Apache Flink 分布式执行
Flink 的分布式执行过程包含两个重要的角色,master 和 worker,参与 Flink 程序执行的有多个进程,包括 Job Manager,Task Manager 以及 Job Client,下图展示了 Flink 程序的执行过程。

Flink 程序首先被提交到 Job Client 上,随后 Job Client 将它提交到 Job Manager 上,Job Manager 负责安排资源的分配和 job 的执行。首先是资源的分配,然后是将 job 划分为若干 task 后提交到对应的 Task Manager 上。Task Manager 在接收到 task 后,初始化一个线程并开始执行程序。执行过程中 Task Manager 持续地将状态的变化情况报告给 Job Manager,这些状态包括开始执行(starting the execution),正在执行(in progress)以及完成(finished)。一旦 job 的执行彻底完成,Job Manager 就将其结果发回 Job Client 端。
Job Manager
Job Manager 是执行过程中的 master 进程,负责协调和管理程序的执行,主要的内容包括调度任务(task),管理检查点(checkpoints)和故障恢复(failure recovery)等等。
可以并行地存在(running)多个 master 进程以共同承担这些职责,这对整个系统的高可用性有重要意义,其中有一个 master 是所谓的 leader 节点,如果它挂了,那么后备的 master 就会选出新的 leader 节点。
Job Manager 包括以下几个重要的组成部分,并发系统(Actor system),调度器(Scheduler)和检查点机制(Check pointing),其中 Flink 在 Job Manager 和 Task Manager 之间使用 Akka actor system 交互。
Actor system
所谓的 Actor system,就是一个包含承担各种角色(role)的 actor 的容器,它提供了诸如调度,配置和日志记录等等的服务。同时,它还控制着初始化所有这些 actor 的线程池(thread pool)。所有的 actor 都在一个层次系统下管理,每一个新创建的系统都会被赋予一个父节点(parent);Actor 之间使用消息系统通信,每个 actor 保持一个自己的邮箱(mailbox)并从其中阅读信息。在本地,信息通过共享内存来传递;在远程,信息使用 RPC 传递。
父节点需要管理它的子节点,子节点出问题的时候会向父节点发送信息,如果当前节点可以解决这个问题,那么它会通过重启子节点来解决,否则就将问题上报给自己的父节点。

Flink 中的 actor 是拥有自己状态(state)和行为(behavior)的容器,actor 逐条处理它从邮箱中收到的信息,根据收到的信息改变自己的状态和行为。
Scheduler
Flink 中任务的实际执行者(executor)被抽象为任务插槽(task slot),每个 Task Manager 都会管理若干个任务插槽。Flink 内部会通过 SlotSharingGroup 和 CoLocationGroup 决定哪些 task 需要共享插槽,哪些 task 需要在特殊的插槽上执行。
Check pointing
Check pointing 机制是 Flink 提供一致地故障处理机制的基石,它保持一致的分布式的数据流和执行者的状态的快照(snapshot)。这个机制受启发于 Chandy-Lamport 算法,不过也针对 Flink 自身的情况进行了定制,具体的快照实现在论文 Lightweight Asynchronous Snapshots for Distributed Dataflows 中。
这个独特的故障容忍机制使得 Flink 能够在数据流上创建轻量级的快照,一般而言,数据流的状态可被配置保存在 HDFS 一类的地方。
一旦出现故障,Flink 终止执行者的运行,将其状态重置到最近的快照上,并重启执行过程。
Flink 的快照机制的核心元素是流栅栏(stream barrier),这些栅栏在不影响流的情况下被插入到数据流中,将记录(record)收集起来形成快照。每一个栅栏都有一个唯一的 ID,下图是这一机制的概念图。
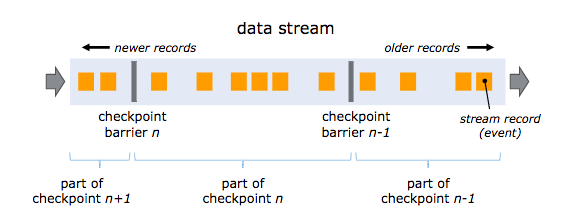
每一个快照的状态都会汇报给 Job Manager 上的检查点协调器,拍摄快照时,Flink 会对齐记录以避免因为故障而对同一条记录处理两次。对齐过程需要消耗若干毫秒,但对于无法忍受这种延迟的某些实时应用,Flink 也提供了关闭对齐的选项,此时快照仍然会在接收到栅栏时拍摄。默认情况下 Flink 开启对齐功能,这保证的 Excatly Once 的语义,关闭该功能时,只保证 At Least Once 的语义。
Task Manager
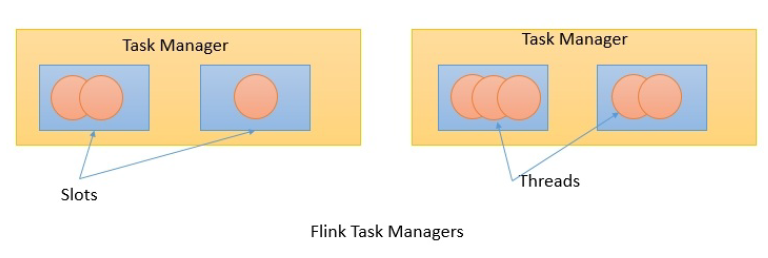
Task Manager 作为 worker 节点在 JVM 上运行,可以同时执行若干个线程以完成分配给它的 task,task 的并行度依赖于 Task Manager 上可用的任务插槽数量,每个 task 占据了分配给它的任务插槽的资源。例如,如果一个 Task Manager 拥有四个插槽,那么它大约会为每个插槽分配 25% 的内存。每个任务插槽上运行着若干个线程,同一个插槽上的线程共享同一个 JVM,同一个 JVM 上的任务共享 TCP 连接和心跳(heart beat)信息。
Job Client
Job Client 不是 Flink 任务执行过程的内部构件,而是执行过程的起始点。Job Client 负责接收用户提交的应用程序,创建对应的数据流,然后将数据流提交到 Job Manager 上执行。一旦执行完毕,Job Client 将执行结果发回给用户。
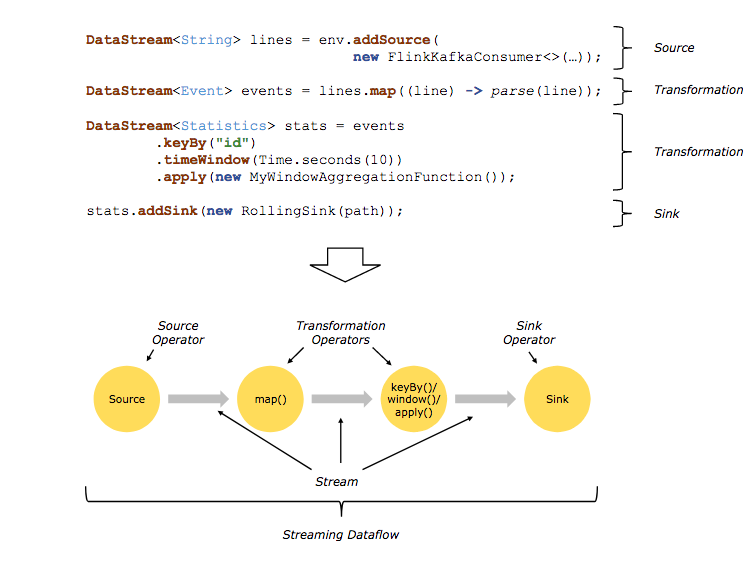
所谓的数据流(data flow)是一个执行的计划,Client 将接收的程序转换为对应的数据流的典型过程如下图所示。
Flink 数据流默认是并行地分布式地执行,因此实际的转化结果可能更像下面的图。
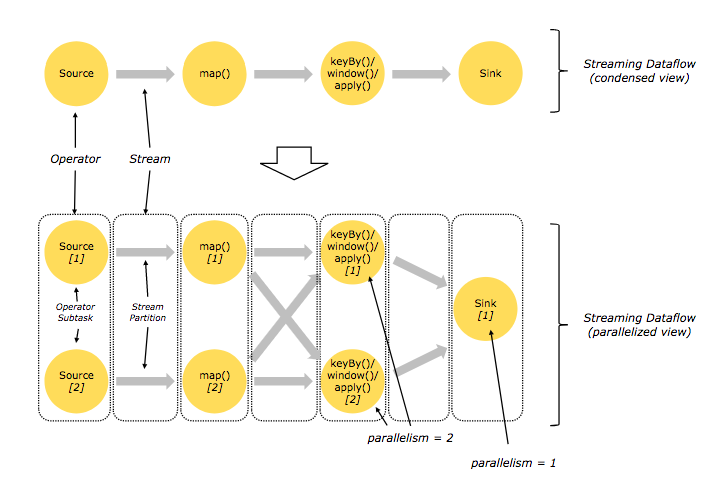
Flink 的分布式分发方式有 one-to-one 和 redistribute 两种。在上图中,从 Source 到 map 的过程即为 one-to-one 的方式,它保证原来的数据划分(partitioning)和排序(ordering)不会改变;从 map 到 keyBy/window 和 从 keyBy/window 到 Sink 的过程采用 redistribute 的分发方式,这种方式可能会打乱数据原有的划分情况和排序情况,对于 keyBy 来说,就是把相同的 key 的数据分发到同一个节点上,而对于最终的 Sink,由于并行执行,它收到的数据可能不是按照原有的排序情况到达的。
Apache Flink 分布式执行的更多相关文章
- Apache Flink 分布式运行时环境
Tasks and Operator Chains(任务及操作链) 在分布式环境下,Flink将操作的子任务链在一起组成一个任务,每一个任务在一个线程中执行.将操作链在一起是一个不错的优化:它减少了线 ...
- Apache Flink - 分布式运行环境
1.任务和操作链 下面的数据流图有5个子任务执行,因此有五个并行线程. 2.Job Managers, Task Managers, Clients Job Managers:协调分布式运行,他们安排 ...
- Apache Flink:特性、概念、组件栈、架构及原理分析
2016-04-30 22:24:39 Yanjun Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtim ...
- Apache Flink:详细入门
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能.现有的开源计算 ...
- Apache Flink任意Jar包上传导致远程代码执行漏洞复现
0x00 简介 Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎.Flink以数据并行和流水线方式执行任意流数据程序,Fl ...
- 「漏洞预警」Apache Flink 任意 Jar 包上传导致远程代码执行漏洞复现
漏洞描述 Apache Flink是一个用于分布式流和批处理数据的开放源码平台.Flink的核心是一个流数据流引擎,它为数据流上的分布式计算提供数据分发.通信和容错功能.Flink在流引擎之上构建批处 ...
- Apache Flink 进阶(六):Flink 作业执行深度解析
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink Contributor.网易云音乐实时计算平台研发工程师岳猛分享.主要分享内容为 Flink Job 执行作业的 ...
- Apache Flink
Flink 剖析 1.概述 在如今数据爆炸的时代,企业的数据量与日俱增,大数据产品层出不穷.今天给大家分享一款产品—— Apache Flink,目前,已是 Apache 顶级项目之一.那么,接下来, ...
- 新一代大数据处理引擎 Apache Flink
https://www.ibm.com/developerworks/cn/opensource/os-cn-apache-flink/index.html 大数据计算引擎的发展 这几年大数据的飞速发 ...
随机推荐
- 邮箱&&密码验证-原理
原理版: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- 云主机和vps的区别
云主机和vps的区别 近年来,IT行业开始热衷于各种云概念,而云主机就是其中之一,并且有越来越热之势.对普通用户而言,可能不太清楚云主机和VPS的区别,下面我们就来说说云主机和VPS到底有什么不同 ...
- firemonkey ListView DynamicAppearance
Go Up to FireMonkey Application Design Contents [hide] 1 Customizing the List View Appearance Prope ...
- 走近webpack(2)--css打包及压缩js
前面的文章介绍了webpack的devServer以及多入口多出口文件的配置,咱们继续往下学. 在开始学习接下来的知识之前,我们先回顾一下,前文提到了webpack的简单配置方法,但是只详细说了下入口 ...
- npm5 packag-lock.json
前几天升级了 Node.js v8.0 后,自带的 npm 也升级到了5.0,第一次使用的时候确实惊艳到了:原本重新安装一次模块要十几秒到事情,现在一秒多就搞定了.先不要激动,现在我来大概讲一下 np ...
- Ubuntu 14.04下Hadoop2.4.1集群安装配置教程
一.环境 系统: Ubuntu 14.04 64bit Hadoop版本: hadoop 2.4.1 (stable) JDK版本: OpenJDK 7 台作为Master,另3台作为Slave. 所 ...
- 将 Shiro 作为应用的权限基础 四:shiro的配置说明
Apache Shiro的配置主要分为四部分: SecurityManager的配置 URL过滤器的配置 静态用户配置 静态角色配置 其中,由于用户.角色一般由后台进行操作的动态数据,比如通过@Req ...
- 定位bug的姿势对吗?
举个例子来说明 WEB页面上数据显示错误,本来应该显示38, 结果显示35,这个时候你怎么去定位这个问题出在哪里? 1.通过fiddler抓包工具(或者其他抓包工具), 分析接口返回的数据是35还是 ...
- oracle 常用sql字符函数介绍
常用字符函数介绍 1.ascii 返回与指定的字符对应的十进制数: SQL>select ascii('A') A,ascii('a') a,ascii('0') zero,ascii(' ') ...
- Repeating Decimals UVA - 202
The / repeats indefinitely with no intervening digits. In fact, the decimal expansion of every ratio ...