SPPNET
SPPNet
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
文章地址:https://arxiv.org/pdf/1406.4729.pdf
摘要
沿着上一篇RCNN的思路,我们继续探索目标检测的痛点,其中RCNN使用CNN作为特征提取器,首次使得目标检测跨入深度学习的阶段。但是RCNN对于每一个区域候选都需要首先将图片放缩到固定的尺寸(224*224),然后为每个区域候选提取CNN特征。容易看出这里面存在的一些性能瓶颈:
- 速度瓶颈:重复为每个region proposal提取特征是极其费时的,Selective Search对于每幅图片产生2K左右个region proposal,也就是意味着一幅图片需要经过2K次的完整的CNN计算得到最终的结果。
- 性能瓶颈:对于所有的region proposal防缩到固定的尺寸会导致我们不期望看到的几何形变,而且由于速度瓶颈的存在,不可能采用多尺度或者是大量的数据增强去训练模型。
但是为什么CNN需要固定的输入呢?CNN网络可以分解为卷积网络部分以及全连接网络部分。我们知道卷积网络的参数主要是卷积核,完全能够适用任意大小的输入,并且能够产生任意大小的输出。但是全连接层部分不同,全连接层部分的参数是神经元对于所有输入的连接权重,也就是说输入尺寸不固定的话,全连接层参数的个数都不能固定。
何凯明团队的SPPNet给出的解决方案是,既然只有全连接层需要固定的输入,那么我们在全连接层前加入一个网络层,让他对任意的输入产生固定的输出不就好了吗?一种常见的想法是对于最后一层卷积层的输出pooling一下,但是这个pooling窗口的尺寸及步伐设置为相对值,也就是输出尺寸的一个比例值,这样对于任意输入经过这层后都能得到一个固定的输出。SPPnet在这个想法上继续加入SPM的思路,SPM其实在传统的机器学习特征提取中很常用,主要思路就是对于一副图像分成若干尺度的一些块,比如一幅图像分成1份,4份,8份等。然后对于每一块提取特征然后融合在一起,这样就可以兼容多个尺度的特征啦。SPPNet首次将这种思想应用在CNN中,对于卷积层特征我们也先给他分成不同的尺寸,然后每个尺寸提取一个固定维度的特征,最后拼接这些特征不就是一个固定维度的输入了吗?
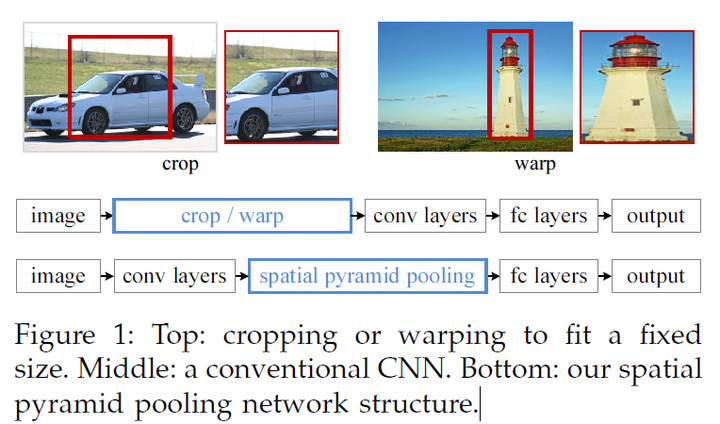 上面这个图可以看出SPPnet和RCNN的区别,首先是输入不需要放缩到指定大小。其次是增加了一个空间金字塔池化层,还有最重要的一点是每幅图片只需要提取一次特征。
上面这个图可以看出SPPnet和RCNN的区别,首先是输入不需要放缩到指定大小。其次是增加了一个空间金字塔池化层,还有最重要的一点是每幅图片只需要提取一次特征。
通过上述方法虽然解决了CNN输入任意大小图片的问题,但是还是需要重复为每个region proposal提取特征啊,能不能我们直接根据region proposal定位到他在卷积层特征的位置,然后直接对于这部分特征处理呢?答案是肯定的,我们将在下一章节介绍。
网络细节
- 卷积层特征图
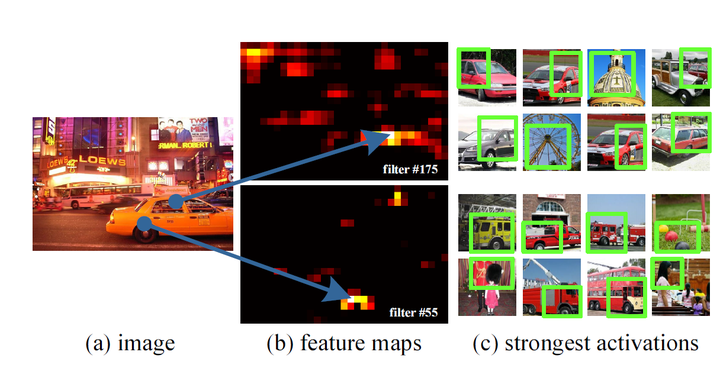 SPPNet通过可视化Conv5层特征,发现卷积特征其实保存了空间位置信息(数学推理中更容易发现这点),并且每一个卷积核负责提取不同的特征,比如C图175、55卷积核的特征,其中175负责提取窗口特征,55负责提取圆形的类似于车轮的特征。我们可以通过传统的方法聚集这些特征,例如词袋模型或是空间金字塔的方法。
SPPNet通过可视化Conv5层特征,发现卷积特征其实保存了空间位置信息(数学推理中更容易发现这点),并且每一个卷积核负责提取不同的特征,比如C图175、55卷积核的特征,其中175负责提取窗口特征,55负责提取圆形的类似于车轮的特征。我们可以通过传统的方法聚集这些特征,例如词袋模型或是空间金字塔的方法。
- 空间金字塔池化层
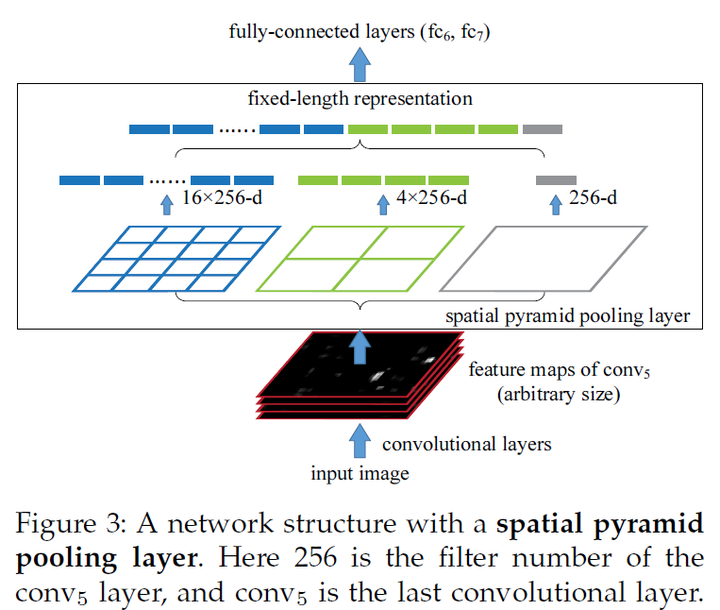 上图的空间金字塔池化层是SPPNet的核心,其主要目的是对于任意尺寸的输入产生固定大小的输出。思路是对于任意大小的feature map首先分成16、4、1个块,然后在每个块上最大池化,池化后的特征拼接得到一个固定维度的输出。以满足全连接层的需要。不过因为不是针对于目标检测的,所以输入的图像为一整副图像。
上图的空间金字塔池化层是SPPNet的核心,其主要目的是对于任意尺寸的输入产生固定大小的输出。思路是对于任意大小的feature map首先分成16、4、1个块,然后在每个块上最大池化,池化后的特征拼接得到一个固定维度的输出。以满足全连接层的需要。不过因为不是针对于目标检测的,所以输入的图像为一整副图像。
- SPPNet应用于图像分类
SPPNet的能够接受任意尺寸图片的输入,但是训练难点在于所有的深度学习框架都需要固定大小的输入,因此SPPNet做出了多阶段多尺寸训练方法。在每一个epoch的时候,我们先将图像放缩到一个size,然后训练网络。训练完整后保存网络的参数,然后resize 到另外一个尺寸,并在之前权值的基础上再次训练模型。相比于其他的CNN网络,SPPNet的优点是可以方便地进行多尺寸训练,而且对于同一个尺度,其特征也是个空间金字塔的特征,综合了多个特征的空间多尺度信息。
- SPPNet应用于目标检测
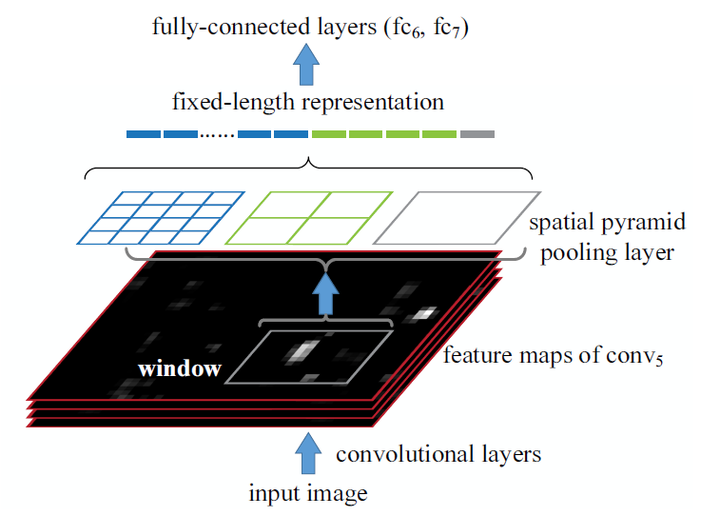 SPPNet理论上可以改进任何CNN网络,通过空间金字塔池化,使得CNN的特征不再是单一尺度的。但是SPPNet更适用于处理目标检测问题,首先是网络可以介绍任意大小的输入,也就是说能够很方便地多尺寸训练。其次是空间金字塔池化能够对于任意大小的输入产生固定的输出,这样使得一幅图片的多个region proposal提取一次特征成为可能。SPPNet的做法是:
SPPNet理论上可以改进任何CNN网络,通过空间金字塔池化,使得CNN的特征不再是单一尺度的。但是SPPNet更适用于处理目标检测问题,首先是网络可以介绍任意大小的输入,也就是说能够很方便地多尺寸训练。其次是空间金字塔池化能够对于任意大小的输入产生固定的输出,这样使得一幅图片的多个region proposal提取一次特征成为可能。SPPNet的做法是:
- 首先通过selective search产生一系列的region proposal,参见:目标检测(1)-Selective Search - 知乎专栏
- 然后训练多尺寸识别网络用以提取区域特征,其中处理方法是每个尺寸的最短边大小在尺寸集合中:
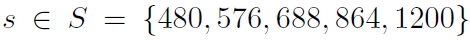
训练的时候通过上面提到的多尺寸训练方法,也就是在每个epoch中首先训练一个尺寸产生一个model,然后加载这个model并训练第二个尺寸,直到训练完所有的尺寸。空间金字塔池化使用的尺度为:1*1,2*2,3*3,6*6,一共是50个bins。
3.在测试时,每个region proposal选择能使其包含的像素个数最接近224*224的尺寸,提取相 应特征。
由于我们的空间金字塔池化可以接受任意大小的输入,因此对于每个region proposal将其映射到feature map上,然后仅对这一块feature map进行空间金字塔池化就可以得到固定维度的特征用以训练CNN了。关于从region proposal映射到feature map的细节我们待会儿去说。
4.训练SVM,BoundingBox回归
这部分和RCNN完全一致,参见:目标检测(2)-RCNN - 知乎专栏
- 实验结果
其中单一尺寸训练结果低于RCNN1.2%,但是速度是其102倍,5个尺寸的训练结果与RCNN相当,其速度为RCNN的38倍。
- 如何从一个region proposal 映射到feature map的位置?
SPPNet通过角点尽量将图像像素映射到feature map感受野的中央,假设每一层的padding都是p/2,p为卷积核大小。对于feature map的一个像素(x',y'),其实际感受野为:(Sx‘,Sy’),其中S为之前所有层步伐的乘积。然后对于region proposal的位置,我们获取左上右下两个点对应的feature map的位置,然后取特征就好了。左上角映射为:
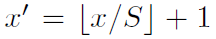 右下角映射为:
右下角映射为:
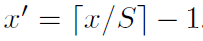 当然,如果padding大小不一致,那么就需要计算相应的偏移值啦。
当然,如果padding大小不一致,那么就需要计算相应的偏移值啦。
- 存在的不足
和RCNN一样,SPP也需要训练CNN提取特征,然后训练SVM分类这些特征。需要巨大的存储空间,并且分开训练也很复杂。而且selective search的方法提取特征是在CPU上进行的,相对于GPU来说还是比较慢的。针对这些问题的改进,我们将在Fast RCNN以及Faster RCNN中介绍,敬请期待。
SPPNET的更多相关文章
- RCNN 和SPPnet的对比
一.RCNN: 1.首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口. 2.把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个候选窗台提取出一个特征向量,也就是说 ...
- RCNN--对象检测的又一伟大跨越 2(包括SPPnet、Fast RCNN)(持续更新)
继续上次的学习笔记,在RCNN之后是Fast RCNN,但是在Fast RCNN之前,我们先来看一个叫做SPP-net的网络架构. 一,SPP(空间金字塔池化,Spatial Pyramid Pool ...
- 对sppnet网络的理解
前言: 接着上一篇文章提到的RCNN网络物体检测,这个网络成功的引入了CNN卷积网络来进行特征提取,但是存在一个问题,就是对需要进行特征提取图片大小有严格的限制.当时面对这种问题,rg大神采用的是对分 ...
- 读论文系列:Object Detection SPP-net
本文为您解读SPP-net: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Motivat ...
- SPP-Net理解
文章没有看完,先挑几个点谈一下. 1. 动机 在上一篇文章的末尾提到,RCNN做了很多重复计算,SPP就是为了解决这个问题而提出的的一个方法----空间金字塔池化. 感觉这个问题本质上还是全连接层对r ...
- SPP-net原理解读
转载自:目标检测:SPP-net 地址https://blog.csdn.net/tinyzhao/article/details/53717136 上文说到R-CNN的最大瓶颈是2k个候选区域都要经 ...
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD, R-FCN系列深度学习检测方法梳理
1. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation 技术路线:selec ...
- 目标检测(二) SPPNet
引言 先简单回顾一下R-CNN的问题,每张图片,通过 Selective Search 选择2000个建议框,通过变形,利用CNN提取特征,这是非常耗时的,而且,形变必然导致信息失真,最终影响模型的性 ...
- 目标检测算法(2)SPP-net
本文是使用深度学习进行目标检测系列的第二篇,主要介绍SPP-net:Spatial Pyramid Pooling in Deep ConvolutionalNetworks for Visual R ...
随机推荐
- mysql cluster部署
一.mysql cluster的基本概念 1.mysql cluster的组成 管理(MGM)节点:这类节点的作用是管理MySQL Cluster内的其他节点,如提供配置数据.启 ...
- 关于非现场审计软件的一些介绍(ACL、IEDA、Teammate)
http://group.vsharing.com/Article.aspx?aid=661512 IDEA是由caseware开发的数据分析软件.caseware的网址如下:http://www.c ...
- Android Java端的Socket.io-client
先讲讲历史,这个方面最早的应该是nkzawa@github的项目:http://mvnrepository.com/artifact/com.github.nkzawa/socket.io-clien ...
- Flask第三方工具组件介绍
flask-wtf组件flask-login组件flask-session组件flask-sqlalchemy组件flask-script组件flask-cache组件flask-assets组件fl ...
- 将Excel表中的数据导入到数据库
网上查到的有参考价值的就一家,自己调试发现可行.感谢原创文章:将Excel中数据导入数据库(一) using System; using System.Collections.Generic; usi ...
- jsoncpp linux平台编译和arm移植
下载 http://sourceforge.net/projects/jsoncpp/ 或者 http://download.csdn.net/detail/chinaeran/8631141 Lin ...
- HTML语义化基础
body { background-color: rgb(60,60,60) } 为使页面呈现较好的内容结构,所以对网页进行布局时,将页面相关元素集中在一起,形成页眉.文章.页脚.侧边栏等元素块,刚开 ...
- hibernate多表查询封装实体
以前用sql实现联合查询 是非常简单的事,只需要写sql语句就可以,第一次遇到hibernate要实现多表联合查询的时候还楞了一下.最后看了下资料,才恍然大悟,hibernate实现多表联合查询跟SQ ...
- 影响 MySQL Server 性能的相关因素
MySQL 最多的使用场景是WEB 应用,那么我们就以一个WEB 应用系统为例,逐个分析其系统构成,进行经验总结,分析出数据库应用系统中各个环境对性能的影响. 商业需求对性能的影响 这里我们就拿一个看 ...
- 微信H5中静默登录及非静默登录的正确使用姿势
在微信中打开网页且需要调用微信登录接口时,微信官方给我们提供了两种登录调用方式:静默登录和非静默登录:但是官方文档中却没有说明在何种情况下使用静默登录,何种情况下使用非静默登录,所以在这里,我想将之前 ...