RowKey设计之单调递增行键/时序数据
在一个集群中,一个导入数据的进程锁住不动,所有的client都在等待一个region
(因而也就是一个单个节点),过了一会后,变成了下一个region…如果使用了单调递增
或者时序的key便会造成这样的问题。
数据存储提示:rowkey采用单调增加的值真的很糟糕。
使用了顺序的key会将本没有顺序的数据变得有顺序,把负载压在一台机器上。所以要尽量避免时间戳或者序列(e.g. 1, 2, 3)这样的行键。
monotonically increasing values are bad
When saving entities to App Engine’s datastore at a high write rate, avoid monotonically increasing values such as timestamps. Generally speaking,
you don’t have to worry about this sort of thing until your application hits 100s of queries per second. Once you’re in that ballpark, you may want to
examine potential hotspots in your application that can increase datastore latency.
作为开发人员,您可以做些什么来避免这种情况?
- 除非您需要查询值,否则请避免使用索引。没有指数=没有增加价值的热板
- 降低写入速率,或弄清楚如何更好地分配值。纯随机分布是最好的,但即使是非随机的分布也会比可预测的,单调递增的值更好
- 将分片标识符作为您的值的前缀。如果您计划进行查询,这是有问题的,因为您需要对值进行前缀和前缀, 然后将结果连接到内存中 - 但这会降低写入的错误率
无论您使用的是Master-Slave还是High Replication数据存储,这些提示都适用。
还有一个提示:不要过早地针对这种情况进行优化,因为很有可能,你不会遇到它。您可以花时间处理功能。
其实我只是想分享几个有趣得图片,娱乐到了我;
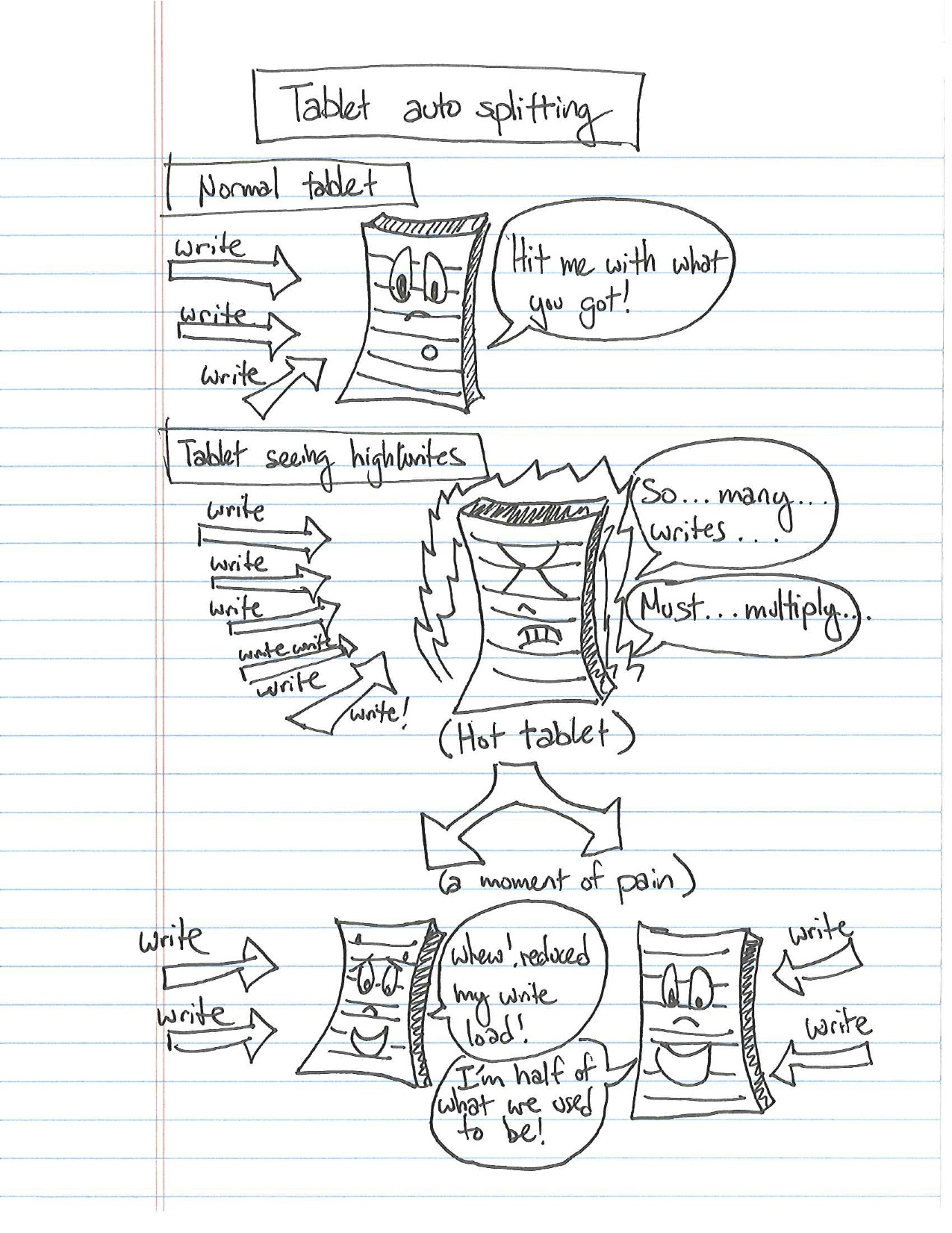
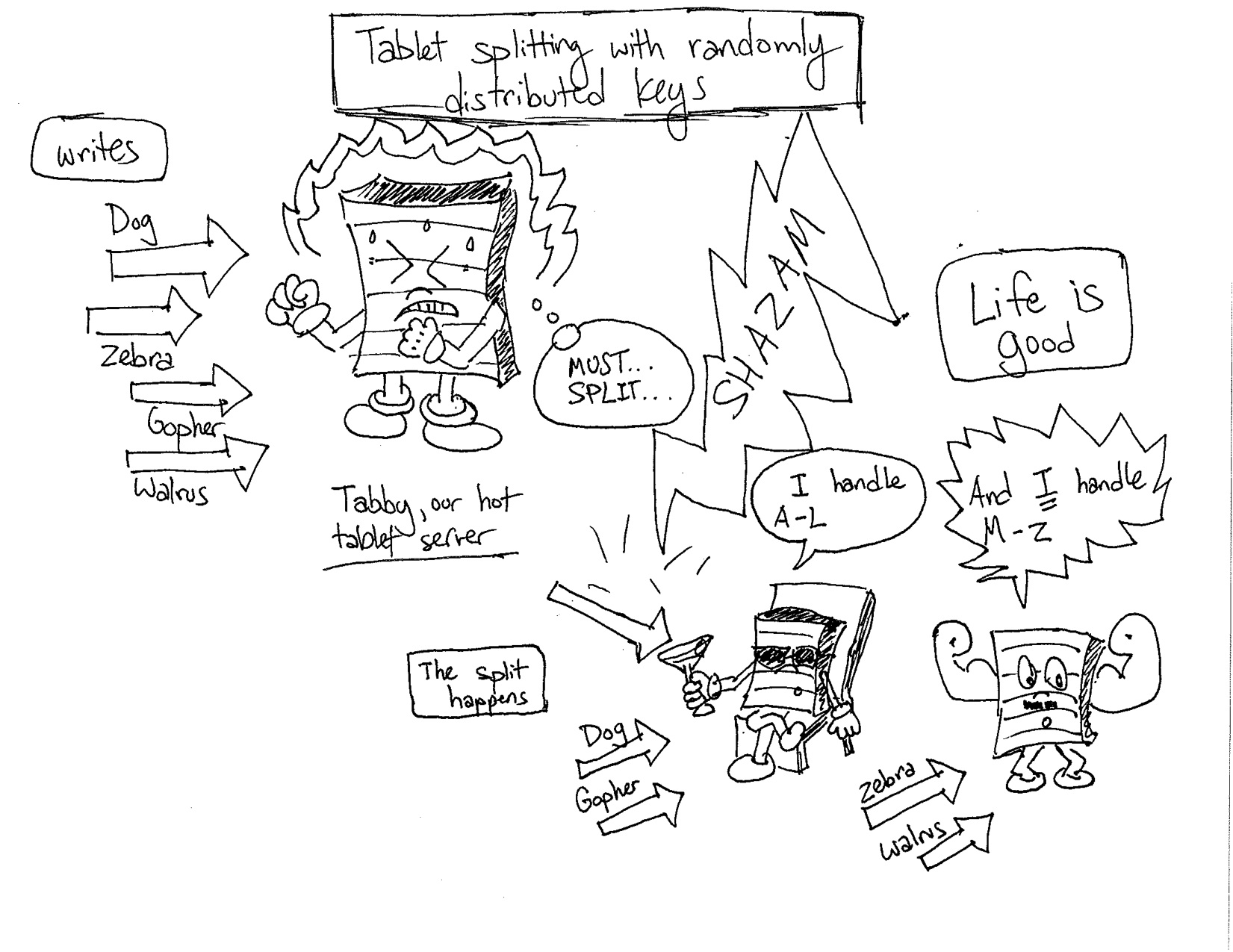
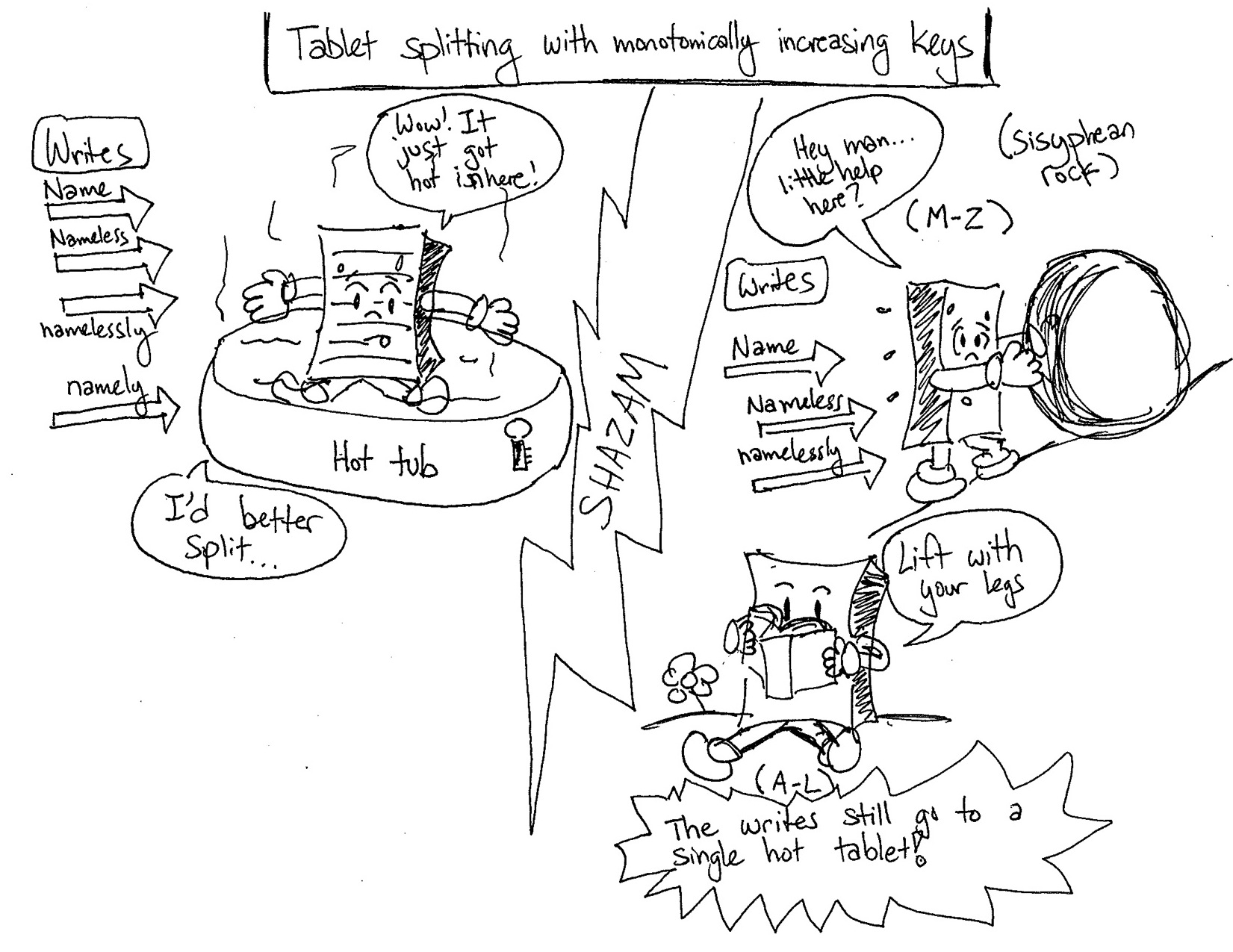
RowKey设计之单调递增行键/时序数据的更多相关文章
- Hadoop HBase概念学习系列之优秀行键设计(十六)
我们通过行键访问HBase.尽管使用扫描过滤器可以一次性指明大量的键,但是HBase仅仅能够根据行键识别出一行. 优秀的行键设计可以保证良好的HBase性能. 1.行键存在于HBase中的每一个单元格 ...
- 八 rowkey设计 几种方法
简单来讲,rowkey就是 KeyValue 中的key rowkey设计之 尽量散列设计 RowKey 如第三部分第六中讲到,如果数据都是有序的存储到一个特定的范围内,将会存 ...
- 架构师必备:HBase行键设计与应用
首先要回答一个问题,为何要使用HBase? 随着业务不断发展.数据量不断增大,MySQL数据库存在这些问题: MySQL支持的数据量为TB级,不能一直保留历史数据.而HBase支持的数据量为PB级,适 ...
- 【HBase】Rowkey设计【转】
本章将深入介绍由HBase的存储架构在设计上带来的影响.如何设计表.row key.column等等,尽可能地使用到HBase存储上的优势. Key设计 HBase有两个基础的主键结构:row key ...
- HBase的rowkey设计(含实例)
转自:http://www.aboutyun.com/thread-7119-1-1.html 对于任何系统的数据设计,我们都想提高性能,达到资源最大化利用,那么对于hbase我们产生如下问题: 1. ...
- HBase Rowkey 设计指南
为什么Rowkey这么重要 RowKey 到底是什么 我们常说看一张 HBase 表设计的好不好,就看它的 RowKey 设计的好不好.可见 RowKey 在 HBase 中的地位.那么 RowKey ...
- Hadoop-No.7之行键
和哈希表类比,HBase中的行键类似于哈希表中的键.要构造一个良好的HBase模式,关键之一就是选择一个合适的行键. 1 记录检索 行键是HBase中检索记录所使用的键.HBase记录含有的列在数量上 ...
- 重新认识HBase,Cassandra列存储——本质是还是行存储,只是可以动态改变列(每行对应的数据字段)数量而已,当心不是parquet
行先是以一种非常独特的方式被索引,随后Bigtable利用行键对数据进行分割,将它们分布到集群中.列可以被迅速地定义在行中,让Bigtable适用于大多数的非模式环境. 数据在表面上最初是由行进行排列 ...
- HBase应用开发回顾与总结系列之二:RowKey行键设计规范
2. RowKey行键设计规范 2.1. RowKey四大特性 2.1.1 字符串类型 虽然行键在HBase中是以byte[]字节数组的形式存储的,但是建议在系统开发过程中将其数据类型设置为Strin ...
随机推荐
- OutOfMemoryError/OOM/内存溢出异常实例分析--虚拟机栈和本地方法栈溢出
关于虚拟机栈和本地方法栈,在JVM规范中描述了两种异常: 1.如果线程请求的栈深度大于JVM所允许的深度,将抛出StackOverflowError异常: 2.如果虚拟机在扩展栈时无法申请到足够的内存 ...
- postgres的使用命令
1.更新源 yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-centos1 ...
- Implement heap using Java
public class HeapImpl { private int CAPACITY = 10; private int size = 0; private int[] data; public ...
- Use Wait & Notify to Implement Two Threads Run Alternatively
public class ThreadCommunication { public static void main(String[] args) { Business business = new ...
- 【RL-TCPnet网络教程】第40章 RL-TCPnet之TFTP客户端(精简版)
第40章 RL-TCPnet之TFTP客户端 本章节为大家讲解RL-TCPnet的TFTP客户端应用,学习本章节前,务必要优先学习第38章的TFTP基础知识.有了这些基础知识之后,再搞本章节 ...
- JDK对CAS ABA问题解决-AtomicMarkableReference和AtomicStampedReference
我们知道AtomicInteger和AtomicLong的原子操作,但是在这两个类在CAS操作的时候会遇到ABA问题,可能大家会疑问什么是ABA问题呢,请待我细细道来: ABA问题:简单讲就是多线程环 ...
- IdentityServer4 中文文档与实战
写在前面 写于2018.9.12 我研究 IdentityServer4 是从.net core 1.1的时候开始的,那时候国内的中文资料比较少,我都是按照官方文档来研究的,整理成了笔记.这个系列文档 ...
- DrawerLayoutDemo【侧边栏(侧滑菜单)简单实现】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 简单实现侧边栏(侧滑菜单)效果: 点击触发打开左侧侧边栏,手势滑动关闭左侧侧边栏: 手势滑动打开右侧侧边栏,手势滑动关闭右侧侧边栏: ...
- 机器学习——随机森林,RandomForestClassifier参数含义详解
1.随机森林模型 clf = RandomForestClassifier(n_estimators=200, criterion='entropy', max_depth=4) rf_clf = c ...
- qs.stringify和JSON.stringify的使用和区别
qs可通过npm install qs命令进行安装,是一个npm仓库所管理的包. 而qs.stringify()将对象 序列化成URL的形式,以&进行拼接. JSON是正常类型的JSON,请对 ...