浅谈surging服务引擎中的rabbitmq组件和容器化部署
1、前言
上个星期完成了surging 的0.9.0.1 更新工作,此版本通过nuget下载引擎组件,下载后,无需通过代码build集成,引擎会通过Sidecar模式自动扫描装配异构组件来构建服务引擎,而这篇将介绍浅谈surging服务引擎中的rabbitmq组件和容器化部署
2、Sidecar模式
比如现在比较火的Service Mesh, 谈到Service Mesh,就不得不了解下Sidecar模式,Sidecar设计模式被越来越多的关注和采用,此模式之所以称作Sidecar,是因为它类似于三轮摩托车上的挎斗。 在此模式中,挎斗附加到应用程序中,为应用程序提供支持性功能。挎斗与应用程序具有相同的生命周期:与应用程序一起创建,一起停用。 挎斗模式有时也称为搭档模式,这是一种分解模式。而surging 采用了Sidecar模式用来附加组件,而使用Sidecar模式有以下功能
- 共享存储空间
引擎组件部署到共享的文件目录里,服务引擎从共享的文件目录扫描引擎组件文件。
- 共享组件和业务的配置文件
针对于组件的配置文件部署到共享的文件目录里,服务引擎从共享的文件目录加载文件。
- 独立的业务服务
针对于业务可以把依赖的组件打包部署到共享的文件目录里,服务引擎从共享的文件目录扫描加载,从而部署成独立的业务服务
- 内置多种协议
针对于独立部署的业务服务,内置了多种协议,提供给服务和外部程序进行调用
模式特点
隔离:让组件都能够关注核心问题。比如eventbus、Logger、 netty 在实现功能的同时无需关注其它组件的实现而发生的冲突;
单一责任原则:每个组件都应该职责分开,而根据这一原则,职责应该是对应一个类、模块或者接口,从而能够独立进行处理。
内聚性/可重用性:针对组件的特性,方法可以进行重用,从而满足组件可持续扩展。
3、基于Event Bus 的Rabbitmq组件
surging服务引擎扩展了基于eventbus 的rabbitmq ,组件可以选择绑定 Normal,Retry(Dead letter),Fail ,如下图所示。
而针对于该组件有哪些应用场景呢?
- 商品秒杀和抢购
抢购/秒杀是如今很常见的一个应用场景,在高并发的流量访问下可以将用户放入到抢购队列中,购买成功则销毁消息。
- 最终数据的一致性
在大型业务中,系统一般由多个独立的服务组成,在分布式调用时候把消息放入到rabbitmq 队列中,再通过消息的幂等性来解决数据的最终一致性
- 订单失效处理
在购买商品/服务生成订单业务中,会设定支付时间,如果一直未支付,会直接关闭订单,而这个场景可以通过死信队列的来解决

示例代码
可以通过继承BaseIntegrationEventHandler或者IIntegrationEventHandler,再通过QueueConsumer特性进行标识,具体代码如下
[QueueConsumer("UserLoginDateChangeHandler",QueueConsumerMode.Normal)]
public class UserLoginDateChangeHandler : BaseIntegrationEventHandler<UserEvent>
{
private readonly IUserService _userService;
public UserLoginDateChangeHandler()
{
_userService = ServiceLocator.GetService<IUserService>("User");
}
public override async Task Handle(UserEvent @event)
{
Console.WriteLine($"消费1。");
await _userService.Update(@event.UserId, new UserModel()
{
Age = @event.Age,
Name = @event.Name,
UserId = @event.UserId
});
Console.WriteLine($"消费1失败。");
throw new Exception();
}
public override Task Handled(EventContext context)
{
Console.WriteLine($"调用{context.Count}次。类型:{context.Type}");
var model = context.Content as UserEvent;
return Task.CompletedTask;
}
}
可以通过以下选项去更改配置
"EventBus": {
"EventBusConnection": "${EventBusConnection}|localhost",
"EventBusUserName": "${EventBusUserName}|guest",//用户名
"EventBusPassword": "${EventBusPassword}|guest",//密码
"VirtualHost": "${VirtualHost}|/",
"MessageTTL": "${MessageTTL}|30000",//消息过期时间,比如过期时间是30分钟就是1800000
"RetryCount": "${RetryCount}|1",//重试次数,这里设置的延迟队列,只能设置为1
"FailCount": "${FailCount}|3",//处理失败流程重试次数,如果出现异常,会进行重试
"prefetchCount": "${PrefetchCount}|0",//设置均匀分配消费者消息的个数
"BrokerName": "${BrokerName}|surging_demo",//exchange 名称
"Port": "${EventBusPort}|5672"//端口
}
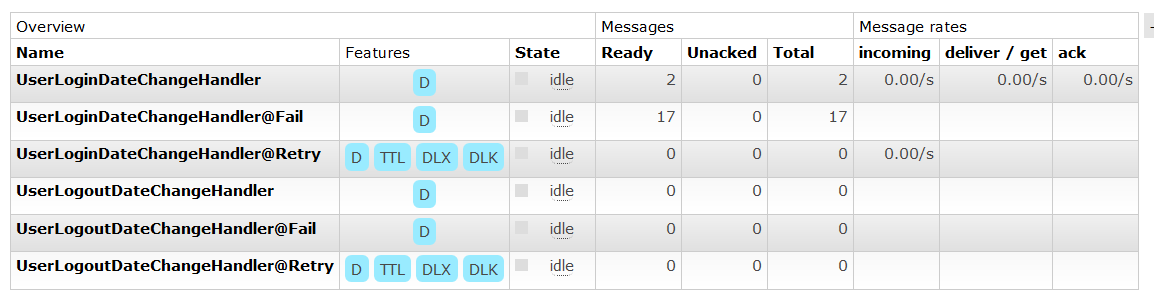
生成绑定的队列如下图
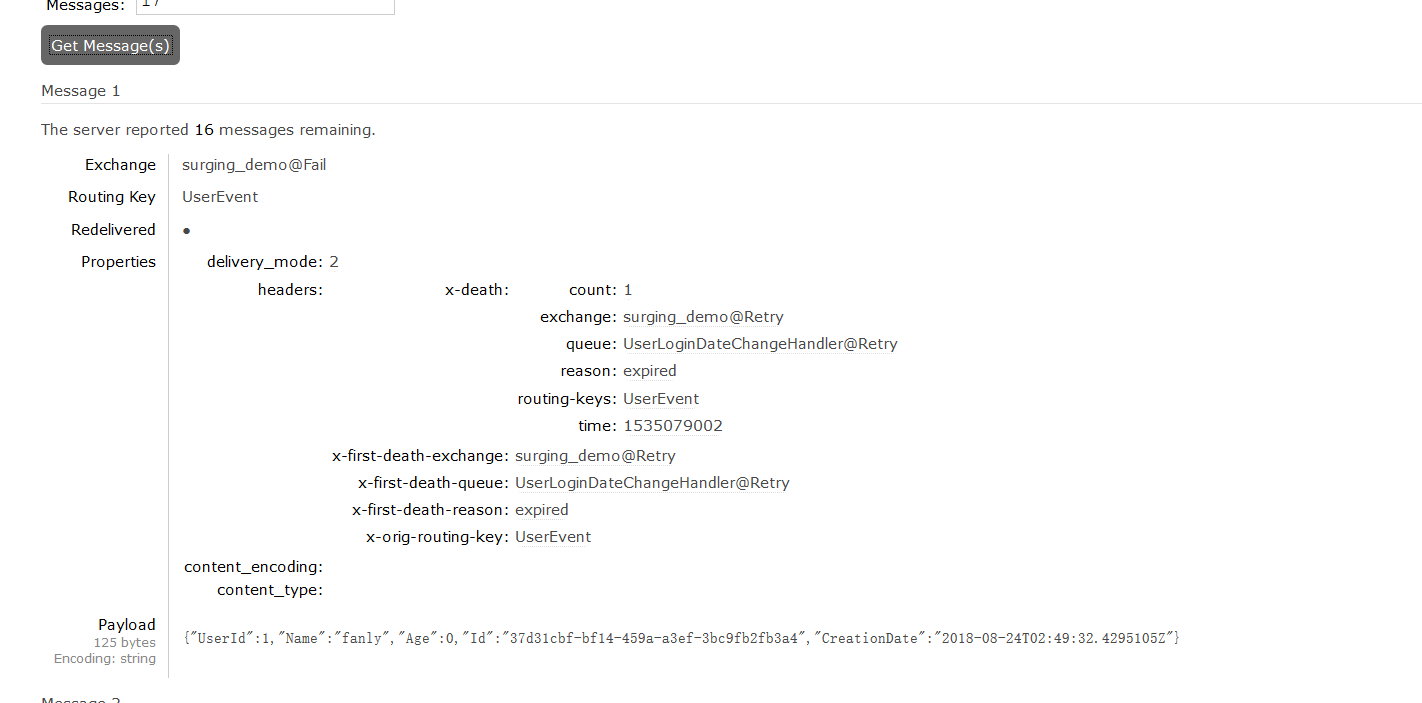
通过rabbitmq管理工具,可以通过properties来查看重试次数count 等一些信息,如下图所示
4、如何部署
surging 服务引擎构建镜像部署在docker中,可以按照业务需求自定义化引擎,也可以从 docker hub中pull镜像,可以按照如下流程从docker hub 拉取部署镜像
如何pull镜像
可以通过命令:
docker pull serviceengine/surging
可以指定具体的tag来拉取,比如需要拉取v0.9.0.2,执行以下命令
docker pull serviceengine/surging:v0.9.0.
如何配置
1.镜像可以用环境变量设置相关参数,而通过以下的默认配置文件知晓如何通过环境变量配置参数,配置的规则:${环境变量名}|默认值
{
"Surging": {
"Ip": "${Surging_Server_IP}|0.0.0.0",
"WatchInterval": ,
"Port": "${Surging_Server_Port}|99",
"MappingIp": "${Mapping_ip}",
"MappingPort": "${Mapping_Port}",
"Token": "true",
"MaxConcurrentRequests": ,
"ExecutionTimeoutInMilliseconds": ,
"Protocol": "${Protocol}|None", //Http、Tcp、None
"RootPath": "${RootPath}|D:\\userapp",
"Ports": {
"HttpPort": "${HttpPort}|280",
"WSPort": "${WSPort}|96"
},
"RequestCacheEnabled": false,
"Packages": [
{
"TypeName": "EnginePartModule",
"Using": "${UseEngineParts}|DotNettyModule;NLogModule;MessagePackModule;ConsulModule;HttpProtocolModule;WSProtocolModule;EventBusRabbitMQModule;"
}
]
}, //如果引用多个同类型的组件,需要配置Packages,如果是自定义按需引用,无需配置Packages
"Consul": {
"ConnectionString": "${Register_Conn}|127.0.0.1:8500", // "127.0.0.1:8500",
"SessionTimeout": "${Register_SessionTimeout}|50",
"RoutePath": "${Register_RoutePath}",
"ReloadOnChange": true
},
"EventBus_Kafka": {
"Servers": "${EventBusConnection}|localhost:9092",
"MaxQueueBuffering": "${MaxQueueBuffering}|10",
"MaxSocketBlocking": "${MaxSocketBlocking}|10",
"EnableAutoCommit": "${EnableAutoCommit}|false",
"LogConnectionClose": "${LogConnectionClose}|false",
"OffsetReset": "${OffsetReset}|earliest",
"GroupID": "${EventBusGroupID}|surgingdemo"
},
"EventBus": {
"EventBusConnection": "${EventBusConnection}|localhost",
"EventBusUserName": "${EventBusUserName}|guest",
"EventBusPassword": "${EventBusPassword}|guest",
"VirtualHost": "${VirtualHost}|/",
"MessageTTL": "${MessageTTL}|30000",
"RetryCount": "${RetryCount}|1",
"FailCount": "${FailCount}|3",
"BrokerName": "${BrokerName}|surging_demo",
"Port": "${EventBusPort}|5672"
},
"Zookeeper": {
"ConnectionString": "${Zookeeper_ConnectionString}|127.0.0.1:2181",
"SessionTimeout": ,
"ReloadOnChange": true
},
"Logging": {
"Debug": {
"LogLevel": {
"Default": "Information"
}
},
"Console": {
"IncludeScopes": true,
"LogLevel": {
"Default": "${LogLevel}|Debug"
}
},
"LogLevel": {
"Default": "${LogLevel}|Debug"
}
}
}
2.可以通过设置环境变量surgingpath和cachepath来指定自定义文件配置,比如,挂载/home/fanly 目录,通过以下命令参数 -v /home/fanly:/home/fanly 来设定,再通过设置以下命令参数用来设定自定义文件配置
--env surgingpath=/home/fanly/configs/surgingSettings.json
--env cachepath=/home/fanly/configs/cacheSettings.json
如何启动内置引擎组件
引擎可以加载多个同一类型的引擎组件,可以通过以下配置启用哪一种引擎组件,如果是自定义的服务引擎,不需要配置以下配置,只需要按照需求引用组件
"Packages": [
{
"TypeName": "EnginePartModule",
"Using": "${UseEngineParts}|DotNettyModule;NLogModule;MessagePackModule;ConsulModule;HttpProtocolModule;WSProtocolModule;EventBusRabbitMQModule;"
}
]
如何启动引擎
比如 pull 的镜像是serviceengine/surging:v0.9.0.2 ,可以按照以下命令进行启动
docker run --name surging --env surgingpath=/home/fanly/configs/surgingSettings.json --env cachepath=/home/fanly/configs/cacheSettings.json -v /home/fanly:/home/fanly serviceengine/surging:v0.9.0.
7.总结
如有问题请到这里提问 ,可以加入surging互相交流QQ群:542283494,引擎组件扩展沟通群:615562965
浅谈surging服务引擎中的rabbitmq组件和容器化部署的更多相关文章
- 浅谈Chrome V8引擎中的垃圾回收机制
垃圾回收器 JavaScript的垃圾回收器 JavaScript使用垃圾回收机制来自动管理内存.垃圾回收是一把双刃剑,其好处是可以大幅简化程序的内存管理代码,降低程序员的负担,减少因 长时间运转而带 ...
- 浅谈线程池(中):独立线程池的作用及IO线程池
原文地址:http://blog.zhaojie.me/2009/07/thread-pool-2-dedicate-pool-and-io-pool.html 在上一篇文章中,我们简单讨论了线程池的 ...
- 浅谈如何检查Linux中开放端口列表
给大家分享一篇关于如何检查Linux中的开放端口列表的详细介绍,首先如果你想检查远程Linux系统上的端口是否打开请点击链接浏览.如果你想检查多个远程Linux系统上的端口是否打开请点击链接浏览.如果 ...
- 浅谈dedecms模板引擎工作原理及其自定义标签
浅谈dedecms模板引擎工作原理: 理解织梦模板引擎有什么意思? 可以更好地自定义标签.更多在于了解织梦系统,理解模板引擎是理解织梦工作原理的第一步. 理解织梦会使我们写PHP代码是更顺手,同时能学 ...
- 浅谈微服务架构与服务治理的Eureka和Dubbo
前言 本来计划周五+周末三天自驾游,谁知人算不如天算,周六恰逢台风来袭,湖州附近的景点全部关停,不得已只能周五玩完之后,于周六踩着台风的边缘逃回上海.周末过得如此艰难,这次就聊点务虚的话题,一是浅谈微 ...
- 【ASP.NET MVC系列】浅谈NuGet在VS中的运用
一 概述 在我们讲解NuGet前,我们先来看看一个例子. 1.例子: 假设现在开发一套系统,其中前端框架我们选择Bootstrap,由于选择Bootstrap作为前端框架,因此,在项目中,我们 ...
- 谈谈surging引擎的tcp、http、ws协议和如何容器化部署
1.前言 分布式已经成为了当前最热门的话题,分布式框架也百花齐放,群雄逐鹿.从中心化服务治理框架,到去中心化分布式服务框架,再到分布式微服务引擎,这都是通过技术不断积累改进而形成的结果.esb,网关, ...
- 1. 容器化部署一套云服务 第一讲 Jenkins(Docker + Jenkins + Yii2 + 云服务器))
容器化部署一套云服务系列 1. 容器化部署一套云服务之Jenkins 一.购买服务器 服务器
- 浅谈MySQL存储引擎-InnoDB&MyISAM
存储引擎在MySQL的逻辑架构中位于第三层,负责MySQL中的数据的存储和提取.MySQL存储引擎有很多,不同的存储引擎保存数据和索引的方式是不同的.每一种存储引擎都有它的优势和劣势,本文只讨论最常见 ...
随机推荐
- 学习AD、DA的体会
AD转换器的转换是指模拟信号输入转化为数字信号输出,而DA转换器是把数字信号转换为模拟信号,在ADC0832.TLC549和TLC5615程序设计中,通过使用中断服务函数每0.5s对ADC0832进行 ...
- Java中的String类型
1.基本类型和引用类型 在C语言里面,是有指针这么一个变量类型的,指针变量保存的就是所要指向内容的地址.在Java里面,没有了指针的这么个说法,而是换了一个词:引用类型变量. 先说Java里面的基本类 ...
- bestcoder round 74 div2
随便看了一场以前的bestcoder,然后顺便写了一下,都不码的样子 有中文题面,这里就不写题目大意了 T1. 刚开始想复杂了,T1可能是4道题里面想的最久的 我们大概弄一下就可以发现,如果a[i]& ...
- VueJs 权限管理
程序运行时,router只配置登陆 首页404 等基本页面 import Main from '@/views/Main.vue'; // 不作为Main组件的子页面展示的页面单独写,如下 expor ...
- WBS 与 甘特图
WBS:工作分解结构(Work Breakdown Structure) 创建WBS:创建WBS是把项目 交付成果和项目工作分解成较小的,更易于管理的组成部分的过程. WBS是项目管理重要的专业术语之 ...
- 【转】mysql索引使用技巧及注意事项
一.索引的作用 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化显然是重中之重. 在数据 ...
- PAT1002:A+B for Polynomials
1002. A+B for Polynomials (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue T ...
- linux内核裁剪及编译可加载模块
一:linux内核裁剪: 1:编译内核源码: 今天的重点内容是内核驱动的编写,在编写驱动之前首先的了解linux内核源码,linux主要是由五个子系统组成:进程调度,内存管理,文件系统,网络接口以及进 ...
- datePicker.js 应用
var calendar2 = new datePicker();calendar.init({ 'trigger': '#datetime-picker-start', /*选择器,触发弹出插件*/ ...
- 《Spring Cloud与Docker微服务架构实战》配套代码
不才写了本使用Spring Cloud玩转微服务架构的书,书名是<Spring Cloud与Docker微服务架构实战> - 周立,已于2017-01-12交稿.不少朋友想先看看源码,现将 ...