Python基础-week04
一.装饰器
1.定义:本质是函数,装饰其他函数就是为其他函数添加附加功能。
2.原则:a.不能修改被装饰的函数的源代码 b.不能修改被装饰的函数的调用方式。
实例1:装饰器的使用
#Author:http://www.cnblogs.com/Jame-mei
#装饰器的使用
import time def timmer(func):
def warpper(*args,**kwargs):
start_time=time.time()
func()
stop_time=time.time()
print ("The func run time is %s" %(stop_time-start_time))
return warpper @timmer #等于 time1=timmer(time1),最后再time1()
def time1():
time.sleep(2)
print ("in the test1...............") time1()
实例1:装饰器的使用
实例2:一个函数调用另一个函数,匿名函数的使用
#Author:http://www.cnblogs.com/Jame-mei def foo():
print ("in the foo")
bar() #foo() 调用bar报错,因为要将foo()放到函数的后面,因为Python是解释型语言,需要逐行翻译! def bar(): #bar()可以放在调用函数的foo的后面
print ("in the bar") calc=lambda x:x*3 #匿名函数的使用 foo() print (calc(10))
实例2:调用其他函数和匿名函数的使用
3.实现装饰器的知识储备:
1).函数即"变量",见下图:
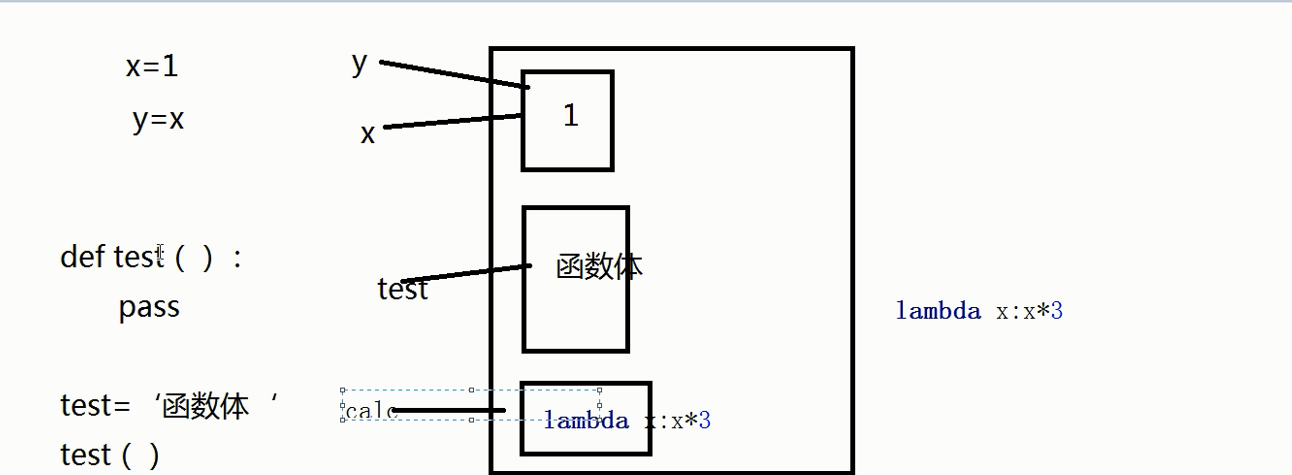
其中变量名x,y和函数名test ,本质他们都是内存中的一个地址,所以函数和变量一样,只不过函数通过()来调用。
2).高阶函数
a.把一个函数名当作实参传给另外一个函数(在不修改被装饰函数的源代码的情况下,为其添加附加功能)
b.返回值中包含函数名(不修改函数的调用方式)
实例3:高阶函数的2个功能
#Author:http://www.cnblogs.com/Jame-mei
#高阶函数的2个功能 import time #1.把一个函数当作实参传给另外一个函数
def bar():
time.sleep(2.5)
print ('in the bar') def foo(func):
start_time=time.time()
func() #bar 的运行时间
stop_time=time.time()
print ("the func run time is %s" %(stop_time-start_time)) #foo() 原来的调用方式
foo(bar)
------------------------------------output--------------------------------------------------- in the bar
the func run time is 2.500143051147461 Process finished with exit code 0
把一个函数名当作另一个函数的实参
#Author:http://www.cnblogs.com/Jame-mei
#高阶函数的2个功能
#2.返回值中包含函数 def bar():
time.sleep(2.5)
print ('in the bar') def test2(func):
print (func) #打印的是内存地址
return func #返回之中包含函数!! bar=test2(bar)
bar() #代表bar(),打印print
返回值中包含函数名
3).嵌套函数和作用域
高阶函数+嵌套函数=装饰器
def foo():
print ('in the foo()')
def bar(): #在函数内定义另一个函数def ,相当于foo()函数的局部变量。
print ('in the bar()') bar() #局部变量只能在内部调用!! foo()
a.函数的嵌套
#Author:http://www.cnblogs.com/Jame-mei
#嵌套函数的全局作用域和局部作用域
x=0
def grandpa():
x=1
def dad():
x=2
def son():
x=3
print (x)
son()
dad() grandpa()
print (x)
b.函数的作用域
def bar2():
print ('in the bar2') def foo2():
print ('in the foo2')
bar2() #这叫函数的调用,这里要区别与函数的嵌套!
c.函数的嵌套和调用的区别
#Author:http://www.cnblogs.com/Jame-mei
import time
#写一个装饰器,用高阶函数+函数嵌套来实现 def timmer(func):
def deco(*args,**kwargs): #*args,**kwargs,无论被装饰的函数有多少参数都可以代替。
start_time=time.time()
func(*args,**kwargs)
stop_time=time.time()
print ('the func run time is %s'%(stop_time-start_time)) return deco #高阶函数返回一个函数名 @timmer # 等于test1=timmer(test1)
def test1():
time.sleep(1.123)
print ('in the test1...') @timmer
def test2(name,age):
time.sleep(2.256)
print ('in the test2',name,age) #用手动的方式来实现装饰器的功能,@timmer的方式来装饰test1(),test2()
# test1=timmer(test1) #把函数名当作实参,传给另一个函数
# test2=timmer(test2) # print (test1)
# print (test2) test1() test2('Alex',22)
d.带参数的装饰器(高阶函数和嵌套函数)
#Author:http://www.cnblogs.com/Jame-mei
user,passwd='alex','abc123'
def auth(auth_type):
def outwrapper(func):
def wrapper(*args, **kwargs):
if auth_type=='local':
username = input("username:").strip()
password = input("password:").strip()
if user == username and passwd == password:
print("\033[32;1m User has passwd authentication \033[0m")
res = func(*args, **kwargs)
print('------------->after authentication')
return res
else:
exit("\033[31;1m Ivalid username or password \033[Om")
elif auth_type=='ldap':
print ('This ldap is disable...')
return wrapper
return outwrapper
def index():
print ('welcome in the index page')
@auth(auth_type='local')
def home():
print ('welcome %s home page' %user)
return 'return from home!'
@auth(auth_type='ldap')
def bbs():
print('welcome %s bbs page' %user)
#调用,index不用装饰器,home打印返回值,bbs来验证local和ldap的差别
index()
print(home())
bbs()
e.判断权限的装饰器
4.Alex的装饰器之旅
1):装饰器之旅1
#Author:http://www.cnblogs.com/Jame-mei #1.模版
'''def home():
print("---首页----") def america():
print("----oumei专区----") def japan():
print("----rihan专区----") def henan():
print("----北上广深专区----") 更改需求: 想收费得先让其进行用户认证,认证通过后,再判定这个用户是否是VIP付费会员就可以了,是VIP就让看,不是VIP就不让看就行了呗。
你觉得这个需求很是简单,因为要对多个版块进行认证,那应该把认证功能提取出来单独写个模块,然后每个版块里调用 就可以了,
与是你轻轻的就实现了下面的功能 。
'''
#更改后代码如下:
user_status=False #如果认证后,修改为True def login():
_username='alex' #假设db中有这2个账号
_password='abc123'
global user_status
if user_status==False:
username=input('please input your username:')
password=input('please input your password:') if username==_username and password==_password:
print ('welcome %s login!' %username)
else:
print ('input username or password error!')
else:
print ('用户已登陆,请勿重复操作!') def home():
print("---首页----") def america():
login() #执行前加上验证
print("----oumei专区----") def rihan():
print("----rihan专区----") def bsgs():
login() #执行前加上验证
print("----北上广深专区----") home()
america()
bsgs()
简单的改造项目和验证
此时你信心满满的把这个代码提交给你的TEAM LEADER审核,没成想,没过5分钟,代码就被打回来了。
TEAM LEADER给你反馈是,我现在有很多模块需要加认证模块,你的代码虽然实现了功能,但是需要更改需要加认证的各个模块的代码,
这直接违反了软件开发中的一个原则“开放-封闭”原则,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展,即:
封闭:已实现的功能代码块不应该被修改
开放:对现有功能的扩展开放 这个原则你还是第一次听说,我擦,再次感受了自己这个野生程序员与正规军的差距,BUT ANYWAY,老大要求的这个怎么实现呢?
如何在不改原有功能代码的情况下加上认证功能呢?你一时想不出思路,只好带着这个问题回家继续憋,媳妇不在家,去隔壁老王家串门了,
你正好落的清静,一不小心就想到了解决方案,不改源代码可以呀, 你师从沙河金角大王时,记得他教过你,高阶函数,就是把一个函数当做一个参数传给另外一个函数,当时大王说。
有一天,你会用到它的,没想到这时这个知识点突然从脑子 里蹦出来了,我只需要写个认证方法,每次调用 需要验证的功能时,
直接 把这个功能 的函数名当做一个参数 传给 我的验证模块不就行了么,哈哈,机智如我,如是你啪啪啪改写了之前的代码
2):装饰器之旅2
#Author:http://www.cnblogs.com/Jame-mei user_status = False # 用户登录了就把这个改成True def login(func): # 把要执行的模块从这里传进来
_username = "alex" # 假装这是DB里存的用户信息
_password = "abc!23" # 假装这是DB里存的用户信息
global user_status if user_status == False:
username = input("user:")
password = input("pasword:") if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!") if user_status == True:
func() # 看这里看这里,只要验证通过了,就调用相应功能 def home():
print("---首页----") def america():
# login() #执行前加上验证
print("----欧美专区----") def japan():
print("----日韩专区----") def henan():
# login() #执行前加上验证
print("----河南专区----") home()
login(america) # 需要验证就调用 login,把需要验证的功能 当做一个参数传给login # home()
# america()
login(henan)
将函数名当作实参
你改变了调用方式呀, 想一想,现在没每个需要认证的模块,都必须调用你的login()方法,并把自己的函数名传给你,人家之前可不是这么调用 的, 试想,如果 有100个模块需要认证,那这100个模块都得更改调用方式,这么多模块肯定不止是一个人写的,让每个人再去修改调用方式 才能加上认证,你会被骂死的。
3):装饰器之旅3
home()america = login(america) #你在这里相当于把america这个函数替换了henan = login(henan)#那用户调用时依然写america() |
但问题在于,还不等用户调用 ,你的america = login(america)就会先自己把america执行了呀。。。。,你应该等我用户调用 的时候 再执行才对呀,不信我试给你看。。。
老王:哈哈,你说的没错,这样搞会出现这个问题? 但你想想有没有解决办法 呢?
你:我擦,你指的思路呀,大哥。。。我哪知道 下一步怎么走。。。
老王:算了,估计你也想不出来。。。 学过嵌套函数没有?
你:yes,然后呢?
老王:想实现一开始你写的america = login(america)不触发你函数的执行,只需要在这个login里面再定义一层函数,第一次调用america = login(america)只调用到外层login,这个login虽然会执行,但不会触发认证了,因为认证的所有代码被封装在login里层的新定义 的函数里了,login只返回 里层函数的函数名,这样下次再执行america()时, 就会调用里层函数啦。详见代码:
def login(func): #把要执行的模块从这里传进来
def inner():#再定义一层函数
_username = "alex" #假装这是DB里存的用户信息
_password = "abc!23" #假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
func() # 看这里看这里,只要验证通过了,就调用相应功能
return inner #用户调用login时,只会返回inner的内存地址,下次再调用时加上()才会执行inner函数
还可以更简单
可以把下面代码去掉
america = login(america) #你在这里相当于把america这个函数替换了
只在你要装饰的函数上面加上下面代码
@login
def america():
#login() #执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
@login
def henan():
#login() #执行前加上验证
print("----河南专区----")
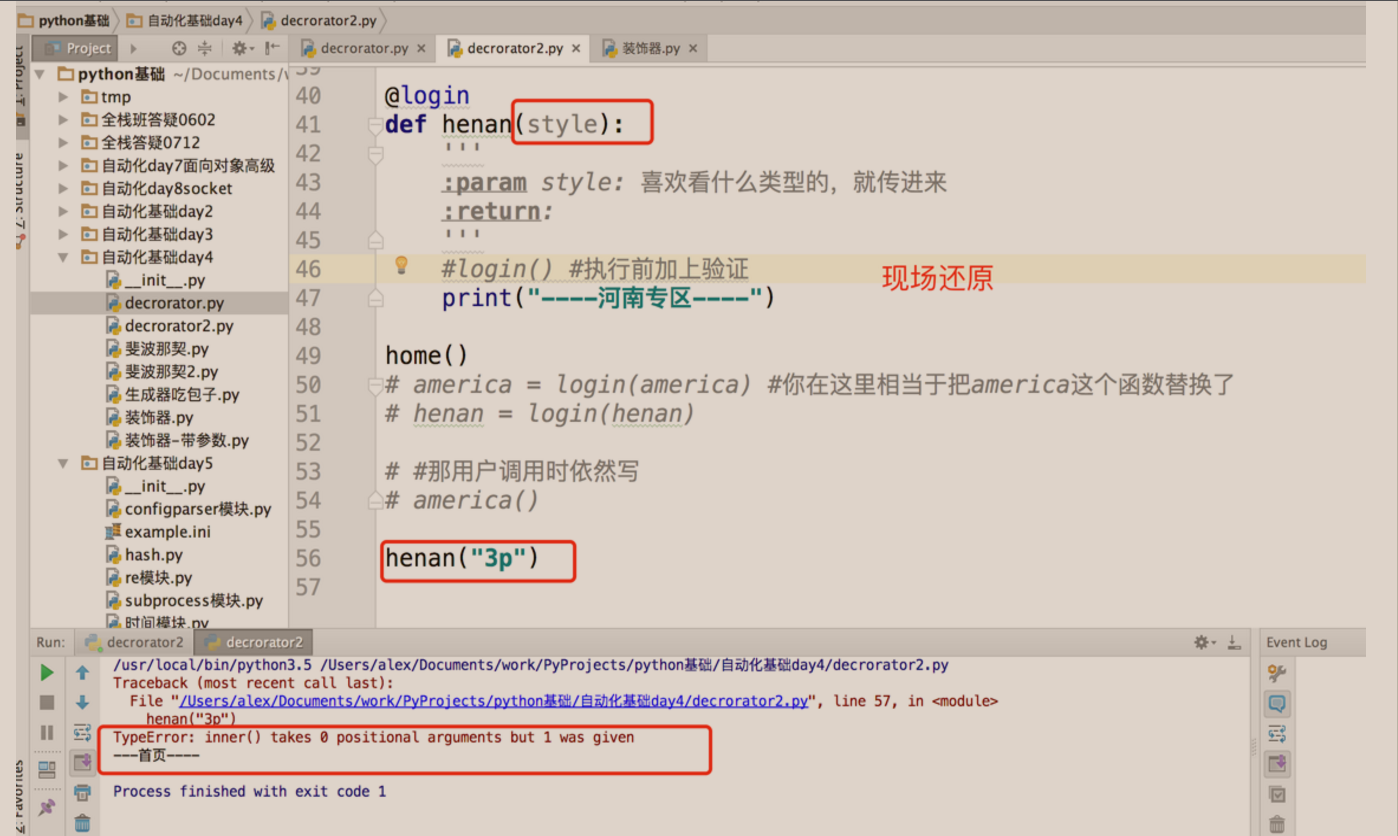
你:老王,老王,怎么传个参数就不行了呢?
老王:那必然呀,你调用henan时,其实是相当于调用的login,你的henan第一次调用时henan = login(henan), login就返回了inner的内存地址,第2次用户自己调用henan("3p"),实际上相当于调用的时inner,但你的inner定义时并没有设置参数,但你给他传了个参数,所以自然就报错了呀
你:但是我的 版块需要传参数呀,你不让我传不行呀。。。
老王:没说不让你传,稍做改动便可。
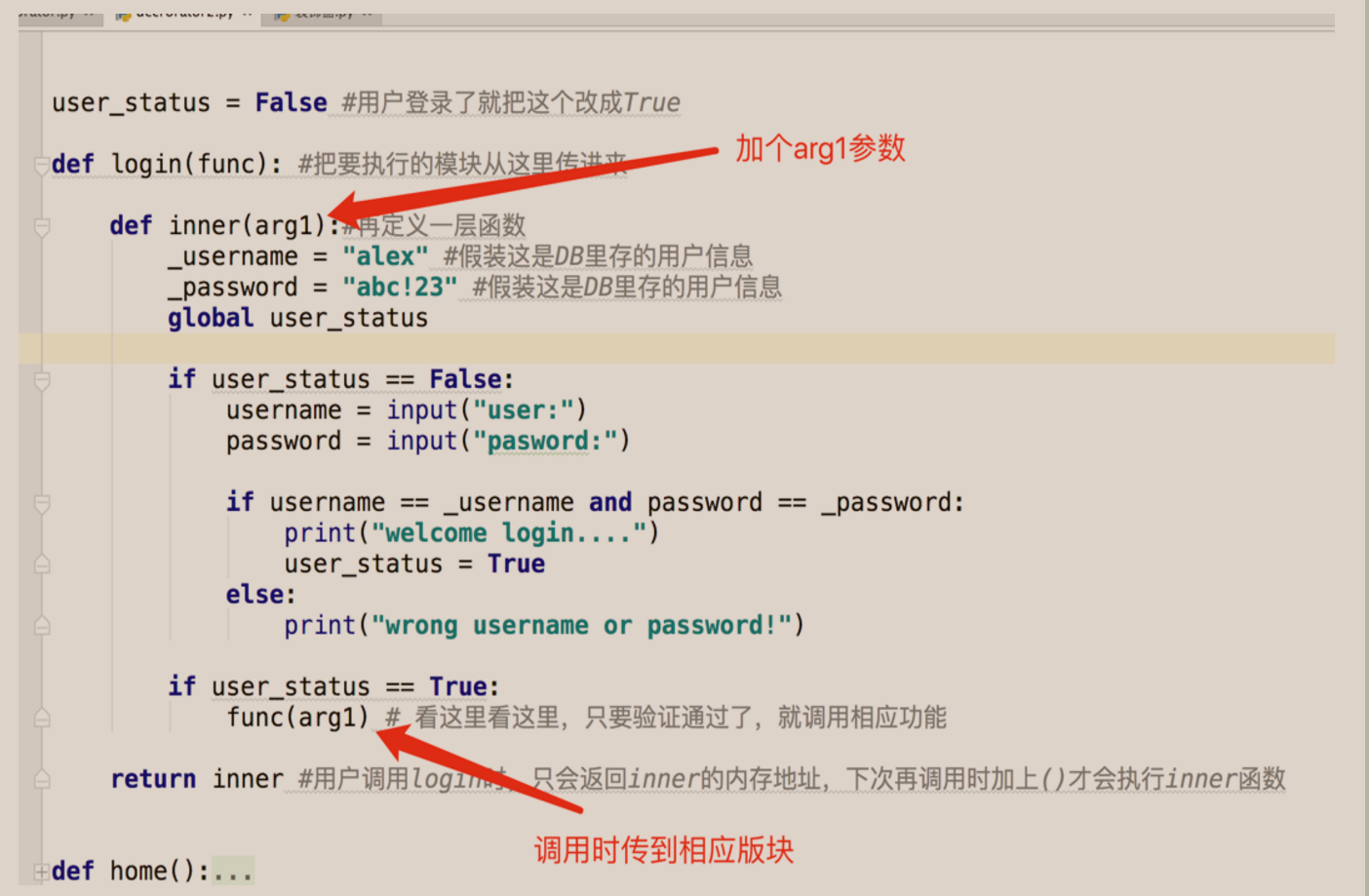
老王:你再试试就好了 。
你: 果然好使,大神就是大神呀。 。。 不过,如果有多个参数呢?
老王:。。。。老弟,你不要什么都让我教你吧,非固定参数你没学过么? *args,**kwargs...
你:噢 。。。还能这么搞?,nb,我再试试。
完全遵循开放-封闭原则,最终代码如下 。
user_status = False #用户登录了就把这个改成True
def login(func): #把要执行的模块从这里传进来
def inner(*args,**kwargs):#再定义一层函数
_username = "alex" #假装这是DB里存的用户信息
_password = "abc!23" #假装这是DB里存的用户信息
global user_status
if user_status == False:
username = input("user:")
password = input("pasword:")
if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!")
if user_status == True:
func(*args,**kwargs) # 看这里看这里,只要验证通过了,就调用相应功能
return inner #用户调用login时,只会返回inner的内存地址,下次再调用时加上()才会执行inner函数
def home():
print("---首页----")
@login
def america():
#login() #执行前加上验证
print("----欧美专区----")
def japan():
print("----日韩专区----")
# @login
def henan(style):
'''
:param style: 喜欢看什么类型的,就传进来
:return:
'''
#login() #执行前加上验证
print("----河南专区----")
home()
# america = login(america) #你在这里相当于把america这个函数替换了
henan = login(henan)
# #那用户调用时依然写
america()
henan("3p")
遵循开放-封闭原则
要允许用户选择用qq\weibo\weixin认证,此时的你,已深谙装饰器各种装逼技巧,轻松的就实现了新的需求:
#_*_coding:utf-8_*_ user_status = False #用户登录了就把这个改成True def login(auth_type): #把要执行的模块从这里传进来
def auth(func):
def inner(*args,**kwargs):#再定义一层函数
if auth_type == "qq":
_username = "alex" #假装这是DB里存的用户信息
_password = "abc!23" #假装这是DB里存的用户信息
global user_status if user_status == False:
username = input("user:")
password = input("pasword:") if username == _username and password == _password:
print("welcome login....")
user_status = True
else:
print("wrong username or password!") if user_status == True:
return func(*args,**kwargs) # 看这里看这里,只要验证通过了,就调用相应功能
else:
print("only support qq ")
return inner #用户调用login时,只会返回inner的内存地址,下次再调用时加上()才会执行inner函数 return auth def home():
print("---首页----") @login('qq')
def america():
#login() #执行前加上验证
print("----欧美专区----") def japan():
print("----日韩专区----") @login('weibo')
def henan(style):
'''
:param style: 喜欢看什么类型的,就传进来
:return:
'''
#login() #执行前加上验证
print("----河南专区----") home()
# america = login(america) #你在这里相当于把america这个函数替换了
#henan = login(henan) # #那用户调用时依然写
america() # henan("3p") 带参数的装饰器
带权限验证的方式
更多装饰器黄段子,请访问导师Alex:http://www.cnblogs.com/alex3714/articles/5765046.html
5.装饰器的练习操作(重要)
1):无参装饰器
import time def timmer(func):
# func=index
def wrapper(*args,**kwargs):
start=time.time()
res=func(*args,**kwargs)
stop=time.time()
print('run time is %s' %(stop - start))
return res
return wrapper def outter(func):
def inner(*args,**kwargs):
res=func(*args,**kwargs)
return res
return inner @timmer #index=timmer(index)
def index():
print('welcome to index page')
time.sleep(3) @timmer #home=timmer(home)
def home(name):
print('welecom %s ' %name)
time.sleep(2)
return 123 index() # wrapper()
res=home('egon') # res=wrapper('egon')
无参数装饰器
2):认证功能装饰器实现
import time
current_userinfo={'user':None}
def outter(func):
def wrapper(*args,**kwargs):
if current_userinfo['user']:
return func(*args,**kwargs)
user=input('please input you username: ').strip()
pwd=input('please input you password: ').strip()
if user == 'egon' and pwd == '':
print('login successfull')
# 保存登录状态
current_userinfo['user']=user
res=func(*args,**kwargs)
return res
else:
print('user or password err')
return wrapper
@outter # index=outter(index)
def index():
print('welcome to index page')
time.sleep(3)
@outter #home=outter(home)
def home(name):
print('welecom %s ' %name)
time.sleep(2)
return 123
index() # wrapper()
res=home('egon') # res=wrapper('egon')
认证功能无参装饰器
3):一个函数添加多个装饰器的生效顺序
import time
current_userinfo={'user':None}
def timmer(func): #func=最原始的index指向的内存地址
def wrapper2(*args,**kwargs):
print('wrapper2.....')
start=time.time()
res=func(*args,**kwargs) # func=最原始的index指向的内存地址
stop=time.time()
print('run time is %s' %(stop - start))
return res
return wrapper2
def outter(func): # func=wrapper2
def wrapper1(*args,**kwargs):
print('wrapper1.....')
if current_userinfo['user']:
return func(*args,**kwargs)
user=input('please input you username: ').strip()
pwd=input('please input you password: ').strip()
if user == 'egon' and pwd == '':
print('login successfull')
# 保存登录状态
current_userinfo['user']=user
res=func(*args,**kwargs) # func=wrapper2
return res
else:
print('user or password err')
return wrapper1
# 解释语法的时候应该自下而上
# 执行时则是自上而下
# 可以连续写多个装饰器,处于最顶层的装饰器先执行
@outter # index=outter(wrapper2) # index=wrapper1
@timmer # timmer(最原始的index指向的内存地址) ==>wrapper2
def index():
print('welcome to index page')
time.sleep(3)
index() #wrapper1()
多个装饰器装饰同一个函数
4):有参装饰器的使用
import time
current_userinfo={'user':None}
def auth(engine='file'):
def outter(func): #func=最原始的index
def wrapper(*args,**kwargs):
if engine == 'file':
if current_userinfo['user']:
return func(*args,**kwargs)
user=input('please input you username: ').strip()
pwd=input('please input you password: ').strip()
if user == 'egon' and pwd == '':
print('login successfull')
# 保存登录状态
current_userinfo['user']=user
res=func(*args,**kwargs)
return res
else:
print('user or password err')
elif engine == 'mysql':
print('mysql 的认证机制')
elif engine == 'ldap':
print('ldap 的认证机制')
else:
print('不支持该engine')
return wrapper
return outter
@auth(engine='mysql') #@outter # index=outter(最原始的index) # index= wrapper
def index():
print('welcome to index page')
time.sleep(3)
@auth(engine='ldap')
def home(name):
print('welecom %s ' %name)
time.sleep(2)
return 123
index() #warpper()
home('egon') #wrapper('egon')
有参的装饰器的使用
5):wraps装饰器使用
import time
from functools import wraps def timmer(func):
@wraps(func)
def wrapper(*args,**kwargs):
start=time.time()
res=func(*args,**kwargs)
stop=time.time()
print('run time is %s' %(stop - start))
return res
# wrapper.__doc__ = func.__doc__
# wrapper.__name__= func.__name__
return wrapper @timmer
def index():
"""
这是一个index函数
:return:
"""
print('welcome to index page')
time.sleep(1)
return 123 print(help(index)) # index.__doc__ print(index.__name__) # res=index()
# print(res)
wraps实现伪装函数的某些特性
二.迭代器 & 生成器
1.迭代器
*什么是迭代器?
迭代是一个重复的过程,每一次重复都是基于上一次结果二进行的。
#单纯的重复并不是迭代:
while True:
print('=====>>>')
*为什么要用迭代器?
找到一种不依赖于索引的取值方式。
*怎么用迭代器?
a.#可迭代对象?
在python中,但凡内置有__iter__()方法对象,都是可迭代对象。
例如:字符串str,列表list,元祖tuple,字典dict,集合set,文件open等有__iter__()方法的可迭代对象。
b.#迭代器对象?
执行可迭代对象下的__iter__()方法得到的返回值就是一个迭代器对象。
迭代器对象中内置有__next__()方法可迭代取值!
所以:同时内置有 __next__()方法 和 __iter__()方法的才叫做迭代器对象!
例如:
d=[1,2,4]
iter_obj=d.__iter__()
print(iter_obj) #<list_iterator object at 0x000000000284A390>
print(iter_obj.__next__())#依次取出d列表中的值,当取完的时候会抛出一个StopIteration的结束信号!
dict={'a':1,'b':2,'c':3,'d':4}
iter_obj=dict.__iter__()
while True:
try:
print(iter_obj.__next__())
except StopIteration:
break
'''
output:
a
b
c
d
'''
不用for循环遍历字典中的值
由上面例子可知:for 循环底层运行机制,for 循环可以称为迭代器循环。
1.先调用in 后面对象的__iter__()方法,得到该对象的迭代器对象。
2.执行迭代器对象的__next__()方法,将得到的返回值赋值给in前面的变量,然后执行一次循环体代码。
3.循环往复,直到取干净迭代器内的所有值,自动捕捉结束循环。
c.#迭代器的优缺点
优点:
1.提供一种不依赖于索引的迭代取值方式
2.更加节省内存空间
缺点:
1.是一次性的,值去干净后无法再次取值,除非重新得到新的迭代器对象。
2.只能往后取值,不能往前取值,永远无法预测迭代器的长度。(不如索引的取值的方式灵活)
2.生成器
a.什么是生成器?
在函数体内但凡有yield关键字,再调用函数就不会执行函数体代码,得到返回值就是一个生成器对象.
生成器本质上就是迭代器!!
实例:
def foo():
print('first')
yield 1
print('second')
yield 2
print('three') g=foo()
print(g) #<generator object foo at 0x00000000024958E0>
print(g.__iter__()) #<generator object foo at 0x00000000024958E0>
res1=next(g) #first
res2=next(g) #second
print(res1) #
print(res2) #
#等价于print(g.__next__()) 当res3=next(g)取不到值的时候会报错,跟迭代器一样。 #生成器本质上就是迭代器!
生成器剖析
def foo():
print('first')
yield 1
print('second')
yield 2
print('three') g=foo()
for item in g:
print(item)
yiled 运行过程
next(g)过程:
会触生成器g 所对应的函数的执行,知道遇到yiled才停下来,然后吧yiled后面的返回值当作本次next操作的结果!
b.为什么要用生成器?
学习生成器是为了掌握一种自定义迭代器的方式!
1.实例:用yield实现range()函数的方法,就叫做自定义迭代器。。。
#用yield 实现range函数的功能
def my_range(start,stop,step=1):
print('开始运行')
while start<stop:
yield start
start+=step print('结束运行') res=my_range(1,1000,2) print(res.__next__())
print(res.__next__())
print(res.__next__())
'''
开始运行
1
3
5
''' # for i in res:
# print(i)
yiled实现range()函数功能
2.yiled表达式应用
实例1:yield的使用,给dog喂包子...
def dog(name):
food_list=[]
print('狗哥 %s 准备开吃'%name)
while True:
food=yield food_list #暂停 yield=None
print('狗哥%s 开始吃了%s'%(name,food))
food_list.append(food) g=dog('alex')
# next(g)#狗哥 alex 准备开吃
# next(g) #狗哥alex 开始吃了None
# next(g)#狗哥alex 开始吃了None g.send(None)#等价于next(g),因为使用是第一次必须传入None!! #狗哥 alex 准备开吃,返回值为None res1=g.send('骨头') #send先传值,再next(g) 狗哥alex 开始吃了骨头
print(res1)
res2=g.send('泔水')
print(res2)
res3=g.send('米饭')
print(res3)
#g.close() #关闭连接
yield的使用1
实例2:yield实现协程函数
#yield关键字的另外一种使用形式:表达式形式的yield
def eater(name):
print('%s 准备开始吃饭啦' %name)
food_list=[]
while True:
food=yield food_list
print('%s 吃了 %s' % (name,food))
food_list.append(food) g=eater('egon')
g.send(None) #对于表达式形式的yield,在使用时,第一次必须传None,g.send(None)等同于next(g)
g.send('蒸羊羔')
g.send('蒸鹿茸')
g.send('蒸熊掌')
g.send('烧素鸭')
g.close()
g.send('烧素鹅')
g.send('烧鹿尾')
egon实现的线程函数
实例3:用装饰器来实现初始化协程函数(next(g) /g.send(None))
def init(func):
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper @init
def eater(name):
print('%s 准备开始吃饭了'%name)
food_list=[]
while True:
food=yield food_list
print('%s 吃了 %s '%(name,food))
food_list.append(food) g=eater('egon')
#g.send(None) #用@init可以替代初始化传入None值的操作
g.send('蒸羊羔')
'''
egon 准备开始吃饭了
egon 吃了 蒸羊羔
'''
初始化协程函数
总结yield:
1.yield提供一种自定义迭代器的方式
2.与return 对比,都能返回多个值,都没有类型限制,而return只能返回一次值,而yiled可以返回多次值(yield可以帮我卖保存函数的执行状态或结果,以便下次迭代使用)
3.生成器表达式
生成器表达式的应用:
'''
用生成器实现range函数的功能
''' #1.应用1
def my_range(start,stop,step=1):
while start<stop:
yield start
start+=step for item in my_range(1,5,2):
print(item) #2.应用2
def dog(name):
print('狗哥:%s 准备开始'%name)
food_list=[]
while True:
food=yield food_list
print('狗哥%s 吃了:%s'%(name,food))
food_list.append(food)
#print(food_list) dg=dog('egon')
res0=next(dg) #初始化yield的时候必须给一个None值!
print(res0) res1=dg.send('骨头')
print(res1)
res2=dg.send('泔水')
print(res2)
res3=dg.send('馒头')
print(res3) #3.生成器表达式应用
#列表表达式
# l=[i**2 for i in range(1,11)]
# print(l) names=['egon','alex','lxx']
g_name=(name.upper() for name in names if name!='egon')
print(g_name) #<generator object <genexpr> at 0x0000000002455A40>
print(next(g_name)) with open('a.txt','rt',encoding='utf-8') as f:
# g_lines=(line for line in f)
# print(next(g_lines))
# g_lines=(len(line) for line in f)
# print(max(g_lines))
print(max(len(line) for line in f))
生成器表达式练习
三.内置函数(1-2)
1.请参考内置函数官方文档或者相关文档 菜鸟教程:http://www.runoob.com/python3/python3-built-in-functions.html 2.部分内置函数实例练习
1):frozenset内置函数
2):hash函数的原理
3).部分其他函数
#Author:http://www.cnblogs.com/Jame-mei #1.匿名函数lanbda 方式1
#(lambda n:print(n)) (5) #匿名函数lanbda 方式2,不能做循环或者迭代,只能进行简单的三元运算!
calc=lambda n:n*2
#print(calc(10)) #输出20 #2.filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。 与匿名函数结合使用如下:
'''
res = filter(lambda n:n>5,range(10))
for i in res:
print (i) 输出:
6
7
8
9
''' '''#3.map函数的使用:map() 会根据提供的函数对指定序列做映射。
res=map(lambda n:n*n,range(10)) #等价于res1=[i*2 for i in range(10)]和res2=[lambda i:i*2,range(10)]
for i in res:
print (i) 输出:
0
1
4
9
16
25
36
49
64
81
''' '''#4.reduce 在python2.x中属于内置函数,但是在python3.x中已经移动到了functools
import functools
res=functools.reduce(lambda x,y:x*y,range(1,5))
print(res)
输出:
24
''' '''#5.frozenset() 冻结
res1=([1,1,22,22,3,3])
res2=frozenset([1,1,22,22,3,3])
''' '''#5.globals() 函数会以字典类型返回当前位置的全部全局变量。'''
print (globals()) '''#6.pow() 方法返回 xy(x的y次方) 的值
print (pow(2,3)) #输出8''' '''#7.repr() 函数将对象转化为供解释器读取的形式。'''
dict = {'runoob': 'runoob.com', 'google': 'google.com'}
print (repr(dict)) '''#8.reversed 函数返回一个反转的迭代器。''' '''#9.round() 方法返回浮点数x的四舍五入值。'''
print (round(4.25))
print (round(4.78))
print (round(3.78)) '''#10.sorted()排序....'''
sor={-5:3,6:2,1:10,9:5,7:4}
print (sor)
#print (sorted(sor.items())) 默认按照Key排序
print (sorted(sor.items(),key=lambda x:x[1])) #按照value来进行排序! '''#11.type() 函数如果你只有第一个参数则返回对象的类型,三个参数返回新的类型对象。''' '''#12.zip()函数'''
a=[1,2,3,4]
b=['a','b','c','d']
for i in zip(a,b):
print (i) '''#13.import decorator
__import__('decorator') 输出:
in the test1...............
The func run time is 2.0011146068573
'''
内置函数
四.Json & pickle 数据序列化
1.参考 http://www.cnblogs.com/alex3714/articles/5161349.html
2.json序列化和反序列化操作实例
1):json序列化和反序列化
实例1:序列化和反序列化前奏
#Author:http://www.cnblogs.com/Jame-mei '''
#1.序列化,将内存的对象,变成字符串存起来 info={
'name':'alex',
'age':24 }
f=open('json1.txt','w')
f.write(str(info))
f.close()
''' #2.反序列化,将字符串取出来
f=open('json1.txt','r')
data=eval(f.read()) #直接r.read()是一个字符串类型,想要输出之前的字典,需要用eval()函数。
print (data['name'])
f.close() #以上转换方法太low了,请看json02.py内容!
前奏:eval实现序列化和反序列化
实例2:json实现序列化和反序列化
#Author:http://www.cnblogs.com/Jame-mei
import json '''
#1.序列化
info={
'name':'alex',
'age':24 }
f=open('json2.txt','w')
# print (json.dumps(info)) #打印出来是字符串
f.write(json.dumps(info))
f.close()
''' #2.反序列化
f=open('json2.txt','r')
#print (json.loads(f.read()))
data=json.loads(f.read())
print (data['name'])
print (data['age'])
json实现序列化和反序列化01
实例3:json只能处理简单的数据类型
#Author:http://www.cnblogs.com/Jame-mei
import json def sayhi(name):
print ('hello ',name) info={
'name':'alex',
'age':24,
'func':sayhi
} f=open('json3.txt','w')
f.write(json.dumps(info))
f.close() '''总结:1.序列化def会报错,TypeError: Object of type 'function' is not JSON serializable。
2.json只能处理简单的数据类型,例如字典,列表,字符串等。
3.想要处理更加复杂的,需要用到pickle,用法跟json完全一样。
'''
json处理简单类型数据
实例4:json处理序列化和反序列化最好单个任务只进行一次
#Author:http://www.cnblogs.com/Jame-mei
import json '''
#1.dumps多次,进行序列化,修改其中的元素再次dumps,发现存了2个字典进去。
def sayhi(name):
print ('hello ',name) info={
'name':'alex',
'age':24,
#'func':sayhi
} f=open('json5.txt','w')
f.write(json.dumps(info)) info['age']=26 #修改info的内容,再次进行dumps
f.write(json.dumps(info)) f.close()
''' f=open('json5.txt','r')
data=json.loads(f.read())
print (data)
#json.decoder.JSONDecodeError: Extra data: line 1 column 28 (char 27) '''总结:
通过以上序列化和反序列化操作,dumps可以多次进行,但是loads后会报错,可以循环打印出来,但是不能打印出每次dumps的。
所以,最好每次dumps()和loads(),每次序列化和反序列化只进行一次,有新的内容再重新进行存取操作。 '''
json有新的内容需要重新dumps()和loads()
3.pickle
1):实例1:pickle序列化和反序列化操作
import pickle '''#1.序列化
def sayhi(name):
print ('hello ',name) info={
'name':'alex',
'age':24,
'func':sayhi
} f=open('json3.txt','wb') #如果只是w,会报TypeError: write() argument must be str, not bytes
f.write(pickle.dumps(info))
f.close()
''' def sayhi(name):
print ('hello ',name) f=open('json3.txt','rb')
data=pickle.loads(f.read())
#AttributeError: Can't get attribute 'sayhi' on <module '__main__' from 'E:/pythonwork/s14/day04/pickle01.py'>
#sayhi随着函数执行后,会从内存中消失,且func:sayhi也不应该这用,需要手动将def sayhi()函数copy过来。
print (data['name'])
print (data)
print (data['func']('caiyunhua')) #执行func对应的函数!
pickle序列化和反序列化
2):实例2:pickle精简版序列化和反序列化
#Author:http://www.cnblogs.com/Jame-mei
import pickle #1.精简版pickle序列化
def sayhi(name):
print ('hello ',name) info={
'name':'alex',
'age':24,
'func':sayhi
} f=open('json4.txt','wb')
pickle.dump(info,f) #这步相当于pickle01中的f.write(pickle.dumps(info))序列化操作!
f.close() f1=open('json4.txt','rb')
data=pickle.load(f1) #这步相当于pickle02中的 data=pickle.loads(f.read())
print (data['name'])
print (data)
print (data['func']('tom'))
pickle精简版
五.三元表达式、列表生成式、字典生成式
1.三元表达式
语法:# res=条件成立时的返回值 if 条件 else 条件不成立时的返回值
例子:比较两个大小:
1):用函数来实现:
def max2(x,y):
if x>y:
return x
else:
return y res=max2(1,2) 2):用三元表达式实现
x=1
y=2
res=x if x>y else y
print(res) res=True if x>y else False
print(res)
2.列表生成式
语法:# [ 条件成立的列表 循环体 判断条件]
例子: 过滤符合条件的数字列表,过滤添加符合条件的字符列表
1.生成一个0-10大于3的新列表
l1=[i for i in range(10) if i > 3]
print(l1) 2.将一个列表过滤,生成一个新的列表
names=['alex_sb','egon','liuqingzheng_sb','wupeiqi_sb']
l2=[]
for name in names:
if name.endswith('sb'):
l.append(name.upper()) print(l2) names=[name.upper() for name in names if name.endswith('sb')]
print(names)
3.字典生成式
语法:#{i:i 循环体 过滤条件}
例子:从数字中快速生成一个字典,将一个列表格式快速生成字典
#1.生成一个纯数字的字典
dic1={i:i for i in range(10) if i>3} print(dic1) #2.将一个列表快速生成为一个字典
l1=[
['name','egon'],
['age',18],
['sex','male']
] dic2={} dic2={item[0]:item[1] for item in l1} print(dic2)
六.软件目录结构规范
为什么要设计好目录结构?
"设计项目目录结构",就和"代码编码风格"一样,属于个人风格问题。对于这种风格上的规范,一直都存在两种态度:
- 一类同学认为,这种个人风格问题"无关紧要"。理由是能让程序work就好,风格问题根本不是问题。
- 另一类同学认为,规范化能更好的控制程序结构,让程序具有更高的可读性。
我是比较偏向于后者的,因为我是前一类同学思想行为下的直接受害者。我曾经维护过一个非常不好读的项目,其实现的逻辑并不复杂,但是却耗费了我非常长的时间去理解它想表达的意思。从此我个人对于提高项目可读性、可维护性的要求就很高了。"项目目录结构"其实也是属于"可读性和可维护性"的范畴,我们设计一个层次清晰的目录结构,就是为了达到以下两点:
- 可读性高: 不熟悉这个项目的代码的人,一眼就能看懂目录结构,知道程序启动脚本是哪个,测试目录在哪儿,配置文件在哪儿等等。从而非常快速的了解这个项目。
- 可维护性高: 定义好组织规则后,维护者就能很明确地知道,新增的哪个文件和代码应该放在什么目录之下。这个好处是,随着时间的推移,代码/配置的规模增加,项目结构不会混乱,仍然能够组织良好。
所以,我认为,保持一个层次清晰的目录结构是有必要的。更何况组织一个良好的工程目录,其实是一件很简单的事儿。
目录组织方式
关于如何组织一个较好的Python工程目录结构,已经有一些得到了共识的目录结构。在Stackoverflow的这个问题上,能看到大家对Python目录结构的讨论。
这里面说的已经很好了,我也不打算重新造轮子列举各种不同的方式,这里面我说一下我的理解和体会。
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/
|-- bin/
| |-- foo
|
|----com
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
简要解释一下:
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。docs/: 存放一些文档。setup.py: 安装、部署、打包的脚本。requirements.txt: 存放软件依赖的外部Python包列表。README: 项目说明文件。
除此之外,有一些方案给出了更加多的内容。比如LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织,可以参考这篇文章。
下面,再简单讲一下我对这些目录的理解和个人要求吧。
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具setuptools来管理这些事情。这种方式普遍应用于开源项目中。不过这里的核心思想不是用标准化的工具来解决这些问题,而是说,一个项目一定要有一个安装部署工具,能快速便捷的在一台新机器上将环境装好、代码部署好和将程序运行起来。
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
- 安装环境时经常忘了最近又添加了一个新的Python包,结果一到线上运行,程序就出错了。
- Python包的版本依赖问题,有时候我们程序中使用的是一个版本的Python包,但是官方的已经是最新的包了,通过手动安装就可能装错了。
- 如果依赖的包很多的话,一个一个安装这些依赖是很费时的事情。
- 新同学开始写项目的时候,将程序跑起来非常麻烦,因为可能经常忘了要怎么安装各种依赖。
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的文档比较庞大,刚接触的话,可能不太好找到切入点。学习技术的方式就是看他人是怎么用的,可以参考一下Python的一个Web框架,flask是如何写的: setup.py
当然,简单点自己写个安装脚本(deploy.sh)替代setup.py也未尝不可。
requirements.txt
这个文件存在的目的是:
- 方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在
setup.py安装依赖时漏掉软件包。 - 方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明: 点这里。
关于配置文件的使用方法
注意,在上面的目录结构中,没有将conf.py放在源码目录下,而是放在docs/目录下。
很多项目对配置文件的使用做法是:
- 配置文件写在一个或多个python文件中,比如此处的conf.py。
- 项目中哪个模块用到这个配置文件就直接通过
import conf这种形式来在代码中使用配置。
这种做法我不太赞同:
- 这让单元测试变得困难(因为模块内部依赖了外部配置)
- 另一方面配置文件作为用户控制程序的接口,应当可以由用户自由指定该文件的路径。
- 程序组件可复用性太差,因为这种贯穿所有模块的代码硬编码方式,使得大部分模块都依赖
conf.py这个文件。
所以,我认为配置的使用,更好的方式是,
- 模块的配置都是可以灵活配置的,不受外部配置文件的影响。
- 程序的配置也是可以灵活控制的。
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的。
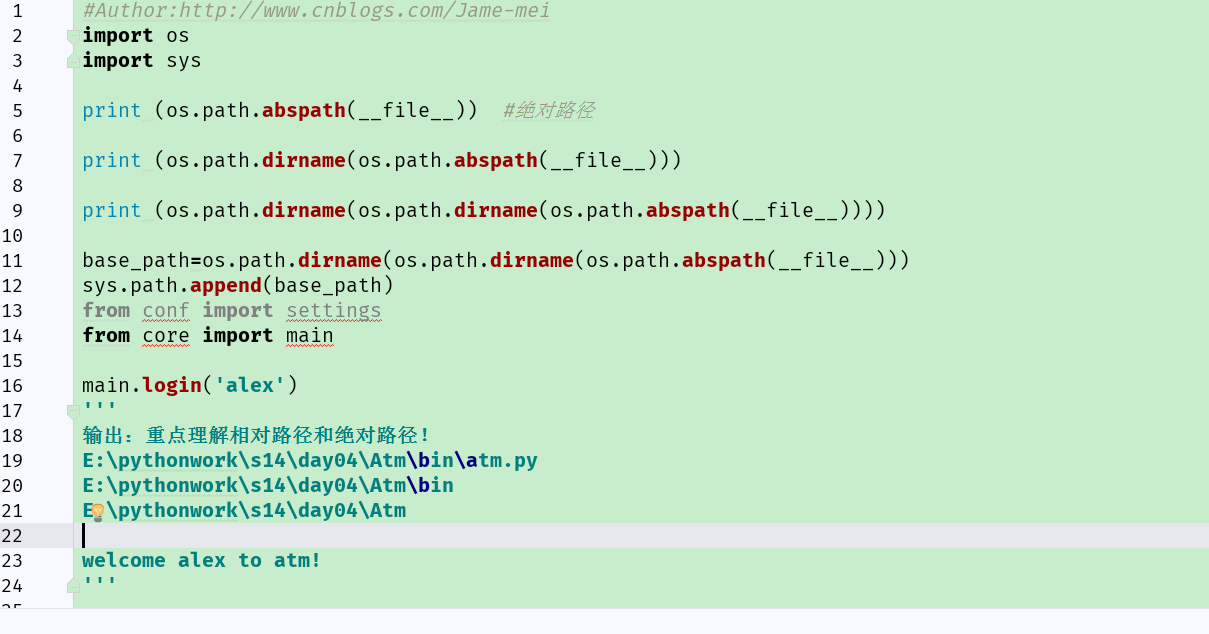
实例:文件结构和不同的文件目录的相互调用!
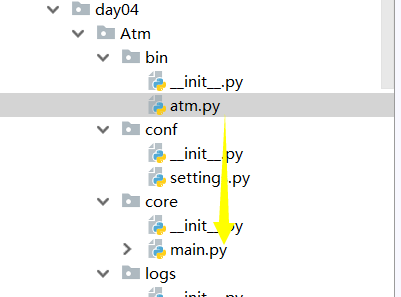
main.py:
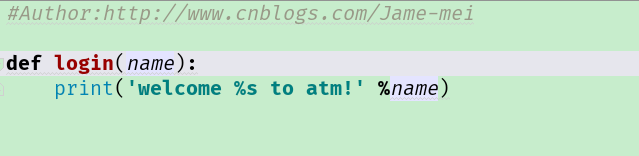
atm.py:其中...bin/atm.py调用...core/main.py内的函数。
七.作业:ATM项目开发
作业需求:
模拟实现一个ATM + 购物商城程序
- 额度 15000或自定义
- 实现购物商城,买东西加入 购物车,调用信用卡接口结账
- 可以提现,手续费5%
- 每月22号出账单,每月10号为还款日,过期未还,按欠款总额 万分之5 每日计息
- 支持多账户登录
- 支持账户间转账
- 记录每月日常消费流水
- 提供还款接口
- ATM记录操作日志
- 提供管理接口,包括添加账户、用户额度,冻结账户等。。。
- 用户认证用装饰器
示例代码 https://github.com/triaquae/py3_training/tree/master/atm
简易流程图:https://www.processon.com/view/link/589eb841e4b0999184934329
本人完成作业提交gitee.com
https://gitee.com/meijinmeng/Atm-Shopping
master 基础版
1stage 升级版
Python基础-week04的更多相关文章
- Python基础-week05
本节大纲:Author:http://www.cnblogs.com/Jame-mei 模块介绍 time & datetime模块 random os sys shutil json &am ...
- python之最强王者(2)——python基础语法
背景介绍:由于本人一直做java开发,也是从txt开始写hello,world,使用javac命令编译,一直到使用myeclipse,其中的道理和辛酸都懂(请容许我擦干眼角的泪水),所以对于pytho ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
- Python小白的发展之路之Python基础(一)
Python基础部分1: 1.Python简介 2.Python 2 or 3,两者的主要区别 3.Python解释器 4.安装Python 5.第一个Python程序 Hello World 6.P ...
- Python之路3【第一篇】Python基础
本节内容 Python简介 Python安装 第一个Python程序 编程语言的分类 Python简介 1.Python的由来 python的创始人为吉多·范罗苏姆(Guido van Rossum) ...
- 进击的Python【第三章】:Python基础(三)
Python基础(三) 本章内容 集合的概念与操作 文件的操作 函数的特点与用法 参数与局部变量 return返回值的概念 递归的基本含义 函数式编程介绍 高阶函数的概念 一.集合的概念与操作 集合( ...
- 进击的Python【第二章】:Python基础(二)
Python基础(二) 本章内容 数据类型 数据运算 列表与元组的基本操作 字典的基本操作 字符编码与转码 模块初探 练习:购物车程序 一.数据类型 Python有五个标准的数据类型: Numbers ...
- Python之路【第一篇】python基础
一.python开发 1.开发: 1)高级语言:python .Java .PHP. C# Go ruby c++ ===>字节码 2)低级语言:c .汇编 2.语言之间的对比: 1)py ...
- python基础之day1
Python 简介 Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言. Python为我们提供了非常完善的基础代码库,覆盖了 ...
随机推荐
- 【其他】3dmax撤销Ctrl+z不能用的解决办法
转载请注明出处:http://www.cnblogs.com/shamoyuu/p/3dmax_ctrlz.html 如果你经常去网上下载各种模型参考学习的话,出现这个问题的概率会非常高.因为出现这个 ...
- NLP+词法系列(二)︱中文分词技术简述、深度学习分词实践(CIPS2016、超多案例)
摘录自:CIPS2016 中文信息处理报告<第一章 词法和句法分析研究进展.现状及趋势>P4 CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bce ...
- 嵌入式 视频编码(H264)
这几天在编写视频录制模块,所以,闲暇之余,又粗粗的整理了一下,主要是API,以备不时之用 摄像头获取的模拟信号通过经芯片处理(我们使用的是CX25825),将模拟信号转成数字信号,产生标准的IT ...
- VS2010 C++学习(5):基于DirectShow的视频预览录像程序
VS2010 C++学习(5):基于DirectShow的视频 预览录像程序 学习VC++编制的基于DirectShow视频捕获程序,主要练习基于DirectShow程序的应用. 一. ...
- jQuery中的val()
jQuery中的val() 1.实例源码 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" &qu ...
- My97 DatePicker图标触发
My97 DatePicker图标触发 1.设计源码 <%@ page language="java" import="java.util.*" page ...
- Java获取某年某周的第一天
Java获取某年某周的第一天 1.设计源码 FirstDayOfWeek.java: /** * @Title:FirstDayOfWeek.java * @Package:com.you.freem ...
- 错误代码: 1052 Column 'stu_id' in field list is ambiguous
1.错误描述 1 queries executed, 0 success, 1 errors, 0 warnings 查询:select stu_id, (SELECT stu_name FROM t ...
- com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxError Exception
1.错误描述 com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxError Exception:You have an error in your SQL synt ...
- linq使用日记
//普通查询 var query = (from t in ServiceList where t.CreateUserID == A ...