海量数据找相同数,高配词,不重复的数,判断一个数是否存在,查询串,不同电话号码的个数,中位数,按照query频度排序,topk
这类题目,首先需要确定可用内存的大小,然后确定数据的大小,由这两个参数就可以确定hash函数应该怎么设置才能保证每个文件的大小都不超过内存的大小,从而可以保证每个小的文件都能被一次性加载到内存中。
1. 如何从大量的url中找到相同的url?
题目描述:给定a、b两个文件,各存放50亿个url,每个url各占64B,内存限制是4GB,请找出a、b两个文件共同的url。
分析:50亿个url,50亿*64 = 5GB*64=320GB,内存大小4GB,因此不可能一次性把所有的url都加载到内存中处理。需要用分治法把一个文件中的url按照某一特征分成多个文件,使得每个文件的内容都小于4GB,这样就可以把这个文件一次性读到内存中进行处理了。
主要思路:
(1)遍历文件a,对遍历到的url求hash(url)%500,根据计算结果把遍历到的url分别存储到a0,a1,...,a499(计算结果为i的url存储到文件ai中),这样每个文件的大小约为600MB。当某一个文件中url的大小超过2GB的时候,可以按照类似的思路把这个文件继续分为更小的子文件;
(2)按照(1)的方法遍历文件b,把文件b中的url分别存储到文件b0,b1,...,b499中;
(3)通过上面的划分,与ai中相同的url一定在bi中。由于ai与bi中所有的url的大小不会超过4GB,因此可以把它们同时读入到内存中进行处理。具体思路为:遍历文件ai,把遍历到的url存入hash_set中,接着遍历文件bi的url,如果这个url在hash_set中存在,那么说明这个url是这两个文件共同的url,如果这个url在hash_set中存在,那么说明这个url是这两个url是这两个文件共同的url,可以把这个url保存到另外一个单独的文件夹中。当把文件a0~a499都遍历完成后,就找到了两个文件共同的url。
2. 如何从大量数据中找出高频词?
题目描述:有一个1GB大小的文件,文件里面每一行是一个词,每个词的大小不超过16B,内存大小限制是1MB,要求返回频数最高的100个词。
分析:由于文件大小为1GB,而内存大小只有1MB,因此不可能一次把所有的词读入到内存中处理,因此也需要采用分治的方法,把一个大的文件分解成多个小的子文件,从而保证每个文件的大小都小于1MB,进而可以直接被读取到内存中处理,具体的思路为:
(1)遍历文件,对遍历到的每一个词,执行如下Hash操作:hash(x)%2000,将结果为i的词存放到ai中,通过这个分解步骤,可以使每个子文件的大小大约为400KB左右,如果这个操作后某个文件的大小超过1MB了,那么可以采用相同的方法对这个文件继续分解,直到文件的大小小于1MB为止。
(2)统计每个文件中出现频率最高的100个词。遍历文件中的所有词,对于遍历到的词,如果在字典中不存在,就把这个词对应的值+1,遍历完后可以非常容易地找出出现频率最高的100个词。
(3)维护一个小顶堆来找出所有词中出现频率最高的100个,具体方法为:遍历第一个文件,把第一个文件中出现频率最高的100个词构建成一个小顶堆(如果第一个文件中词的个数小于100,那么可以继续遍历第2个文件,直到构建好有100个结点的小顶堆为止)。继续遍历,如果遍历到的词的出现次数大于堆顶上词的出现次数,那么可以用新遍历到的词替换堆顶的词,然后重新调整这个堆为小顶堆。当遍历完所有文件后,这个小顶堆中的词就是出现频率最高的100个词。这一步也可以采用类似归并排序的方法把所有文件中出现频率最高的100个词排序,最终找出出现频率最高的100个词。
引申:在海量数据中找出重复次数最多的一个
前面的算法是求解topk,这道题目是求解top1,将上面的小顶堆变成一个变量就可以了。
3. 如何找出访问百度最多的IP?
题目描述:现有海量日志数据存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天访问BD次数最多的那个IP。
分析:先对文件遍历一遍,把一天访问BD的IP信息记录到一个单独的文件中。接下来用上一题的思路求解。需要将大文件分成小文件。以IPV4为例,一个IP地址占用32位,因此最多会有232=4G种取值情况。如果使用hash(IP)%1024值,那么把海量IP日志分别存储到1024个小文件中,这样,每个小文件最多包含4M个IP地址;如果使用2048个小文件,每个文件最多包含2M个IP地址。
4. 如何在大量的数据中找出不重复的整数?【位图法】
题目描述:在2.5亿个整数中找出不重复的整数,注意,内存不足以容纳这2.5亿个整数
思路1:使用hash,把这2.5亿个数划分到更小的文件中,从而保证每个文件的大小不超过可用的内存的大小。然后对于每个小文件而言,所有的数据可用一次性被加载到内存中,因此可以使用字典或set来找到每个小文件中不重复的数。当处理完所有的文件后就可以找出这2.5亿个整数中所有的不重复的数。
思路2:位图法
如果可用内存空间超过1GB就可以使用这种方法。具体思路为:假设整数占用4B(如果占用8B,那么求解思路类似,只不过需要占用更大的内存),4B也就是32位,可以表示的整数的个数为232。由于本题只查找不重复的数,而不关心具体数字出现的次数,因此可以分别使用2bit来表示各个数字的状态:用00表示这个数字没有出现过,01表示出现过1次,10表示出现了多次,11暂不使用。
根据上面的逻辑,在遍历这2.5亿个整数的时候,如果这个整数对应的位图中的位为00,那么修改为01,如果未01,修改为10,如果为10,就保持不变。这样当所有数据遍历完成后,可以再遍历一遍位图,位图中01的对应的数字就是没有重复的数字。
5. 如何在大量的数据中判断一个数是否存在?【分治法、位图法】
题目描述:在2.5亿个整数中找出不重复的整数,注意,内存不足以容纳这2.5亿个整数。
思路1:分治法
根据实际可用内存的情况,确定一个Hash函数,比如hash(value)%1000,通过这个Hash函数可以把这2.5亿个数字划分到1000个文件中(a1,a2,...,a1000),然后再对待查找的数字使用相同的Hash函数求出Hash值,假设计算出的Hash值为i,如果这个数存在,那么它一定在文件ai中。通过这种方式就能把题目的问题转换为文件ai中是否存在这个数。
思路2:位图法
以32位整数为例,它可以表示的数字的个数为232,可以申请一个位图,让每个整数对应位图中的一个bit,这样232个数需要位图的大小为512MB。具体:申请一个512MB大小的位图,并把所有的位都初始化为0;接着遍历所有的整数,对遍历到的数字,把相应位置上的bit位都初始化为0;接着遍历所有的整数,对遍历到的数字,把相应位置上的bit设置为1. 最后判断待查找的数对应的位图上的值是多少,如果是0,那么表示这个数字不存在,如果是1,那么表示这个数字存在。
6. 如何查询最热门的查询串?【分治法、字典法】
题目描述:搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询串的长度为1~255B。假设目前有1000万个记录(这些查询串的重复度比较高,虽然总数是1000万,但如果除去重复后,那么不超过300万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请统计最热门的10个查询词,要求使用的内存不超过1GB。
思路1:分治法
对字符串设置一个hash函数,通过这个hash函数把字符串划分到更多更小的文件中,从而保证每个小文件中的字符串都可以直接被加载到内存中处理,然后求出每个文件中出现次数最多的10个字符串;最后通过一个小顶堆统计出所有文件中出现次数最多的10个字符串。
但是由于需要对文件遍历两遍,而且hash函数也需要被调用1000万次,所以性能不是很好。
思路2:字典法
虽然字符串的总数比较多,但是字符串的种类不超过300万个,因此可以考虑把所有字符串出现的次数保存在一个字典中(键为字符串,值为字符串出现的次数)。字典所需要的空间为300万*(255+4)=3MB*259=777MB(其中,4表示用来记录字符串出现次数的整数占用4B)。由此可见1G的内存空间是足够用的。求解思路如下:
(1)遍历字符串,不在字典中,就存入字典,键为该字符串,值为1;如果在,就把对应的值加1,这一操作的时间复杂度为O(N),N为字符串的数量
(2)在前一步的基础上找出出现频率最高的10个字符串。可以通过小顶堆的方法来完成,遍历字典的前10个元素,并根据字符串出现的次数构建一个小顶堆,然后接着遍历字典,只要遍历到的字符串的出现次数大于堆顶字符串的出现次数,就用遍历的字符串替换堆顶的字符串,然后把堆调整为小顶堆。
(3)对所有剩余的字符串都遍历一遍,遍历完成后堆中的10个字符串就是出现次数最多的字符串,这一步的时间复杂度为O(NlogN)。
思路3:trie树法
方法2中使用字典来统计每个字符串出现的次数。当这些字符串有大量相同前缀的时候,可以考虑用trie树来统计字符串出现的次数。可以在树的结点中保存字符串出现的次数,0表示没有出现。具体实现方法为:在遍历的时候,在trie树中查找,如果找到,那么把结点中保存的字符串出现的次数加1,否则为这个字符串构建新的结点,构建完成后把叶子结点中字符串的出现次数设置为1.这样遍历完字符串后就可以知道每个字符串的出现次数,然后通过遍历这个树就可以找出出现次数最多的字符串。
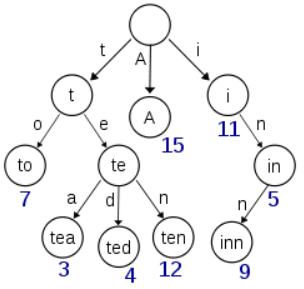
trie树经常被用来统计字符串的出现次数,它的另外一个大的用途就是字符串查找,判断是否有重复的字符串等。
7. 如何统计不同电话号码的个数?【位图法】
题目描述:已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
思路:位图法
对于本题而言,8位电话号码可以表示的范围为:0000 0000~9999 9999,如果用1bit表示一个号码,那么总共需要1亿个bit,总共需要大约100MB的内存。申请一个位图并初始化为0,然后遍历所有电话号码,把遍历到的电话号码对应的位图中的bit设置为1。完成后,如果bit值为1,那么表示这个电话号码在文件中存在,否则这个bit对应的电话号码在文件中不存在。所以bit值为1的数量即为不同电话号码的个数。
申请一个位图并初始化为0,然后遍历所有电话号码,把遍历到的电话号码对应的位图中的bit设置为1.当遍历完成后,如果bit值为1,那么表示这个电话号码在文件中存在,否则这个bit对应的电话号码在文件中不存在。所以bit值为1的数量即为不同电话号码的个数。
如何确定电话号码对应的是位图中的哪一位?
0000 0000对应位图最后1位:0x0000...0000 0001
0000 0001对应位图最后2位:0x0000...0000 0010(1向左移1位)
0000 0002对应位图最后3位:0x0000...0000 0100(1向左移2位)
0000 0012对应位图最后13位:0x0000...0001 0000 0000 0000(1向左移12位)
通常来说,位图都是通过一个整数数组来实现的(这里假设一个整数占用4B)。由此可以得出通过电话号码获取位图中对应位置的方法为(假设电话号码为P):
(1)用P/32计算出该电话号码在bitmap数组的下标(因为每个整数占用32bit,通过这个公式就可以确定这个电话号码需要移动多少个32位,也就是可以确定它对应的bit在数组中的位置)
(2)用P%32计算出该电话在整型数字中具体的bit的位置,也就是1这个数字对应的左移次数。因此可以通过把1向左移P%32位然后把的得到的值与这个数组中的值做或运算,这样就可以把这个电话号码在位图中对应的设置为1.
8. 如何从5亿个数中找出中位数?【双堆法】
题目描述:从5亿个数中找出中位数。数组排序后,位置在最中间的数值就是中位数。当样本数为奇数时,中位数=(N+1)/2;当样本数为偶数时,中位数为N/2与1+N/2的均值
分析:常规没有内存大小限制,就先排序然后找中位数,但是最好的排序算法的时间复杂度为O(NlogN),这里介绍另外一种求解中位数的算法:双堆法
思路1:双堆法:一个大顶堆 + 一个小顶堆【适合数据量比较小的情况,因为需要一次性将所有数据都加载到内存中】
特性1:大顶堆中最大的数值小于等于小顶堆最小的数
特性2:保证这两个堆中的元素个数的差不超过1

思路2:分治法

9. 如何按照query的频度排序?【归并排序】
题目描述:有10个文件,每个文件1GB,每个文件的每一行存放的都是用户的query,每个文件的query都有可能重复。要求按照query的频度排序。
思路1:hash_map法
如果query的重复率比较高,那么说明不同的query总数比较小,可以考虑把所有的query都加载到内存中的hash_map中,接着就可以对hash_map按照query出现的次数进行排序。
思路2:分治法
可以顺序遍历10个文件中的query,通过hash函数hash(query)%10把这些query划分到10个文件中,通过这样的划分,每个文件的大小为1GB左右。然后对每个划分后的小文件使用hash_map统计每个query出现的次数,然后根据出现次数排序,并把排序好的query以及出现次数写入到另外一个单独的文件中。这样针对每个文件,都可以得到一个按照query出现次数排序的文件。
接着对所有的文件按照query的出现次数进行排序,这里可以使用归并排序(由于无法把所有的query都读入到内存中,因此这里需要使用外排序)。
10. 如何找出排序前500的数?【堆排序】
题目描述:有20个数组,每个数组有500个元素,并且是有序排好的,现在如何在这20*500个数中找出排名前500的数?
思路:堆排序
(1)首先建立大顶堆,堆的大小为数组的个数,即20,把每个数组最大的值(数组第一个值)存放到堆中。Python中heapq是小顶堆,通过对输入和输出的元素分别取相反数来实现大顶堆的功能
(2)接着删除堆顶元素,保存到另外一个大小为500的数组中,然后向大顶堆插入删除的元素所在数组的下一个元素。
(3)重复第(1)、(2)个步骤,直到删除个数为最大的k个数,这里为500。
以下代码是个简化版求top5,假设有3个数组,每个数组有5个元素且有序,找出排名前5的值
import heapq
def getTop(data):
rowSize = len(data)
columnSize = len(data[0])
result = [None] * columnSize #保持一个最小堆,这个堆存放来自20个数组的最大数
heap = []
i = 0
while i < rowSize:
#数值,数值来源的数组,数值在数组中的次序index
arr = (-data[i][0],i,0)
heapq.heappush(heap,arr)
i += 1
num = 0
while num < columnSize:
d = heapq.heappop(heap)
result[num] = -d[0]
num += 1
if num >= columnSize:
break
arr = (-data[d[1]][d[2]+1],d[1],d[2]+1)
heapq.heappush(heap,arr)
return result #3个数组,每个数组有5个元素且有序,找出排名前5的值
data = [[29,17,14,2,1],[19,17,16,15,6],[30,25,20,14,5]]
print(getTop(data))
11. 海量数据中找出前k大的数
先拿10000个数建堆,然后一次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样,遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是O(mlogm),算法的时间复杂度为O(nmlogm)(n为10亿,m为10000)。
优化的方法:可以把所有10亿个数据分组存放,比如分别放在1000个文件中。这样处理就可以分别在每个文件的10^6个数据中找出最大的10000个数,合并到一起在再找出最终的结果。
参考文献:
海量数据找相同数,高配词,不重复的数,判断一个数是否存在,查询串,不同电话号码的个数,中位数,按照query频度排序,topk的更多相关文章
- 剑指offer:1.找出数组中重复的数(java版)
数组中重复的数:题目:找出数组中重复的数,题目描述:在一个长度为n的数组里的所有数字都在0到n-1的范围内.数组中某些数字是重复的,但不知道有几个数字是重复的.也不知道每个数字重复几次.请找出数组中任 ...
- Newtonsoft.Json C# Json序列化和反序列化工具的使用、类型方法大全 C# 算法题系列(二) 各位相加、整数反转、回文数、罗马数字转整数 C# 算法题系列(一) 两数之和、无重复字符的最长子串 DateTime Tips c#发送邮件,可发送多个附件 MVC图片上传详解
Newtonsoft.Json C# Json序列化和反序列化工具的使用.类型方法大全 Newtonsoft.Json Newtonsoft.Json 是.Net平台操作Json的工具,他的介绍就 ...
- 剑指offer第二版-3.数组中重复的数
面试题3:数组中重复的数 题目要求: 在一个长度为n的数组中,所有数字的取值范围都在[0,n-1],但不知道有几个数字重复或重复几次,找出其中任意一个重复的数字. 解法比较: /** * Copyri ...
- 找出数组中出现次数超过一半的数,现在有一个数组,已知一个数出现的次数超过了一半,请用O(n)的复杂度的算法找出这个数
找出数组中出现次数超过一半的数,现在有一个数组,已知一个数出现的次数超过了一半,请用O(n)的复杂度的算法找出这个数 #include<iostream>using namespace s ...
- 10,随机等概率的输出m个不重复的数
今天看到一段代码,可以从0.....n-1中随机等概率的输出m个不重复的数(n远远大于m).遂记录下来. 首先,产生随机数,不免要用到srand,rand函数.先简单介绍下两个函数. 1,void s ...
- sql语句查询表中重复字段以及显示字段重复条数
今天跟大家分享两条SQL语句,是关于查询某表中重复字段以及显示该字段的重复条数. 1.select * from 表名 where 列名 in (select 列名 from 表名 group by ...
- 算法面试题(python)——如何找出数组中出现一次的数
题目描述: 一个数组里,除了三个数是唯一出现的,其余的数都出现了偶数次,找出这三个数中任意一个.比如数组序列为[1,2,4,5,6,4,2],只有1.5.6这三个数字是唯一出现的,数字2.4均出现了偶 ...
- 随机指定范围内N个不重复的数
此为工具类,支持抽奖业务需求,具体实现见下方代码: package com.org.test; import java.util.ArrayList; import java.util.List; p ...
- python统计一个文本中重复行数的方法
python统计一个文本中重复行数的方法 这篇文章主要介绍了python统计一个文本中重复行数的方法,涉及针对Python中dict对象的使用及相关本文的操作,具有一定的借鉴价值,需要的朋友可以参考下 ...
随机推荐
- Android最全开发资源(申明:来源于网络)
Android最全开发资源(申明:来源于网络) 地址:http://www.jianshu.com/p/0c36302e0ed0?ref=myread
- POJ-1143(状态压缩)
Number Game Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 3432 Accepted: 1399 Descripti ...
- 树剖||树链剖分||线段树||BZOJ4034||Luogu3178||[HAOI2015]树上操作
题面:P3178 [HAOI2015]树上操作 好像其他人都嫌这道题太容易了懒得讲,好吧那我讲. 题解:第一个操作和第二个操作本质上是一样的,所以可以合并.唯一值得讲的点就是:第二个操作要求把某个节点 ...
- Java高级工程师面试题总结及参考答案
一.面试题基础总结 1. JVM结构原理.GC工作机制详解 答:具体参照:JVM结构.GC工作机制详解 ,说到GC,记住两点:1.GC是负责回收所有无任何引用对象的内存空间. 注意:垃圾回收回 ...
- int 4 bytes
http://waynewhitty.ie/blog-post.php?id=19 MySQL - INT(11) vs BIGINT(11) vs TINYINT(11) This seems to ...
- goreplay,tcpcopy
流量拷贝工具试用 https://github.com/buger/goreplaynginx mirror openresty 通过lua tcpcopy 支持 HTTP 请求的录制和重放,可以在线 ...
- [hyperscan][pkg-config] hyperscan 从0到1路线图
经过一系列的研究学习,知识储备之后,终于,可以开始研究hyperscan了. [knowledge][模式匹配] 字符匹配/模式匹配 正则表达式 自动机 [knowledge][perl][pcre] ...
- git bash 命名
git log -p -2 我们常用 -p 选项展开显示每次提交的内容差异,用 -2 则仅显示最近的两次更新. git diff HEAD git clean -df 恢复到最后一次提交的改动: gi ...
- 转:Java中Scanner类和BufferReader类之间的区别
原文地址:https://blog.csdn.net/u014717036/article/details/52227782 java.util.Scanner类是一个简单的文本扫描类,它可以解析基本 ...
- day2_python基础
1.变量: 用来存东西的,左边是名字,右边是值 2.python中的单引号.双信号.三引号 单引号和双引号和三引号没什么区别,用哪个都可以,如果定义字符串里面如果有单引号,则外面用双引号;如果字符串里 ...