python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做。
一直对爬虫很好奇,所以不妨从爬虫先入手吧。
Python版本:3.6
这是我看的教程:Python - Jack -Cui -CSDN
大概学了一下urllib,beautifulsoup这两个库,也看了一些官方文档,学会了这两个库的大概的用法。
urllib用来爬取url的内容,如html文档等。beautifulsoup是用来解析html文档,就像js的DOM操作一样。简单流程如下:
from urllib import request
from bs4 import BeautifulSoup
#urllib操作
url = 'http://blog.csdn.net/'
#编辑header,至少要把User-Agent写上,否则python会自动加上,导致直接被有反爬虫机制的网站识别
#有很多网站会有个Content-Encoding=gzip,进行后面的输出时一定要gzip解压缩,具体怎么解压缩,看看这个:https://www.jianshu.com/p/2c2781462902
headers = {
'Connection' : 'keep-alive',
'Cache-Control' : 'max-age=0',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'
}
req = request.Request(url, headers=headers)
response = request.urlopen(req)
html = response.read()
#输出html内容
print(html)
#beautifulsoup操作
soup = BeautifulSoup(html, 'lxml')
#选取所有a标签
a_tags = soup.find_all('a')
#获得a标签中的内容(string属性)
for item in a_tags:
print(item.string)
基础内容差不多就这些,下面来爬一下煎蛋。
先看一下其源代码,发现源html中并没有图片的链接,而是只有一个没有url的img标签和一个有img-hash属性的span标签
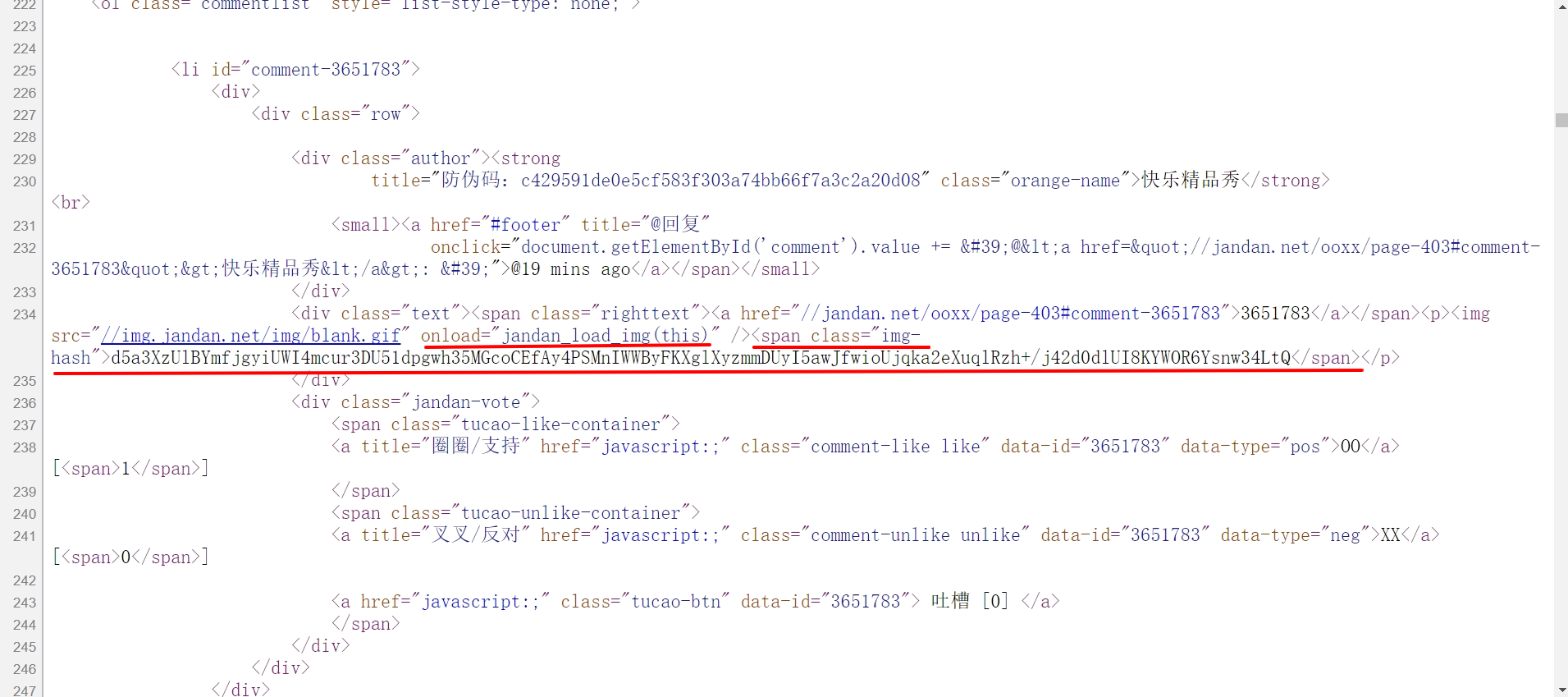
查看js文件,寻找jandan_load_img()函数

分析可知,由span的img-hash属性的值和一个固定的hash作为参数,传入一个f_开头的函数,将返回值直接插入html文档中的a的href中,可见,返回值就是图片的真实url。所以思路有了:用python模拟js的函数,先取img-hash的值,再传入一个解密函数(对应f_开头函数),得到图片url。再看一下jandan_load_img()函数,取回url之后,如果文件后缀名为.gif,则在其中加入'thumb180'字符串,这个好做。
下面直接贴个源码吧:
#!/usr/bin/env python3
from bs4 import BeautifulSoup
from urllib import request
import argparse
import hashlib
import base64
import gzip
import time
import os
import io
import re
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36',
'Accept-Encoding':'gzip, deflate',
'Accept-Language':'zh-CN,zh;q=0.9',
}
def md5(src):
m = hashlib.md5()
m.update(src.encode('utf-8'))
return m.hexdigest()
def decode_base64(data):
missing_padding=4-len(data)%4
if missing_padding:
data += '='* missing_padding
return base64.b64decode(data)
def calculate_url(img_hash, constant):
k = 'DECODE'
q = 4
constant = md5(constant)
o = md5(constant[0:16])
#n = md5(constant[16:16])
n = md5(constant[16:32])
l = img_hash[0:q]
c = o+md5(o + l)
img_hash = img_hash[q:]
k = decode_base64(img_hash)
h = []
for g in range(256):
h.append(g)
b = []
for g in range(256):
b.append(ord(c[g % len(c)]))
f = 0
for g in range(256):
f = (f + h[g] + b[g]) % 256
tmp = h[g]
h[g] = h[f]
h[f] = tmp
t = ""
f = 0
p = 0
for g in range(len(k)):
p = (p + 1) % 256
f = (f + h[p]) % 256
tmp = h[p]
h[p] = h[f]
h[f] = tmp
t += chr(k[g] ^ (h[(h[p] + h[f]) % 256]))
t = t[26:]
return t
def get_raw_html(url):
req = request.Request(url=url, headers=headers)
response = request.urlopen(req)
text = response.read()
encoding = response.getheader('Content-Encoding')
if encoding == 'gzip':
buf = io.BytesIO(text)
translated_raw = gzip.GzipFile(fileobj=buf)
text = translated_raw.read()
text = text.decode('utf-8')
return text
def get_soup(html):
soup = BeautifulSoup(html, 'lxml')
return soup
def get_preurl(soup):
preurl = 'http:'+soup.find(class_='previous-comment-page').get('href')
return preurl
def get_hashesAndConstant(soup, html):
hashes = []
for each in soup.find_all(class_='img-hash'):
hashes.append(each.string)
js = re.search(r'<script\ssrc=\"\/\/(cdn.jandan.net\/static\/min\/.*?)\">.*?<\/script>', html)
jsFileURL = 'http://'+js.group(1)
jsFile = get_raw_html(jsFileURL)
target_func = re.search(r'f_\w*?\(e,\"(\w*?)\"\)', jsFile)
constant_hash = target_func.group(1)
return hashes, constant_hash
def download_images(urls):
if not os.path.exists('downloads'):
os.makedirs('downloads')
for url in urls:
filename = ''
file_suffix = re.match(r'.*(\.\w+)', url).group(1)
filename = md5(str(time.time()))+file_suffix
request.urlretrieve(url, 'downloads/'+filename)
time.sleep(3)
def spider(url, page):
#get hashes, constant-hash, previous page's url
html = get_raw_html(url)
soup = get_soup(html)
params = get_hashesAndConstant(soup, html)
hashes = params[0]
constant_hash = params[1]
preurl = get_preurl(soup)
urls = []
index = 1
for each in hashes:
real_url = 'http:'+calculate_url(each, constant_hash)
replace = re.match(r'(\/\/w+\.sinaimg\.cn\/)(\w+)(\/.+\.gif)', real_url)
if replace:
real_url = replace.group(1)+'thumb180'+replace.group(3)
urls.append(real_url)
index += 1
download_images(urls)
page -= 1
if page > 0:
spider(preurl, page)
if __name__ == '__main__':
#user interface
parser = argparse.ArgumentParser(description='download images from Jandan.net')
parser.add_argument('-p', metavar='PAGE', default=1, type=int, help='the number of pages you want to download (default 1)')
args = parser.parse_args()
#start crawling
url = 'http://jandan.net/ooxx/'
spider(url, args.p)
防止被识别,采取了以下措施:
运行的时候可以加个-p参数,是要下载的页数,默认是1。
每爬一张图片暂停3s,为了防止被服务器识别,你们嫌慢的话可以改短一点。
下载的图片保存在当前目录的downloads文件夹下(没有则创建)。
ps:用Windows的同学请注意!这里说的当前目录不是指这个python文件的路径,而是cmd中的当前路径!我一开始是在Linux上做的,后来在Windows测试的时候一直找不到downloads文件夹,把源代码检查了好久,最后才发现是路径问题。。
pps:此项目也可以在我的Github中找到(更有.exe文件等你来发现~滑稽)。
参考:
http://blog.csdn.net/c406495762/article/details/71158264
http://blog.csdn.net/van_brilliant/article/details/78723878
python爬虫–爬取煎蛋网妹子图片的更多相关文章
- python爬虫爬取煎蛋网妹子图片
import urllib.request import os def url_open(url): req = urllib.request.Request(url) req.add_header( ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
- Python 爬取煎蛋网妹子图片
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-24 10:17:28 # @Author : EnderZhou (z ...
- Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改 修改一:修改爬虫执行方式 ...
- python3爬虫爬取煎蛋网妹纸图片(上篇)
其实之前实现过这个功能,是使用selenium模拟浏览器页面点击来完成的,但是效率实际上相对来说较低.本次以解密参数来完成爬取的过程. 首先打开煎蛋网http://jandan.net/ooxx,查看 ...
- python3爬虫爬取煎蛋网妹纸图片(下篇)2018.6.25有效
分析完了真实图片链接地址,下面要做的就是写代码去实现了.想直接看源代码的可以点击这里 大致思路是:获取一个页面的的html---->使用正则表达式提取出图片hash值并进行base64解码--- ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
随机推荐
- sql server 内存初探
一. 前言 对于sql server 这个产品来说,内存这块是最重要的一个资源, 当我们新建一个会话,相同的sql语句查询第二次查询时间往往会比第一次快,特别是在sql统计或大量查询数据输出时,会有这 ...
- 关于find命令的一些知识
在服务器运维的过程中,我们会用到这样一个命令,关于这个命令,你知道多少呢?接下来,咱们一起来研究一下它的用途. find命令主要用来在硬盘上搜索文件, find命令主要用于文件查找,列出当前目录及子目 ...
- Windows 下python 环境安装
1.先在官网上下载安装包,官网地址: https://www.python.org 2. 选择自己需要的版本进行安装,最好选择新版本下载, 3. 下载完成后,双击运行安装,一直next,直至 ...
- C#中使用Bogus创建模拟数据
原文:CREATING SAMPLE DATA FOR C# 作者:Bruno Sonnino 译文:C#中使用Bogus创建模拟数据 译者: Lamond Lu 背景 在我每次写技术类博文的时候,经 ...
- eShopOnContainers 知多少[5]:EventBus With RabbitMQ
1. 引言 事件总线这个概念对你来说可能很陌生,但提到观察者(发布-订阅)模式,你也许就很熟悉.事件总线是对发布-订阅模式的一种实现.它是一种集中式事件处理机制,允许不同的组件之间进行彼此通信而又不需 ...
- java提高(15)---java深浅拷贝
#java深浅拷贝 一.前言 为什么会有深浅拷贝这个概念? 我觉得主要跟JVM内存分配有关,对于基本数据类型,只存在栈内存,所以它的拷贝不存在深浅拷贝这个概念.而对于对象而言,一个对象的创建会在内存中 ...
- 我为什么放弃MySQL?最终选择了MongoDB
最近有个项目的功能模块,为了处理方便,需要操作集合类型的数据以及其他原因.考虑再三最终决定放弃使用MySQL,而选择MongoDB. 两个数据库,大家应该都不陌生.他们最大的区别就是MySQL为关系型 ...
- 《k8s-1.13版本源码分析》-调度器初始化
源码分析系列文章已经开源到github,地址如下: github:https://github.com/farmer-hutao/k8s-source-code-analysis gitbook:ht ...
- Go map实现原理
map结构 整体为一个数组,数组每个元素可以理解成一个槽,槽是一个链表结构,槽的每个节点可存8个元素,搞清楚了map的结构,想想对应的增删改查操作也不是那么难
- 【4】Asp.Net Core2.2中间件多扩展对应应用
[前言] 上一篇完成了Asp.Net Core 2.2全新的管道处理模型解析,“俄罗斯套娃”式的委托嵌套和传递,组建了扩展性无与伦比的管道模型!与此同时,委托嵌套过于复杂,使用起来并不友好,然后多种扩 ...