Web 项目系列之浏览器机制(一)
目录:
——初步认识浏览器
——浏览器的渲染机制
——浏览器的缓存机制
正文:
初步认识浏览器
想来任何一位读者,对浏览器都不会陌生。除开IT相关人员常用的Chrome(谷歌,Google)、Firefox(火狐,Mozilla)、IE(微软),大多国内用户可能更熟悉诸如 百度浏览器、360浏览器、QQ浏览器、猎豹浏览器、UC浏览器……
(ps:以上排名不分先后)
OK,请打量您当前使用的浏览器——我们先认识一下浏览器的概念:
浏览器是指能够显示HTML文件内容,并让用户能够与这些文件进行交互的一种软件。
由上述概念可以清楚地认识到三个重点:
一能够显示HTML文件内容
再次请观察您当前所用的浏览器,请注意,你所看到浏览器里的内容——也就是包括这篇博客,它本质上就是一个HTML文件(这里要补充一点:现时代的浏览器,有些也能显示其他格式的文件)。
按下快捷键 F12,在Elements里所呈现的就是一个完整的HTML文件内容,浏览器通过解析它将内容渲染到浏览器界面上,就是读者目前所看到的网页内容。
二让能够与这些文件进行交互
交互直译为交流、互动。比如:点击导航进行页面跳转,在注册表单里填写内容然后提交,点击评论输入你的读后感,F12里对元素属性改写……
无论是PC端,还是移动端,大多数交互,我们称之为事件——在场各位,常用的点击事件(click/touch)、鼠标事件(mouse)、键盘事件(key)、改变文本事件(change)……(此处省略很多很多事件)总而言之,我们与浏览器的交互,大多都被称之为事件(注意,不是事故)。
三一种软件
之前的两点说的是浏览器的功能,这里要重点说明浏览器的构成。
如图:

即:
1用户界面:即读者目前所看到的浏览器界面,除开当前窗口显示的网页,其他的就是用户界面。(注意,不包括显示的网页)
2用户界面后端(UIBackend):功能上讲,能够绘制浏览器独有的弹窗会话、组合框等小窗口部件,对页面开发者来讲,也可以通过js脚本指令让它工作。
3网络:用来执行网络请求。浏览器通过它与网络层沟通,和web服务器建立联系。
4浏览器引擎:可以理解为渲染引擎和用户界面之间的中间层,把一方的指令传给另一方,让另一方对应工作。
5渲染引擎:解析HTML文件中的html标签和css样式规则,并将内容绘在窗口中。
6 Js解释器:解析并执行HTML文件中的JavaScript脚本代码。
7 Persistence(存储)/Storage(仓库):在硬盘上保存数据的本地仓库,是实现浏览器缓存的依赖。——一般来讲默认在浏览器目录里创建文件夹。
以上,是整个浏览器的功能组件构成。
小白可以这样理解:HTML文件内容==html(超文本标签语言)+css(修饰html元素的布局样式规则)+js(脚本指令代码)。
浏览器的渲染机制
了解过浏览器内部的实现结构,那么对于浏览器如何去请求html页面并将其解析,最后渲染到浏览器窗口内的这个过程,你就能通过下面这张图看个明白了。
如图:
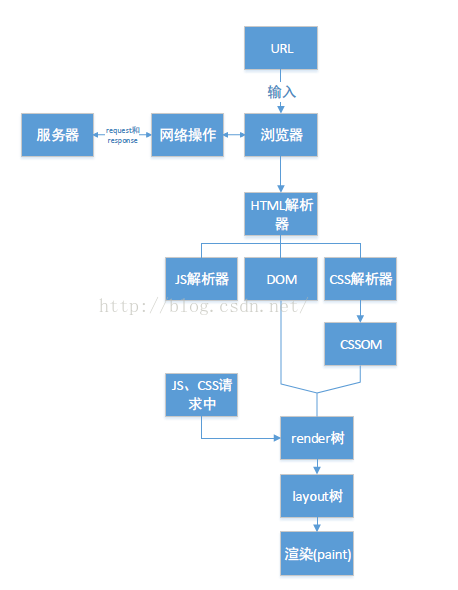
(该图取自csdn 博主a767536305的博客,以谷歌浏览器引擎 为基准 )
解读该图:
1、 用户输入一个URl地址请求后,请求成功,得到了返回的HTML。(这里请求发出后的实现过程,请往下看——浏览器缓存机制)
2、 浏览器的HTML解析器会将这个文件解析,并且构建成一棵DOM树。
3、 在构建DOM树的时候,遇到JS和CSS元素,HTML解析器就换将控制权转让给JS解析器或者是CSS解析器。(意思是常规情况下,同一时间只能调用一个解析器)
4、 JS解析器或者是CSS解析器解析完这个元素时候,HTML又继续解析下个元素,直到整棵DOM树构建完成。
5、 DOM树构建完之后,浏览器把DOM树中的一些不可视元素去掉,然后与CSSOM合成一棵render树。
6、 接着浏览器根据这棵render树,计算出各个节点(元素)在屏幕的位置。这个过程叫做layout,输出的是一棵layout树。
7、 最后浏览器根据这棵layout树,将页面渲染到屏幕上去。
浏览器的缓存机制
这里首先提两道面试题:当用户在浏览器地址栏里输入了www.baidu.com,按下回车后发生了什么?状态码304是什么意思?
3开头的状态码都是重定向的意思。304意思是请求重定向到本地浏览器缓存。
按下回车后,会先解析这个域名,转化为IP地址,发送请求。
我画了一个简单的请求图:

可以看到,我们的浏览器发送的请求会先在网络层进行一个判断。
如果浏览器本地缓存有效,就不用在请求服务器了~~(这样做的目的是 :节省了请求的时间,缩短了用户等待响应的时间,有效减少服务器被请求的次数。)
如果浏览器本地缓存无效,这个请求就会发送到服务端,服务端收到请求之后,要返回一个结果(响应),这个结果会原路返回到浏览器(返回的时候干了什么?读者不妨自己思考一下)。
——
请求有请求头,那么响应也自然有响应头。
服务端在响应头里设置了哪些东西应该被浏览器缓存,缓存的方式、存储的地点以及缓存的时间。
按照这个逻辑,我们再画一张响应图:
……算了画图太累了。自行脑补,或者查阅相关文章。
这里给一个不错的链接:
https://www.cnblogs.com/shixiaomiao1122/p/7591556.html
(浏览器缓存机制)
Ok,入门篇尽量使小白看得懂,因此太复杂的我们暂且先放一放。
浏览器的存储方式什么的后续篇章再讲。
本文介绍到这里,告一段落。
写在最后
本文属于Web项目的基础篇。
本文参考:
浏览器渲染机制:https://blog.csdn.net/cde7070/article/details/50619853
两张结构图为笔者个人灵魂画作。
本文中如有说法不当之处请留言指出,谢谢。
Web 项目系列之浏览器机制(一)的更多相关文章
- SSM框架开发web项目系列(二) MyBatis真正的力量
前言 上篇SSM框架环境搭建篇,演示了我们进行web开发必不可少的一些配置和准备工作,如果这方面还有疑问的地方,可以先参考上一篇“SSM框架开发web项目系列(一) 环境搭建篇”.本文主要介绍MyBa ...
- SSM框架开发web项目系列(三) MyBatis之resultMap及关联映射
前言 在上篇MyBatis基础篇中我们独立使用MyBatis构建了一个简单的数据库访问程序,可以实现单表的基本增删改查等操作,通过该实例我们可以初步了解MyBatis操作数据库需要的一些组成部分(配置 ...
- SSM框架开发web项目系列(五) Spring集成MyBatis
前言 在前面的MyBatis部分内容中,我们已经可以独立的基于MyBatis构建一个数据库访问层应用,但是在实际的项目开发中,我们的程序不会这么简单,层次也更加复杂,除了这里说到的持久层,还有业务逻辑 ...
- SSM框架开发web项目系列(七) SpringMVC请求接收
前言 在上篇Spring MVC入门篇中,我们初步了解了Spring MVC开发的基本搭建过程,本文将针对实际开发过程的着重点Controller部分,将常用的知识点罗列出来,并配以示例.在这之前,我 ...
- SSM框架开发web项目系列(六) SpringMVC入门
前言 我们最初的javaSE部分学习后,基本算是入门了,也熟悉了Java的语法和一些常用API,然后再深入到数据库操作.WEB程序开发,渐渐会接触到JDBC.Servlet/Jsp之类的知识,期间可能 ...
- SSM框架开发web项目系列(一) 环境搭建篇
前言 开发环境:Eclipse Mars + Maven + JDK 1.7 + Tomcat 7 + MySQL 主要框架:Spring + Spring MVC + Mybatis 目的:快速上手 ...
- web项目中的浏览器行为和服务器行为
package day10.think_about_path; import java.io.IOException; import javax.servlet.ServletException; i ...
- web项目直接在浏览器上访问不需要带.jsp,直接ip地址加项目名 在web.xml里配置
web.xml最上方 <welcome-file-list> <welcome-file> /view/login.jsp </welcome-file> < ...
- SSM框架开发web项目系列(四) MyBatis之快速掌握动态SQL
前言 通过前面的MyBatis部分学习,已经可以使用MyBatis独立构建一个数据库程序,基本的增删查改/关联查询等等都可以实现了.简单的单表操作和关联查询在实际开的业务流程中一定会有,但是可能只会占 ...
随机推荐
- 如何创建应用程序包(C ++)
备注 如果您要创建UWP应用程序包,请参阅使用MakeAppx.exe工具创建应用程序包. 了解如何使用打包API为Windows应用商店应用创建应用包. 如果要手动创建桌面应用程序包,还可以使用使用 ...
- windows的80端口被占用时的处理方法
1.利用jfinal极速开发时,显示异常,80端口被占用. 2.win+R输入cmd打开黑窗口. netstat -ano | findstr 3.发现进程被占用,输入以下指令停止http服务 net ...
- 我的那些年(9)~我来团队了,Mvc兴起了
回到目录 我的那些年(9)~我来团队了,Mvc兴起了 在一次后出办事后直接去面试了 面试就是答卷子 六里桥一个好地址 搬回老家了 在老婆的建议下学驾照了 拿到大专毕业证了 买车了 愉一切可以愉的时间学 ...
- C#委托、事件、线程
这是几个简单的例子,但是实际的开发中委托还还只在反射时用到过,事件的话只自己做了一次,并且还是特意去用的 ,实际上可以不用.线程的话,因为需要,所以用的会多点,这里主要是WS上的线程. 委托 在前面的 ...
- springcloud情操陶冶-初识springcloud
许久之前便听到了springcloud如雷贯耳的大名,但是不曾谋面,其主要应用于微服务的相关架构.笔者对微服务并不是很了解,但其既然比较出众,遂也稍微接触研究下 springcloud特性 sprin ...
- DSAPI 短域名服务
有时,需要将长域名转换为短域名,或是为了减少字符量,或是为了隐藏真实网址.在DSAPI中,集成了EPS-GS的短域名接口.该功能需要联接互联网,从EPS服务器获取. 代码 DSAPI.网络.短域名服务 ...
- 从零开始学安全(四十二)●利用Wireshark分析ARP协议数据包
wireshark:是一个网络封包分析软件.网络封包分析软件的功能是撷取网络封包,并尽可能显示出最为详细的网络封包资料.Wireshark使用WinPCAP作为接口,直接与网卡进行数据报文交换,是目前 ...
- .NET Core: 在.NET Core中进行单元测试
单元测试能够帮助开发人员确保所开发的模块.类以及类中的方法等的正确性,在项目开发过程中,及时进行单元测试能够避免不必要的BUG以及提高测试效率. 在本文中,我们会分别来学习如何使用MSTest.xUn ...
- Springboot2注解使用Mybatis动态SQL
1.简单SQL使用 //从***数据表获取统计数据 @Select("select count(*) from issues where issue_type = #{type}" ...
- Django学习之十: staticfile 静态文件
目录 Django学习之十: staticfile 静态文件 理解阐述 静态文件 Django对静态文件的处理 其它方面 总结 Django学习之十: staticfile 静态文件 理解阐述 ...