【pwn】学pwn日记(堆结构学习)
【pwn】学pwn日记(堆结构学习)
1、什么是堆?
堆是下图中绿色的部分,而它上面的橙色部分则是堆管理器
我们都知道栈的从高内存向低内存扩展的,而堆是相反的,它是由低内存向高内存扩展的

堆管理器的作用,充当一个中间人的作用。管理从操作系统中申请来的物理内存,如果有用户需要,就提供给他。
2、了解堆管理器

注意:linux使用glibc

这里有两种申请内存的系统调用:
- brk
- mmap
第一种brk,是将heap下方的data段(bss属于data段),向上扩展申请的内存。
第二种mmap,其实下图中的shared libraries叫做mmap区域,也就是内存映射。如果使用这种方式申请内存,那么就在这块区域内开辟新的内存空间。

主线程可以用brk和mmap,如果主线程申请的空间过大,那么会使用mmap;如果申请的空间比较小,那么就会再data段上向上扩展一段空间
子线程只能使用mmap段
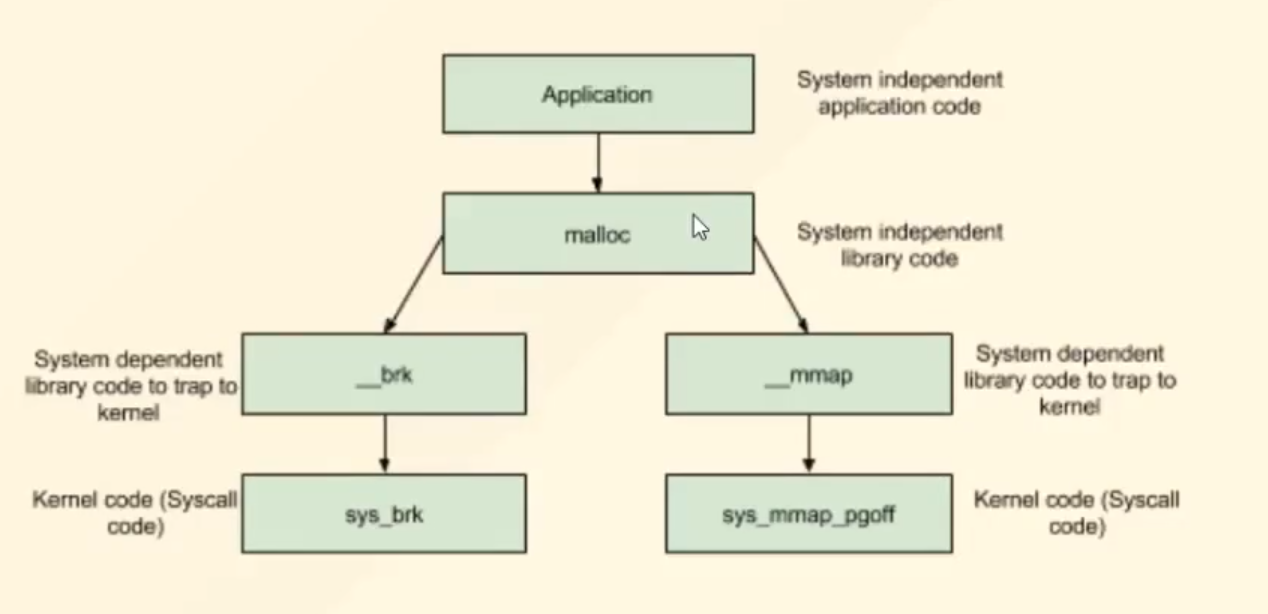
malloc就是向堆管理器申请一块内存空间
free就是将申请来的内存空间归还给堆管理器
用户使用malloc向堆管理器要内存,堆管理器通过brk和mmap向操作系统要内存
3、堆管理器的操作方式
首先了解三个关键词:
- arena
- chunk
- bin

堆管理器可以与用户的内存交易发生于arena中
可以理解为堆管理器向操作系统批发来的有冗余的内存库存
每一个线程中都有一个arena分配区,每一个分配区都有一个控制结构


chunk是内存分配的最小单位,也是我们malloc过来的内存
chunk的size控制字段的最后三位分别是A、M、P
A代表是否是主线程arena中分配的内存
M代表这段区域是否是MMAP的
P用于标识上一个chunk的状态。当它为1时,表示上一个chunk处于释放状态,否则表示上一个chunk处于使用状态
我们来了解malloc_chunk各个成员的功能
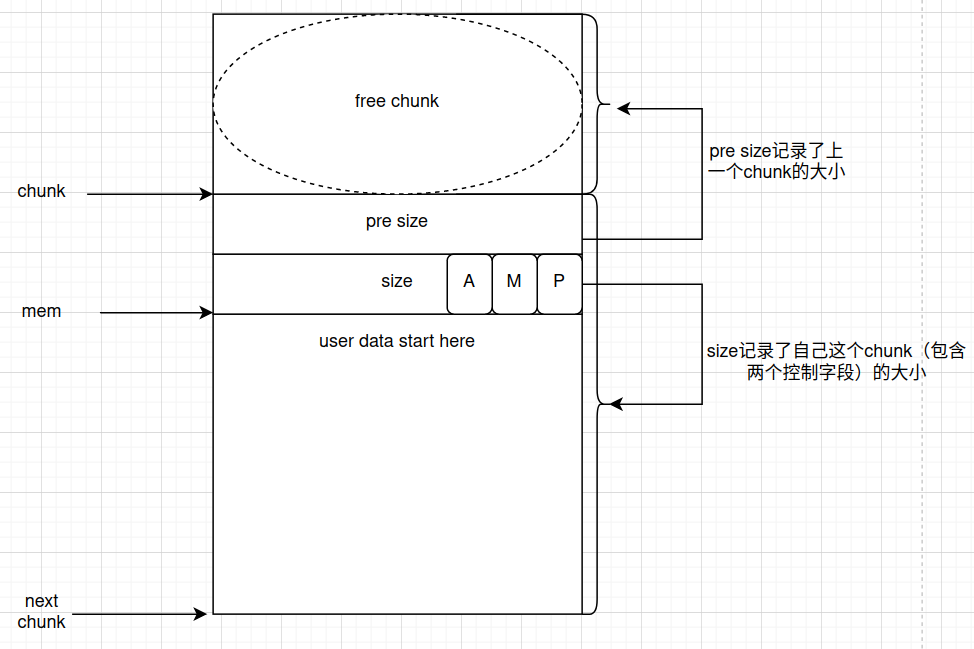
- prev_size:如果上一个chunk处于释放状态,用于表示其大小。否则作为上一个chunk的一个部分,用于保存上一个chunk的数据
- size:表示当前size的大小,根据规定必须是2*SIZE_SZ的整数倍。默认情况下,SIZE_SZ在64位系统下是8字节,32位下是4字节。受到内存对齐的影响,最后3个比特位被用作状态标识,从高到低分别表示
- NON_MAIN_ARENA:用于标识当前堆是否不属于主线程,1 表示不属于,0 表示属于。
- IS_MAPPED:用于标识一个chunk是否是从mmap()函数得到的。如果用户申请一个相当大的内存,malloc会通过mmap分配一个映射段
- PREV_INUSE:用于标识上一个chunk的状态。当它为0时,表示上一个chunk处于释放状态,否则表示上一个chunk处于使用状态
- fd和bk:仅在当前chunk处于释放状态有效。chunk被释放后会加入相应的bin链表中,此时fd和bk指向该chunk在链表的下一个和上一个free chunk(不一定时物理相连的)。如果当前chunk处于使用状态,那么这两个字段是无效的,都是用户使用的空间
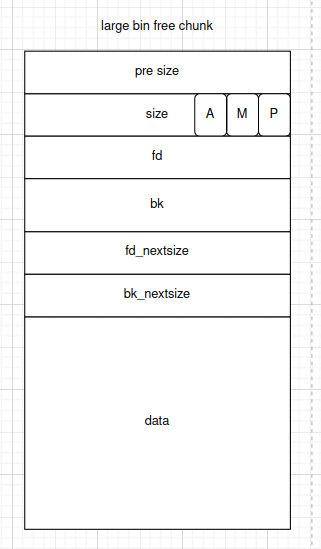
- fd_nextsize和bk_nextsize:与fd和bk相似,仅在处于释放状态时有效,否则就是用户使用的空间。不同的是,它们仅仅用于large bin,分别指向前后第一个和当前chunk大小不同的chunk
4、各种chunk的结构
chunk有4种:
alloced_chunk
free_chunk
top chunk
ast_remainder chunk
1.alloced_chunk
- 首先认识alloced chunk结构,alloced chunk就是处于使用状态的chunk,即pre_size和size组成的chunk header和后面供用户使用的user data。malloc函数返回给用户的实际上是指向用户数据的mem指针
2.free_chunk
- 再认识free chunk中最常见的几种
- small bin、unsorted bin
- 这两种结构如下图所示

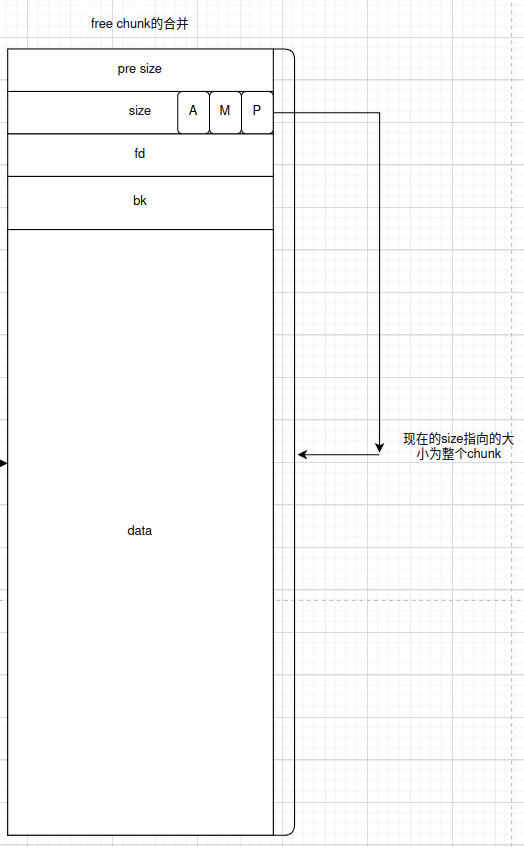
- 如果下面的这个chunk被free了,并且标志位P=0(也就是上一个chunk是free chunk),那么会变成这样的一个大的free chunk
- large bin free chunk 的结构
- fast bin free chunk的结构
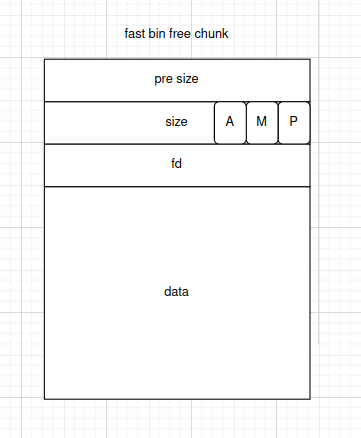
3.top chunk
- 我们再来看top chunk
- 在整个堆初始化后,会被当成一个free chunk,称为top chunk,每次用户申请内存的时候,如果bins中没有合适的chunk,malloc就会从top chunk中进行划分,如果top chunk的大小不够,那么会调用brk()扩展堆的大小,然后从新生成的top chunk中进行切分。
4.last remainder chunk
- 再看last_remainder chunk
- 首先我们需要知道用户申请内存的过程,在底层是如何实现的
- 首先,如果申请的内存小于64bytes,在fastbin中查找并给出
- 如果申请大于64bytes,那么在unsorted bin中查找
- 如果unsorted bin中没有适合申请内存大小的bin段,那么unsorted bin进行遍历合并一部分free chunk,在这些合并后的chunk中找合适的
- 如果还没找到那么就向top chunk在申请一些内存
- 如果top chunk的内存都不够,如果仅仅比top chunk大一点,那么向操作系统要一点,通过brk()的方式扩展top chunk的空间
- 如果比top chunk大了很多很多,那么通过mmap()的方式映射一块内存给和用户
- 说了这么多过程,last remainder chunk在哪里出现了呢?
- 其实在第二步就出现了,因为glibc的特性,在unsorted bin中查询到了比用户申请的内存大的chunk段,malloc就会返回这一段的size之后的指针。而如果我们的这段内存其实比用户申请的大了那么一点,多出来的就会变成我们的last remainder chunk,然后这一部分再在prev size中又进入了unsoorted bin中
5、chunk在glibc中的实现

chunk的结构体如上图,但是我们发现其实除了large bin free chunk之外,其他的chunk都没有用结构体中的所有变量
首先来看一个程序
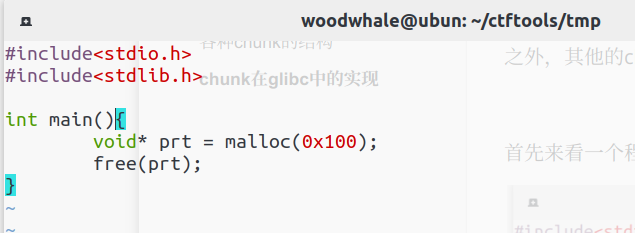
我们申请了一个0x100空间大小的heap,用空指针prt指向malloc返回的地址,然后再通过free()函数释放这段空间
我们用gcc编译一下,得到了一个a.out的elf文件

我们使用gdb对这个elf文件进行调试
我们执行到malloc执行完毕的时候查看vmmap

我们可以看到两个细节:
第一个细节:虽然我们申请的是0x100大小的heap,但是这里第一次申请却有0x21000大小的区域。为什么会申请这么大的空间呢?这个就与我们刚刚了解到的arena有关了
我们知道操作系统会将内存分配给堆管理器,然后堆管理器再调用给用户。
这个过程我们可以怎么理解呢?
就像堆管理器向操作系统批发了一大块内存空间,然后再对用户进行一小份一小份的售卖。
所以我们这里看到的0x21000大小的区域其实是操作系统给堆管理器的(也就是我们上面说的top chunk),然后我们的第二次调用malloc就从这一大份的内存空间中给出
第二个细节:我们发现我们申请的heap区域是在data段的高地址处,这也印证了我们刚刚说的如果主线程申请的内存区域比较小,那么是通过brk的方式在data段的高地址申请一块区域
一个小插曲:
我们想知道在x64下,能最小分配的堆空间是多大呢?
我们继续在刚刚的gdb调试中,输入fastbin
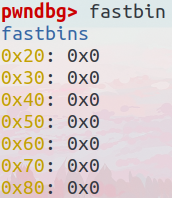
我们最小的chunk被free掉之后就会放入fastbin中,可以看到最小的fastbin是0x20的大小,为什么是0x20的大小呢?

首先在x64下,一个地址的内存大小就为0x8,那么我们的一个最小的chunk,就像上图一样,用pre size记录上一个chunk大小,用size记录自己的大小,size下面是一个fd,在下面是data,所以如果要最小的话,一共是4个0x8,那么就是0x20的大小
那么同理,在x86下,一个地址的内存大小为0x4,所以就是上面的图从中砍了一半,剩下左半部分是有效的,那么最小的堆在x86中就是0x10的大小
回到主线:
我们在test.c中使用malloc申请的是0x100的大小空间,但是实际上,堆管理器会给我们0x110的chunk,这多出来的0x10实际上就是prev size和size的大小,我们能够使用的data段就是这个0x100大小空间

这个时候我们又有一个问题了,我们是通过空指针prt当再malloc的返回值,那么我们的ptr指针在哪里呢?其实我们pte指针是指向0x100这个数据段的,而并非prev size这个chunk的开头部分

我们再回到调试,输入heap观察堆,可以发现我们申请的0x100大小的空间其实是0x111,这是为什么呢?(其他的heap、chunk区域可能是程序的缓冲区之类的)
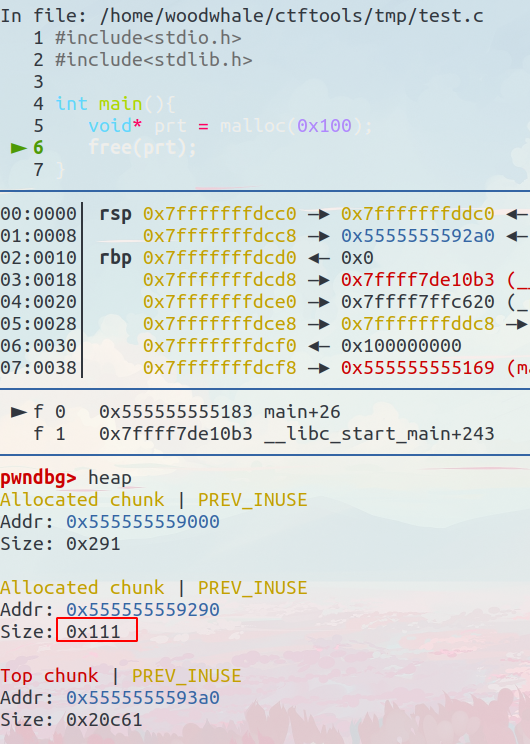
这个0x111其实是0x100+0x10+0x1得来的
0x10就是prev size+size的大小
0x1其实是size最后的3bit中的P=1
然后我们再来看ptr这个指针,我们刚刚说了ptr这个malloc返回的指针处在size之后的data段开头
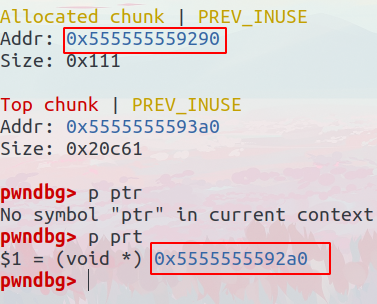
我们申请的0x100大小的heap的addr是0x55555555559290,而我们ptr这个指针指向的地址是0x555555552a0,我们发现其实是heap的addr+0x10,也就是在pre size和size之后,印证了我们刚刚的结论
再来一个小插曲:
这个插曲是关于prev size的覆用
首先说一个结论,我们申请0xn0大小的空间和申请0xn8大小的空间,堆管理器给我们的内存是一样的,为什么呢?
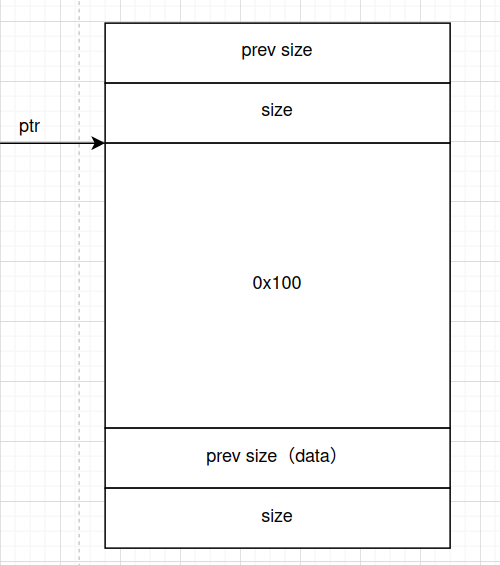
因为prev size的作用是记录相邻的低地址的free chunk的大小,而如果prev size上面是一个malloced chunk,那么prev size就没有作用了,这个时候堆管理器体现出了节省内存的思想,将prev size进行覆写,从而获得0x8的内存大小
6、bin和链表
bin是什么?在英文中,bin是垃圾桶的意思,就如字面意思一样,bin是管理堆的回收。
bin管理arena中空闲的chunk的结构,并且以数组的形式存在,数组元素为相应大小的chunk链表的链表头。bin存在于arena的malloc_state中
在chunk被释放的时候,glibc会将它们重新组织起来,构成不同的bin链表。当用户再次申请的时候,就会从其中寻找合适的chunk返回给用户。
不同大小区间的chunk被划分到不同的bin中,再加上一种特殊的fast bin,一共是4种:fast bin、small bin、large bin、unsorted bin
关于chunk中的链表有两种:
- 物理链表
- 逻辑链表
- 物理链表就是每一个prev size记录了前面一个free chunk的大小,从而可以指向上一个prev size,形成了一个物理链表。这种链表是物理层面上的相邻
- 而逻辑链表不是物理层面的互相连在一起,而是通过chunk中的指针来连接,比如fastbin就是由fd连到下一个prev size,然后按照这样的结构延续下去的一个结构。逻辑链表就是将同类型的chunk通过指针连接在一起。
在bin中我们一般都是讨论逻辑链表
fastbins如下图所示,我们可以从中看出逻辑链表的结构特点
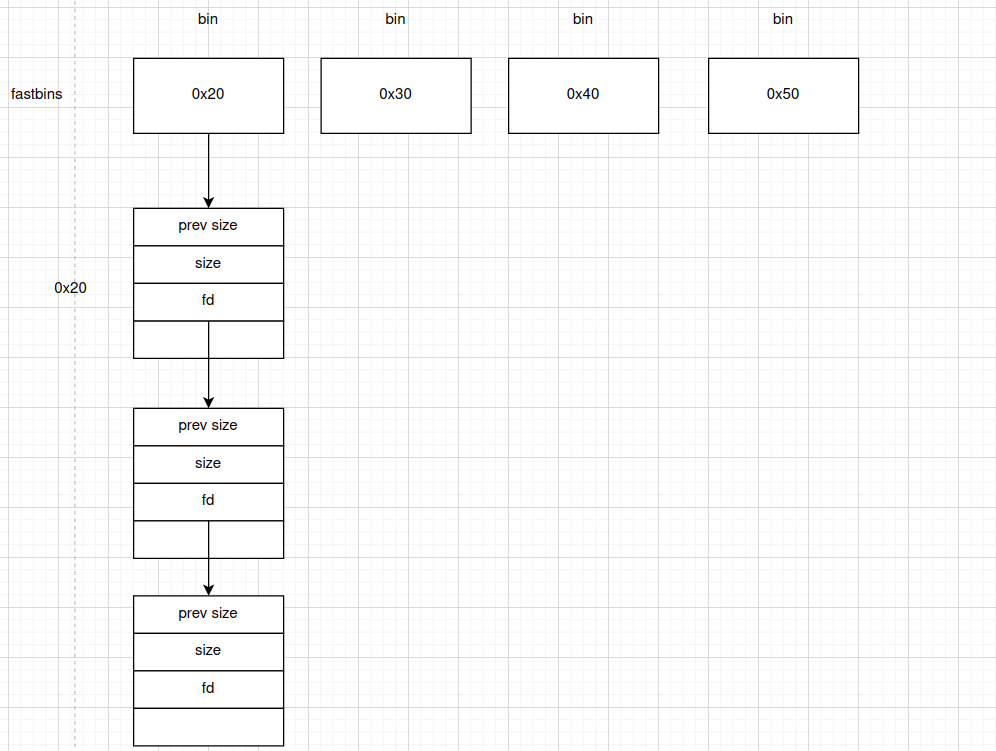
逻辑链表的好处是什么呢?如果我们想要再free之后重新申请一块区域,这个时候在bins中就会寻找适配的bin来还原内存空间。而这些空间恰好是被逻辑链表连在一起的,这样就可以提供刚好合适的内存空间给用户,不会造成浪费
bin有两种结构:双向链表和单向链表,除了fastbin是单向链表,其余的bin都是双向链表
我们的bin中有两个bin数组:
- fastbinsY:装有NFASTBINS个fast bin,NFASTBINS一般是7
- bins:是一个bin数组,一共有126个bin,按顺序分别是:
- bin[1]是unsorted bin
- bin[2]~bin[63]是small bin
- bin[64]~bin[126]是large bin
1.fastbin
- 除了fastbin的结构是单项链表,其他的bin都是双向链表。因为fastbin只有一个fd指针。
- fastbin的工作方式是后进先出。
- fastbin的P永远是1,因为就如同字面的fast意思一样,为了更快的释放和分配。这样就避免了fastbin被合并。也就是这样让它有了fast的属性
- 那么我们为什么需要fastbin这种东西呢?
- 因为fastbin的范围是从最小的0x20开始,有7个,也就是到0x80。我们的程序经常性的频繁的会申请一些小空间,如果一些很小的空间都需要被堆管理器频繁的接手,那就会变得非常麻烦,并且消耗资源。这就犹如我们在银行频繁的存入5块钱,然后下一秒又取出3块钱,又存1块钱,然后又取出10块钱。为了避免这样的情况出现,就有了fastbin的单链表。
- 并且这也是为什么fastbin的工作方式是LIFO(后进先出),因为需要快速的管理小的内存空间。也是为什么P永远为1。
- fastbin管理16、24、32、40、48、56、64bytes的free chunks(32位下默认)
- 按照fastbinsY数组里从小到大的顺序,序号为0的fast bin中容纳的chunk大小为4*SIZE_SZ字节,随着序号增加,所容纳的chunk递增2*SIZE_SZ字节。
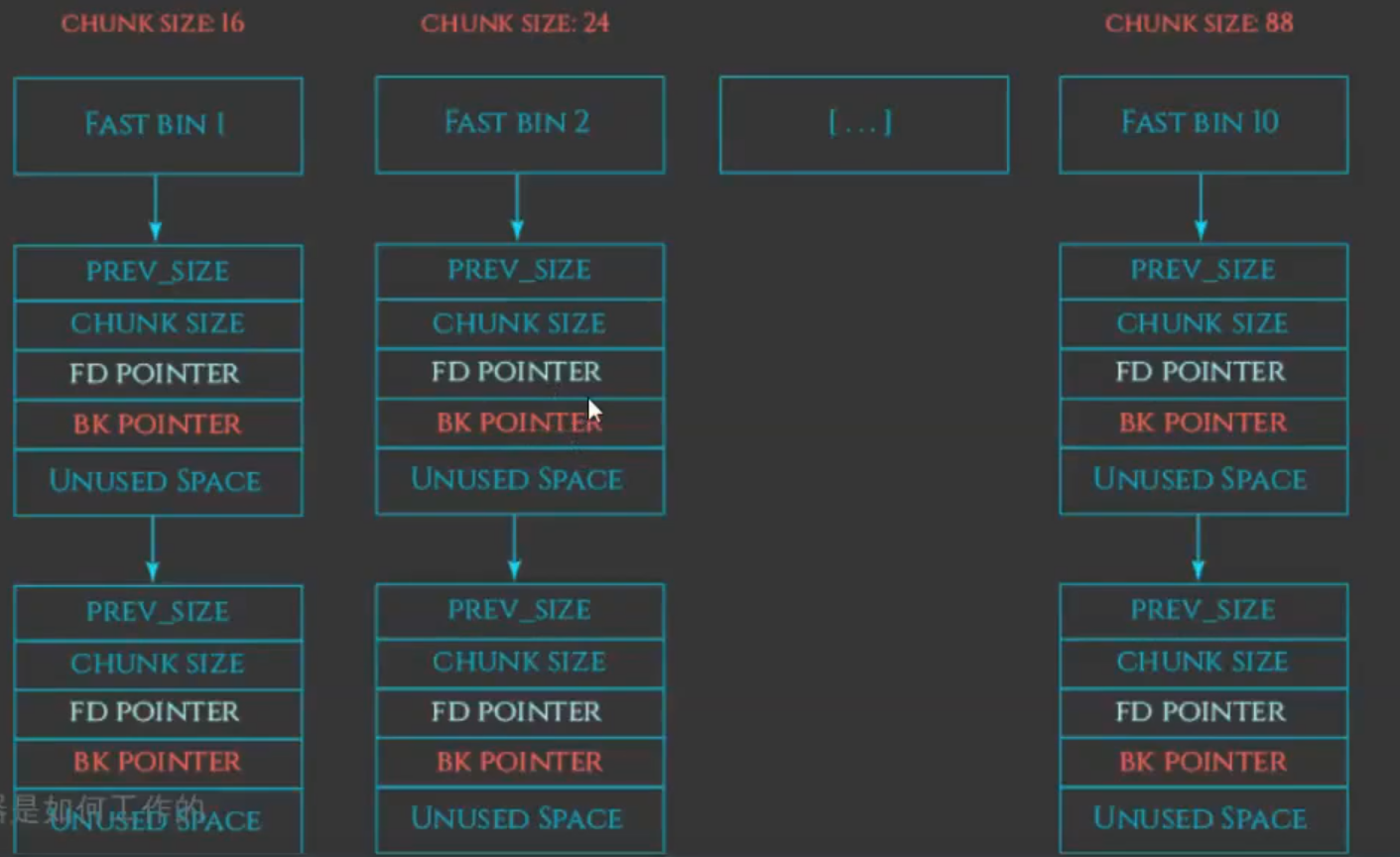
- 这里有一个小插曲:为什么fastbins中有bk指针?
- 因为fastbin管理16~64bytes的free chunks,而smallbin管理16~504bytes的free chunks(32位下)
- 并且如果unsotred bin在自己遍历的过程中,可能会将fastbin变为smallbin。
- 在fastbin中,bk这个域没有任何用处
2.unsorted bin
在实践中,一个被释放的chunk常常很快就会被重新使用,所以将其先放入unsorted bin中,可以加快分配的速度。
- unsorted bin仅仅占用一个,也就没有bins的说法,所以是bin[1]
- unsorted bin管理刚刚释放还未分类的chunk(这也就是为什么叫unsorted bin)
- 我们可以unsorted bin视为空闲的chunk回归其所属bin之前的缓冲区
- 然后unsorted bin因为仅仅是单独的一个,所以结构如下图

- 当malloc了一个在large bin范围之内的chunk,并且在unsorted bin中没有找到满足用户要求的空间大小的free chunk,这个时候unsorted bin就会开始遍历进行可以合并的chunk进行合并(物理结构上相邻的两个或者多个free chunk),合并完成了就会把合并完成后从bin放入相对应的bins中
3.small bin
small bin使用频率介于fast bin和large bin之间。刚刚也提到了在unsorted bin 遍历的时候,fast bin可以变为small bin。
- bin[2]~bin[63]
- 62个循环双向链表
- 先进先出(FIFO)的工作特性
- 管理16、24、32、40、....、504 bytes的free chunks(32位下)
- 每个链表中存储的chunk大小都一样
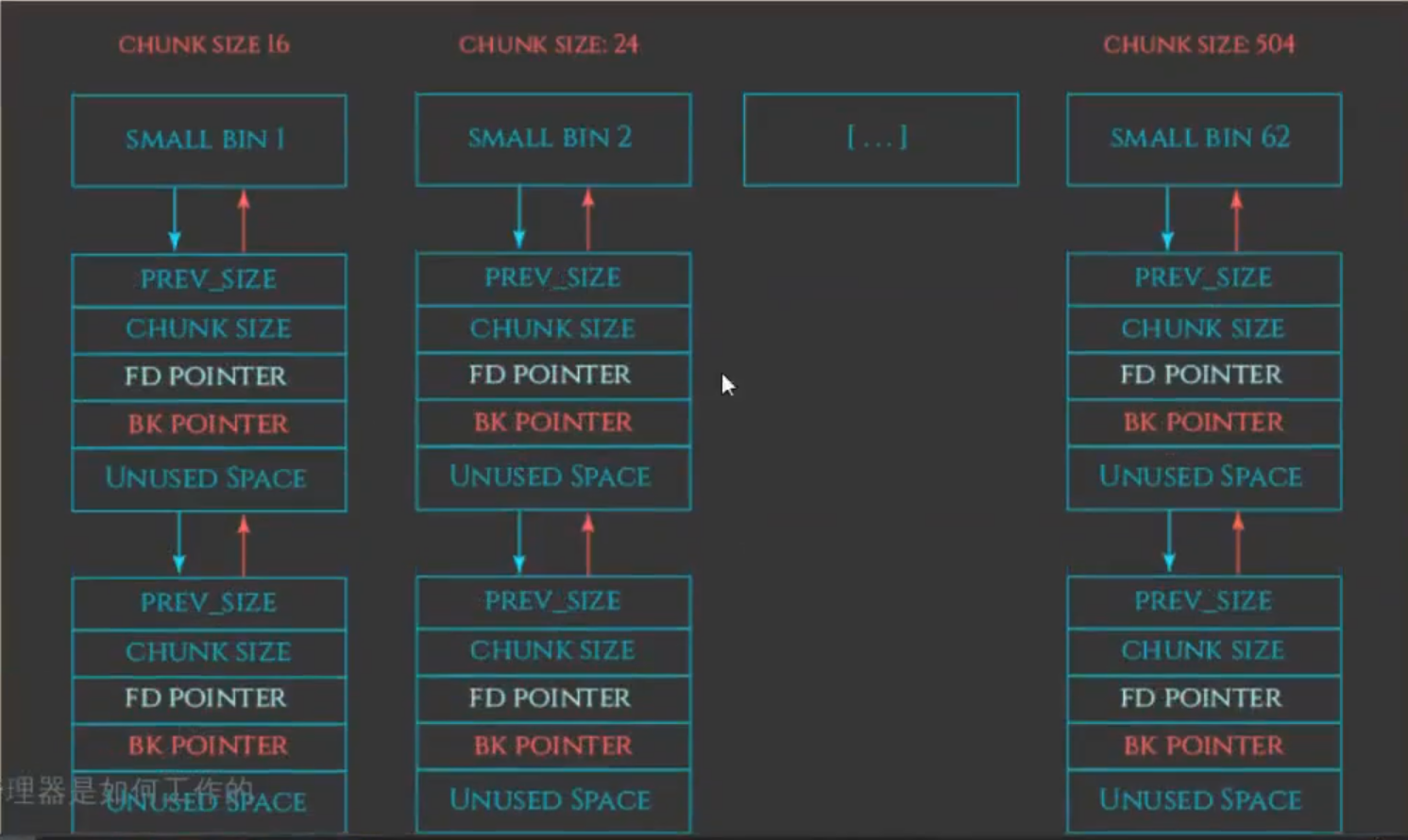
4.large bin
bin[64]~bin[126]
63个循环双向链表
先进先出(FIFO)的工作特性
管理大于504 bytes的free chunks(32位下)
large bin被分为了6组,每组bin能够容纳的chunk按顺序排成了等差数列,如下图所示
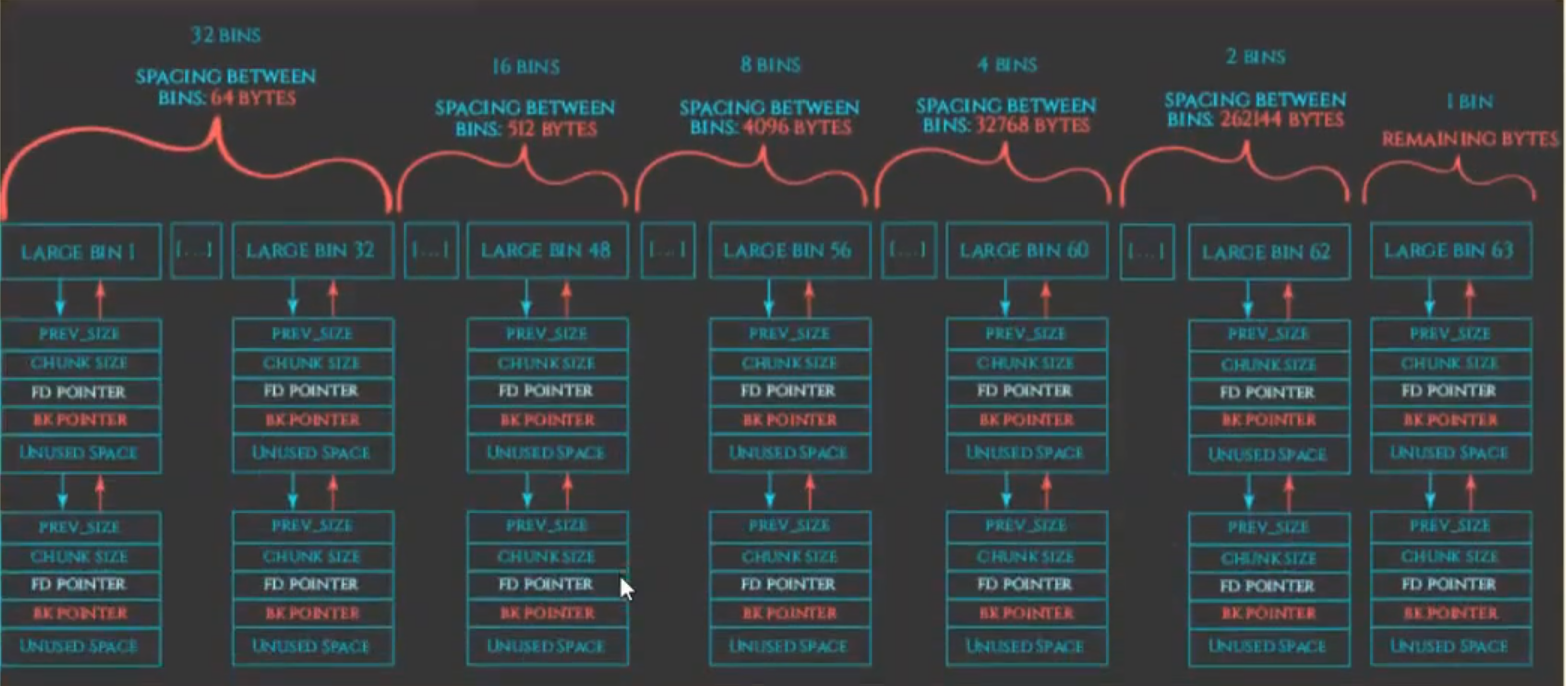
large bin为了加快检索速度,fd_nextsize和bk_nextsize指针用于指向第一个与自己不同大小的chunk。所以只有在加入了大小不同的chunk时,这两个指针才会被修改。
内存申请和释放
这一块等到学到了再补上吧
【pwn】学pwn日记(堆结构学习)的更多相关文章
- 【pwn】学pwn日记——栈学习(持续更新)
[pwn]学pwn日记--栈学习(持续更新) 前言 从8.2开始系统性学习pwn,在此之前,学习了部分汇编指令以及32位c语言程序的堆栈图及函数调用. 学习视频链接:XMCVE 2020 CTF Pw ...
- 堆结构的优秀实现类----PriorityQueue优先队列
之前的文章中,我们有介绍过动态数组ArrayList,双向队列LinkedList,键值对集合HashMap,树集TreeMap.他们都各自有各自的优点,ArrayList动态扩容,数组实现查询非常快 ...
- 《零基础学JavaScript(全彩版)》学习笔记
<零基础学JavaScript(全彩版)>学习笔记 二〇一九年二月九日星期六0时9分 前期: 刚刚学完<零基础学HTML5+CSS3(全彩版)>,准备开始学习JavaScrip ...
- 机器学习&数据挖掘笔记_24(PGM练习八:结构学习)
前言: 本次实验包含了2部分:贝叶斯模型参数的学习以及贝叶斯模型结构的学习,在前面的博文PGM练习七:CRF中参数的学习 中我们已经知道怎样学习马尔科夫模型(CRF)的参数,那个实验采用的是优化方法, ...
- java实现堆结构
一.前言 之前用java实现堆结构,一直用的优先队列,但是在实际的面试中,可能会要求用数组实现,所以还是用java老老实实的实现一遍堆结构吧. 二.概念 堆,有两种形式,一种是大根堆,另一种是小根堆. ...
- Linux 目录结构学习与简析 Part2
linux目录结构学习与简析 by:授客 QQ:1033553122 ---------------接Part 1-------------- #1.查看CPU信息 #cat /proc/cpuinf ...
- Linux 目录结构学习与简析 Part1
linux目录结构学习与简析 by:授客 QQ:1033553122 说明: / linux系统目录树的起点 =============== /bin User Bi ...
- Libheap:一款用于分析Glibc堆结构的GDB调试工具
Libheap是一个用于在Linux平台上分析glibc堆结构的GDB调试脚本,使用Python语言编写. 安装 Glibc安装 尽管Libheap不要求glibc使用GDB调试支持和 ...
- 使用加强堆结构解决topK问题
作者:Grey 原文地址: 使用加强堆结构解决topK问题 题目描述 LintCode 550 · Top K Frequent Words II 思路 由于要统计每个字符串的次数,以及字典序,所以, ...
随机推荐
- CF135A Replacement 题解
Content 有 \(n\) 个数 \(a_1,a_2,a_3,...,a_n\),试用 \(1\) ~ \(10^9\) 之间的数(除了本身)代替其中的一个数,使得这 \(n\) 个数的总和最小, ...
- selecter模块默认使用epoll 实现IO多路复用,展示单线程的并发效果
import selectors import socket sel = selectors.DefaultSelector() def accept(sock, mask): conn, addr ...
- ligerui有时候竖直的线没对齐,是因为某一列的内容太长,此刻可以调整一下此列的宽度为适当的值便可消除此现象
ligerui有时候竖直的线没对齐,是因为某一列的内容太长,此刻可以调整一下此列的宽度为适当的值便可消除此现象
- 【LeetCode】1402. 做菜顺序 Reducing Dishes
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 贪心 日期 题目地址:https://leetcode ...
- 【LeetCode】83. Remove Duplicates from Sorted List 解题报告(C++&Java&Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 判断相邻节点是否相等 使用set 使用列表 递归 日 ...
- 1248 - Dice (III)
1248 - Dice (III) PDF (English) Statistics Forum Time Limit: 1 second(s) Memory Limit: 32 MB Given ...
- The Best Path
The Best Path Time Limit: 9000/3000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Tot ...
- Buy Tickets(poj2828)
Buy Tickets Time Limit: 4000MS Memory Limit: 65536K Total Submissions: 17416 Accepted: 8646 Desc ...
- leetcode日记本
写在前面: 2019.6开始经过一年的学习,我依然没有学会算法,依然停留在最基本的阶段,面对题目依然一头雾水 但是难不是放弃的理由,根据毛主席的论持久战原理,我决定一天看一点循序渐进,相信总有一天可以 ...
- 【Azure API 管理】为调用APIM的请求启用Trace -- 调试APIM Policy的利器
问题描述 在APIM中,通过门户上的 Test 功能,可以非常容易的查看请求的Trace信息,帮助调试 API 对各种Policy,在Inbound,Backend, Outbound部分的耗时问题, ...