -------- 所需要的python依赖包在requirements.txt中
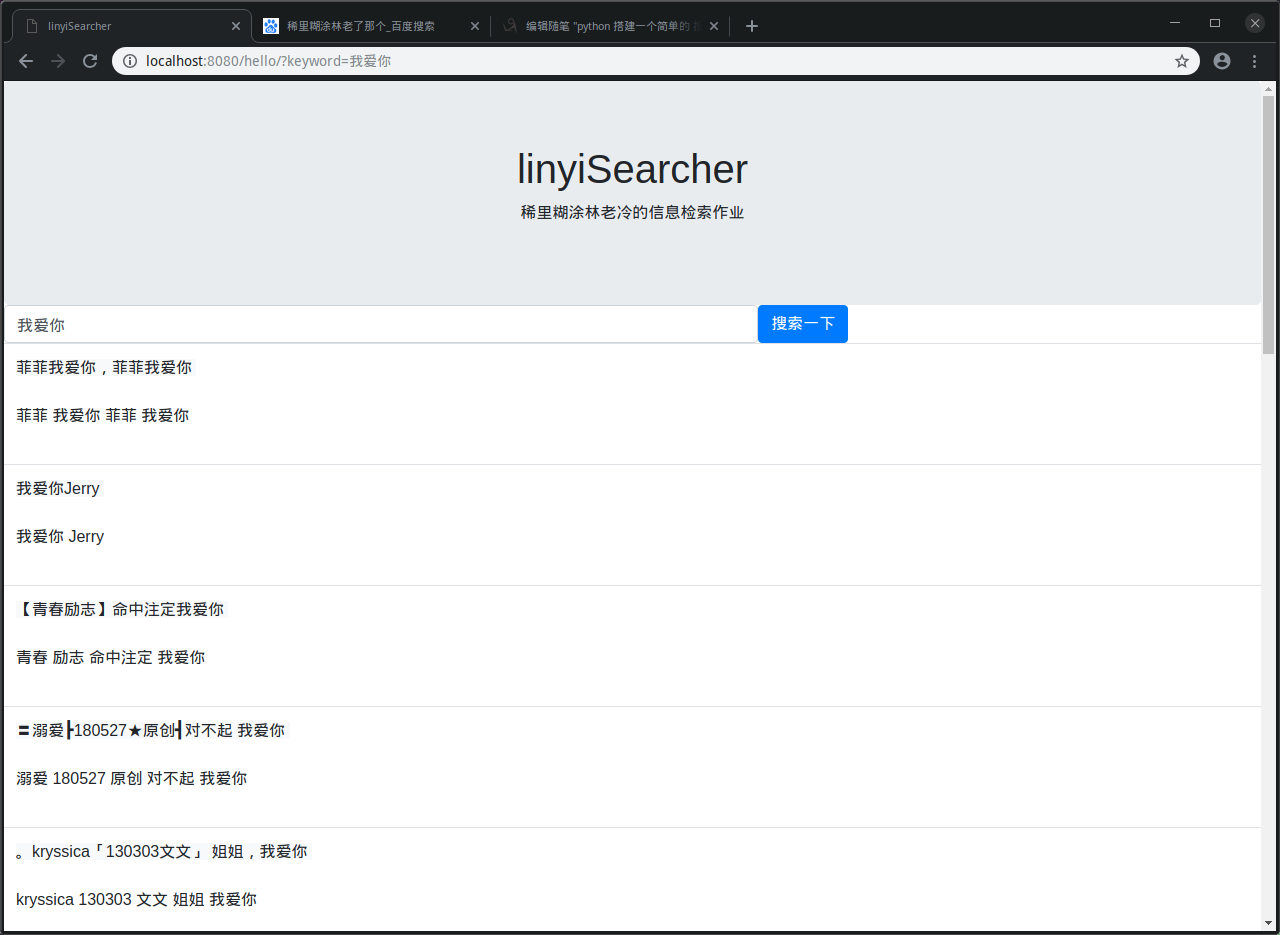
可以使用 pip install -r requirements.txt 一次性安装全部 -------- 一共分成3部分完成(后面有稍微详细点的解读) 1_spider.py 是一个爬虫, 爬取搜索引擎的语料库 2_clean_data_and_make_index 是对爬下来的数据 进行一些清晰工作,并且将数据存入数据库,建立索引 这里使用了 sqlite数据库,为了方便数据和项目一同携带 3_searcher.py 简易的web后端, 实现了 1 在网页输入搜索关键字, 在后端接收到关键字 2 对关键字进行分词 3 在索引中查找和关键字有关的文档 4 按照余弦相似度 对文档进行排序 5 把相近的文档展示出来 -------- 自己的知识储备和代码能力都捉襟见肘。 大神来看,还望海涵~欢迎大家批评指正共同学习 -------- 1 爬虫: 因为没有数据,只能写爬虫来做, 又只有自己的笔记本来跑,所以数据量也做不到非常大 在这里 写了1程序 爬了百度贴吧 娱乐明星分类下面的所有1级页面帖子的标题 当做语料库 爬取下来的数据存在了 ./data/database.csv 下 数据有2列 分别是 title 和url 2 数据清洗 并 建立索引: database.db 是一个sqlite数据库文件 首先将每个文档存到了数据库当中 数据库表为 page_info(id,keyword, title, url) id 自增主键 keyword: 存了该文档文字用jieba分词打散后的词汇列表(用空格隔开所有词语的字符串) title: 文档的文字内容 url: 该文档的网页链接 然后 把每个文档 使用jieba分词工具, 打散成词语,把所有词语放到一个集合中(集合能去重) 把所有词 存入数据库 建立索引 索引这样理解: 关键词: 你好 包含关键词的文档: <1,2,6,8,9> 表为 page_index(id, word, page_id) id: 自增 主键 word: 当前关键词 page_id: 包含该关键词的文档id 也就是page_info.id 3 实现检索: 首先 使用了bottle框架,是一个非常轻巧的web后端框架,实现了一个简单的web后端 前端页面使用了bootstrap 的css样式,,毕竟自己什么垃圾的一p 检索的实现过程: 1 后端拿到检索的关键词,用jieba分词 把拿到的语句打散成词汇 形成关键词keyword_list 2 在建立的索引表page_index中,搜关keyword_list中出现的词汇的page_id 3 在包含所有keyword的文档上 计算和keyword的余弦相似度,然后降序排列 4 返回给前端显示搜索结果 看看检索结果:


1_spider.py 爬虫的代码
import requests
from lxml import etree
import random
import COMMON
import os
from selenium import webdriver
import pandas as pd
"""
这里是建立搜索引擎的第一步
""" class Spider_BaiduTieba(object): def __init__(self):
self.start_url = "/f/index/forumpark?pcn=娱乐明星&pci=0&ct=1&rn=20&pn=1"
self.base_url = "http://tieba.baidu.com"
self.headers = COMMON.HEADERS
self.driver = webdriver.Chrome()
self.urlset = set()
self.titleset = set() def get(self, url):
header = random.choice(self.headers)
response = requests.get(url=url, headers=header, timeout=10)
return response.content def parse_url(self, url):
"""通过url 拿到xpath对象"""
print(url)
header = random.choice(self.headers)
response = requests.get(url=url, headers=header, timeout=10)
# 如果获取的状态码不是200 则抛出异常
assert response.status_code == 200
xhtml = etree.HTML(response.content)
return xhtml def get_base_url_list(self):
"""获得第一层url列表"""
if os.path.exists(COMMON.BASE_URL_LIST_FILE):
li = self.read_base_url_list()
return li
next_page = [self.start_url]
url_list = []
while next_page:
next_page = next_page[0]
xhtml = self.parse_url(self.base_url + next_page)
tmp_list = xhtml.xpath('//div[@id="ba_list"]/div/a/@href')
url_list += tmp_list
next_page = xhtml.xpath('//div[@class="pagination"]/a[@class="next"]/@href')
print(next_page)
self.save_base_url_list(url_list)
return url_list def save_base_url_list(self, base_url_list):
with open(COMMON.BASE_URL_LIST_FILE, "w") as f:
for u in base_url_list:
f.write(self.base_url + u + "\n") def read_base_url_list(self):
with open(COMMON.BASE_URL_LIST_FILE, "r") as f:
line = f.readlines()
li = [s.strip() for s in line]
return li def driver_get(self, url):
try:
self.driver.set_script_timeout(5)
self.driver.get(url)
except:
self.driver_get(url)
def run(self):
"""爬虫程序入口"""
# 爬取根网页地址
base_url_list = self.get_base_url_list()
data_list = []
for url in base_url_list:
self.driver_get(url)
html = self.driver.page_source
xhtml = etree.HTML(html)
a_list = xhtml.xpath('//ul[@id="thread_list"]//a[@rel="noreferrer"]')
for a in a_list:
title = a.xpath(".//@title")
url = a.xpath(".//@href")
if not url or not title or title[0]=="点击隐藏本贴":
continue
url = self.base_url + url[0]
title = title[0] if url in self.urlset:
continue data_list.append([title, url])
self.urlset.add(url)
data = pd.DataFrame(data_list, columns=["title,", "url"])
data.to_csv("./data/database.csv") if __name__ == '__main__':
s = Spider_BaiduTieba()
s.run()
2 清晰数据 和 建立索引部分代码 这里是notebook 完成的, 所以看起来有点奇怪
#%%
import pandas as pd
import sqlite3
import jieba
#%%
data = pd.read_csv("./data/database.csv")
#%%
def check_contain_chinese(check_str):
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return True
if "a" <= ch <= "z" or "A" <= ch <= "X":
return True
if "" <= ch <= "":
return True
return False
#%%
data2 = []
for d in data.itertuples():
title = d[1]
url = d[2]
cut = jieba.cut(title)
keyword = ""
for c in cut:
if check_contain_chinese(c):
keyword += " " + c
keyword = keyword.strip()
data2.append([title, keyword, url])
#%%
data3 = pd.DataFrame(data2, columns=["title", "keyword", "url"])
data3
#%%
data3.to_csv("./data/cleaned_database.csv", index=False)
#%%
for line in data3.itertuples():
title, keyword, url = line[1],line[2],line[3]
print(title)
print(keyword)
print(url)
break #%%
conn = sqlite3.connect("./data/database.db")
c = conn.cursor() # 创建数据库
sql = "drop table page_info;"
c.execute(sql)
conn.commit() sql = """
create table page_info(
id INTEGER PRIMARY KEY,
keyword text not null,
url text not null
);
"""
c.execute(sql)
conn.commit() # 创建索引表
sql = """
create table page_index(
id INTEGER PRIMARY KEY,
keyword text not null,
page_id INTEGER not null
);
"""
c.execute(sql)
conn.commit()
#%%
sql = "delete from page_info;"
c.execute(sql)
conn.commit() # 插入到数据库
i = 0
for line in data3.itertuples():
title, keyword, url = line[1],line[2],line[3]
sql = """
insert into page_info (url, keyword)
values('%s', '%s')
""" % (url, keyword)
c.execute(sql)
conn.commit()
i += 1
if i % 50 == 0:
print(i, len(data3)) sql = "delete from page_index;"
c.execute(sql)
conn.commit() sql = "select * from page_info;"
res = c.execute(sql)
res = list(res)
length = len(res) i = 0
for line in res:
pid, words, url = line[0], line[1], line[2]
words = words.split(" ")
for w in words:
sql = """
insert into page_index (keyword, page_id)
values('%s', '%s')
""" % (w, pid)
c.execute(sql)
conn.commit()
i += 1
if i % 100 == 0:
print(i, length)
#%% #%% #%%
titles = list(words)
colums = ["title", "url"] + titles
word_vector = pd.DataFrame(columns=colums)
word_vector
#%% #%%
data = pd.read_csv("./data/database.csv")
#%%
data
#%%
sql = "alter table page_info add title text;"
conn = sqlite3.connect("./data/database.db")
c = conn.cursor()
c.execute(sql)
conn.commit()
#%%
conn = sqlite3.connect("./data/database.db")
c = conn.cursor()
length = len(data)
i = 0
for line in data.itertuples():
pid = line[0]+1
title = line[1]
sql = "UPDATE page_info SET title = '%s' WHERE id = %s "%(title,pid)
try:
c.execute(sql)
conn.commit()
except:
continue
i += 1
if i % 50 == 0:
print(i, length) #%% #%%
3 web后端 完成检索功能代码
# coding=utf-8
import jieba
import sqlite3
from bottle import route, run, template, request, static_file, redirect @route('/static/<filename>')
def server_static(filename):
if filename == "jquery.min.js":
return static_file("jquery.min.js", root='./data/front/js/')
elif filename == "bootstrap.min.js":
return static_file("bootstrap.js", root='./data/front/js/')
elif filename == "bootstrap.min.css":
return static_file("bootstrap.css", root='./data/front/css/') @route('/')
def index():
return redirect("/hello/") @route('/hello/')
def index():
form = request.GET.decode("utf-8")
keyword = form.get("keyword", "")
cut = list(jieba.cut(keyword))
# 根据索引查询包含关键词的网页编号
page_id_list = get_page_id_list_from_key_word_cut(cut)
# 根据网页编号 查询网页具体内容
page_list = get_page_list_from_page_id_list(page_id_list)
# 根据查询关键字和网页包含的关键字,进行相关度排序 余弦相似度
page_list = sort_page_list(page_list, cut)
context = {
"page_list": page_list[:20],
"keyword": keyword
}
return template("./data/front/searcher.html", context) # 计算page_list中每个page 和 cut的余弦相似度
def sort_page_list(page_list, cut):
con_list = []
for page in page_list:
url = page[2]
words = page[1]
title = page[3]
vector = words.split(" ")
same = 0
for i in vector:
if i in cut:
same += 1
cos = same / (len(vector)*len(cut))
con_list.append([cos, url, words, title])
con_list = sorted(con_list, key=lambda i: i[0], reverse=True)
return con_list # 根据网页id列表获取网页详细内容列表
def get_page_list_from_page_id_list(page_id_list):
id_list = "("
for k in page_id_list:
id_list += "%s,"%k
id_list = id_list.strip(",") + ")"
conn = sqlite3.connect("./data/database.db")
c = conn.cursor()
sql = "select * " \
+ "from page_info " \
+ "where id in " + id_list + ";"
res = c.execute(sql)
res = [r for r in res]
return res # 根据关键词在索引中获取网页编号
def get_page_id_list_from_key_word_cut(cut):
keyword = "("
for k in cut:
if k == " ":
continue
keyword += "'%s',"%k
keyword = keyword.strip(",") + ")"
conn = sqlite3.connect("./data/database.db")
c = conn.cursor()
sql = "select page_id " \
+ "from page_index " \
+ "where keyword in " + keyword + ";"
res = c.execute(sql)
res = [r[0] for r in res]
return res if __name__ == '__main__':
run(host='localhost', port=8080)
python 搭建一个简单的 搜索引擎的更多相关文章
- Python实现一个简单三层神经网络的搭建并测试
python实现一个简单三层神经网络的搭建(有代码) 废话不多说了,直接步入正题,一个完整的神经网络一般由三层构成:输入层,隐藏层(可以有多层)和输出层.本文所构建的神经网络隐藏层只有一层.一个神经网 ...
- 用Python写一个简单的Web框架
一.概述 二.从demo_app开始 三.WSGI中的application 四.区分URL 五.重构 1.正则匹配URL 2.DRY 3.抽象出框架 六.参考 一.概述 在Python中,WSGI( ...
- 用nodejs搭建一个简单的服务器
使用nodejs搭建一个简单的服务器 nodejs优点:性能高(读写文件) 数据操作能力强 官网:www.nodejs.org 验证是否安装成功:cmd命令行中输入node -v 如果显示版本号表示安 ...
- 初学Node(六)搭建一个简单的服务器
搭建一个简单的服务器 通过下面的代码可以搭建一个简单的服务器: var http = require("http"); http.createServer(function(req ...
- 【netty】(2)---搭建一个简单服务器
netty(2)---搭建一个简单服务器 说明:本篇博客是基于学习慕课网有关视频教学.效果:当用户访问:localhost:8088 后 服务器返回 "hello netty"; ...
- 用Python编写一个简单的Http Server
用Python编写一个简单的Http Server Python内置了支持HTTP协议的模块,我们可以用来开发单机版功能较少的Web服务器.Python支持该功能的实现模块是BaseFTTPServe ...
- 使用gitblit搭建一个简单的局域网服务器
使用gitblit搭建一个简单的局域网服务器 1.使用背景 现在很多使用github管理代码,但是github需要互联网的支持,而且私有的git库需要收费.有一些项目的代码不能外泄,所以,搭建一个局域 ...
- Golang学习-第二篇 搭建一个简单的Go Web服务器
序言 由于本人一直从事Web服务器端的程序开发,所以在学习Golang也想从Web这里开始学起,如果对Golang还不太清楚怎么搭建环境的朋友们可以参考我的上一篇文章 Golang的简单介绍及Wind ...
- Prism for WPF 搭建一个简单的模块化开发框架 (一个节点)
原文:Prism for WPF 搭建一个简单的模块化开发框架 (一个节点) 这里我就只贴图不贴代码了,看看这个节点之前的效果 觉得做的好的地方可以范之前的文章看看 有好的建议也可以说说 填充数据 ...
随机推荐
- Web下文件上传下载的路径问题
工程结构
- linux笔记_day03
1.命令行展开{} mkdir -p a/b/{c,d/e} 2.-v verbose 详细的 3.touch touch - change file timestamps 4.stat 文件 显示 ...
- python中datetime与string的相互转换
>>> import datetime >>> value = '2016-10-30 01:48:31' >>> datetime.strpti ...
- ubuntu下tensorflow 报错 libcusolver.so.8.0: cannot open shared object file: No such file or directory
解决方法1. 在终端执行: export LD_LIBRARY_PATH=”$LD_LIBRARY_PATH:/usr/local/cuda/lib64” export CUDA_HOME=/usr/ ...
- 用python查看windows事件日志的方法(待后续研究)
#coding=utf8 import copy import ctypes from ctypes import byref, POINTER, cast, c_uint64, c_ulong, c ...
- Visual Studio 2017中的快捷键
Ctrl+Tab: 快速切换活动文件
- linux下快速安装jenkins
Linux下快速安装Jenkins 建议使用 FileZilla 工具简化以下步骤中移动.环境变量配置等步骤. 1 软件下载 l Java:jdk-7u17-linux-x64.tar.g ...
- jmeter之正则表达式
一.Jmeter关联的方式: Jmeter中关联可以在需要获取数据的请求上 右键-->后置处理器 选择需要的关联方式,如下图有很多种方法可以提取动态变化数据: 二.正则表达式提取器: 1.比如需 ...
- table下tbody滚动条与thead对齐的方法且每一列可以不均等
1 前言 table下tbody滚动条与thead对齐的方法,开始在tbody的td和thead的tr>td,对每一个Item加入百分比,结果是没对齐.也尝试了用bootstrap的col-md ...
- xcode 8 清除无用的打印
OS_ACTIVITY_MODE disable 虽然模拟器这样写能屏蔽掉无用的打印,但是在真机测试的时候什么都不会打印 Nslog 也打印不出来 , 这时候就要点掉 OS_ACTIVIT ...