Unsupervised Feature Learning via Non-Parametric Instance Discrimination
概
这篇文章也是最近很虎的contrastive learning的经典之作, 其用于下游任务的处理虽没现在的简单粗暴, 但效果依然很好.
主要内容
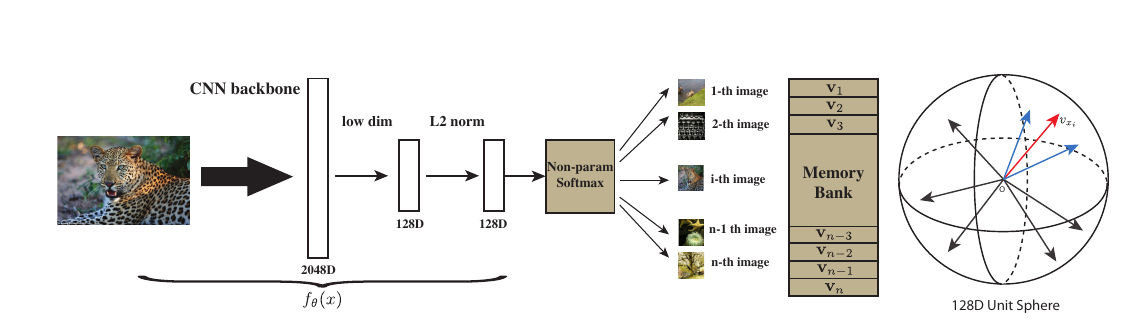
因为作者实际上是从一个无监督的角度去考虑的, 其出发点就是, 如果希望将分类器将每一个样本都区分开来, 是否能够获得比较好的特征呢? 输入\(x\)经过embedding function 得到\(f_{\theta}(x)\), 即特征, 那么现在的问题是:
- 目标是将所有样本作为一个单独的类别, 这就会导致类别个数很大, 甚至成百上千万, 如果这是还和普通的分类任务一样, 将
\]
则最后一个分类层的权重\(W \in \mathbb{R}^{k \times n}\), 这将是无法承受的存储量和计算量.
为了解决这个问题, 作者选择的首先构造一个memory bank, 将特征存储起来, 第\(i\)个样本对应的为\(v_i\), 而当前\(f_{\theta}(x_i)\)记作\(f_i\), 则
\]
这里\(\tau\)是temperature.
这样就避免了\(w\), 且符合直觉: 即衡量了\(f_{\theta}(x)\)与数据中的第\(i\)个样本的相关度. 但是, 虽然这一定程度上减少了存储量, 但是计算量并没有减少, 即我们需要估计分母\(Z_i\), 实际上, 这就是一个配平的问题, 这是负样本采样可以发挥作用的地方.
假设
\]
其中\(P_n(i)\)为一个均匀分布, 即每个特征被选中的概率为\(\frac{1}{n}\). 然后便是经典的损失
\]
个人感觉: \(P_d(i, v) = P(v) \cdot Q(i|v)\), 其中\(Q(i|v)\)仅当\(v\)为第\(i\)个样本点的特征是概率为\(1\)否则为\(0\). 而\(P_n(i, v) = P(v) \cdot \frac{1}{n}\). 同时, 估计
\]
感觉就像是一个抽样. 这个\(\frac{n}{m}\)最新的文章里出现过, 但是当时没感觉出其意义来, 原来源头是在这?
解决了计算了和存储问题, 还有一个训练不稳定的问题要解决.
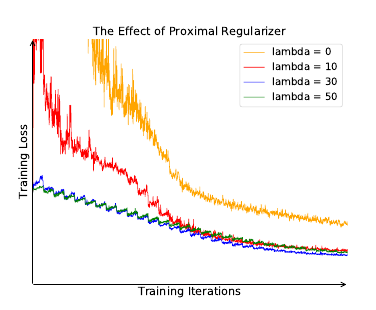
训练不稳定的诱因, 作者认为是每个样本作为一个类, 如此每个类在每个epoch里仅会被访问一次. 解决策略是用proximal 算子:
\]
有疑问的是, 我看的proximal算法里面, 应该是\(\log h(i, v^{(t)})\), 虽然二者可能相差不大.
Unsupervised Feature Learning via Non-Parametric Instance Discrimination的更多相关文章
- paper 124:【转载】无监督特征学习——Unsupervised feature learning and deep learning
来源:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio c ...
- 泡泡一分钟:Stabilize an Unsupervised Feature Learning for LiDAR-based Place Recognition
Stabilize an Unsupervised Feature Learning for LiDAR-based Place Recognition Peng Yin, Lingyun Xu, Z ...
- 转:无监督特征学习——Unsupervised feature learning and deep learning
http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio clas ...
- [转] 无监督特征学习——Unsupervised feature learning and deep learning
from:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio ...
- UFLDL(Unsupervised Feature Learning and Deep Learning)
UFLDL(Unsupervised Feature Learning and Deep Learning)Tutorial 是由 Stanford 大学的 Andrew Ng 教授及其团队编写的一套 ...
- Unsupervised Feature Learning and Deep Learning(UFLDL) Exercise 总结
7.27 暑假开始后,稍有时间,“搞完”金融项目,便开始跑跑 Deep Learning的程序 Hinton 在Nature上文章的代码 跑了3天 也没跑完 后来Debug 把batch 从200改到 ...
- Joint Detection and Identification Feature Learning for Person Search
Joint Detection and Identification Feature Learning for Person Search 2018-06-02 本文的贡献主要体现在: 提出一种联合的 ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- 图像分类之特征学习ECCV-2010 Tutorial: Feature Learning for Image Classification
ECCV-2010 Tutorial: Feature Learning for Image Classification Organizers Kai Yu (NEC Laboratories Am ...
随机推荐
- Spark(十二)【SparkSql中数据读取和保存】
一. 读取和保存说明 SparkSQL提供了通用的保存数据和数据加载的方式,还提供了专用的方式 读取:通用和专用 保存 保存有四种模式: 默认: error : 输出目录存在就报错 append: 向 ...
- Hive(三)【DDL 数据定义】
目录 一.DDL数据定义 1.库的DDL 1.1创建数据库 1.2查询数据库 1.3查看数据库详情 1.4切换数据库 1.5修改数据库 1.6删除数据库 2.表的DDL 2.1创建表 2.2管理表(内 ...
- Oracle中的DBMS_LOCK包的使用
一.DBMS_LOCK相关知识介绍 锁模式: 名字 描述 数据类型 值 nl_mode Null INTEGER 1 ss_mode Sub Shared: used on an aggregate ...
- Linux学习 - 环境变量配置文件
一.环境变量配置文件的作用 /etc/profile /etc/profile.d/*.sh ~/.bash_profile ~/.bashrc /etc/bashrc 1 /etc/profile的 ...
- Mysql不锁表备份之Xtrabackup的备份与恢复
一.Xtrabackup介绍 MySQL冷备.热备.mysqldump都无法实现对数据库进行增量备份.如果数据量较大我们每天进行完整备份不仅耗时且影响性能.而Percona-Xtrabackup就是为 ...
- HashMap 和 HashSet
对于HashSet而言,系统采用Hash算法决定集合元素的存储位置,这样可以保证快速存取集合元素: 对于HashMap,系统将value当成key的附属,系统根据Hash算法来决定key的存储位置,这 ...
- spring-dm 一个简单的实例
spring-dm2.0 运行环境,支持JSP页面 运行spring web 项目需要引用包
- NSURLSessionDownloadTask实现大文件下载
- 4.1 涉及知识点(1)使用NSURLSession和NSURLSessionDownload可以很方便的实现文件下载操作 第一个参数:要下载文件的url路径 第二个参数:当接收完服务器返回的数据 ...
- Dubbo服务调用超时
服务降级的发生,其实是由于消费者调用服务超时引起的,即从发出调用请求到获取到提供者的响应结果这个时间超出了设定的时限.默认服务调用超时时限为1秒.可以在消费者端与提供者端设置超时时限. 一.创建提供者 ...
- 使用IntelliJ IDEA创建简单的Spring Boot项目
方法一: File - New -Project 创建结束后进行测试运行,修改代码如下: package com.springboot.testone; import org.springframew ...