sql索引实例
1.创建表并插入数据
在Sql Server2008中创建测试数据库Test,接着创建数据库表并插入数据,sql代码如下:
USE Test
IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_NAME = 'emp_pay')
DROP TABLE emp_pay
GO
USE Test
IF EXISTS (SELECT name FROM sys.indexes
WHERE name = 'employeeID_ind')
DROP INDEX emp_pay.employeeID_ind
GO
USE Test
GO
CREATE TABLE emp_pay
(
employeeID int NOT NULL,
base_pay money NOT NULL,
commission decimal(2, 2) NOT NULL
)
INSERT emp_pay
VALUES (1, 500, .10)
INSERT emp_pay
VALUES (2, 1000, .05)
INSERT emp_pay
VALUES (6, 800, .07)
INSERT emp_pay
VALUES (5, 1500, .03)
INSERT emp_pay
VALUES (9, 750, .06)
执行完上述sql代码以后我们会发现在Test数据库中多出了一张emp_pay表,数据库表的内容如下图所示:
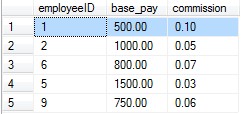
2.无索引查找
从上图我们可以看出数据库中存储的数据排列顺序与我们插入的先后顺序一致。接下来我们查询employeeID=5的字段,执行如下sql代码:
USE Test
SELECT * FROM emp_pay where employeeID=5
在SQL SERVER MANAGEMENT STUDIO中我们点击“显示估计的查询计划”,会出现如下图所示的查询计划图:

其中表扫描的内容为:
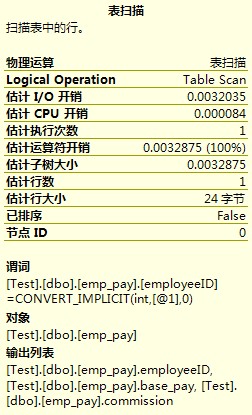
3.创建索引
接下来我们为上述表添加聚集唯一索引,代码如下:
SET NOCOUNT OFF
CREATE UNIQUE CLUSTERED INDEX employeeID_ind
ON emp_pay (employeeID)
GO
在执行完上述创建索引的代码以后,我们再次查询emp_pay的数据内容,如下图所示:

从上图我们可以发现数据内容已经按照employeeID进行了排序。
我们继续执行前面关于employeeID=5的查询,点击“显示估计的执行计划”,出现如下图所示内容:

聚集索引查找的内容为:

总结:
当我们为数据库表中的某一个字段创建索引,并且在查询语句中where子句中用到这样一个字段,那么查询效率会有所提高,我们上述实验因为数据量的关系查询效率提高不明显。
补充
我们上面添加的索引是唯一聚集索引,因此当插入的数据在employeeID字段出现重复时会报错。假如我们在创建索引之前数据字段出现重复,那么就不能创建唯一索引。
创建索引以后的排序(PS:2012-5-28)
执行如下sql语句
update emp_pay set employeeID=7 where employeeID=1;
然后再次执行全表查询,我们发现查询结果如下所示:
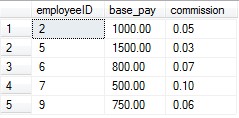
只要我们更新了employeeID,那么最后的更新结果都会按照employeeID的值进行升序排序。这是因为我们在employeeID上创建了索引的缘故。
删除索引(PS:2012-6-4)
我们可以通过sql server management studio这个工具删除索引,也可以通过sql语句进行索引的删除,假设我们要求删除在前面创建的索引employeeID_ind,那么sql语句如下代码所示:
DROP INDEX employeeID_ind ON emp_pay;
sql索引实例的更多相关文章
- mysql sql优化实例
mysql sql优化实例 优化前: pt-query-degist分析结果: # Query 3: 0.00 QPS, 0.00x concurrency, ID 0xDC6E62FA021C85B ...
- SQL索引学习-聚集索引
这篇接着我们的索引学习系列,这次主要来分享一些有关聚集索引的问题.上一篇SQL索引学习-索引结构主要是从一些基础概念上给大家分享了我的理解,没有实例,有朋友就提到了聚集索引的问题,这里列出来一下: 其 ...
- 数据库性能优化:SQL索引
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
- SQL索引一步到位
以下均非原创,仅供分享.学习!!! SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? S ...
- {好文备份}SQL索引一步到位
SQL索引一步到位(此文章为"数据库性能优化二:数据库表优化"附属文章之一) SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百 ...
- 转载:SQL索引一步到位
原文: http://www.cnblogs.com/AK2012/archive/2013/01/04/2844283.html SQL索引一步到位(此文章为“数据库性能优化二:数据库表优化”附属文 ...
- SQL索引一步到位(此文章为“数据库性能优化二:数据库表优化”附属文章之一)
SQL索引一步到位(此文章为“数据库性能优化二:数据库表优化”附属文章之一) SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭 ...
- SQL索引详解
转自:http://www.cnblogs.com/AK2012/archive/2013/01/04/2844283.html SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可 ...
- 数据库性能优化一:SQL索引一步到位
SQL索引在数据库优化中占有一个非常大的比例, 一个好的索引的设计,可以让你的效率提高几十甚至几百倍,在这里将带你一步步揭开他的神秘面纱. 1.1 什么是索引? SQL索引有两种,聚集索引和非聚集索引 ...
随机推荐
- php session_start() 非常慢 问题原因查找
最近在做东西的时候发现一个问题 有一个接口挂了 ,然后进行测试访问地址的时候,浏览器就一直处于等待响应的状态 怎么访问都不行,只有重启web服务器才行. 如果不重启web服务器进行代码调试,总发现在s ...
- Cookie案例-显示商品浏览历史纪录
package cn.itcast.cookie; import java.io.IOException; import java.io.PrintWriter; import java.util.D ...
- 整形输出netsh的内容
$raw = netsh wlan show network mode=bssid $ssids = $raw | Select-String -Pattern 'SSID\b'| Select-St ...
- itertools 介绍
在python中itertool为python提供一系列迭代iterator的方法. 第一个:组合 排列 itertools.combinations(sq, r) 该函数的作用是在列表sq中穷举所有 ...
- php7安装及配置
一.下载php-7.0.5http://cn2.php.net/distributions/php-7.0.5.tar.gz 二.解压安装:# tar zxvf php-7.0.5.tar.gz# c ...
- 使用Mongo官方驱动操作Mongo数据库
首先到 https://github.com/mongodb/mongo-csharp-driver/downloads 下载Mongo官方驱动 下载完成后引用到项目中 public class Co ...
- iOS 宏(define)与常量(const)的正确使用
在iOS开发中,经常用到宏定义,或用const修饰一些数据类型,经常有开发者不知怎么正确使用,导致项目中乱用宏与const修饰 你能区分下面的吗?知道什么时候用吗? #define HSCoder @ ...
- Eclipse设置代码模版
设置注释模板的入口: Window->Preference->Java->Code Style->Code Template 然后展开Comments节点就是所有需设置注释的元 ...
- [转载] 使用MySQL Proxy解决MySQL主从同步延迟
原文地址:http://koda.iteye.com/blog/682547 MySQL的主从同步机制非常方便的解决了高并发读的应用需求,给Web方面开发带来了极大的便利.但这种方式有个比较大的缺陷在 ...
- 【C解毒】滥用变量
见:[C解毒]滥用变量