支持向量机(SVM)基础
版权声明:
本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gmail.com
前言:
又有很长的一段时间没有更新博客了,距离上次更新已经有两个月的时间了。其中一个很大的原因是,不知道写什么好-_-,最近一段时间看了看关于 SVM(Support Vector Machine)的文章,觉得SVM是一个非常有趣,而且自成一派的方向,所以今天准备写一篇关于关于SVM的文章。
关于SVM的论文、书籍都非常的多,引用强哥的话“SVM是让应用数学家真正得到应用的一种算法”。SVM对于大部分的普通人来说,要完全理解其中的数学 是非常困难的,所以要让这些普通人理解,得要把里面的数学知识用简单的语言去讲解才行。而且想明白了这些数学,对学习其他的内容也是大有裨益的。我就是属 于绝大多数的普通人,为了看明白SVM,看了不少的资料,这里把我的心得分享分享。
其实现在能够找到的,关于SVM的中文资料已经不少了,不过个人觉得,每个人的理解都不太一样,所以还是决定写一写,一些雷同的地方肯定是不可避免的,不 过还是希望能够写出一点与别人不一样的地方吧。另外本文准备不谈太多的数学(因为很多文章都谈过了),尽量简单地给出结论,就像题目一样-机器学习中的算法(之前叫做机器学习中的数学),所以本系列的内容将更偏重应用一些。如果想看更详细的数学解释,可以看看参考文献中的资料。
一、线性分类器:
首先给出一个非常非常简单的分类问题(线性可分),我们要用一条直线,将下图中黑色的点和白色的点分开,很显然,图上的这条直线就是我们要求的直线之一(可以有无数条这样的直线)
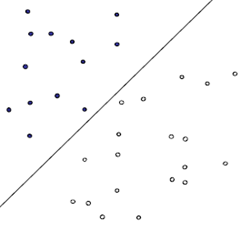 假如说,我们令黑色的点 = -1, 白色的点 = +1,直线f(x) = w.x + b,这儿的x、w是向量,其实写成这种形式也是等价的f(x) = w1x1 + w2x2 … + wnxn + b, 当向量x的维度=2的时候,f(x) 表示二维空间中的一条直线, 当x的维度=3的时候,f(x) 表示3维空间中的一个平面,当x的维度=n > 3的时候,表示n维空间中的n-1维超平面。这些都是比较基础的内容,如果不太清楚,可能需要复习一下微积分、线性代数的内容。
假如说,我们令黑色的点 = -1, 白色的点 = +1,直线f(x) = w.x + b,这儿的x、w是向量,其实写成这种形式也是等价的f(x) = w1x1 + w2x2 … + wnxn + b, 当向量x的维度=2的时候,f(x) 表示二维空间中的一条直线, 当x的维度=3的时候,f(x) 表示3维空间中的一个平面,当x的维度=n > 3的时候,表示n维空间中的n-1维超平面。这些都是比较基础的内容,如果不太清楚,可能需要复习一下微积分、线性代数的内容。
刚刚说了,我们令黑色白色两类的点分别为+1, -1,所以当有一个新的点x需要预测属于哪个分类的时候,我们用sgn(f(x)),就可以预测了,sgn表示符号函数,当f(x) > 0的时候,sgn(f(x)) = +1, 当f(x) < 0的时候sgn(f(x)) = –1。
但是,我们怎样才能取得一个最优的划分直线f(x)呢?下图的直线表示几条可能的f(x)

一个很直观的感受是,让这条直线到给定样本中最近的点最远,这句话读起来比较拗口,下面给出几个图,来说明一下:
第一种分法:

第二种分法:

这两种分法哪种更好呢?从直观上来说,就是分割的间隙越大越好,把两个类别的点分得越开越好。就像我们平时判断一个人是男还是女,就是很难出现分错的情况,这就是男、女两个类别之间的间隙非常的大导致的,让我们可以更准确的进行分类。在SVM中,称为Maximum Marginal,是SVM的一个理论基础之一。选择使得间隙最大的函数作为分割平面是由很多道理的,比如说从概率的角度上来说,就是使得置信度最小的点置信度最大(听起来很拗口),从实践的角度来说,这样的效果非常好,等等。这里就不展开讲,作为一个结论就ok了,:)
上图被红色和蓝色的线圈出来的点就是所谓的支持向量(support vector)。
 上图就是一个对之前说的类别中的间隙的一个描述。Classifier Boundary就是f(x),红色和蓝色的线(plus plane与minus plane)就是support vector所在的面,红色、蓝色线之间的间隙就是我们要最大化的分类间的间隙。
上图就是一个对之前说的类别中的间隙的一个描述。Classifier Boundary就是f(x),红色和蓝色的线(plus plane与minus plane)就是support vector所在的面,红色、蓝色线之间的间隙就是我们要最大化的分类间的间隙。
这里直接给出M的式子:(从高中的解析几何就可以很容易的得到了,也可以参考后面Moore的ppt)

另外支持向量位于wx + b = 1与wx + b = -1的直线上,我们在前面乘上一个该点所属的类别y(还记得吗?y不是+1就是-1),就可以得到支持向量的表达式为:y(wx + b) = 1,这样就可以更简单的将支持向量表示出来了。
当支持向量确定下来的时候,分割函数就确定下来了,两个问题是等价的。得到支持向量,还有一个作用是,让支持向量后方那些点就不用参与计算了。这点在后面将会更详细的讲讲。
在这个小节的最后,给出我们要优化求解的表达式:
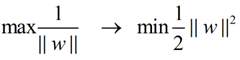
||w||的意思是w的二范数,跟上面的M表达式的分母是一个意思,之前得到,M = 2 / ||w||,最大化这个式子等价于最小化||w||, 另外由于||w||是一个单调函数,我们可以对其加入平方,和前面的系数,熟悉的同学应该很容易就看出来了,这个式子是为了方便求导。
这个式子有还有一些限制条件,完整的写下来,应该是这样的:(原问题)

s.t的意思是subject to,也就是在后面这个限制条件下的意思,这个词在svm的论文里面非常容易见到。这个其实是一个带约束的二次规划(quadratic programming, QP)问题,是一个凸问题,凸问题就是指的不会有局部最优解,可以想象一个漏斗,不管我们开始的时候将一个小球放在漏斗的什么位置,这个小球最终一定可以 掉出漏斗,也就是得到全局最优解。s.t.后面的限制条件可以看做是一个凸多面体,我们要做的就是在这个凸多面体中找到最优解。这些问题这里不展开,因为 展开的话,一本书也写不完。如果有疑问请看看wikipedia。
二、转化为对偶问题,并优化求解:
这个优化问题可以用拉格朗日乘子法去解,使用了KKT条件的理论,这里直接作出这个式子的拉格朗日目标函数:

求解这个式子的过程需要拉格朗日对偶性的相关知识(另外pluskid也有一篇文章专门讲这个问题),并且有一定的公式推导,如果不感兴趣,可以直接跳到后面用蓝色公式表示的结论,该部分推导主要参考自plukids的文章。
首先让L关于w,b最小化,分别令L关于w,b的偏导数为0,得到关于原问题的一个表达式
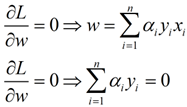
将两式带回L(w,b,a)得到对偶问题的表达式

新问题加上其限制条件是(对偶问题):
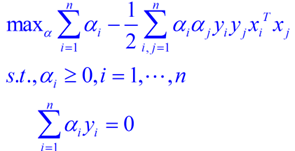
这个就是我们需要最终优化的式子。至此,得到了线性可分问题的优化式子。
求解这个式子,有很多的方法,比如SMO等等,个人认为,求解这样的一个带约束的凸优化问题与得到这个凸优化问题是比较独立的两件事情,所以在这篇文章中准备完全不涉及如何求解这个话题,如果之后有时间可以补上一篇文章来谈谈:)。
三、线性不可分的情况(软间隔):
接下来谈谈线性不可分的情况,因为线性可分这种假设实在是太有局限性了:
下图就是一个典型的线性不可分的分类图,我们没有办法用一条直线去将其分成两个区域,每个区域只包含一种颜色的点。
 要想在这种情况下的分类器,有两种方式,一种是用曲线去将其完全分开,曲线就是一种非线性的情况,跟之后将谈到的核函数有一定的关系:
要想在这种情况下的分类器,有两种方式,一种是用曲线去将其完全分开,曲线就是一种非线性的情况,跟之后将谈到的核函数有一定的关系:
 另外一种还是用直线,不过不用去保证可分性, 就是包容那些分错的情况,不过我们得加入惩罚函数,使得点分错的情况越合理越好。其实在很多时候,不是在训练的时候分类函数越完美越好,因为训练函数中有 些数据本来就是噪声,可能就是在人工加上分类标签的时候加错了,如果我们在训练(学习)的时候把这些错误的点学习到了,那么模型在下次碰到这些错误情况的 时候就难免出错了(假如老师给你讲课的时候,某个知识点讲错了,你还信以为真了,那么在考试的时候就难免出错)。这种学习的时候学到了“噪声”的过程就是 一个过拟合(over-fitting),这在机器学习中是一个大忌,我们宁愿少学一些内容,也坚决杜绝多学一些错误的知识。还是回到主题,用直线怎么去 分割线性不可分的点:
另外一种还是用直线,不过不用去保证可分性, 就是包容那些分错的情况,不过我们得加入惩罚函数,使得点分错的情况越合理越好。其实在很多时候,不是在训练的时候分类函数越完美越好,因为训练函数中有 些数据本来就是噪声,可能就是在人工加上分类标签的时候加错了,如果我们在训练(学习)的时候把这些错误的点学习到了,那么模型在下次碰到这些错误情况的 时候就难免出错了(假如老师给你讲课的时候,某个知识点讲错了,你还信以为真了,那么在考试的时候就难免出错)。这种学习的时候学到了“噪声”的过程就是 一个过拟合(over-fitting),这在机器学习中是一个大忌,我们宁愿少学一些内容,也坚决杜绝多学一些错误的知识。还是回到主题,用直线怎么去 分割线性不可分的点:
我们可以为分错的点加上一点惩罚,对一个分错的点的惩罚函数就是这个点到其正确位置的距离:

在上图中,蓝色、红色的直线分别为支持向量所在的边界,绿色的线为决策函数,那些紫色的线表示分错的点到其相应的决策面的距离,这样我们可以在原函数上面加上一个惩罚函数,并且带上其限制条件为:

公式中蓝色的部分为在线性可分问题的基础上加上的惩罚函数部分,当xi在正确一边的时候,ε=0,R为全部的点的数目,C是一个由用户去指定的系数,表示 对分错的点加入多少的惩罚,当C很大的时候,分错的点就会更少,但是过拟合的情况可能会比较严重,当C很小的时候,分错的点可能会很多,不过可能由此得到 的模型也会不太正确,所以如何选择C是有很多学问的,不过在大部分情况下就是通过经验尝试得到的。
接下来就是同样的,求解一个拉格朗日对偶问题,得到一个原问题的对偶问题的表达式:
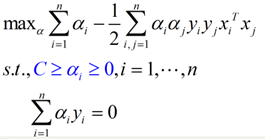
蓝色的部分是与线性可分的对偶问题表达式的不同之处。在线性不可分情况下得到的对偶问题,不同的地方就是α的范围从[0, +∞),变为了[0, C],增加的惩罚ε没有为对偶问题增加什么复杂度。
四、核函数:
刚刚在谈不可分的情况下,提了一句,如果使用某些非线性的方法,可以得到将两个分类完美划分的曲线,比如接下来将要说的核函数。
我们可以让空间从原本的线性空间变成一个更高维的空间,在这个高维的线性空间下,再用一个超平面进行划分。这儿举个例子,来理解一下如何利用空间的维度变得更高来帮助我们分类的(例子以及图片来自pluskid的kernel函数部分):
下图是一个典型的线性不可分的情况

但是当我们把这两个类似于椭圆形的点映射到一个高维空间后,映射函数为:
 用这个函数可以将上图的平面中的点映射到一个三维空间(z1,z2,z3),并且对映射后的坐标加以旋转之后就可以得到一个线性可分的点集了。
用这个函数可以将上图的平面中的点映射到一个三维空间(z1,z2,z3),并且对映射后的坐标加以旋转之后就可以得到一个线性可分的点集了。

用另外一个哲学例子来说:世界上本来没有两个完全一样的物体,对于所有的两个物体,我们可以通过增加维度来让他们最终有所区别,比如说两本书,从(颜色,内容)两个维度来说,可能是一样的,我们可以加上 作者 这个维度,是在不行我们还可以加入 页码,可以加入 拥有者,可以加入 购买地点,可以加入 笔记内容等等。当维度增加到无限维的时候,一定可以让任意的两个物体可分了。
回忆刚刚得到的对偶问题表达式:
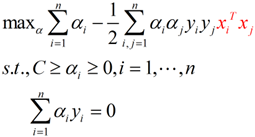
我们可以将红色这个部分进行改造,令:
 这个式子所做的事情就是将线性的空间映射到高维的空间,k(x, xj)有很多种,下面是比较典型的两种:
这个式子所做的事情就是将线性的空间映射到高维的空间,k(x, xj)有很多种,下面是比较典型的两种:
 上面这个核称为多项式核,下面这个核称为高斯核,高斯核甚至是将原始空间映射为无穷维空间,另外核函数有一些比较好的性质,比如说不会比线性条件下增加多 少额外的计算量,等等,这里也不再深入。一般对于一个问题,不同的核函数可能会带来不同的结果,一般是需要尝试来得到的。
上面这个核称为多项式核,下面这个核称为高斯核,高斯核甚至是将原始空间映射为无穷维空间,另外核函数有一些比较好的性质,比如说不会比线性条件下增加多 少额外的计算量,等等,这里也不再深入。一般对于一个问题,不同的核函数可能会带来不同的结果,一般是需要尝试来得到的。
五、一些其他的问题:
1)如何进行多分类问题:
上面所谈到的分类都是2分类的情况,当N分类的情况下,主要有两种方式,一种是1 vs (N – 1)一种是1 vs 1,前一种方法我们需要训练N个分类器,第i个分类器是看看是属于分类i还是属于分类i的补集(出去i的N-1个分类)。
后一种方式我们需要训练N * (N – 1) / 2个分类器,分类器(i,j)能够判断某个点是属于i还是属于j。
这种处理方式不仅在SVM中会用到,在很多其他的分类中也是被广泛用到,从林教授(libsvm的作者)的结论来看,1 vs 1的方式要优于1 vs (N – 1)。
2)SVM会overfitting吗?
SVM避免overfitting,一种是调整之前说的惩罚函数中的C,另一种其实从式子上来看,min ||w||^2这个看起来是不是很眼熟?在最小二乘法回归的时候,我们看到过这个式子,这个式子可以让函数更平滑,所以SVM是一种不太容易over- fitting的方法。
参考文档:
主要的参考文档来自4个地方,wikipedia(在文章中已经给出了超链接了),pluskid关于SVM的博文,Andrew moore的ppt(文章中不少图片都是引用或者改自Andrew Moore的ppt,以及prml
引自:http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html
感谢LeftNotEasy的介绍,剩下的还是需要自己去看SVM提出者的文章和测试相关的源码的程序,才能理解的更深入,并最终用到自己的想法上,加油!!!
以下网址需要好好琢磨和研究:
wiki:http://en.wikipedia.org/wiki/Support_vector_machine
http://www.dtreg.com/svm.htm
http://www.cnblogs.com/leivo/archive/2010/08/30/1812625.html
libsvm
http://www.csie.ntu.edu.tw/~cjlin/libsvm/index.html?js=1#svm-toy-js
svmlight
http://svmlight.joachims.org/
支持向量机(SVM)基础的更多相关文章
- 转:机器学习中的算法(2)-支持向量机(SVM)基础
机器学习中的算法(2)-支持向量机(SVM)基础 转:http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html 版 ...
- 机器学习中的算法(2)-支持向量机(SVM)基础
版权声明:本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gma ...
- 【IUML】支持向量机SVM
从1995年Vapnik等人提出一种机器学习的新方法支持向量机(SVM)之后,支持向量机成为继人工神经网络之后又一研究热点,国内外研究都很多.支持向量机方法是建立在统计学习理论的VC维理论和结构风险最 ...
- 支持向量机SVM 参数选择
http://ju.outofmemory.cn/entry/119152 http://www.cnblogs.com/zhizhan/p/4412343.html 支持向量机SVM是从线性可分情况 ...
- 机器学习第7周-炼数成金-支持向量机SVM
支持向量机SVM 原创性(非组合)的具有明显直观几何意义的分类算法,具有较高的准确率源于Vapnik和Chervonenkis关于统计学习的早期工作(1971年),第一篇有关论文由Boser.Guyo ...
- 【Supervised Learning】支持向量机SVM (to explain Support Vector Machines (SVM) like I am a 5 year old )
Support Vector Machines 引言 内核方法是模式分析中非常有用的算法,其中最著名的一个是支持向量机SVM 工程师在于合理使用你所拥有的toolkit 相关代码 sklearn-SV ...
- OpenCV支持向量机SVM对线性不可分数据的处理
支持向量机对线性不可分数据的处理 目标 本文档尝试解答如下问题: 在训练数据线性不可分时,如何定义此情形下支持向量机的最优化问题. 如何设置 CvSVMParams 中的参数来解决此类问题. 动机 为 ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- 机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资) 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异 ...
随机推荐
- 笔记本_Lenovo_G480
ZC: 这是 严g 的笔记本 1.进入 BIOS --> F2键 2.安装 WinServer2003时,蓝屏 2.1.Win2003的PE(不太明白 这里的PE指什么...)不支持 AHCI ...
- jQuery实现两个按钮的位置互换
页面上有2个按钮A和B.点击按钮A和按钮B互换位置 ,点击按钮B和按钮A互换位置.应该如何实现? html代码如下: <body> <!--页面上有2个按钮A和B. 点击按钮A和按钮 ...
- sqlplus无密码登录TNS协议适配器错误
登录到sqlplus使用无密码登录用户时出现:TNS协议适配器错误 检查自己是否有多个数据库,可能默认登录的数据库服务没有启动,启动即可. 查看当前数据库名 select name from v$d ...
- 主页面获取iframe 的子页面方法。
父页面parent.html <html> <head> <script type="text/javascript"> function sa ...
- c#简易反射调用泛型方法
// 所谓程序集的简单理解,存在不同项目中(不是解决方案),即using前需要引用**.dll 1.调用当前类文件下的方法public List<T> GetByCondition< ...
- PDF 补丁丁 0.4.2.1023 测试版发布:新增旋转页面功能
新的测试版发布啦.此版本增加了旋转页面的功能. 在“PDF文档选项”对话框的“页面设置”选项卡中,可设置需要旋转的页面(输入页码范围),以及旋转角度. 此外,还修复了统一页面尺寸功能的小问题.
- foundation框架—结构体
Foundation框架—结构体 一.基本知识 Foundation—基础框架.框架中包含了很多开发中常用的数据类型,如结构体,枚举,类等,是其他ios框架的基础. 如果要想使用foundation框 ...
- [vijos P1035] 贪婪的送礼者
为何我要做此等弱智题,只因我太久不码代码,心有所虚… 明天的任务是,做些难题,累了就理房间,实在不行就睡觉,不要做别的事情w 目测自己做不到呢OAO program vijos_p1035; ..] ...
- 使用Spring整合javaMail发用邮件
1.导入javamail.jar 自行百度下载 2.使用模板发送邮件架包 freemarker.jar 3.Spring配置文件 以及架包这里就不需要说了吧,如果不明白的发我Email ...
- wireshark使用方法(学习笔记一)
wireshark是非常流行的网络封包分析软件,功能十分强大.可以截取各种网络封包,显示网络封包的详细信息.使用wireshark的人必须了解网络协议,否则就看不懂wireshark了. 为了安全考虑 ...