HDFS基本原理总结
HDFS由三个基本组件组成:NameNode,SecondaryName,DataNode,其思想类似于Linux的文件系统,可以进行类比。
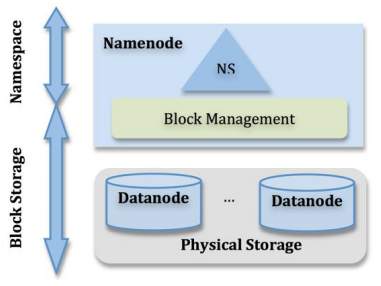
1.NameNode介绍:
1.管理整个文件系统的命名空间,内部维护了命名树。
2.存储元数据:文件层级关系,文件所有者及权限,每个文件由哪些文件块组成(但元信息中不包括每个块的位置)。内容通过fsimage及edits维护,后文会详述。
3.接受客户端请求
2.为什么HDFS倾向于存储大文件:
首先,NameNode中存储一条元信息需要200byte,而元信息是保存在NameNode的内存中的,不能分布式存储,文件越小,存储同样大小的内容元信息越大,NameNode的内存有可能会成为系统存储的瓶颈。
其次,大文件减少了磁盘的寻道时间。但是数据块过大也会出现问题,MapReduce框架通常会为每个数据块启动一个进程,数据块过大会使并行数量减少,降低任务处理效率。
3.元信息持久化:
fsimage是NameNode的元数据镜像文件,用于存储某一时段内存的元数据信息,而系统运行期间所有元信息的操作都保存在内存中并被持久化到另一个文件edits中,edits会被周期性合并进fsimage中。合并两个日志的操作显然会占用大量的CPU,内存及IO,而NameNode中的计算及存储资源是很宝贵的,因此,通常合并操作通常交给SecondaryNameNode(注意,SecondaryNameNode作用不是热备!)。而NameNode本身通常也不会参与MapReduce计算和数据存储。
4.单点问题:
可以发现,HDFS中NameNode是一个单点,除了定期保存fsimage用于故障恢复外,也可以在元数据写入同时将其实时同步到一个远程挂载的NFS上。
5.SecondaryNameNode作用:
1. 减少启动时NameNode合并日志的时间
2. 一定程度上减少了NameNode的单点问题
2.DataNode
1.负责存储数据块,响应客户端读写(注意,客户端直接读写DataNode,而非经过NameNode)。
2.根据NameNode发送的指令创建,删除和复制文件。
3.定期向NameNode发送心跳,报告文件块列表信息。
4.为了安全,提供了数据块冗余,默认为3个副本。数据块默认为64MB
5.数据完整性问题:
存储和处理数据时数据有可能发生错误或丢失,HDFS会对写入的数据计算校验和。
HDFS基本原理总结的更多相关文章
- HDFS基本原理及数据存取实战
---------------------------------------------------------------------------------------------------- ...
- 【图文详解】HDFS基本原理
本文主要详述了HDFS的组成结构,客户端上传下载的过程,以及HDFS的高可用和联邦HDFS等内容.若有不当之处还请留言指出. 当数据集大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区,并 ...
- Hadoop之HDFS(二)HDFS基本原理
HDFS 基本 原理 1,为什么选择 HDFS 存储数据 之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点: 1.高容错性 数据自动保存多个副本.它通过增加副本的形式,提高容错性. 某一 ...
- HDFS基本原理
一.什么是HDFS HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,它和现有的分布式文件系统有很多共同点.但同时, ...
- hdfs的基本原理和基本操作总结
hdfs基本原理 Hadoop分布式文件系统(HDFS)被设计成适合执行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有非常多共同点. 但同一时候,它和 ...
- 最通熟易懂的Hadoop HDFS实践攻略
HDFS是用来解决什么问题?怎么解决的? 如何在命令行下操作HDFS? 如何使用Java API来操作HDFS? 在了解基本思路和操作方法后,进一步深究HDFS具体的读写数据流程 学习并实践本文教程后 ...
- Hadoop_HDFS_02
1. HDFS入门 1.1 HDFS基本概念 HDFS是Hadoop Distribute File System的简称, 意为: Hadoop分布式文件系统. 是Hadoop三大核心组件之一, 作为 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 定时脚本: 删除HDFS中的过期文件
1. 基本原理: 通过hadoop fs -ls *命令获取相关文件或目录的修改时间,然后与设定的过期时间进行比较,之后执行删除操作即可 2. 相关代码: #!/bin/bash source ~/. ...
随机推荐
- 1.11 str 字符串
字符串属于不可变序列,是 文本序列. 字符串的声明 >>> #字符串的声明既可以用单引号也可以用双引号,这两个能方法在效果上是一样的 >>> s = '' > ...
- 轻松掌握VS Code开发.Net Core及创建Xunit单元测试
前言 本篇文章主要还是介绍使用 VS Code 进行.Net Core开发和常用 CLI命令的使用,至于为啥要用VS Code ,因为它是真的是好看又好用 :) ,哈哈,主要还是为了跨平台开发做准备. ...
- POJ - 3268 单源最短路
题意:给定一些有向边,以及一个目的地,从某个点到达目的地,再从目的地回到那个点.共有n个点,问这n个点花费最大是多少? 思路:从目的地回去直接把目的地作为源点即可.那么从某个点到达目的地应该如何得到最 ...
- MySQL基础学习笔记
一.数据库基本概念 1.1 数据库 - Database 从字面意思看,数据库就是一个存储数据的仓库.从计算机的角度来讲,数据库(Datebase)是按照数据结构来组织.存储和管理数据的仓库. 简单来 ...
- websocket 和 ansible配合Tomcat实时日志给前端展示
业务流程图如下 效果图展示 1.django安装websocket模块 pip install dwebsocket 2.shell脚本 用来传递不同的行号输出不同的内容; 第一个参数为0的时候,默认 ...
- Centos搭建mysql/Hadoop/Hive/Hbase/Sqoop/Pig
目录: 准备工作 Centos安装 mysql Centos安装Hadoop Centos安装hive JDBC远程连接Hive Hbase和hive整合 Centos安装Hbase 准备工作: 配置 ...
- caffe+GAN︱PPGN生成模型5则官方案例(caffe版)
一.效果与架构 PPGN 整合了对抗训练.cnn特征匹配.降噪自编码.Langevin采样:在NIPS2016得到了Ian Goodfellow的介绍. PPGN生成的图像同类差异化大,可根据指定生成 ...
- Shell脚本编程学习入门 01
从程序员的角度来看, Shell本身是一种用C语言编写的程序,从用户的角度来看,Shell是用户与Linux操作系统沟通的桥梁.用户既可以输入命令执行,又可以利用 Shell脚本编程,完成更加复杂的操 ...
- mysql事务介绍
什么是事务 一组sql语句操作单元组内所有sql完成一个业务如果整组成功,意味着组内的全部的sql成功如果其中任何一个失败,意味着整个操作失败 数据回到操作前的状态 事务的特点 1.多条sql语句组成 ...
- css(外部样式表)中各种选择器(定义属性时)的优先级
今天在学css的时候遇到一个问题,用css的外部样式表改变一个<p>元素的颜色,死活就是改变不了,最后才发现是优先级的问题(我自己想当然成后面的优先级就高了,犯了经验主义错误). 先给大家 ...