Spark算子之aggregateByKey详解
一、基本介绍
rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值
3代表每次分完组之后的每个组的初始值。
seqFunc代表combine的聚合逻辑
每一个mapTask的结果的聚合成为combine
combFunc reduce端大聚合的逻辑
ps:aggregateByKey默认分组
二、源码
三、代码
from pyspark import SparkConf,SparkContext
from __builtin__ import str
conf = SparkConf().setMaster("local").setAppName("AggregateByKey")
sc = SparkContext(conf = conf) rdd = sc.parallelize([(,),(,),(,),(,),(,),(,)],) def f(index,items):
print "partitionId:%d" %index
for val in items:
print val
return items rdd.mapPartitionsWithIndex(f, False).count() def seqFunc(a,b):
print "seqFunc:%s,%s" %(a,b)
return max(a,b) #取最大值
def combFunc(a,b):
print "combFunc:%s,%s" %(a ,b)
return a + b #累加起来
'''
aggregateByKey这个算子内部肯定有分组
'''
aggregateRDD = rdd.aggregateByKey(, seqFunc, combFunc)
rest = aggregateRDD.collectAsMap()
for k,v in rest.items():
print k,v sc.stop()
四、详细逻辑
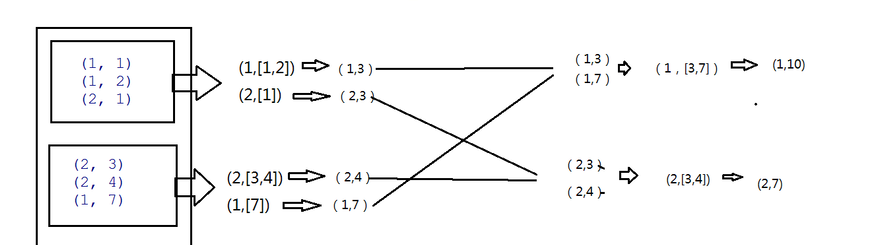
PS:seqFunc函数 combine篇。
3是每个分组的最大值,所以把3传进来,在combine函数中也就是seqFunc中第一次调用 3代表a,b即1,max(a,b)即3 第二次再调用则max(3.1)中的最大值3即输入值,2即b值 所以结果则为(1,3)
底下类似。combine函数调用的次数与分组内的数据个数一致。
combFunc函数 reduce聚合
在reduce端大聚合,拉完数据后也是先分组,然后再调用combFunc函数
五、结果

Spark算子之aggregateByKey详解的更多相关文章
- Spark算子篇 --Spark算子之aggregateByKey详解
一.基本介绍 rdd.aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值 3代表每次分完组之后的每个组的初始值. seqFunc代表combine的聚合逻 ...
- Spark算子篇 --Spark算子之combineByKey详解
一.概念 rdd.combineByKey(lambda x:"%d_" %x, lambda a,b:"%s@%s" %(a,b), lambda a,b:& ...
- [Spark内核] 第36课:TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本課主題 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Spark log4j日志配置详解(转载)
一.spark job日志介绍 spark中提供了log4j的方式记录日志.可以在$SPARK_HOME/conf/下,将 log4j.properties.template 文件copy为 l ...
- Spark中的分区方法详解
转自:https://blog.csdn.net/dmy1115143060/article/details/82620715 一.Spark数据分区方式简要 在Spark中,RDD(Resilien ...
- Spark技术内幕: Shuffle详解(一)
通过上面一系列文章,我们知道在集群启动时,在Standalone模式下,Worker会向Master注册,使得Master可以感知进而管理整个集群:Master通过借助ZK,可以简单的实现HA:而应用 ...
- Spark操作—aggregate、aggregateByKey详解
https://blog.csdn.net/u013514928/article/details/56680825 1. aggregate函数 将每个分区里面的元素进行聚合,然后用combine函数 ...
- Spark 核心概念 RDD 详解
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合,它只能通过其他RDD转换而创建,为此,RDD支持 ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
随机推荐
- 【zheng环境准备】安装activemq
1.下载http://activemq.apache.org/activemq-5140-release.html 2.移动到linux机器上 3.解压 tar -zxvf apache-active ...
- Spring.NET依赖注入框架学习--入门
Spring.NET依赖注入框架学习--入门 在学些Spring.net框架之前,有必要先脑补一点知识,比如什么是依赖注入?IOC又是什么?控制反转又是什么意思?它们与Spring.net又有什么关系 ...
- 使用JUnit测试预期异常
开发人员常常使用单元测试来验证的一段儿代码的操作,很多时候单元测试可以检查抛出预期异常( expected exceptions)的代码.在Java语言中,JUnit是一套标准的单元测试方案,它提供了 ...
- 【连载6】二手电商APP的导购功能与关系链机制分析
导读:得益于十余年来各种一手电商平台对市场与用户的教育以及共享.分享经济浪潮的兴起,互联网化的二手.闲置商品买卖.置换成为越来越普遍且简单可实现的生活方式. 第三章目录: 三.对比:主流二手电商竞品的 ...
- 让jQuery的contains方法不区分大小写
// NEW selector jQuery.expr[':'].Contains = function(a, i, m) { return jQuery(a).text().toUpperCase( ...
- bytes和str的区别与转换
bytes和str的区别 1.英文 b'alex'的表现形式与str没什么两样 2.中文 b'\xe4\xb8\xad'这是一个汉字在utf-8的bytes表现形式 3.中文 b'\xce\xd2'这 ...
- 恢复制作了系统盘的U盘
制作了系统盘的U盘通常容量会变得很小(比如用win32制作的系统盘) 此时在系统安装完成之后就要把U盘恢复,否则就无法正常使用了 步骤: 1.win+r打开程序搜索框,输入cmd打开dos窗口 2.在 ...
- 12.4 hdfs总结
启动hdfs 需要在namenode 节点 上 s11 启动yarn 需要在resourceManager 节点上 namenode, resourceManager 都需要在整个集群中都是可以无密登 ...
- hdu6397 Character Encoding 母函数解约束条件下多重集
http://acm.hdu.edu.cn/showproblem.php?pid=6397 原问题的本质是问m个元素的多重集S,每一种类型的对象至多出现n-1次的S的k组合的个数是多少? 等价于 x ...
- WinForm将一个窗体的值传到另一个窗体的listbox控件,C#
做arcgisengine二次开发,读取当前图层文件的字段值,别名,类型. 读取文件是在有地图图层的窗体(假设为Form1),由于窗体有限,所以想把读取的数据在另一个窗体(假设为Form2)显示出来 ...