Spark入门(1-5)Spark统一了TableView和GraphView
下面我们看一下图计算的简单示例:
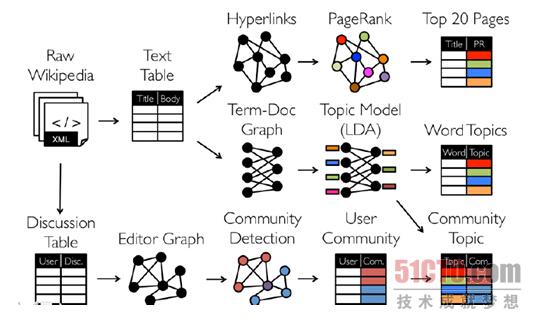
从图我们可以看出, 拿到Wikipedia的文档后,我们可以:
1、Wikipedia的文档 -- > table视图 -- >分析Hyperlinks超链接 -- > PageRank分析,
2、Wikipedia的文档 -- > table视图 -- >分析Term-Doc Graph -- > LDA -- > WordTopics
3、Wikipedia的文档 -- >Editor Graph -- > Community , 这个过程可以称之为Triangle Computation,这是计算三角形的一个算法,基于此,会发现一个社区,
从上面的分析中我们可以发现图计算有很多的做法和算法,同时也发现图和表格可以做互相的转换,不过并非所有的图计算框架都支持图与表格的互相转换。
Spark GraphX的优势在于能够把表格和图进行互相转换,这一点可以带来非常多的优势,
现在很多框架也在渐渐的往这方面发展,例如GraphLib已经实现了可以读取Graph中的Data,也可以读取Table中的Data,也可以读取Text总的data即文本中的内容等,
与此同时Spark GraphX基于Spark也为GraphX增添了额外的很多优势,例如和mllib、Spark SQL协作等。
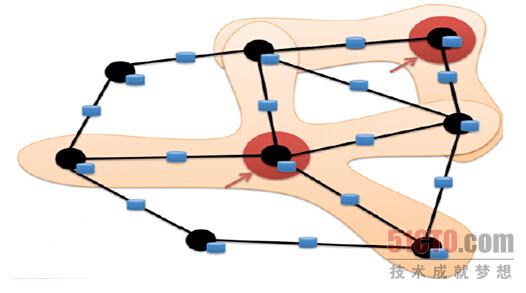
当今图计算领域对图的计算大多数只考虑邻居节点的计算,也就是说一个节点计算的时候只会考虑其邻居节点,对于非邻居节点是不关心的,如下图所示:
目前基于图的并行计算框架已经有很多,比如来自Google的Pregel、来自Apache开源的图计算框架Giraph,以及我们最为著名的GraphLab,当然也包含HAMA,其中Pregel、HAMA、Giraph都是非常类似的,都是基于BSP模型,
BSP模型实现了SuperStep即超步,BSP首先进行本地计算,然后进行全局的通信,然后进行全局的Barrier;
BSP最大的好处是编程简单,而其问题在于一些情况下BSP运算的性能非常差,
因为我们有一个全局Barrier的存在,所以系统速度取决于最慢的计算,也就把木桶原理体现无遗,
另外一方面,很多现实生活中的网络是符合幂律分布的,也就是定点、边等分布式很不均匀,所以在这种情况下BSP的木桶原理导致了性能问题会得到很大的放大,
对这个问题的解决,以GraphLab为例,使用了一种异步的概念而没有全部的Barrier;
最后,不得不提的一点是在Spark Graphx中可以用极为简洁的代码非常方便的使用Pregel的API。
基于图的计算框架的共同特点是抽象出了一批API来简化基于图的编程,这往往比一般的data-parellel系统的性能高出很多倍。
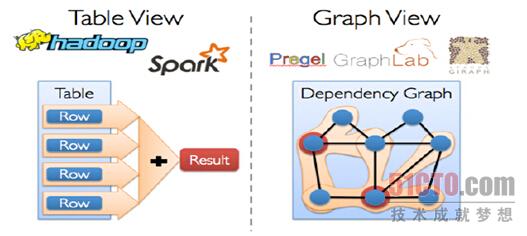
传统的图计算,往往需要不同的系统支持不同的View,
例如在Table View这种视图下可能需要Spark的支持或者Hadoop的支持,
而在Graph View这种视图下可能需要Pregel或者GraphLab的支持,
也就是把图和表分别在不同的系统中进行拉练处理,如下图所示:
上面所描述的图计算处理方式是传统的计算方式,当然现在除了Spark GraphX之外的图计算框架也在考虑这个问题;
不同系统带来的问题是之一是需要学习、部署和管理不同的系统,
例如要同时学习、部署和管理Hadoop、Hive、Spark、Giraph、GraphLab等:

大家都知道“Detail is evil”,如果我们能够用更少的框架解决更多的问题那是更好的。
其实最关键的问题还是效率问题,因为在不同的转换中间每步都要落地的话,数据转换和复制带来的开销也非常大,包括序列化带来的开销,同时中间结果和相应的结构无法重用,特别是一些结构性的东西,
譬如说顶点或者边的结构一直没有变,这种情况下结构内部的Structure是不需要改变的,而如果每次都重新构建的话,就算不变也无法重用,这回导致非常差的性能:
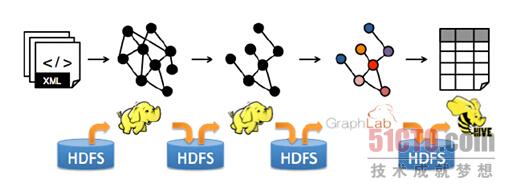
解决方案就是Spark GraphX,GarphX实现了Unified Representation,GraphX统一了Table View和Graph View,基于Spark可以非常轻松的做pipeline的操作:
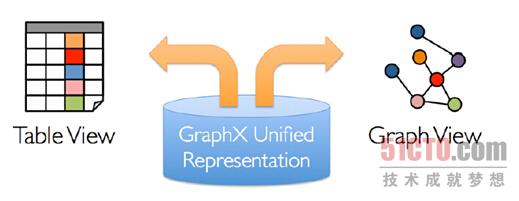
如果和Spark SQL结合,我们可以用SQL语句来进行ETL,然后放入GraphX来处理,是非常方便的。
在Spark GraphX中的Graph其实是Property Graph,也就是说图的每个顶点和边都是有属性的,如下图所示:
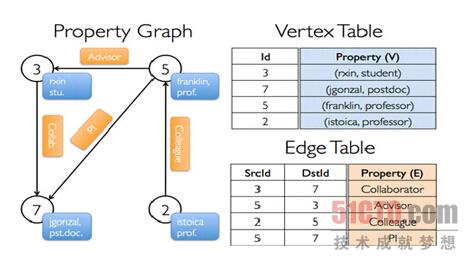
例如为3的顶点的名称为rxin,是学生stu.,5这个顶点是franlin,是一个prof.,5到3表明5是3的Advisor,上图中蓝色的表示的是相应顶点的Property,而黄色橙黄色部分表示的边的Property,边和顶点都是有ID的,对于顶点而言有自身的ID,而对于边来说有SourceID和DestinationID,即对于边而言会有两个ID来表达从哪个顶点出发到哪个顶点结束,来表明边的方向,这就是Property Graph的表示方法;如果把Property反映到表上的话,例如我们在Vertex Table中Id为的3的Property就是(rxin, student),而在Edge Table中3到7表明的边的Property是Collaborator的关系,2到5是Colleague的关系;更为重要的是Property Graph和Table之间是可以相互转换的,在GraphX中所有操作的基础是table operator和graph operator,,其继承自Spark中的RDD,都是针对集合进行操作。
Spark入门(1-5)Spark统一了TableView和GraphView的更多相关文章
- Spark入门2(Spark简析)
一.Spark核心概念-RDD RDD是弹性分布式数据集,一个RDD由多个partition构成,一个partition对应一个task.RDD的操作分为两种:Trasformation(把一个RDD ...
- Spark入门实战系列--10.分布式内存文件系统Tachyon介绍及安装部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Tachyon介绍 1.1 Tachyon简介 随着实时计算的需求日益增多,分布式内存计算 ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--5.Hive(上)--Hive介绍及部署
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Hive介绍 1.1 Hive介绍 月开源的一个数据仓库框架,提供了类似于SQL语法的HQ ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--6.SparkSQL(下)--Spark实战应用
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .运行环境说明 1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软件:VMwa ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- Spark入门:第1节 Spark概述:1 - 4
2.spark概述 2.1 什么是spark Apache Spark™ is a unified analytics engine for large-scale data processing. ...
随机推荐
- 【Unity与23种设计模式】责任链模式(Chain of Responsibility)
GoF中定义: "让一群对象都有机会来处理一项请求,以减少请求发送者与接收者之间的耦合度.将所有的接受对象串联起来,让请求沿着串接传递,直到有一个对象可以处理为止." 举个现实中的 ...
- 《Linux命令行与shell脚本编程大全》- 读书笔记3 - 理解shell
当用户登录终端的时候,通常会启动一个默认的交互式shell.系统究竟启动哪个shell,这取决于用户配置.一般这个shell都是/bin/shell.默认的系统shell(/bin/sh)用于系统sh ...
- nodejs简单数据迁移demo
近期做数据迁移,采用nodejs框架,数据库为mysql.作为一枚菜鸟,在编码过程中,遇到众多奇葩问题,感谢民少给予的支持. 由于旧数据库中的数据,在之前设计中存在众多不合理的情况,因此在数据迁移中, ...
- Dubbo源码-从HelloWorld开始
Dubbo简介 Dubbo,相信做后端的同学应该都用过,或者有所耳闻.没错,我就是那个有所耳闻中的一员. 公司在好几年前实现了一套自己的RPC框架,所以也就没有机会使用市面上琳琅满目的RPC框架产品. ...
- ReactNative环境配置的坑
我用的是windows开发android,mac的可以绕道了. 1.android studio及Android SDK的安装 现在需要的Android版本及对应的tool 2.真机运行要配置对and ...
- Shell 读取用户输入
14.2 读取用户输入 14.2.1 变量 上一章我们谈到如何定义或取消变量,变量可被设置为当前shell的局部变量,或是环境变量.如果您的shell脚本不需要调用其他脚本,其中的变量通常设置为脚 ...
- 源码实现 --> atoi函数实现
atoi函数实现 atoi()函数的功能是将一个字符串转换为一个整型数值. 例如“12345”,转换之后的数值为12345,“-0123”转换之后为-123. #include <stdio.h ...
- MyBatis-plus 代码生成器
1.添加pom文件依赖 <!-- Mybatis-Plus 自动生成实体类--> <dependency> <groupId>com.baomidou</gr ...
- Matlab绘图基础——图形修饰处理(入门)
引入--标题.色条.坐标轴.图例等 例一: set(groot,'defaultAxesLineStyleOrder','remove','defaultAxesColorOrder','remove ...
- sphinx的安装
1.下载sphinx 没想到sphinx3解压后即可: wget http://sphinxsearch.com/files/sphinx-3.0.2-2592786-linux-amd64.tar. ...