HashMap原理及源码分析
HashMap 原理及源码分析
1. 存储结构
HashMap 内部是由 Node 类型的数组实现的。Node 包含着键值对,内部有四个字段,从 next 字段我们可以看出,Node 是一个链表。即数组的每一个位置被当作一个桶,每个桶存储一个链表。HashMap 使用拉链法来解决冲突,同一个桶中存放 hashcode 与数组长度取模运算结果相同的 Node。

static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
2. 索引计算
在 HashMap 中,node 在数组中的索引根据 key 的哈希值与数组长度取模运算得到。
如下为 HashMap 中 putVal 方法(put方法的实际执行过程),
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// ...
}
可以看到第6行中
i = (n - 1) & hash
其中 i 即为根据 key 计算得到的索引,n 为数组的大小。
这是因为在 HashMap 中, 数组的大小为 \(2^n\), 则其二进制形式具有如下特点:
令 x = 1 << 4,即 x 为 2 的 4 次方
x : 0001 0000
x-1 : 0000 1111
令一个数 y 与 x - 1 取与
y : 1101 1011
x-1 : 0000 1111
y&(x-1) : 0000 1011
这个性质和 y 对 x 取模效果是一样的
y : 1101 1011
x : 0001 0000
y%x : 0000 1011
我们知道,位运算的代价比求模运算小的多,因此使用这种计算时用位运算能够带来更高的性能。
3. put 操作
HashMap 中 put 方法实际执行的是 putVal 方法。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
下面为 putVal 方法的实现,为了更好的理解 put 操作,源码中有关红黑树及扩容的部分,先使用省略号代替。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// map 刚构造并且未添加元素时,数组为 null,需要进行初始化
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 计算索引,若索引位置的桶为空,则将其放入桶中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 若桶的头节点的 key 与要插入的 key 相同,将其赋给 e(e 为需要更新的节点)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// ...
else {
// 遍历桶中的链表
for (int binCount = 0; ; ++binCount) {
// 如果到达链表尾部,即 map 中不存在该 key 的节点,则将其添加到尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// ...
break;
}
// 如果在遍历过程中存在 key,则将其赋给 e
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// e 不为空,说明 map 中存在该 key,更新其 value
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//...
}
总结
put 操作主要步骤为:
- 根据 key 计算 node 在数组中的索引
- 若索引位置为空,则将 node 放入该索引位置
- 若不为空
- 遍历该索引位置的桶中元素,比较桶中元素 key 是否与该 key 相同,若相同则更新其 value
- 若桶中不存在该 key,则新建一个 node 放入桶中
4. 扩容
设 HashMap 中数组的长度为 n, 存储的键值对数量为 m, 在哈希函数满足均匀性的前提下,每个链表长度为 m / n。因此查找的时间复杂度为 O(m / n)。
为了减小查找效率,即减小 m / n, 则应该增大 n,即数组的长度。HashMap 使用动态扩容的方式来根据当前键值对的数量,来调整数组的大小,是得空间和时间效率都能得到保证。
和扩容相关的参数主要有:capatity、size、threshold 和 loadFactor
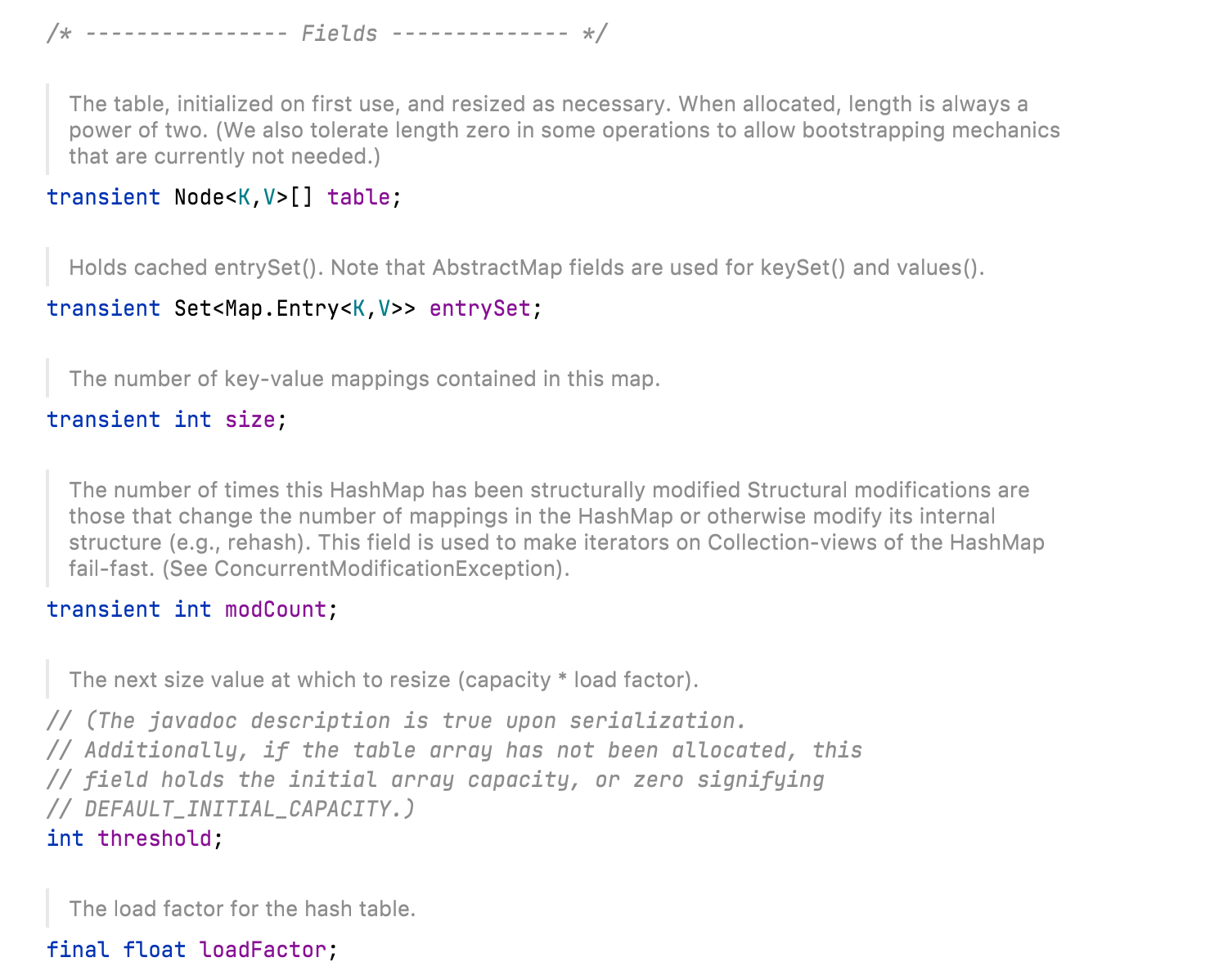
| 参数 | 含义 |
|---|---|
| capacity | table 数组的大小,默认为 16 |
| size | 键值对数量 |
| threshold | size 的临界值,当 size 大于 threshold 时就必须进行扩容操作 |
| loadFactor | 装载因子,默认为 0.75,table 能够使用的比例 threshold = (int) (capacity * loadFactor) |
扩容操作在 putVal 中,有两种情况会触发
- map 初始时,数组大小为 0,需要扩容
- 当键值对数量超过临界值时,触发扩容
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; /* 数组为 null,需要扩容 */
// ...
if (++size > threshold)
resize(); /* size 超过临界值,触发扩容 */
// ...
}
扩容主要分为两步
- 对数组容量进行扩容
- 扩容后需要原来数组的所有键插入到新的数组中
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
// 1. 进行扩容
if (oldCap > 0) {
// 若容量大于等于最大容量,则无法扩容,将临界值改为 int 的最大值,并返回(因为没有扩容无需重新插入键)
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 容量扩大到原来的两倍,并将临界值修改到原来的两倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0) // 若数组大小为 0,临界值不为 0,则数组初始大小为临界值(tableSizeFor 方法保证 oldThr 为 2 的 n 次方,下一节介绍)
newCap = oldThr;
else { // 若数组大小为 0,临界值为 0,则初始大小为 16,初始临界值 = 0.75 * 16 = 12
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// 2. 重新插入键
if (oldTab != null) {
// 遍历旧的数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// 桶中含有元素,则遍历桶中元素
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 若桶中只有一个元素,只需重新计算索引
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 若桶中为红黑树
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 遍历链表
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
/**
* 举个例子
* oldCap : 0001 0000
* newCap : 0010 0000
* newCap-1: 0001 1111
* 若哈希与旧数组大小与运算为 0,则说明
* 哈希与 newCap-1 运算时,与最高位1运算
* 的结果为 0,则索引位置位于 [0,oldCap)
* 若运算结果不为 0,则索引位置为 [oldCap, newCap)
* 又同一个桶中,与 oldCap-1 运算结果相同,
* 即同一个桶中的元素,计算的新索引要么为旧索引值,
* 要么为旧索引值+oldCap(与最高位1相与不为0)
* 则 loHead 为旧索引位置的头节点,hiHead 为
* 新索引位置的头节点
*/
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
5. 保证数组容量为 \(2^n\)
HashMap 的构造函数允许用户传入初始容量,并且可以不是 \(2^n\)。但是 HashMap 可以将其转为 \(2^n\) 。
先考虑如何求一个数的掩码,对于 1000 0000,它的掩码为 1111 1111。可以使用以下方法得到:
mask |= mask >> 1 1100 0000
mask |= mask >> 2 1111 0000
mask |= mask >> 4 1111 1111
则 mask + 1 是大于原始数字的最小的 2 的 n 次方

HashMap 通过 tableSizeFor 来保证数组容量为 2 的 n 次方

HashMap原理及源码分析的更多相关文章
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- HashMap实现原理及源码分析之JDK8
继续上回HashMap的学习 HashMap实现原理及源码分析之JDK7 转载 Java8源码-HashMap 基于JDK8的HashMap源码解析 [jdk1.8]HashMap源码分析 一.H ...
- 每天学会一点点(HashMap实现原理及源码分析)
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希 ...
- ConcurrentHashMap实现原理及源码分析
ConcurrentHashMap实现原理 ConcurrentHashMap源码分析 总结 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对Ha ...
- 并发-HashMap和HashTable源码分析
HashMap和HashTable源码分析 参考: https://blog.csdn.net/luanlouis/article/details/41576373 http://www.cnblog ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- (转)ReentrantLock实现原理及源码分析
背景:ReetrantLock底层是基于AQS实现的(CAS+CHL),有公平和非公平两种区别. 这种底层机制,很有必要通过跟踪源码来进行分析. 参考 ReentrantLock实现原理及源码分析 源 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
随机推荐
- Mac 下安装Phonegap开发环境
Mac 下安装Phonegap开发环境 2014.09.11 星期四 评论 0 条 阅读 5,613 次 作者:野草 标签:phonegap ios mac 什么是Phonegap呢?Phon ...
- Redis入门及常用命令学习
Redis简介 Redis 是完全开源的,遵守 BSD 协议,是一个高性能的 key-value 数据库. Redis 与其他 key - value 缓存产品有以下三个特点: Redis支持数据的持 ...
- odoo14 继承改写原生模块的视图优先级问题
需要类似这样的改写方法: 1.更改id名,方便下方引用!!! 2.使用原生模块的"model"!!! 3.添加字段priority!!!(越小越大) 4.form 和 kanban ...
- LuoguP1898 缘分计算 题解
Content 根据一个长度为 \(l\),只含大写字母的字符串算出它的"缘分值". 步骤如下: 给定一个数 \(st\). 将字符串里面的所有字母改成数字(如 A 改成 \(st ...
- WebApi的前端调用
WebApi前端调用 HTML代码: <!DOCTYPE html><html> <head> <meta charset="utf-8" ...
- Oracle根据约束条件名称查找对应的数据
select * from dba_constraints where constraint_name = 'SYS_C0082752'
- 【九度OJ】题目1074:对称平方数 解题报告
[九度OJ]题目1074:对称平方数 解题报告 标签(空格分隔): 九度OJ 原题地址:http://ac.jobdu.com/problem.php?pid=1074 题目描述: 打印所有不超过n( ...
- 【LeetCode】543. Diameter of Binary Tree 解题报告 (C++&Java&Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 递归 日期 题目地址:https://leetcode ...
- 【LeetCode】732. My Calendar III解题报告
[LeetCode]732. My Calendar III解题报告 标签(空格分隔): LeetCode 题目地址:https://leetcode.com/problems/my-calendar ...
- 【LeetCode】503. Next Greater Element II 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 暴力解法 单调递减栈 日期 题目地址:https:/ ...