ActiveMq笔记1-消息可靠性理论
原博客:http://shift-alt-ctrl.iteye.com/blog/2020182
https://mp.weixin.qq.com/s/h74d6LtGB5M8VF0oLrXdCA
我们先看一消息的声明周期如下图:
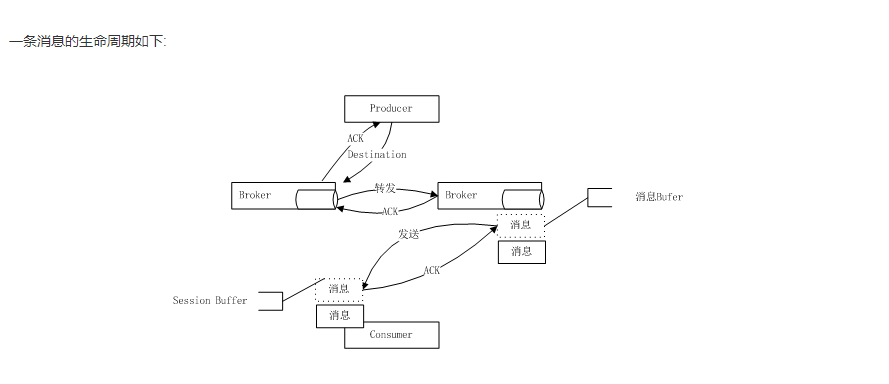
图片中简单的描述了一条消息的生命周期,不过在不同的架构环境中,message的流动行可能更加复杂.将在稍后有关broker的架构中详解..一条消息从producer端发出之后,一旦被broker正确保存,那么它将会被consumer消费,然后ACK,broker端才会删除;不过当消息过期或者存储设备溢出时,也会终结它。
1.ACK机制
JMS API中约定了Client端可以使用四种ACK模式,在javax.jms.Session接口中:
- AUTO_ACKNOWLEDGE = 1 自动确认
- CLIENT_ACKNOWLEDGE = 2 客户端手动确认 如下图:

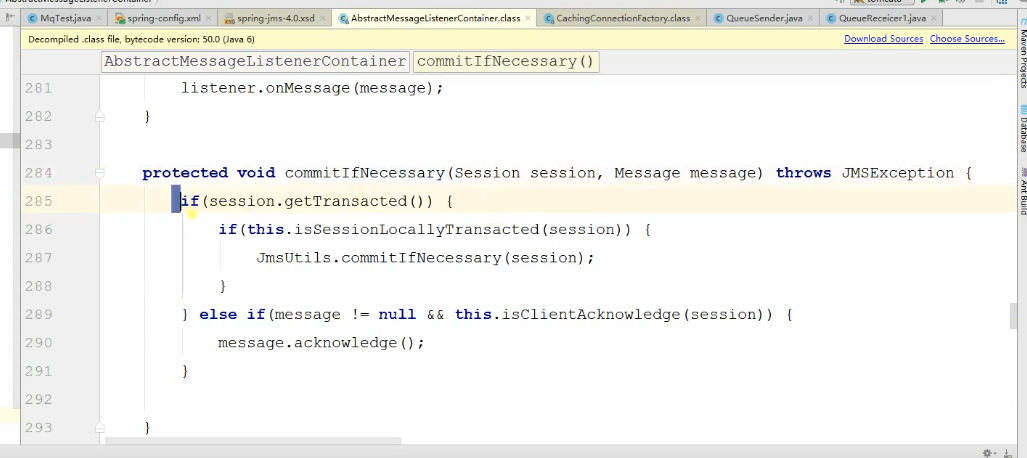
如果不写这行代码,会默认即消费失败的,就不会出队列。会一直存着,知道你ACK确认后。注意:JMS里面已经帮你封装过了,无论你在配置中如何配置都不会生效的,JMS源码里面的配置如下图:


- DUPS_OK_ACKNOWLEDGE = 3 自动批量确认
- SESSION_TRANSACTED = 0 事务提交并确认
此外AcitveMQ补充了一个自定义的ACK模式:
- INDIVIDUAL_ACKNOWLEDGE = 4 单条消息确认
我们在开发JMS应用程序的时候,会经常使用到上述ACK模式,其中"INDIVIDUAL_ACKNOWLEDGE "只有ActiveMQ支持,当然开发者也可以使用它. ACK模式描述了Consumer与broker确认消息的方式(时机),比如当消息被Consumer接收之后,Consumer将在何时确认消息。对于broker而言,只有接收到ACK指令,才会认为消息被正确的接收或者处理成功了,通过ACK,可以在consumer(/producer)与Broker之间建立一种简单的“担保”机制.
Client端指定了ACK模式,但是在Client与broker在交换ACK指令的时候,还需要告知ACK_TYPE,ACK_TYPE表示此确认指令的类型,不同的ACK_TYPE将传递着消息的状态,broker可以根据不同的ACK_TYPE对消息进行不同的操作。
比如Consumer消费消息时出现异常,就需要向broker发送ACK指令,ACK_TYPE为"REDELIVERED_ACK_TYPE",那么broker就会重新发送此消息。在JMS API中并没有定义ACT_TYPE,因为它通常是一种内部机制,并不会面向开发者。ActiveMQ中定义了如下几种ACK_TYPE(参看MessageAck类):
- DELIVERED_ACK_TYPE = 0 消息"已接收",但尚未处理结束
- STANDARD_ACK_TYPE = 2 "标准"类型,通常表示为消息"处理成功",broker端可以删除消息了
- POSION_ACK_TYPE = 1 消息"错误",通常表示"抛弃"此消息,比如消息重发多次后,都无法正确处理时,消息将会被删除或者DLQ(死信队列)
- REDELIVERED_ACK_TYPE = 3 消息需"重发",比如consumer处理消息时抛出了异常,broker稍后会重新发送此消息
- INDIVIDUAL_ACK_TYPE = 4 表示只确认"单条消息",无论在任何ACK_MODE下
- UNMATCHED_ACK_TYPE = 5 在Topic中,如果一条消息在转发给“订阅者”时,发现此消息不符合Selector过滤条件,那么此消息将 不会转发给订阅者,消息将会被存储引擎删除(相当于在Broker上确认了消息)。
到目前为止,我们已经清楚了大概的原理: Client端在不同的ACK模式时,将意味着在不同的时机发送ACK指令,每个ACK Command中会包含ACK_TYPE,那么broker端就可以根据ACK_TYPE来决定此消息的后续操作. 接下来,我们详细的分析ACK模式与ACK_TYPE.
我们需要在创建Session时指定ACK模式,由此可见,ACK模式将是session共享的,意味着一个session下所有的 consumer都使用同一种ACK模式。在创建Session时,开发者不能指定除ACK模式列表之外的其他值.如果此session为事务类型,用户指定的ACK模式将被忽略,而强制使用"SESSION_TRANSACTED"类型;如果session非事务类型时,也将不能将 ACK模式设定为"SESSION_TRANSACTED",毕竟这是相悖的.
Consumer消费消息的风格有2种: 同步/异步..使用consumer.receive()就是同步,使用messageListener就是异步;在同一个consumer中,我们不能同时使用这2种风格,比如在使用listener的情况下,当调用receive()方法将会获得一个Exception。两种风格下,消息确认时机有所不同。
同步调用时,在消息从receive方法返回之前,就已经调用了ACK;因此如果Client端没有处理成功,此消息将丢失(可能重发,与ACK模式有关)。
基于异步调用时,消息的确认是在onMessage方法返回之后,如果onMessage方法异常,会导致消息不能被ACK,会触发重发。
ACK模式详解
AUTO_ACKNOWLEDGE : 自动确认,这就意味着消息的确认时机将有consumer择机确认."择机确认"似乎充满了不确定性,这也意味着,开发者必须明确知道"择机确认"的具体时机,否则将有可能导致消息的丢失,或者消息的重复接收.那么在ActiveMQ中,AUTO_ACKNOWLEDGE是如何运作的呢?
1) 对于consumer而言,optimizeAcknowledge属性只会在AUTO_ACK模式下有效。
2) 其中DUPS_ACKNOWLEGE也是一种潜在的AUTO_ACK,只是确认消息的条数和时间上有所不同。
3) 在“同步”(receive)方法返回message之前,会检测optimizeACK选项是否开启,如果没有开启,此单条消息将立即确认,所以在这种情况下,message返回之后,如果开发者在处理message过程中出现异常,会导致此消息也不会redelivery,即"潜在的消息丢失";如果开启了optimizeACK,则会在unAck数量达到prefetch * 0.65时确认,当然我们可以指定prefetchSize = 1来实现逐条消息确认。
4) 在"异步"(messageListener)方式中,将会首先调用listener.onMessage(message),此后再ACK,如果onMessage方法异常,将导致client端补充发送一个ACK_TYPE为REDELIVERED_ACK_TYPE确认指令;如果onMessage方法正常,消息将会正常确认(STANDARD_ACK_TYPE)。此外需要注意,消息的重发次数是有限制的,每条消息中都会包含“redeliveryCounter”计数器,用来表示此消息已经被重发的次数,如果重发次数达到阀值,将会导致发送一个ACK_TYPE为POSION_ACK_TYPE确认指令,这就导致broker端认为此消息无法消费,此消息将会被删除或者迁移到"dead letter"通道中。
因此当我们使用messageListener方式消费消息时,通常建议在onMessage方法中使用try-catch,这样可以在处理消息出错时记录一些信息,而不是让consumer不断去重发消息;如果你没有使用try-catch,就有可能会因为异常而导致消息重复接收的问题,需要注意你的onMessage方法中逻辑是否能够兼容对重复消息的判断
CLIENT_ACKNOWLEDGE : 客户端手动确认,这就意味着AcitveMQ将不会“自作主张”的为你ACK任何消息,开发者需要自己择机确认。在此模式下,开发者需要需要关注几个方法:1) message.acknowledge(),2) ActiveMQMessageConsumer.acknowledege(),3) ActiveMQSession.acknowledge();其1)和3)是等效的,将当前session中所有consumer中尚未ACK的消息都一起确认,2)只会对当前consumer中那些尚未确认的消息进行确认。开发者可以在合适的时机必须调用一次上述方法。为了避免混乱,对于这种ACK模式下,建议一个session下只有一个consumer。
我们通常会在基于Group(消息分组)情况下会使用CLIENT_ACKNOWLEDGE,我们将在一个group的消息序列接受完毕之后确认消息(组);不过当你认为消息很重要,只有当消息被正确处理之后才能确认时,也可以使用此模式 。
如果开发者忘记调用acknowledge方法,将会导致当consumer重启后,会接受到重复消息,因为对于broker而言,那些尚未真正ACK的消息被视为“未消费”。
开发者可以在当前消息处理成功之后,立即调用message.acknowledge()方法来"逐个"确认消息,这样可以尽可能的减少因网络故障而导致消息重发的个数;当然也可以处理多条消息之后,间歇性的调用acknowledge方法来一次确认多条消息,减少ack的次数来提升consumer的效率,不过这仍然是一个利弊权衡的问题。
除了message.acknowledge()方法之外,ActiveMQMessageConumser.acknowledge()和ActiveMQSession.acknowledge()也可以确认消息,只不过前者只会确认当前consumer中的消息。其中sesson.acknowledge()和message.acknowledge()是等效的。
无论是“同步”/“异步”,ActiveMQ都不会发送STANDARD_ACK_TYPE,直到message.acknowledge()调用。如果在client端未确认的消息个数达到prefetchSize * 0.5时,会补充发送一个ACK_TYPE为DELIVERED_ACK_TYPE的确认指令,这会触发broker端可以继续push消息到client端。(参看PrefetchSubscription.acknwoledge方法)
在broker端,针对每个Consumer,都会保存一个因为"DELIVERED_ACK_TYPE"而“拖延”的消息个数,这个参数为prefetchExtension,事实上这个值不会大于prefetchSize * 0.5,因为Consumer端会严格控制DELIVERED_ACK_TYPE指令发送的时机(参见ActiveMQMessageConsumer.ackLater方法),broker端通过“prefetchExtension”与prefetchSize互相配合,来决定即将push给client端的消息个数,count = prefetchExtension + prefetchSize - dispatched.size(),其中dispatched表示已经发送给client端但是还没有“STANDARD_ACK_TYPE”的消息总量;由此可见,在CLIENT_ACK模式下,足够快速的调用acknowledge()方法是决定consumer端消费消息的速率;如果client端因为某种原因导致acknowledge方法未被执行,将导致大量消息不能被确认,broker端将不会push消息,事实上client端将处于“假死”状态,而无法继续消费消息。我们要求client端在消费1.5*prefetchSize个消息之前,必须acknowledge()一次;通常我们总是每消费一个消息调用一次,这是一种良好的设计。
此外需要额外的补充一下:所有ACK指令都是依次发送给broker端,在CLIET_ACK模式下,消息在交付给listener之前,都会首先创建一个DELIVERED_ACK_TYPE的ACK指令,直到client端未确认的消息达到"prefetchSize * 0.5"时才会发送此ACK指令,如果在此之前,开发者调用了acknowledge()方法,会导致消息直接被确认(STANDARD_ACK_TYPE)。broker端通常会认为“DELIVERED_ACK_TYPE”确认指令是一种“slow consumer”信号,如果consumer不能及时的对消息进行acknowledge而导致broker端阻塞,那么此consumer将会被标记为“slow”,此后queue中的消息将会转发给其他Consumer。
DUPS_OK_ACKNOWLEDGE : "消息可重复"确认,意思是此模式下,可能会出现重复消息,并不是一条消息需要发送多次ACK才行。它是一种潜在的"AUTO_ACK"确认机制,为批量确认而生,而且具有“延迟”确认的特点。对于开发者而言,这种模式下的代码结构和AUTO_ACKNOWLEDGE一样,不需要像CLIENT_ACKNOWLEDGE那样调用acknowledge()方法来确认消息。
1) 在ActiveMQ中,如果在Destination是Queue通道,我们真的可以认为DUPS_OK_ACK就是“AUTO_ACK + optimizeACK + (prefetch > 0)”这种情况,在确认时机上几乎完全一致;此外在此模式下,如果prefetchSize =1 或者没有开启optimizeACK,也会导致消息逐条确认,从而失去批量确认的特性。
2) 如果Destination为Topic,DUPS_OK_ACKNOWLEDGE才会产生JMS规范中诠释的意义,即无论optimizeACK是否开启,都会在消费的消息个数>=prefetch * 0.5时,批量确认(STANDARD_ACK_TYPE),在此过程中,不会发送DELIVERED_ACK_TYPE的确认指令,这是1)和AUTO_ACK的最大的区别。
这也意味着,当consumer故障重启后,那些尚未ACK的消息会重新发送过来。
SESSION_TRANSACTED : 当session使用事务时,就是使用此模式。在事务开启之后,和session.commit()之前,所有消费的消息,要么全部正常确认,要么全部redelivery。这种严谨性,通常在基于GROUP(消息分组)或者其他场景下特别适合。在SESSION_TRANSACTED模式下,optimizeACK并不能发挥任何效果,因为在此模式下,optimizeACK会被强制设定为false,不过prefetch仍然可以决定DELIVERED_ACK_TYPE的发送时机。
因为Session非线程安全,那么当前session下所有的consumer都会共享同一个transactionContext;同时建议,一个事务类型的Session中只有一个Consumer,以避免rollback()或者commit()方法被多个consumer调用而造成的消息混乱。
当consumer接受到消息之后,首先检测TransactionContext是否已经开启,如果没有,就会开启并生成新的transactionId,并把信息发送给broker;此后将检测事务中已经消费的消息个数是否 >= prefetch * 0.5,如果大于则补充发送一个“DELIVERED_ACK_TYPE”的确认指令;这时就开始调用onMessage()方法,如果是同步(receive),那么即返回message。上述过程,和其他确认模式没有任何特殊的地方。
当开发者决定事务可以提交时,必须调用session.commit()方法,commit方法将会导致当前session的事务中所有消息立即被确认;事务的确认过程中,首先把本地的deliveredMessage队列中尚未确认的消息全部确认(STANDARD_ACK_TYPE);此后向broker发送transaction提交指令并等待broker反馈,如果broker端事务操作成功,那么将会把本地deliveredMessage队列清空,新的事务开始;如果broker端事务操作失败(此时broker已经rollback),那么对于session而言,将执行inner-rollback,这个rollback所做的事情,就是将当前事务中的消息清空并要求broker重发(REDELIVERED_ACK_TYPE),同时commit方法将抛出异常。
当session.commit方法异常时,对于开发者而言通常是调用session.rollback()回滚事务(事实上开发者不调用也没有问题),当然你可以在事务开始之后的任何时机调用rollback(),rollback意味着当前事务的结束,事务中所有的消息都将被重发。需要注意,无论是inner-rollback还是调用session.rollback()而导致消息重发,都会导致message.redeliveryCounter计数器增加,最终都会受限于brokerUrl中配置的"jms.redeliveryPolicy.maximumRedeliveries",如果rollback的次数过多,而达到重发次数的上限时,消息将会被DLQ(dead letter)。
INDIVIDUAL_ACKNOWLEDGE : 单条消息确认,这种确认模式,我们很少使用,它的确认时机和CLIENT_ACKNOWLEDGE几乎一样,当消息消费成功之后,需要调用message.acknowledege来确认此消息(单条),而CLIENT_ACKNOWLEDGE模式先message.acknowledge()方法将导致整个session中所有消息被确认(批量确认)。
optimizeACK
"可优化的ACK",这是ActiveMQ对于consumer在消息消费时,对消息ACK的优化选项,也是consumer端最重要的优化参数之一,
1) 在brokerUrl中增加如下查询字符串:
String brokerUrl = "tcp://localhost:61616?" + "jms.optimizeAcknowledge=true" + "&jms.optimizeAcknowledgeTimeOut=30000" + "&jms.redeliveryPolicy.maximumRedeliveries=6"; ActiveMQConnectionFactory factory = new ActiveMQConnectionFactory(brokerUrl);
2) 在destinationUri中,增加如下查询字符串:
String queueName = "test-queue?customer.prefetchSize=100";
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
Destination queue = session.createQueue(queueName);
我们需要在brokerUrl指定optimizeACK选项,在destinationUri中指定prefetchSize(预获取)选项,其中brokerUrl参数选项是全局的,即当前factory下所有的connection/session/consumer都会默认使用这些值;而destinationUri中的选项,只会在使用此destination的consumer实例中有效;如果同时指定,brokerUrl中的参数选项值将会被覆盖。optimizeAck表示是否开启“优化ACK”,只有在为true的情况下,prefetchSize(下文中将会简写成prefetch)以及optimizeAcknowledgeTimeout参数才会有意义。此处需要注意"optimizeAcknowledgeTimeout"选项只能在brokerUrl中配置。
prefetch值建议在destinationUri中指定,因为在brokerUrl中指定比较繁琐;在brokerUrl中,queuePrefetchSize和topicPrefetchSize都需要单独设定:"&jms.prefetchPolicy.queuePrefetch=12&jms.prefetchPolicy.topicPrefetch=12"等来逐个指定。
如果prefetchACK为true,那么prefetch必须大于0;当prefetchACK为false时,你可以指定prefetch为0以及任意大小的正数。不过,当prefetch=0是,表示consumer将使用PULL(拉取)的方式从broker端获取消息,broker端将不会主动push消息给client端,直到client端发送PullCommand时;当prefetch>0时,就开启了broker push模式,此后只要当client端消费且ACK了一定的消息之后,会立即push给client端多条消息。
当consumer端使用receive()方法同步获取消息时,prefetch可以为0和任意正值;当prefetch=0时,那么receive()方法将会首先发送一个PULL指令并阻塞,直到broker端返回消息为止,这也意味着消息只能逐个获取(类似于Request<->Response),这也是Activemq中PULL消息模式;当prefetch > 0时,broker端将会批量push给client 一定数量的消息(<= prefetch),client端会把这些消息(unconsumedMessage)放入到本地的队列中,只要此队列有消息,那么receive方法将会立即返回,当一定量的消息ACK之后,broker端会继续批量push消息给client端。
当consumer端使用MessageListener异步获取消息时,这就需要开发设定的prefetch值必须 >=1,即至少为1;在异步消费消息模式中,设定prefetch=0,是相悖的,也将获得一个Exception。
此外,我们还可以brokerUrl中配置“redelivery”策略,比如当一条消息处理异常时,broker端可以重发的最大次数;和下文中提到REDELIVERED_ACK_TYPE互相协同。当消息需要broker端重发时,consumer会首先在本地的“deliveredMessage队列”(Consumer已经接收但还未确认的消息队列)删除它,然后向broker发送“REDELIVERED_ACK_TYPE”类型的确认指令,broker将会把指令中指定的消息重新添加到pendingQueue(亟待发送给consumer的消息队列)中,直到合适的时机,再次push给client。
到目前为止,或许你知道了optimizeACK和prefeth的大概意义,不过我们可能还会有些疑惑!!optimizeACK和prefetch配合,将会达成一个高效的消息消费模型:批量获取消息,并“延迟”确认(ACK)。prefetch表达了“批量获取”消息的语义,broker端主动的批量push多条消息给client端,总比client多次发送PULL指令然后broker返回一条消息的方式要优秀很多,它不仅减少了client端在获取消息时阻塞的次数和阻塞的时间,还能够大大的减少网络开支。optimizeACK表达了“延迟确认”的语义(ACK时机),client端在消费消息后暂且不发送ACK,而是把它缓存下来(pendingACK),等到这些消息的条数达到一定阀值时,只需要通过一个ACK指令把它们全部确认;这比对每条消息都逐个确认,在性能上要提高很多。由此可见,prefetch优化了消息传送的性能,optimizeACK优化了消息确认的性能。
当consumer端消息消费的速率很高(相对于producer生产消息),而且消息的数量也很大时(比如消息源源不断的生产),我们使用optimizeACK + prefetch将会极大的提升consumer的性能。不过反过来:
1) 如果consumer端消费速度很慢(对消息的处理是耗时的),过大的prefetchSize,并不能有效的提升性能,反而不利于consumer端的负载均衡(只针对queue);按照良好的设计准则,当consumer消费速度很慢时,我们通常会部署多个consumer客户端,并使用较小的prefetch,同时关闭optimizeACK,可以让消息在多个consumer间“负载均衡”(即均匀的发送给每个consumer);如果较大的prefetchSize,将会导致broker一次性push给client大量的消息,但是这些消息需要很久才能ACK(消息积压),而且在client故障时,还会导致这些消息的重发。
2) 如果consumer端消费速度很快,但是producer端生成消息的速率较慢,比如生产者10秒钟生成10条消息,但是consumer一秒就能消费完毕,而且我们还部署了多个consumer!!这种场景下,建议开启optimizeACK,但是需要设置的prefetchSize不能过大;这样可以保证每个consumer都能有"活干",否则将会出现一个consumer非常忙碌,但是其他consumer几乎收不到消息。
3) 如果消息很重要,特别是不愿意接收到”redelivery“的消息,那么我们需要将optimizeACK=false,prefetchSize=1
既然optimizeACK是”延迟“确认,那么就引入一种潜在的风险:在消息被消费之后还没有来得及确认时,client端发生故障,那么这些消息就有可能会被重新发送给其他consumer,那么这种风险就需要client端能够容忍“重复”消息。
prefetch值默认为1000,当然这个值可能在很多场景下是偏大的;我们暂且不考虑ACK模式(参见下文),通常情况下,我们只需要简单的统计出单个consumer每秒的最大消费消息数即可,比如一个consumer每秒可以处理100个消息,我们期望consumer端每2秒确认一次,那么我们的prefetchSize可以设置为100 * 2 /0.65大概为300。无论如何设定此值,client持有的消息条数最大为:prefetch + “DELIVERED_ACK_TYPE消息条数”(DELIVERED_ACK_TYPE参见下文)
即使当optimizeACK为true,也只会当session的ACK模式为AUTO_ACKNOWLEDGE时才会生效,即在其他类型的ACK模式时consumer端仍然不会“延迟确认”,即:
consumer.optimizeAck = connection.optimizeACK && session.isAutoAcknowledge()
当consumer.optimizeACK有效时,如果客户端已经消费但尚未确认的消息(deliveredMessage)达到prefetch * 0.65,consumer端将会自动进行ACK;同时如果离上一次ACK的时间间隔,已经超过"optimizeAcknowledgeTimout"毫秒,也会导致自动进行ACK。
此外简单的补充一下,批量确认消息时,只需要在ACK指令中指明“firstMessageId”和“lastMessageId”即可,即消息区间,那么broker端就知道此consumer(根据consumerId识别)需要确认哪些消息。
最后让我们想一下,如何保证消息队列做最终一致性的时候消息不会丢失和重复消费呢?
我们可以通过幂等的方式实现。所谓的幂等就是多次调用,结果和一次调用一致。即我们通过生产者发送消息带一个MessageID来到Broker,Broker已经收到了,返回ACK给生产者,如果此时发生网络故障了,生产者没收到ACK,生产者以为Broker没收到ACK,生产者重传消息。这样造成重复消费,如果我们通过通过生产者发送消息带一个MessageID来到Broker,Broker记录这个MessageID,Broker已经收到了,返回ACK给生产者,如果此时发生网络故障了,生产者没收到ACK,生产者以为Broker没收到ACK,生产者重传消息并再次附带MessageID,Broker根据这个MessageID核对本地是否有这个MessageID,如果有,返回ACK给生产者,对生产者再次发来的Message丢弃不管。这样就解决了队列做最终一致性的时候消息不会丢失和重复消费。
一、缘起
《消息总线消息必达》所述,MQ消息必达,架构上有两个核心设计点:
(1)消息落地
(2)消息超时、重传、确认
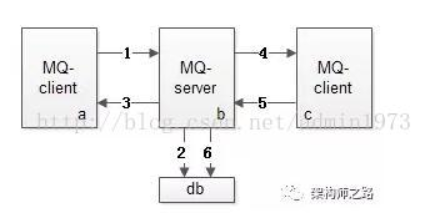
再次回顾消息总线核心架构,它由发送端、服务端、固化存储、接收端四大部分组成。
为保证消息的可达性,超时、重传、确认机制可能导致消息总线、或者业务方收到重复的消息,从而对业务产生影响。
举个例子:
购买会员卡,上游支付系统负责给用户扣款,下游系统负责给用户发卡,通过MQ异步通知。不管是上半场的ACK丢失,导致MQ收到重复的消息,还是下半场ACK丢失,导致购卡系统收到重复的购卡通知,都可能出现,上游扣了一次钱,下游发了多张卡。
消息总线的幂等性设计至关重要,是本文将要讨论的重点。
二、上半场的幂等性设计
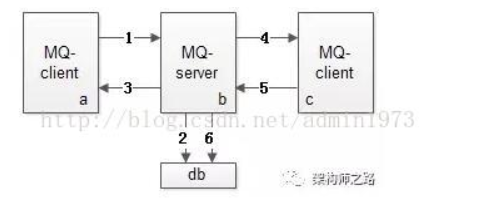
MQ消息发送上半场,即上图中的1-3
1,发送端MQ-client将消息发给服务端MQ-server
2,服务端MQ-server将消息落地
3,服务端MQ-server回ACK给发送端MQ-client
如果3丢失,发送端MQ-client超时后会重发消息,可能导致服务端MQ-server收到重复消息。
此时重发是MQ-client发起的,消息的处理是MQ-server,为了避免步骤2落地重复的消息,对每条消息,MQ系统内部必须生成一个inner-msg-id,作为去重和幂等的依据,这个内部消息ID的特性是:
(1)全局唯一
(2)MQ生成,具备业务无关性,对消息发送方和消息接收方屏蔽
有了这个inner-msg-id,就能保证上半场重发,也只有1条消息落到MQ-server的DB中,实现上半场幂等。
三、下半场的幂等性设计
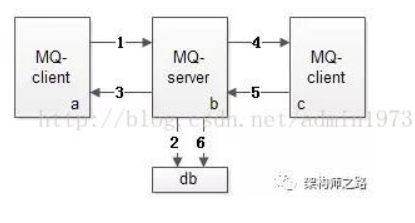
MQ消息发送下半场,即上图中的4-6
4,服务端MQ-server将消息发给接收端MQ-client
5,接收端MQ-client回ACK给服务端
6,服务端MQ-server将落地消息删除
需要强调的是,接收端MQ-client回ACK给服务端MQ-server,是消息消费业务方的主动调用行为,不能由MQ-client自动发起,因为MQ系统不知道消费方什么时候真正消费成功。
如果5丢失,服务端MQ-server超时后会重发消息,可能导致MQ-client收到重复的消息。
此时重发是MQ-server发起的,消息的处理是消息消费业务方,消息重发势必导致业务方重复消费(上例中的一次付款,重复发卡),为了保证业务幂等性,业务消息体中,必须有一个biz-id,作为去重和幂等的依据,这个业务ID的特性是:
(1)对于同一个业务场景,全局唯一
(2)由业务消息发送方生成,业务相关,对MQ透明
(3)由业务消息消费方负责判重,以保证幂等
最常见的业务ID有:支付ID,订单ID,帖子ID等。
具体到支付购卡场景,发送方必须将支付ID放到消息体中,消费方必须对同一个支付ID进行判重,保证购卡的幂等。
有了这个业务ID,才能够保证下半场消息消费业务方即使收到重复消息,也只有1条消息被消费,保证了幂等。
三、总结
MQ为了保证消息必达,消息上下半场均可能发送重复消息,如何保证消息的幂等性呢?
上半场
MQ-client生成inner-msg-id,保证上半场幂等。
这个ID全局唯一,业务无关,由MQ保证。
下半场
业务发送方带入biz-id,业务接收方去重保证幂等。
这个ID对单业务唯一,业务相关,对MQ透明。
结论:幂等性,不仅对MQ有要求,对业务上下游也有要求。
结语:到目前为止,我们已经已经简单的了解了ActiveMQ中消息传送机制,还有JMS中ACK策略,重点分析了optimizeACK的策略,希望开发者能够在使用activeMQ中避免一些不必要的错误。
ActiveMq笔记1-消息可靠性理论的更多相关文章
- ActiveMQ笔记(7):如何清理无效的延时消息?
ActiveMQ的延时消息是一个让人又爱又恨的功能,具体使用可参考上篇ActiveMQ笔记(6):消息延时投递,在很多需要消息延时投递的业务场景十分有用,但是也有一个缺陷,在一些大访问量的场景,如果瞬 ...
- php 利用activeMq+stomp实现消息队列
php 利用activeMq+stomp实现消息队列 一.activeMq概述 ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线.ActiveMQ 是一个完全支持JMS1.1和J ...
- Linux进程间通信IPC学习笔记之消息队列(SVR4)
Linux进程间通信IPC学习笔记之消息队列(SVR4)
- 【ActiveMQ】持久化消息队列的三种方式
1.ActiveMQ消息持久化方式,分别是:文件.mysql数据库.oracle数据库 2.修改方式: a.文件持久化: ActiveMQ默认的消息保存方式,一般如果没有修改过其他持久化方式的话可以不 ...
- php 事务处理,ActiveMQ的发送消息,与处理消息
可以通过链式发送->处理->发送...的方式处理类似事务型业务逻辑 比如 发送一个注册消息,消息队列处理完注册以后,紧接着发送一个新手优惠券赠送,赠送完再发一个其它后续逻辑处理的消息等待后 ...
- ActiveMQ发布-订阅消息模式(同点对点模式的区别)
点对点与发布订阅最初是由JMS定义的.这两种模式主要区别或解决的问题就是发送到队列的消息能否重复消费(多订阅) 点对点: 消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费 ...
- (二)ActiveMQ之点对点消息实现
一.点对点消息实现概念 在点对点或队列模型下,一个生产者向一个特定的队列发布消息,一个消费者从该队列中读取消息.这里,生产者知道消费者的队列,并直接将消息发送到消费者的队列.这种模式被概括为:只有一个 ...
- 使用ActiveMQ实现JMS消息通信服务
PTP(点对点的消息模型) 在点对点模型中,相当于两个人打电话,两个人独享一条通信线路.一方发送消息,一方接收消息. 在p2p的模型中,双方通过队列交流,一个队列只有一个生产者和一个消费者. 1.建立 ...
- ActiveMQ 笔记(六)ActiveMQ的消息存储和持久化
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.持久化机制 1.Activemq持久化 1.1 什么是持久化: 持久化就是高可用的机制,即使服务器宕 ...
随机推荐
- 使用EndNote在Word中插入参考文献的格式设置
endnote其实自带了很多参考文献格式的样式,如下图,但往往跟我们要使用的会有所出入,本文主要介绍的就是设置自定义endnote参考文献格式,以endnote X6和word2003为例,其它版本以 ...
- java ecplise配置
运行java项目首先配置java运行时环境:Window->Preferences->Java->Installed JREs 修改为jdk:C:\Program Files\Jav ...
- 02_HTML5+CSS详解第三天
WebStorage简单的网页留言板用到的函数有3个1.saveStorage函数使用"new Date().getTime()"语句来获取当前的日期和时间戳,然后使用localS ...
- awk处理重复行错误分析
[root@localhost ~]#cat 0712 YRSD2-1-11 YRSD2-2-18 YRSD1-1-8 YRSD1-1-18 YRSD1-1-20 YRSD1-1-25 YRSD1-2 ...
- Nginx+Geoserver部署所遇问题总结
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 该问题的最终解决离不开公司大拿whs先生的指点,先表示感谢. ...
- Spring Cache For Redis
一.概述 缓存(Caching)可以存储经常会用到的信息,这样每次需要的时候,这些信息都是立即可用的. 常用的缓存数据库: Redis 使用内存存储(in-memory)的非关系数据库,字符串.列 ...
- MySQL--当事务遇到DDL命令
众所周知MySQL的DDL语句是非事务的,即不能对DLL语句进行回滚操作,哪在事务中包含DDL语句会怎样呢? 如: #禁用自动提交 set autocommit=off; #创建tb1 create ...
- 百度网盘不限速下载软件 Pan Download
百度网盘不限速下载软件 Pan Download Pan Download下载软件是一款电脑端的快速下载器软件,您可以通过Pan Download直接下载百度网盘中的资源,此款软件下载速度快,下载压缩 ...
- C#基础(六)--枚举的一些常用操作
本章将介绍以下几点: 1.如何把其它类型转换为枚举类型? 2.如何把枚举中的值添加到下拉菜单中? 一.如何把其它类型转换为枚举类型? 我们回顾一下有关字符串与数字之间的转换,如: ...
- 03_Linux文件和目录
一.Linux目录结构 /:根目录,一般根目录下只存放目录,在Linux下有且只有一个根目录.所有的东西都是从这里开始.当你在终端里输入"/home",你其实是在告诉电脑,先从/( ...