Java基础(八)——IO流3_对象流
一、对象流
1、序列化与反序列化
序列化:将内存中的Java对象保存到磁盘中或通过网络传输出去。
反序列化:将磁盘文件中的对象还原为内存中的一个Java对象。
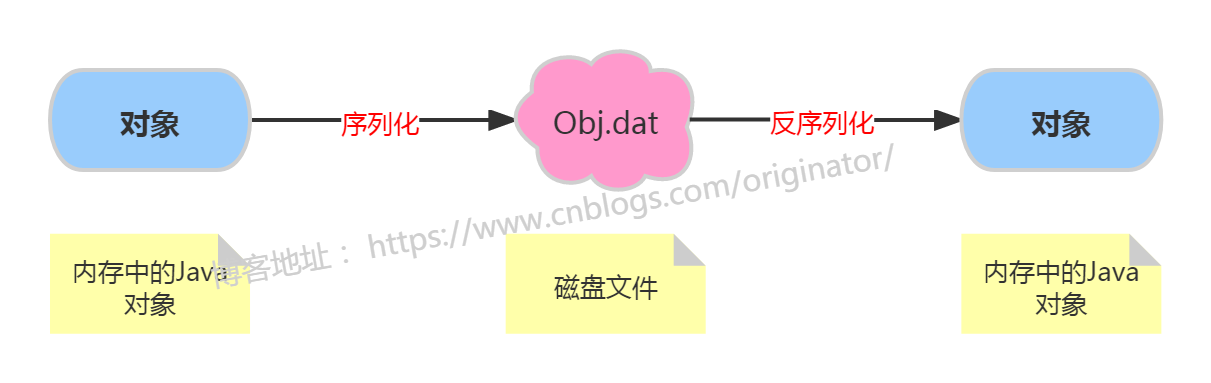
用途:
(1)将对象保存到物理硬盘:比如Web服务器中的Session对象,当有10万用户并发访问时,有可能出现10万个Session对象,内存可能吃不消,从而导致OOM。于是Web容器就会把一些Session序列化到硬盘中,等需要时,再把硬盘中的对象反序列化到内存中。
(2)将对象在网络上进行传输:当两个进程进行通信时,数据都会以二进制序列的形式在网络上进行传输。发送方需要把这个Java对象转换为字节序列,才能在网络上传输;接收方则需要把字节序列再恢复为Java对象。
2、ObjectOutputStream、ObjectInputStream
字节流,处理流。ObjectOutputStream 和 ObjectInputStream,用于存储和读取基本数据类型或对象的处理流。它的强大之处就是可以把Java中的对象写入到数据源中,也能把对象从数据源中还原回来。
序列化:用ObjectOutputStream类保存基本类型数据或对象的机制。
反序列化:用ObjectInputStream类读取基本类型数据或对象的机制。
注:不能序列化static和transient修饰的成员变量。
如何进行序列化?
(1)必须实现接口:Serializable,这是一个标识接口,没有任何抽象方法,用于表明该类是可序列化的。
(2)定义一个全局常量:serialVersionUID,这个常量是可选的,用于标识类的版本号。
(3)若类有类属性:必须保证该类的所有属性也是可序列化的。
代码示例:标准模板
1 public class Person implements Serializable {
2 private static final long serialVersionUID = 1L;
3 }
代码示例:序列化与反序列化
1 // 序列化.对象->磁盘
2 public class Main {
3 public static void main(String[] args) {
4 try (FileOutputStream stream = new FileOutputStream("Obj.dat");
5 // 对象输出流
6 ObjectOutputStream oos = new ObjectOutputStream(stream);) {
7
8 oos.writeObject("用于测试序列化");
9 oos.writeObject(new Person(1001, "张三", new Account(11.1)));
10 } catch (Exception e) {
11 }
12 }
13 }
14
15 // 反序列化.磁盘->对象
16 public class Main {
17 public static void main(String[] args) {
18 try (FileInputStream stream = new FileInputStream("Obj.dat");
19 // 对象输入流
20 ObjectInputStream ois = new ObjectInputStream(stream);) {
21
22 String str = (String) ois.readObject();
23 Person p = (Person) ois.readObject();
24
25 System.out.println(str);
26 System.out.println(p);
27 } catch (Exception e) {
28 }
29 }
30 }
31
32
33 class Person implements Serializable {
34 public static final long serialVersionUID = 1L;
35 private int id;
36 private String name;
37 // private transient double hight; // 不需要序列化
38 private Account acct; // acct属性必须也是可序列化的
39
40 // 无参构造器
41 // 有参构造器
42 // getter & setter
43 // toString()
44 }
45
46 class Account implements Serializable {
47 public static final long serialVersionUID = 1L;
48 private double balance;
49
50 // 无参构造器
51 // 有参构造器
52 // getter & setter
53 // toString()
54 }
总结(重要):
(1)若未实现接口Serializable,会直接报java.io.NotSerializableException异常。
(2)实现Serializable,但不写serialVersionUID,不会有异常,但是会有隐藏的问题。如果类已经序列化了,此时修改了类的结构,比如新增了一个属性,再反序列化的时候会报错。
(3)如果类中某个属性不想被序列化,可以加上关键字transient。
3、serialVersionUID的理解
若没有
private static final long serialVersionUID = 1L;
先序列化类,然后修改类的结构(如,新增一个字段),再反序列化。会报错如下:
java.io.InvalidClassException: temp.file.Person; local class incompatible: stream classdesc serialVersionUID = 503624515100475858, local class serialVersionUID = -443494311322032311
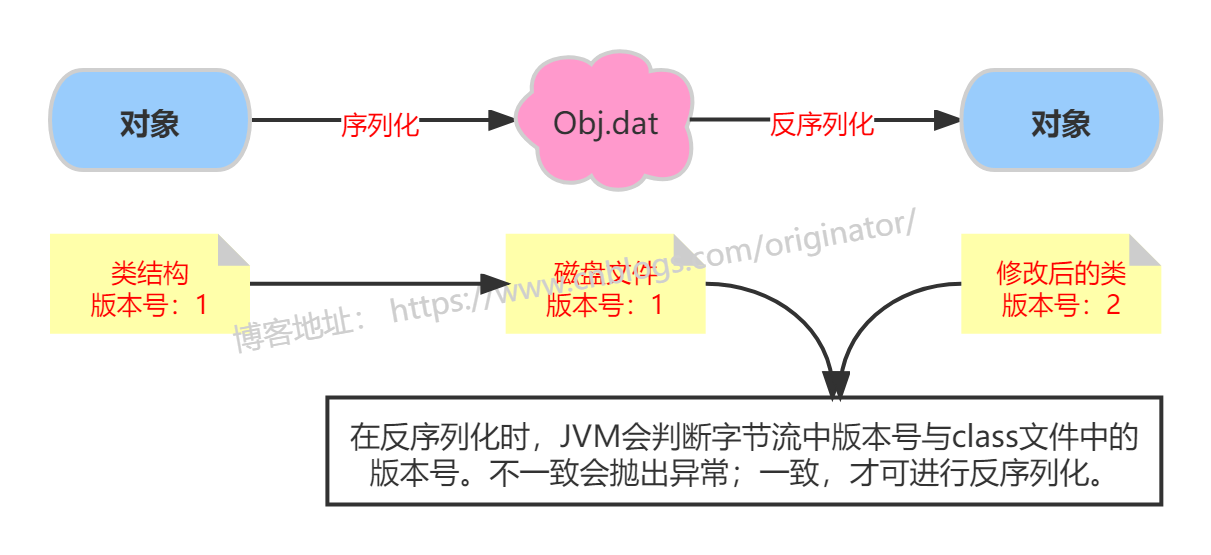
serialVersionUID:序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量,用来表明类的不同版本间的兼容性。
如果类没有显示定义这个静态变量,它的值是Java运行时环境根据类的内部细节自动生成的。若类的结构做了修改,文件流中的class和classpath中的class不兼容了,处于安全机制考虑,程序抛出异常,并拒绝载入。
解决:上述问题只需要显式声明 serialVersionUID 即可。
既然 serialVersionUID 是在序列化的时候使用到,那么抽象类(abstract)没有实例被序列化是不是就不需要定义 serialVersionUID 属性呢?事实是序列化的时候会递归获取父类的描述,所以如果父类的 serialVersionUID 修改了,同样会导致子类对象反序列化失败。
Java基础(八)——IO流3_对象流的更多相关文章
- java基础之IO流(二)之字符流
java基础之IO流(二)之字符流 字符流,顾名思义,它是以字符为数据处理单元的流对象,那么字符流和字节流之间的关系又是如何呢? 字符流可以理解为是字节流+字符编码集额一种封装与抽象,专门设计用来读写 ...
- java基础之IO流(一)字节流
java基础之IO流(一)之字节流 IO流体系太大,涉及到的各种流对象,我觉得很有必要总结一下. 那什么是IO流,IO代表Input.Output,而流就是原始数据源与目标媒介的数据传输的一种抽象.典 ...
- Java基础之IO流整理
Java基础之IO流 Java IO流使用装饰器设计模式,因此如果不能理清其中的关系的话很容易把各种流搞混,此文将简单的几个流进行梳理,后序遇见新的流会继续更新(本文下方还附有xmind文件链接) 抽 ...
- Java基础八--构造函数
Java基础八--构造函数 一.子父类中构造函数的特点 1.1 为什么在子类构造对象时,发现,访问子类构造函数时,父类也运行了呢? 原因是:在子类的构造函数中第一行有一个默认的隐式语句. super( ...
- Java基础IO类之对象流与序列化
对象流的两个类: ObjectOutputStream:将Java对象的基本数据类型和图形写入OutputStream ObjectInputStream:对以前使用ObjectOutputStrea ...
- 【java基础】]IO流
IO流 概念: 流的概念源于unix中管道(pipe)的概念,在unix中,管道是一条不间断的字节流,用来实现程序或进程间的通信,或读写外围设备,外部文件等 一个流,一定能够会有源和去向(目的地),他 ...
- java基础06 IO流
IO用于在设备间进行数据传输的操作. Java IO流类图结构: IO流分类 字节流: InputStream FileInputStream BufferedInputStream Output ...
- java基础之io流总结一:io流概述
IO流概念: 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.io流是实现输入和输出的基础,可以方便的实现数据的输入和输出操作. IO流的分类: 根据处理数据类型的不同分为:字符流 ...
- Java基础学习总结(13)——流IO
一.JAVA流式输入/输出原理 流是用来读写数据的,java有一个类叫File,它封装的是文件的文件名,只是内存里面的一个对象,真正的文件是在硬盘上的一块空间,在这个文件里面存放着各种各样的数据,我们 ...
随机推荐
- html标签设置contenteditable时,去除粘贴文本自带样式
在一个div标签里面加了可编辑的属性,从别的地方复制了一串文本,只想把文本内容存到接口里面,结果发现文本自带的标签和样式都会存进去. $(".session-new-name"). ...
- linux系统的一些常用命令
cd 进入某个目录 ifconfig 查看本机的ip cp (要复制的文件的位置) (要把文件复制的位置) ll 查看文件下,文件的操作权限 ls查看该文件夹下的有那些文件和文件夹 vi filena ...
- logrotate没有rotate的排查过程
前言 背景 xxx,你过来把squid的日志检查一下,是否做了日志切割:于是乎开启了logrotate没有切割日志的排查旅程,em--.只能说过程很爽,平时疲于应付繁琐的事情,难得有点时间能一条线慢慢 ...
- 【JavaWeb】【Maven】001 下载与配置
Maven下载与配置 Download Url:Maven – Download Apache Maven After downloading it, unpack it and configure ...
- 一行配置搞定 Spring Boot项目的 log4j2 核弹漏洞!
相信昨天,很多小伙伴都因为Log4j2的史诗级漏洞忙翻了吧? 看到群里还有小伙伴说公司里还特别建了800+人的群在处理... 好在很快就有了缓解措施和解决方案.同时,log4j2官方也是速度影响发布了 ...
- 07- Vue3 UI Framework - Switch 组件
为了更好的提升用户体验,我们这里再做一个很常用的开关组件 switch 返回阅读列表点击 这里 需求分析 开始之前我们先做一个简单的需求分析 switch 组件应分为选中/未被选中,两种状态 可以通过 ...
- [BUUCTF]PWN——[V&N2020 公开赛]babybabypwn
[V&N2020 公开赛]babybabypwn 附件 步骤: 例行检查,64位程序,保护全开 本地试运行一下,看看程序的大概情况 64位ida载入,看一下main函数 sub_1202()函 ...
- Element-UI 使用 class 方式和 css 方式引入图标
今天在使用 vxe-table 时,需要引入 Element UI的图标,顺便就找了下这些组件库中图标的引用方式. 我们知道 Element .Ant Design.Font Awesome 等很多组 ...
- CF658A Bear and Reverse Radewoosh 题解
Content 一场比赛有 \(n\) 道题目,其中第 \(i\) 道题目的分值为 \(p_i\),需要花费的时间为 \(t_i\).需要说明的是,\(t_i\) 越大,这道题目的难度越大.在第 \( ...
- 盘点 2021|「避坑宝典」为大家分享一下笔者在 2021 年所遇到“匪夷所思”的 Bug 趣事(上)
正版内容:https://xie.infoq.cn/article/3145cd5f525fe26ce9d574c8d 2021尾声想跟大家说的话 虚则实之 引用 https://xie.infoq. ...