基于MPI的并行计算—矩阵向量乘
以前没接触过MPI编程,对并行计算也没什么了解。朋友的期末课程作业让我帮忙写一写,哎,实现结果很一般啊。最终也没完整完成任务,惭愧惭愧。
问题大概是利用MPI完成矩阵和向量相乘。输入:Am×n,Bn×1 ,输出:Cm×1
附:程序中定义m=400,n=100,矩阵和向量的取值为随意整型数,为了便于显示并行效果,循环完成该计算任务100000次。
实现过程
1.实验环境:WINDOWS8.1 64位+ MPICH + VS2013 / kubuntu 14.04 + mpich
2.解题思路:采用带状划分的并行算法,同时用主从结构,设处理器个数为p,对矩阵A按行划分成p块,每块含有连续的m行向量,m = N/p,分别存放在标号0...p-1的处理器中,同时将向量B广播给所有处理器。各处理器并行地进行矩阵向量乘积操作,最后返回结果。
运行代码如下:
#include "mpi.h"
#include <stdio.h>
#include <stdlib.h> const int rows = ; //the rows of matrix
const int cols = ; //the cols of matrix int main(int argc, char* argv[])
{
int i, j, k, myid, numprocs, anstag;
int A[rows][cols], B[cols], C[rows];
int masterpro,buf[cols], ans,cnt;
double starttime,endtime;
double tmp,totaltime; MPI_Status status;
masterpro = ;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);
for(cnt = ; cnt < ; cnt++){
if(numprocs < ){
printf("Error:Too few processes!\n");
MPI_Abort(MPI_COMM_WORLD,);
}
if(myid == masterpro){
starttime = MPI_Wtime();
for (i = ; i < cols; i++)
{
B[i] = rand()%;
for (j = ; j < rows; j++)
{
A[j][i] = rand()%;
}
}
//bcast the B vector to all slave processor
MPI_Bcast(B, cols, MPI_INT, masterpro, MPI_COMM_WORLD);
//partition the A matrix to all slave processor
for (i = ; i < numprocs; i++)
{
for (k = i - ; k < rows; k += numprocs - )
{
for (j = ; j < cols; j++)
{
buf[j] = A[k][j];
}
MPI_Send(buf, cols, MPI_INT, i, k, MPI_COMM_WORLD);
}
}
}
else{
//starttime = MPI_Wtime();
MPI_Bcast(B, cols, MPI_INT, masterpro, MPI_COMM_WORLD);
//every processor receive the part of A matrix,and make Mul operator with B vector
for ( i = myid - ; i < rows; i += numprocs - ){
MPI_Recv(buf, cols, MPI_INT, masterpro, i, MPI_COMM_WORLD, &status);
ans = ; for ( j = ; j < cols; j++)
{
ans += buf[j] * B[j];
}
//send back the result
MPI_Send(&ans, , MPI_INT, masterpro, i, MPI_COMM_WORLD);
}
//endtime = MPI_Wtime();
//tmp = endtime-starttime;
}
if(myid == masterpro){
//receive the result from all slave processor
for ( i = ; i < rows; i++)
{
MPI_Recv(&ans, , MPI_INT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
//sender = status.MPI_SOURCE;
anstag = status.MPI_TAG;
C[anstag] = ans;
}
//print the result
/*
for (i = 0; i < rows; i++)
{
printf("%d ",C[i]);
if((i+1)%20 == 0)
printf("\n");
}
*/
}
}
endtime = MPI_Wtime();
totaltime = endtime-starttime;
//printf("cost time:%f s.\n",tmp);
//MPI_Reduce(&tmp,&totaltime,1,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_WORLD);
if(myid == masterpro)
printf("total time:%f s.\n",totaltime);
MPI_Finalize();
return ;
}
测试结果:单机多进程运行时,由于进程资源分配和cpu使用率会随着进程数增加而减少,所以时间反而会久一点。在linux上测试时,发现2进程运行时,CPU使用率能达100%,4进程运行时平均50%左右。

联机测试过程,还存在一些问题,自己也没处理好,这里就不误导大家了。
环境搭建
Linux环境 kubuntu 14.04
(1)安装:
sudo apt-get install mpd
sudo apt-get install mpich
(2)编译运行
mpicc -o matrixvec matrixvec.c
mpirun -np ./matrixvec
Windows环境
主要是MPICH3.1.3+VS2013搭建过程的一些注意问题。
(1)下载安装:在MPICH官网下载相应的包,虽然系统是64位,但实际测试过程中,发现64为的mpich3.1.3无法运行,重新安装32位版本后才正常,所以建议安装32位版本。同时在环境变量PATH添加mpich/bin的路径。
(2)注册账号:运行安装目录下的/bin/wmpiregister.exe,输入系统用户名、密码。注意,这里注册的是你在使用的电脑系统的用户名和密码。

(3)运行测试:运行安装目录下的/bin/wmpiexec.exe,选择Application为安装目录下\examples\cpi.exe(一个计算圆周率的例子程序)
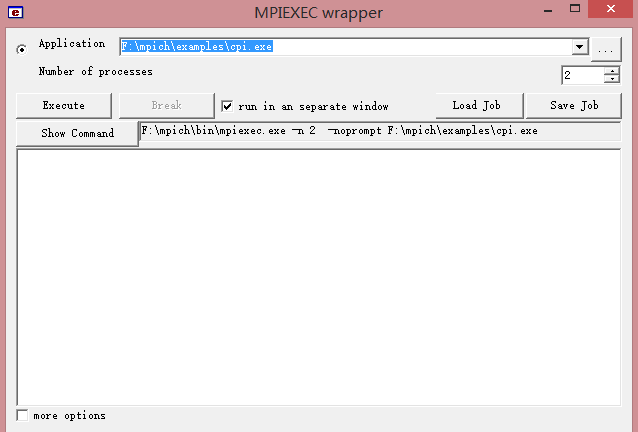
若遇到下例问题,用管理员权限打开控制台,输入smpd -install即可

下面用VS2013实现简单的mpi程序作为示例,分享一下配置过程。
(1)打开VS2013,新建项目及源文件
(2)配置项目属性,引入mpi头文件和库
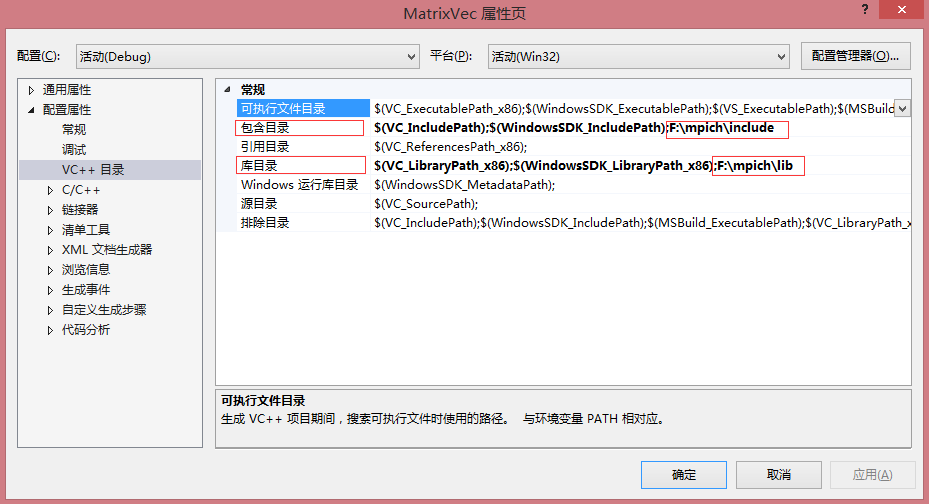
因为VC的IO库与MPI头文件中的宏定义有冲突,所以需要预定义一个MPICH_SKIP_MPICXX宏,使得预编译时跳过MPICXX定义,同时可以添加_CRT_SECURE_NO_WARNINGS。

代码生成,设置运行库为多线程,在如下位置选择“Multi-threaded Debug (/MTd)”,可以通过下拉单选择

链接器添加连接库,在如下位置添加“mpi.lib”

配置完成,通过VS编译mpi程序,用wmpiexec.exe打开生成的exe文件便可运行,或者用命令行形式。
相关参考:
1.MoreWindows Blog:Windows系统下搭建MPI(并行计算)环境
2.Romi-知行合一:Windows下MPI的环境搭建及机群测试
基于MPI的并行计算—矩阵向量乘的更多相关文章
- 基于MPI的大规模矩阵乘法问题
转载请注明出处. /* Function:C++实现并行矩阵乘法; Time: 19/03/25; Writer:ZhiHong Cc; */ 运行方法:切到工程文件x64\Debug文件下,打开命令 ...
- AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法
AAAI 2018 论文 | 蚂蚁金服公开最新基于笔画的中文词向量算法 2018-01-18 16:13蚂蚁金服/雾霾/人工智能 导读:词向量算法是自然语言处理领域的基础算法,在序列标注.问答系统和机 ...
- 基于word2vec的文档向量模型的应用
基于word2vec的文档向量模型的应用 word2vec的原理以及训练过程具体细节就不介绍了,推荐两篇文档:<word2vec parameter learning explained> ...
- 快速电路仿真器(FastSPICE)中的高性能矩阵向量运算实现
今年10-11月份参加了EDA2020(第二届)集成电路EDA设计精英挑战赛,通过了初赛,并参加了总决赛,最后拿了一个三等奖,虽然成绩不是很好,但是想把自己做的分享一下,我所做的题目是概伦电子出的F题 ...
- Spark MLlib之使用Breeze操作矩阵向量
在使用Breeze 库时,需要导入相关包: import breeze.linalg._ import breeze.numerics._ Breeze创建函数 //全0矩阵 DenseMatrix. ...
- sparkmllib矩阵向量
Spark MLlib底层的向量.矩阵运算使用了Breeze库,Breeze库提供了Vector/Matrix的实现以及相应计算的接口(Linalg).但是在MLlib里面同时也提供了Vector和L ...
- opengl矩阵向量
如何创建一个物体.着色.加入纹理,给它们一些细节的表现,但因为它们都还是静态的物体,仍是不够有趣.我们可以尝试着在每一帧改变物体的顶点并且重配置缓冲区从而使它们移动,但这太繁琐了,而且会消耗很多的处理 ...
- 基于FPGA的4x4矩阵键盘驱动调试
好久不见,因为博主最近两个月有点事情,加上接着考试,考完试也有点事情要处理,最近才稍微闲了一些,这才赶紧记录分享一篇博文.FPGA驱动4x4矩阵键盘.这个其实原理是十分简单,但是由于博主做的时候遇到了 ...
- 基于 MPI/OpenMP 混合编程的大规模多体(N-Body)问题仿真实验
完整代码: #include <iostream> #include <ctime> #include <mpi.h> #include <omp.h> ...
随机推荐
- Zabbix 3.0.3 SQL Injection
Zabbix version 3.0.3 suffers from a remote SQL injection vulnerability. ============================ ...
- 《K&R》中引用的几个排序算法(shellsort、)以及一个自己乱写的排序
留待期末考后更新... void shellsort(int v[], int n) { int gap, i, j, temp; ; gap > ; gap /= ) for(i = gap; ...
- Uiautomator ——API详解
版权声明:本文出自carter_dream的博客,转载必须注明出处. 转载请注明出处:http://www.cnblogs.com/by-dream/p/4921701.html 简单的例子 以一个简 ...
- JAVA 使用POI导出数据格式为Execl
需要下载一个poi的jar包. 控制器 @Override public void getContractListExecl(Contract contract, BindingResult resu ...
- [Selenium] 拖拽一个 Component 到 Workspace
先使Component可见,获取Component位置信息,获取Workspace位置信息,点击Component并拖拽到Workspace,最后释放.(调试时dragAndDropOffset()方 ...
- iOS开发 火星坐标转百度坐标
CLLocationCoordinate2D coor = CLLocationCoordinate2DMake(latitude, longitude);//原始坐标 //转换 google地图.s ...
- 在centos6.5中安装scp和lrzsz
简介 scp用于在两台centos中传输文件用的,lrzsz用于在xshell上传输本地文件到远程centos服务器上用的 1.安装scp [root@localhost ~]# scp -ba ...
- spring.xml中的配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- CSS Hack相关知识
CSS Hack 1.由于不同厂商的浏览器,比如Internet Explorer,Safari,Chrome,Mozila Firefox等,或者是同一厂商的浏览器的不同版本,如IE6和IE7,对C ...
- Linux下I/O模型
Unix下共有五种I/O模型 1. 阻塞式I/O 2. 非阻塞式I/O 3. I/O复用(select和poll) 4. 信号驱动式I/O(SIGIO) 5. 异步I/O(POSIX的aio_系列函数 ...