一步一步理解 python web 框架,才不会从入门到放弃
要想清楚地理解 python web 框架,首先要清楚浏览器访问服务器的过程。
用户通过浏览器浏览网站的过程:
用户浏览器(socket客户端)
3. 客户端往服务端发消息
6. 客户端接收消息
7. 关闭
网站服务器(socket服务端)
1. 启动,监听
2. 等待客户端连接
4. 服务端收消息
5. 服务端回消息
7. 关闭(一般都不会关闭)
下面,我们先写一个服务端程序,来模拟浏览器服务器访问过程。
'''
简单的web服务端示例
''' import socket # 生成socket实例对象,默认family=AF_INET, type=SOCK_STREAM, 也就是TCP通信
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 8001))
# 监听
sk.listen() # 写一个死循环,一直等待客户端来连接
while 1:
# 获取与客户端的连接,conn为客户端连接服务器的socket,_为客户端的地址
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
print(data)
# 给客户端回复消息
conn.send(b'<h1>hello s10!</h1>')
# 关闭客户端连接服务器的socket
conn.close()
# 关闭服务器socket
sk.close()
你会发现,运行程序之后并且用浏览器访问 127.0.0.1:8001 ,程序会报错,浏览器显示“该网页无法正常运作”,如下图
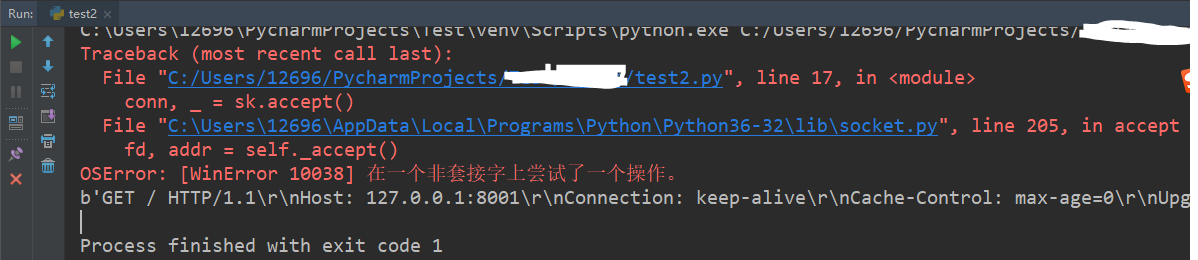
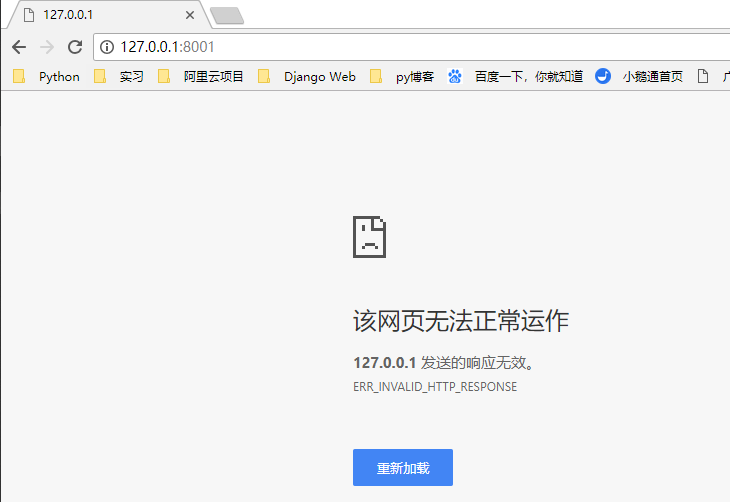
为什么呢?这时候就要引出 HTTP 协议了。
HTTP协议
HTTP是一个客户端终端(用户)和服务器端(网站)请求和应答的标准(TCP)。
HTTP请求/响应步骤:
1. 客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。
2. 发送HTTP请求
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
3. 服务器接受请求并返回HTTP响应
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
4. 释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
5. 客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
浏览器和服务端通信都要遵循一个HTTP协议(消息的格式要求)
关于HTTP协议:
1. 浏览器往服务端发的叫 请求(request)
请求的消息格式:
请求方法 路径 HTTP/1.1\r\n
k1:v1\r\n
k2:v2\r\n
\r\n
请求数据
2. 服务端往浏览器发的叫 响应(response)
响应的消息格式:
HTTP/1.1 状态码 状态描述符\r\n
k1:v1\r\n
k2:v2\r\n
\r\n
响应正文 <-- html的内容
HTTP请求报文格式:
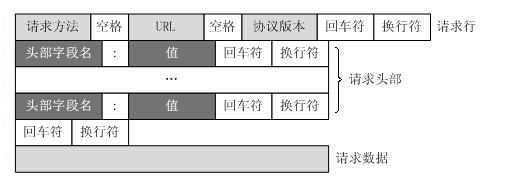
HTTP响应报文格式:
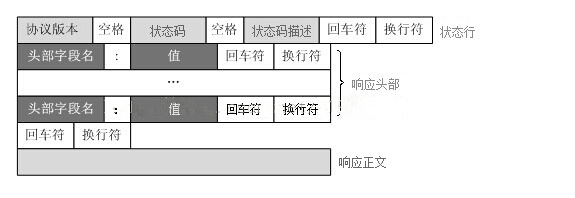
再回到我们刚才的程序,程序报错的原因是接收到了浏览器的访问报文请求,但是我们的服务器程序在响应的时候并没有按照HTTP响应格式(一个响应由状态行、响应头部、空行和响应数据4部分组成)进行回应,所以浏览器在处理服务器的响应的时候就会出错。
因此,我们要在发送给浏览器的响应中按照HTTP响应格式加上 状态行、响应头部、空行和响应数据 这四部分。
'''
简单的web服务端示例
''' import socket # 生成socket实例对象,默认family=AF_INET, type=SOCK_STREAM, 也就是TCP通信
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 8001))
# 监听
sk.listen() # 写一个死循环,一直等待客户端来连接
while 1:
# 获取与客户端的连接,conn为客户端连接服务器的socket,_为客户端的地址
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
print(data)
# 给客户端回复消息,都是以byte的形式传输
# 响应协议版本是 http/1.1,状态码是 200,状态码描述我们定义为 OK,然后加上换行符
# 响应头部我们写上content-type:text/html; 字符编码为 charset=utf-8,加上两个换行符,这一次send先不传响应正文
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 由于前一个send已经传过一次响应规定的格式了,这一个send我们就传想要在网页上显示的正文内容
conn.send(b'<h1>hello s10!</h1>')
# 关闭客户端连接服务器的socket
conn.close()
# 关闭服务器socket
sk.close()
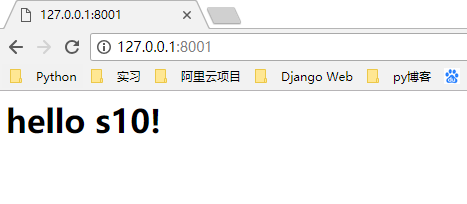
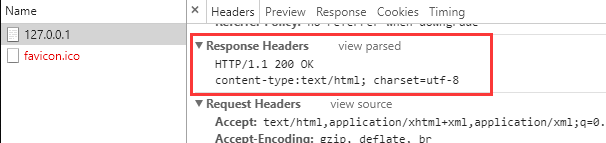
这时候,在浏览器上面就可以看到正确的页面了,并且可以调出Chrome的开发者工具查看到我们传过来的HTTP响应格式。
根据不同的路径返回不同的内容
细心的你可能会发现,现在无论我们输出什么样的路径,只要保持 IP 和端口号不变,浏览器页面显示的都是同样的内容,这不太符合我们日常的使用场景。
如果我想根据不同的路径返回不同的内容,应该怎么办呢?
这时候就需要我们把服务器收到的请求报文进行解析,读取到其中的访问路径。
观察收到的HTTP请求,会发现,它们的请求行、请求头部、请求数据是以 \r\n 进行分隔的,所以我们可以根据 \r\n 对收到的请求进行分隔,取出我们想要的访问路径。
"""
完善的web服务端示例
根据不同的路径返回不同的内容
""" import socket # 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 8001))
# 监听
sk.listen() # 写一个死循环,一直等待客户端来连接
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# l1[0]获得请求行,按照空格切割上面的字符串
l2 = l1[0].split()
# 请求行格式为:请求方法 URL 协议版本,因此 URL 是 l2[1]
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文 # 根据不同的url返回不同的内容
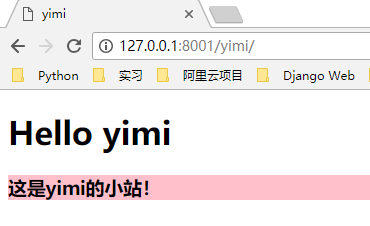
if url == "/yimi/":
response = b'<h1>hello yimi!</h1>'
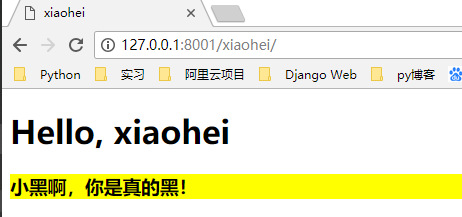
elif url == "/xiaohei/":
response = b'<h1>hello xiaohei!</h1>'
else:
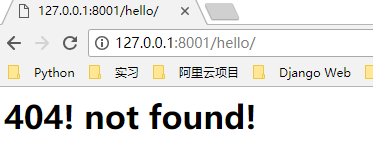
response = b'<h1>404! not found!</h1>'
conn.send(response)
# 关闭
conn.close()
sk.close()
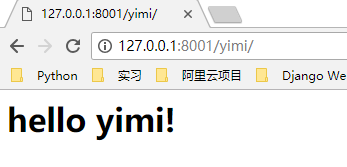
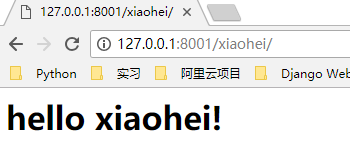
这时候,我们访问不同的路径,例如 http://127.0.0.1:8001/yimi/ http://127.0.0.1:8001/xiaohei/ 会在浏览器上显示不一样的内容
可以看到,我们现在的程序逻辑不是很清晰,我们可以改一下,url 用一个列表存起来,url 对应的响应分别写成一个个函数,通过函数调用进行 url 访问,你会发现,这跟某个框架的处理方式很像很像(偷笑罒ω罒~~~)
"""
完善的web服务端示例
函数版根据不同的路径返回不同的内容
进阶函数版 不写if判断了,用url名字去找对应的函数名
""" import socket # 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 8001))
# 监听
sk.listen() # 定义一个处理/yimi/的函数
def yimi(url):
ret = '<h1>hello {}</h1>'.format(url)
# 因为HTTP传的是字节,所以要把上面的字符串转成字节
return bytes(ret, encoding="utf-8") # 定义一个处理/xiaohei/的函数
def xiaohei(url):
ret = '<h1>hello {}</h1>'.format(url)
return bytes(ret, encoding="utf-8") # 定义一个专门用来处理404的函数
def f404(url):
ret = "<h1>你访问的这个{} 找不到</h1>".format(url)
return bytes(ret, encoding="utf-8") url_func = [
("/yimi/", yimi),
("/xiaohei/", xiaohei),
] # 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文 # 根据不同的url返回不同的内容
# 去url_func里面找对应关系
for i in url_func:
if i[0] == url:
func = i[1]
break
# 找不到对应关系就默认执行f404函数
else:
func = f404 # 拿到函数的执行结果
response = func(url)
# 将函数返回的结果发送给浏览器
conn.send(response)
# 关闭连接
conn.close()
返回具体的 HTML 页面
现在,你可能会在想,目前我们想要返回的内容是通过函数进行返回的,返回的都是一些简单地字节,如果我想要返回一个已经写好的精美的 HTML 页面应该怎么办呢?
我们可以把写好的 HTML 页面以二进制的形式读取进来,返回给浏览器,浏览器再进行解析,这就可以啦!
"""
完善的web服务端示例
函数版根据不同的路径返回不同的内容
进阶函数版 不写if判断了,用url名字去找对应的函数名
返回html页面
""" import socket # 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 8001))
# 监听
sk.listen() # 定义一个处理/yimi/的函数
def yimi(url):
# 以二进制的形式读取
with open("yimi.html", "rb") as f:
ret = f.read()
return ret # 定义一个处理/xiaohei/的函数
def xiaohei(url):
with open("xiaohei.html", "rb") as f:
ret = f.read()
return ret # 定义一个专门用来处理404的函数
def f404(url):
ret = "<h1>你访问的这个{} 找不到</h1>".format(url)
return bytes(ret, encoding="utf-8") # 用户访问的路径和后端要执行的函数的对应关系
url_func = [
("/yimi/", yimi),
("/xiaohei/", xiaohei),
] # 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文 # 根据不同的url返回不同的内容
# 去url_func里面找对应关系
for i in url_func:
if i[0] == url:
func = i[1]
break
# 找不到对应关系就默认执行f404函数
else:
func = f404
# 拿到函数的执行结果
response = func(url)
# 将函数返回的结果发送给浏览器
conn.send(response)
# 关闭连接
conn.close()
返回动态 HTML 页面
这时候,你可能又会纳闷,现在返回的都是些静态的、固定的 HTML 页面,如果我想返回一个动态的 HTML 页面,应该怎么办?
动态的网页,本质上都是字符串的替换,字符串替换发生服务端,替换完再返回给浏览器。
这里,我们通过返回一个当前时间,来模拟动态 HTML 页面的返回过程。
"""
完善的web服务端示例
函数版根据不同的路径返回不同的内容
进阶函数版 不写if判断了,用url名字去找对应的函数名
返回html页面
返回动态的html页面
""" import socket
import time # 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 8001))
# 监听
sk.listen() # 定义一个处理/yimi/的函数
def yimi(url):
with open("yimi.html", "r", encoding="utf-8") as f:
ret = f.read()
# 得到替换后的字符串
ret2 = ret.replace("@@xx@@", str(time.ctime()))
return bytes(ret2, encoding="utf-8") # 定义一个处理/xiaohei/的函数
def xiaohei(url):
with open("xiaohei.html", "rb") as f:
ret = f.read()
return ret # 定义一个专门用来处理404的函数
def f404(url):
ret = "你访问的这个{} 找不到".format(url)
return bytes(ret, encoding="utf-8") url_func = [
("/yimi/", yimi),
("/xiaohei/", xiaohei),
] # 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文 # 根据不同的url返回不同的内容
# 去url_func里面找对应关系
for i in url_func:
if i[0] == url:
func = i[1]
break
# 找不到对应关系就默认执行f404函数
else:
func = f404
# 拿到函数的执行结果
response = func(url)
# 将函数返回的结果发送给浏览器
conn.send(response)
# 关闭连接
conn.close()
服务端.py
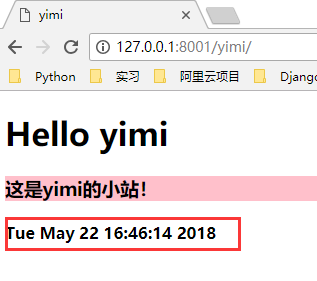
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>yimi</title>
</head>
<body>
<h1>Hello yimi</h1>
<h3 style="background-color: pink">这是yimi的小站!</h3>
<h4>@@xx@@</h4>
</body>
</html>
yimi.html
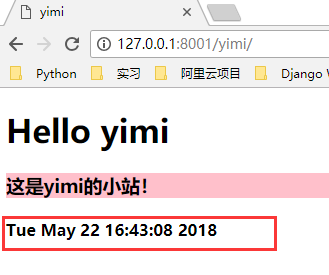
可以看到,现在我们每一次访问 yimi 页面,都会返回一个当前时间。
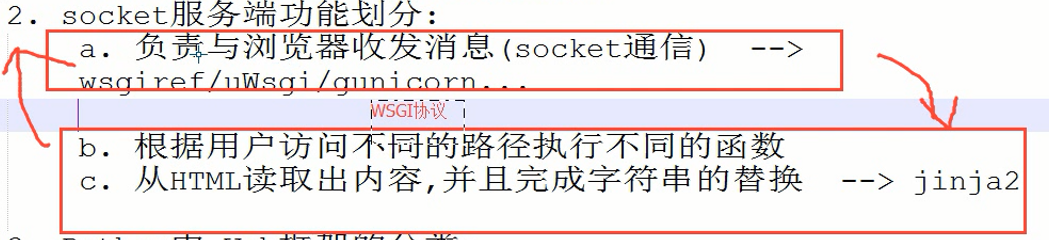
小结一下
1. web 框架的本质:
socket 服务端 与 浏览器的通信
2. socket 服务端功能划分:
a. 负责与浏览器收发消息( socket 通信) --> wsgiref/uWsgi/gunicorn...
b. 根据用户访问不同的路径执行不同的函数
c. 从 HTML 读取出内容,并且完成字符串的替换 --> jinja2 (模板语言)
3. Python 中 Web 框架的分类:
1. 按上面三个功能划分:
1. 框架自带 a,b,c --> Tornado
2. 框架自带 b 和 c,使用第三方的 a --> Django
3. 框架自带 b,使用第三方的 a 和 c --> Flask
2. 按另一个维度来划分:
1. Django --> 大而全(你做一个网站能用到的它都有)
2. 其他 --> Flask 轻量级
引入 wsgiref 模块实现 socket 通信
不知道你会不会觉得之前的程序中,socket 通信特别麻烦,而且还都是一样的套路,完完全全可以独立出来做成一个模块,要用的时候再直接引进来用就可以了。
没错,有你这种想法的人还不在少数(吃鲸......),特别是一些大牛们,就 socket 通信这一块,做出了一些特别好用的模块,例如我们下面要用的 wsgiref 模块。
"""
根据URL中不同的路径返回不同的内容--函数进阶版
返回HTML页面
让网页动态起来
wsgiref模块负责与浏览器收发消息(socket通信)
""" import time
from wsgiref.simple_server import make_server # 将返回不同的内容部分封装成函数
def yimi(url):
with open("yimi.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.ctime())
s = s.replace("@@xx@@", now)
return bytes(s, encoding="utf8") def xiaohei(url):
with open("xiaohei.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8") # 定义一个url和实际要执行的函数的对应关系
list1 = [
("/yimi/", yimi),
("/xiaohei/", xiaohei),
] def run_server(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息
url = environ['PATH_INFO'] # 取到用户输入的url
func = None
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"<h1>404 not found!</h1>"
return [response, ] if __name__ == '__main__':
httpd = make_server('127.0.0.1', 8090, run_server)
print("我在8090等你哦...")
httpd.serve_forever()
你会发现,使用了 wsgiref 模块之后,程序封装更好了,代码逻辑也更加清晰了。
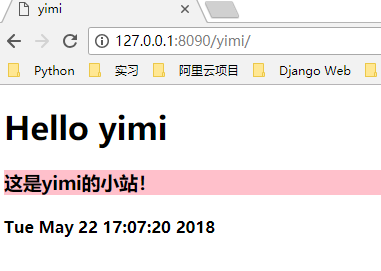

WSGI 协议
经过上面的 wsgiref 模块的示例,在使用通信模块的方便之余,你可能已经意识到一个问题,类似于 wsgiref 这样的模块肯定不止一个,我们自己写的 url 处理函数需要和这些模块进行通信,那么,我怎么知道这些模块传过来的信息是什么格式?如果各个模块传过来的信息结构都不一样的话,那岂不是说我得根据每一个模块去定制它专门的 url 处理函数?这不科学,这中间肯定需要一个协议进行约束,这个协议,就叫 WSGI 协议。
下节预告
到了这里,相信聪明的你已经理解清楚整个 浏览器 服务器的访问过程,并且 socket 服务端功能划分有了清晰的认知。
下一节,我们将走进 Django 框架,领略 Django 的魅力。
作者: 守护窗明守护爱
出处: https://www.cnblogs.com/chuangming/p/9072251.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出。如有问题,可邮件(1269619593@qq.com)咨询.
一步一步理解 python web 框架,才不会从入门到放弃的更多相关文章
- 一步一步理解 python web 框架,才不会从入门到放弃 -- 开始使用 Django
背景知识 要使用 Django,首先必须先安装 Django. 下图是 Django 官网的版本支持,我们可以看到上面有一个 LTS 存在.什么是 LTS 呢?LTS ,long-term suppo ...
- 一步一步理解 python web 框架,才不会从入门到放弃 -- 简单登录页面
上一节,我们基本了解了 Django 的一些配置,这一节,我们将通过一个简单的登录页面,进一步学习 Django 的使用. 新建项目 首先,新建一个 Django 项目,记得别弄错了哦. settin ...
- python web框架Flask——csrf攻击
CSRF是什么? (Cross Site Request Forgery, 跨站域请求伪造)是一种网络的攻击方式,它在 2007 年曾被列为互联网 20 大安全隐患之一,也被称为“One Click ...
- 一文读懂Python web框架和web服务器之间的关系
我们都知道 Python 作为一门强大的语言,能够适应快速原型和较大项目的制作,因此被广泛用于 web 应用程序的开发中. 在面试的过程中,大家或多或少都被问到过这样一个问题:一个请求从浏览器发出到数 ...
- python web框架介绍对比
Django Python框架虽然说是百花齐放,但仍然有那么一家是最大的,它就是Django.要说Django是Python框架里最好的,有人同意也有人 坚决反对,但说Django的文档最完善.市场占 ...
- “脚踢各大Python Web框架”,Sanic真有这能耐么?
在Github上,Sanic第一句介绍语就是: "Sanic is a Flask-like Python 3.5+ web server that's written to go fast ...
- python三大web框架Django,Flask,Flask,Python几种主流框架,13个Python web框架比较,2018年Python web五大主流框架
Python几种主流框架 从GitHub中整理出的15个最受欢迎的Python开源框架.这些框架包括事件I/O,OLAP,Web开发,高性能网络通信,测试,爬虫等. Django: Python We ...
- Python Web框架Tornado的异步处理代码演示样例
1. What is Tornado Tornado是一个轻量级但高性能的Python web框架,与还有一个流行的Python web框架Django相比.tornado不提供操作数据库的ORM接口 ...
- Django,Flask,Tornado三大框架对比,Python几种主流框架,13个Python web框架比较,2018年Python web五大主流框架
Django 与 Tornado 各自的优缺点Django优点: 大和全(重量级框架)自带orm,template,view 需要的功能也可以去找第三方的app注重高效开发全自动化的管理后台(只需要使 ...
随机推荐
- Oracel 编写控制结构
1.条件分支语句 在Oracle9i之前,执行条件分支操作都需要使用IF语句来完成,并且PL/SQL中,提供了三种条件分支语句:IF-THEN.IF-THEN-ELSE.IF-THEN-ELSIF.具 ...
- List集合中元素排序
应用场景: 在开发中经常遇到要对List<Object>集合进行排序,并且是根据集合中的对象的某个属性来进行排序 --------以下就此做出的解决方案 public static ...
- java——多态
多态定义:某一类事物的多种存在形态.对象的多态性.猫这类事物即具备猫的形态,又具备着动物的形态,这就是对象的多态性.简单说:就是一个对象对应着不同类型.多态在代码中的体现:父类或者接口的引用指向其子类 ...
- Tornado、Bottle以及Flask
最近接手一个Tornado项目代码,项目要在原有基础上做很大扩展,为了更好地吃透并扩展好这个项目,就对Tornado以及比较轻型的Bottle.Flask这些框架一一作了调研.其实若干年前做第一个Py ...
- Android OkHttp文件上传与下载的进度监听扩展
http://www.loongwind.com/archives/290.html 上一篇文章介绍了用Retrofit实现文件的上传与下载,但是我们发现没办法监听上传下载的进度,毕竟我们在做开发的时 ...
- Android Studio布局等XML文件怎么改都恢复原状的问题
编译时,XML布局文件报错,点击链接进去改,怎么改,一编译就恢复原状,这是什么原因,问题出在点击错误链接进的是中间生成XML文件,这个文件改动是没用的,需要改动原始layout文件才会生效.
- 基于Python的数据分析(1):配置安装环境
数据分析是一个历史久远的东西,但是直到近代微型计算机的普及,数据分析的价值才得到大家的重视.到了今天,数据分析已经成为企业生产运维的一个核心组成部分. 据我自己做数据分析的经验来看,目前数据分析按照使 ...
- 微信小程序入门三实战
微信小应用借鉴了很多web的理念,但是其与传统的webApp.微信公共号这些BS架构不同,他是CS架构,是客户端的程序 小程序开发实战--豆瓣电影 项目配置 -在app.jsop中进行简单配置 --n ...
- 【Java】运用泽勒一致性计算某天是星期几
/** * Created by liangjiahao on 2017/2/26. * 运用泽勒一致性计算某天是星期几? * 公式: * h = (q + 26(m+1)/10 + k +k/4 + ...
- tomcat的配置使用详细版
摘要: 开发者开发部署web应用时通常使用tomcat服务器,很多初学者只懂得在开发工具上配置,但离开了开发工具,自己手动配置部署,并让一个项目跑起来,你会了吗.小编也遇到过这样的困扰.网上查找的资料 ...