spider 爬虫文件基本参数(3)
一 代码
- # -*- coding: utf-8 -*-
- import scrapy
- class ZhihuSpider(scrapy.Spider):
- # 爬虫名字,名字唯一,允许自定义
- name = 'zhihu'
- # 允许爬取的域名,scrapy每次发起的url爬取数据,先回进行域名检测,检测通过就爬取
- allowed_domains = ['zhihu.com']
- #发起的起始url地址,scrapy项目启动自动调用start_request()方法,把start_urls
- # url的作为请求url发起请求,把获取到的response交给回调函数,回调函数传递给parse
- # 解析数据
- start_urls = ['http://zhihu.com/']
- custom_settings = {
- # 请求头
- 'user-agent': None,
- # 请求来源
- # 'referer': 'https://www.zhihu.com/',
- }
- def start_requests(self):
- '重写start_requests方法'
- for url in self.start_urls:
- #自定义解析方法
- yield scrapy.Request(url=url,method='Get',callback=self.define_parse)
- def parse(self, response):
- pass
- def define_parse(self,response):
- print(response)
- #输出状态码
- self.logger.info(response.status)
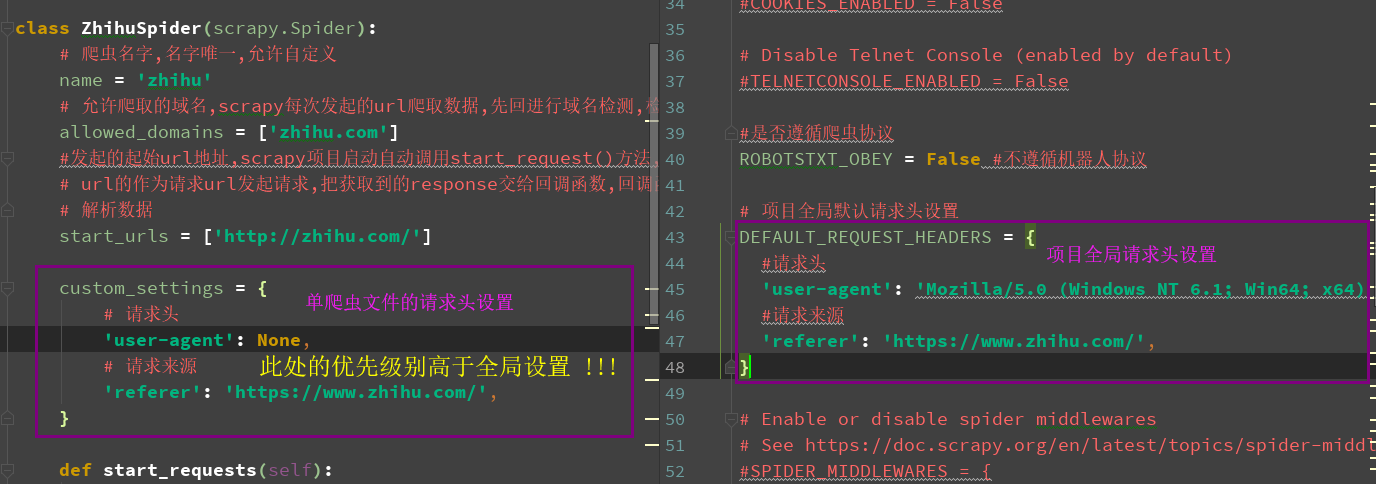
二 参数详解
custom_settings
- 1 settings 文件中默认请求头 DEFAULT_REQUEST_HEADERS
- 2 spider文件中请求头参数 custom_settings
- 必须以类变量形式存在
- 优先级别高与全局
访问知乎不携带请求参数,返回400

两种请求头的书写方式如下(左:spisder, 右:settings.py)
allowed_domains
允许爬取的域名,scrapy每次发起的url爬取数据,先回进行域名检测,检测通过就爬取
start_urls
发起的起始url地址,scrapy项目启动自动调用start_request()方法,把start_urlsurl的作为请求url发起请求,把获取到的response交给回调函数,回调函数传递给parse解析数据
settings
全局的配置文件
logger
日志信息,使用=python自带的log模块
start_requests()
- class MySpider(scrapy.Spider):
- name = 'myspider'
- def start_requests(self):
- #使用FormRequest提交数据
- return [scrapy.FormRequest("http://www.example.com/login",
- formdata={'user': 'john', 'pass': 'secret'},
- callback=self.logged_in)]
- def logged_in(self, response):
- pass
post 请求

parse(response)
参数:response(Response) - 对解析的响应
指定解析函数,可以扩展多个函数,多层次的解析方法.
spider 启动参数配置
- import scrapy
- class MySpider(scrapy.Spider):
- name = 'myspider'
- def __init__(self, category=None, *args, **kwargs):
- super(MySpider, self).__init__(*args, **kwargs)
- self.start_urls = ['http://www.example.com/categories/%s' % category]
命令行中调用
- scrapy crawl myspider -a category=electronics
spider 爬虫文件基本参数(3)的更多相关文章
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- 第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
第三百四十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器 编写spiders爬虫文件循环 ...
- 二十 Python分布式爬虫打造搜索引擎Scrapy精讲—编写spiders爬虫文件循环抓取内容—meta属性返回指定值给回调函数—Scrapy内置图片下载器
编写spiders爬虫文件循环抓取内容 Request()方法,将指定的url地址添加到下载器下载页面,两个必须参数, 参数: url='url' callback=页面处理函数 使用时需要yield ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 二十三 Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
用命令创建自动爬虫文件 创建爬虫文件是根据scrapy的母版来创建爬虫文件的 scrapy genspider -l 查看scrapy创建爬虫文件可用的母版 Available templates: ...
- SWFUpload多图上传、C#后端跨域传文件带参数
前几天工作中用到了SWFUpload上传图片,涉及到跨域,因为前端无法实现跨域,所以只能把文件传到后端进行跨域请求,整理分享下. 效果图 前端 html部分 <!DOCTYPE html> ...
- C# 如何执行bat文件 传参数
C# 如何执行bat文件 传参数 分类: C# basic 2011-04-25 18:55 3972人阅读 评论(0) 收藏 举报 c#stringpathoutput Process p = ne ...
- Django之用户上传文件的参数配置
Django之用户上传文件的参数配置 models.py文件 class Xxoo(models.Model): title = models.CharField(max_length=128) # ...
- 由于想要实现下载的文件可以进行选择,而不是通过<a>标签写死下载文件的参数,所以一直想要使用JFinal结合ajax实现文件下载,但是ajax实现的文件下载并不能触发浏览器的下载文件弹出框,这里通过模拟表单提交实现同样的效果。
由于想要实现下载的文件可以进行选择,而不是通过<a>标签写死下载文件的参数,所以一直想要使用JFinal结合ajax实现文件下载(这样的话ajax可以传递不同的参数),但是ajax实现的文 ...
随机推荐
- java正则表达式验证金额
String reg_money = "\\d+(\\.\\d{1,2})?";// 金额正则,可以没有小数,小数最多不超过两位 Pattern pattern = Pattern ...
- (细节)My SQL中主键为0和主键自排约束的关系
开始不设置主键 表的设计如下: 如果id的位置有好几个0的话:设置主键并且自动排序时,0会从1开始递增: Insert 进去 id = 0的数据,数据会从实际的行数开始增加,和从0变化不一样: 现在主 ...
- Linux共享库、静态库、动态库详解
1. 介绍 使用GNU的工具我们如何在Linux下创建自己的程序函数库?一个“程序函数库”简单的说就是一个文件包含了一些编译好的代码和数据,这些编译好的代码和数据可以在事后供其他的程序使用.程序函数库 ...
- 架构选型之Nodejs与Java
前言: 身边越来越多的同事谈论Nodejs,谈其异步IO.事件回调.前后台统一一门语言,创业的朋友的第一个创业项目也选择了Nodejs,期望能够使用一种语言节省成本快速完成需求开发.与其他项目组的同事 ...
- ETCD相关介绍--整体概念及原理方面
etcd作为一个受到ZooKeeper与doozer启发而催生的项目,除了拥有与之类似的功能外,更专注于以下四点. 简单:基于HTTP+JSON的API让你用curl就可以轻松使用. 安全:可选SSL ...
- javascript快速入门之BOM模型—浏览器对象模型(Browser Object Model)
什么是BOM? BOM是Browser Object Model的缩写,简称浏览器对象模型 BOM提供了独立于内容而与浏览器窗口进行交互的对象 由于BOM主要用于管理窗口与窗口之间的通讯,因此其核心对 ...
- APP内置react 应用与APP的交互问题
一.内置的H5应用唤起(返回)app 可以用 intent url 来唤起,但要求 webview 实现 shouldOverrideUrlLoading() ,解析 uri,找到对应的 activi ...
- SSH(Spring_SpringMVC_Hibernate)
Users实体类 package com.tao.pojo; public class Users { private int id; private String name; private Str ...
- 【NOI赛前训练】——专项测试1·网络流
T1: 题目大意: 传送门 给一个长度为$n(n<=200)$的数列$h$,再给$m$个可以无限使用的操作,第$i$个操作为给长度为花费$c_i$的价值给长度为$l_i$的数列子序列+1或-1, ...
- 硬木地板 JDFZ1667
Description 举行计算机科学家盛宴的大厅的地板为M×N (1<=M<=9, 1<=N<=9)的矩形.现在必须要铺上硬木地板砖.可以使用的地板砖形状有两种:1) 2×1 ...