hive的jdbc使用
①新建maven项目,加载依赖包
在pom.xml中添加
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.1</version>
</dependency>
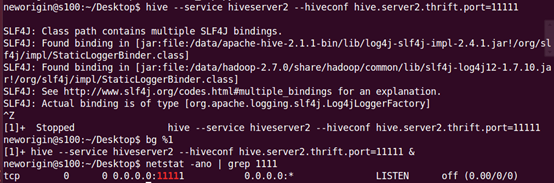
②启动hive的service,启动集群
(hive1.2.1版本以后需要使用hiveserver2启动)
hive –-service hiveserver2 –-hiveconf hive.server2.thrift.port=11111(开启服务并设置端口号)
③配置core-xite.xml
<property>
<name>hadoop.proxyuser.neworigin.groups</name>
<value>*</value>
<description>Allow the superuser oozie to impersonate any members of the group group1 and group2</description>
</property>
<property>
<name>hadoop.proxyuser.neworigin.hosts</name>
<value>*</value>
<description>The superuser can connect only from host1 and host2 to impersonate a user</description>
</property>
④编写java代码
- package com.neworigin.HiveTest1;
- import java.sql.Connection;
- import java.sql.DriverManager;
- import java.sql.SQLException;
- import java.sql.Statement;
- public class JDBCUtil {
- static String DriverName="org.apache.hive.jdbc.HiveDriver";
- static String url="jdbc:hive2://s100:11111/myhive";
- static String user="neworigin";
- static String pass="123";
- //创建连接
- public static Connection getConn() throws Exception{
- Class.forName(DriverName);
- Connection conn = DriverManager.getConnection(url,user,pass);
- return conn;
- }
- //创建命令
- public static Statement getStmt(Connection conn) throws SQLException{
- return conn.createStatement();
- }
- public void closeFunc(Connection conn,Statement stmt) throws SQLException
- {
- stmt.close();
- conn.close();
- }
- }
- package com.neworigin.HiveTest1;
- import java.sql.Connection;
- import java.sql.ResultSet;
- import java.sql.ResultSetMetaData;
- import java.sql.Statement;
- public class JDBCTest {
- public static void main(String[] args) throws Exception {
- Connection conn = JDBCUtil.getConn();//创建连接
- Statement stmt=JDBCUtil.getStmt(conn);//创建执行对象
- String sql="select * from myhive.employee";//执行sql语句
- String sql2="create table jdbctest(id int,name string)";
- ResultSet set = stmt.executeQuery(sql);//返回执行的结果集
- ResultSetMetaData meta = set.getMetaData();//获取字段
- while(set.next())
- {
- for(int i=1;i<=meta.getColumnCount();i++)
- {
- System.out.print(set.getString(i)+" ");
- }
- System.out.println();
- }
- System.out.println("第一条sql语句执行完毕");
- boolean b = stmt.execute(sql2);
- if(b)
- {
- System.out.println("成功");
- }
- }
- }
hive的jdbc使用的更多相关文章
- Hive的JDBC使用&并把JDBC放置后台运行
使用JDBC访问HIVE: 首先启动hive的JDBC服务. 进入hive的bin目录: 这样启动是启动到前台.如果 要想启动到后台需要用到Linux的相关命令. 我们先把其放到前台看下效果,之后再把 ...
- [Hive_5] Hive 的 JDBC 编程
0. 说明 Hive 的 JDBC 编程 1. hiveserver2 介绍 hiveserver2 是 Hive 的 JDBC 接口,用户可以连接此端口来连接 Hive 服务器 JDBC 驱动类为 ...
- Hive的JDBC
Hive 的JDBC 包含例子 https://cwiki.apache.org/confluence/display/Hive/HiveClient#HiveClient-JDBC HiveServ ...
- hive安装 jdbc链接hive
1. 下载hive安装包 2. 进入 conf 中 : cp hive-default.xml.template hive-site.xml, vi hive-site.xml 1)首行添加: ...
- Hive和Jdbc示例
重要:在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.使用下面命令进行开启:hive -service hiveserver & 1). 测试数据 user ...
- SPARK_sql加载,hive以及jdbc使用
sql加载 格式 或者下面这种直接json加载 或者下面这种spark的text加载 以及rdd的加载 上述记得配置文件加入.mastrt("local")或者spark://m ...
- Hive的JDBC访问
实现hive查询源码: String driverName = "org.apache.hive.jdbc.HiveDriver"; try { Class.forName(dri ...
- Hive:JDBC示例
1)本地目录/home/hadoop/test下的test4.txt文件内容(每行数据之间用tab键隔开)如下所示: [hadoop@master test]$ sudo vim test4.txt ...
- Hive的JDBC连接
首相要安装好hive 1.首先修改配置文件文件为hive 路径下的 conf/hive-sit.xml 将内容增加 <property> <name>hive.server2 ...
随机推荐
- activiti 5.13流程图连线名称不显示bug修复
使用modeler设计器,流程图连线名称是有显示的,但是运行结果却没显示.找到网上2遍文章,说是activiti框架中的一个bug,要修改 DefaultProcessDiagramGenerator ...
- P4492 [HAOI2018]苹果树
思路 题目要求的其实就是每种方案的权值之和(因为每种方案的概率相等) 所以自然想到要求所有的边对最终答案的贡献次数 考虑这一条边被经过了多少次,有这个子树内的点数*子树外的点数次,即\(k\times ...
- Basic Mathematics You Should Mastered
Basic Mathematics You Should Mastered 2017-08-17 21:22:40 1. Statistical distance In statistics, ...
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 论文笔记
Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 论文笔记 ECCV 2 ...
- vs添加webservice
VS2010中添加WebService注意的几个地方 添加web引用和添加服务引用有什么区别? 2.4.1 基础知识——添加服务引用与Web引用的区别 C#之VS2010开发Web Service V ...
- 【抓包】【Charles】
Mac抓包神器-----Charles Charles 是一款Mac上的HTTP代理服务器.HTTP监视器.反向代理服务器,可以让开发者监视查看所有连接互联网的HTTP通信,包括请求,响应和HTTP头 ...
- JS基础---常见的Bom对象
BOM(Browser Object Mode)浏览器对象模型,是Javascript的重要组成部分.它提供了一系列对象用于与浏览器窗口进行交互,这些对象通常统称为BOM. 一张图了解一下先 1.wi ...
- Adobe photoshop CS5(32位and64位)破解补丁
转载自:http://www.wusiwei.com 网上有很多photoshop cs5的永久序列号,但这个在2年前还能有用,现在一般都不行,序列号给你验证过了,然后过几秒钟还是会弹出要你输入序列号 ...
- 重装win7系统并激活
备份 大白菜制作启动盘 下载大白菜软件UEFI版(新电脑使用uefi版本,装机版支持的主板多) 选择默认安装 选择默认模式开始制作 下载iso镜像文件,复制到u盘(手动复制) 设置bios ...
- Boostrap本地导入js文件
我一般都是用CDN直接导入的,但是有时候需要自己添加一些功能进入,会用到本地导入.关于导入路径问题,做个笔记. 使用HBuilder,首先右键导入相应的js/cs文件 然后是常规——>文件系统 ...