Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例
简介
今天我们会讲解一下Pandas的高级教程,包括读写文件、选取子集和图形表示等。
读写文件
数据处理的一个关键步骤就是读取文件进行分析,然后将分析处理结果再次写入文件。
Pandas支持多种文件格式的读取和写入:
In [108]: pd.read_
read_clipboard() read_excel() read_fwf() read_hdf() read_json read_parquet read_sas read_sql_query read_stata
read_csv read_feather() read_gbq() read_html read_msgpack read_pickle read_sql read_sql_table read_table

接下来我们会以Pandas官网提供的Titanic.csv为例来讲解Pandas的使用。
Titanic.csv提供了800多个泰坦利特号上乘客的信息,是一个891 rows x 12 columns的矩阵。
我们使用Pandas来读取这个csv:
In [5]: titanic=pd.read_csv("titanic.csv")
read_csv方法会将csv文件转换成为pandas 的DataFrame。
默认情况下我们直接使用DF变量,会默认展示前5行和后5行数据:
In [3]: titanic
Out[3]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
.. ... ... ... ... ... ... ... ... ... ... ...
886 887 0 2 Montvila, Rev. Juozas male ... 0 211536 13.0000 NaN S
887 888 1 1 Graham, Miss. Margaret Edith female ... 0 112053 30.0000 B42 S
888 889 0 3 Johnston, Miss. Catherine Helen "Carrie" female ... 2 W./C. 6607 23.4500 NaN S
889 890 1 1 Behr, Mr. Karl Howell male ... 0 111369 30.0000 C148 C
890 891 0 3 Dooley, Mr. Patrick male ... 0 370376 7.7500 NaN Q
[891 rows x 12 columns]
可以使用head(n)和tail(n)来指定特定的行数:
In [4]: titanic.head(8)
Out[4]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. James male ... 0 330877 8.4583 NaN Q
6 7 0 1 McCarthy, Mr. Timothy J male ... 0 17463 51.8625 E46 S
7 8 0 3 Palsson, Master. Gosta Leonard male ... 1 349909 21.0750 NaN S
[8 rows x 12 columns]
使用dtypes可以查看每一列的数据类型:
In [5]: titanic.dtypes
Out[5]:
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
使用to_excel可以将DF转换为excel文件,使用read_excel可以再次读取excel文件:
In [11]: titanic.to_excel('titanic.xlsx', sheet_name='passengers', index=False)
In [12]: titanic = pd.read_excel('titanic.xlsx', sheet_name='passengers')
使用info()可以来对DF进行一个初步的统计:
In [14]: titanic.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
DF的选择
选择列数据
DF的head或者tail方法只能显示所有的列数据,下面的方法可以选择特定的列数据。

In [15]: ages = titanic["Age"]
In [16]: ages.head()
Out[16]:
0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
Name: Age, dtype: float64
每一列都是一个Series:
In [6]: type(titanic["Age"])
Out[6]: pandas.core.series.Series
In [7]: titanic["Age"].shape
Out[7]: (891,)
还可以多选:
In [8]: age_sex = titanic[["Age", "Sex"]]
In [9]: age_sex.head()
Out[9]:
Age Sex
0 22.0 male
1 38.0 female
2 26.0 female
3 35.0 female
4 35.0 male
如果选择多列的话,返回的结果就是一个DF类型:
In [10]: type(titanic[["Age", "Sex"]])
Out[10]: pandas.core.frame.DataFrame
In [11]: titanic[["Age", "Sex"]].shape
Out[11]: (891, 2)
选择行数据
上面我们讲到了怎么选择列数据,下面我们来看看怎么选择行数据:
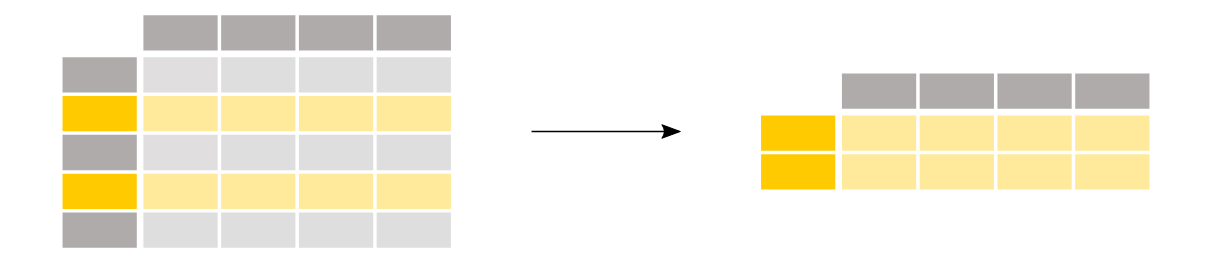
选择客户年龄大于35岁的:
In [12]: above_35 = titanic[titanic["Age"] > 35]
In [13]: above_35.head()
Out[13]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
6 7 0 1 McCarthy, Mr. Timothy J male ... 0 17463 51.8625 E46 S
11 12 1 1 Bonnell, Miss. Elizabeth female ... 0 113783 26.5500 C103 S
13 14 0 3 Andersson, Mr. Anders Johan male ... 5 347082 31.2750 NaN S
15 16 1 2 Hewlett, Mrs. (Mary D Kingcome) female ... 0 248706 16.0000 NaN S
[5 rows x 12 columns]
使用isin选择Pclass在2和3的所有客户:
In [16]: class_23 = titanic[titanic["Pclass"].isin([2, 3])]
In [17]: class_23.head()
Out[17]:
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
5 6 0 3 Moran, Mr. James male NaN 0 0 330877 8.4583 NaN Q
7 8 0 3 Palsson, Master. Gosta Leonard male 2.0 3 1 349909 21.0750 NaN S
上面的isin等于:
In [18]: class_23 = titanic[(titanic["Pclass"] == 2) | (titanic["Pclass"] == 3)]
筛选Age不是空的:
In [20]: age_no_na = titanic[titanic["Age"].notna()]
In [21]: age_no_na.head()
Out[21]:
PassengerId Survived Pclass Name Sex ... Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male ... 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female ... 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female ... 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female ... 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male ... 0 373450 8.0500 NaN S
[5 rows x 12 columns]
同时选择行和列

我们可以同时选择行和列。
使用loc和iloc可以进行行和列的选择,他们两者的区别是loc是使用名字进行选择,iloc是使用数字进行选择。
选择age>35的乘客名:
In [23]: adult_names = titanic.loc[titanic["Age"] > 35, "Name"]
In [24]: adult_names.head()
Out[24]:
1 Cumings, Mrs. John Bradley (Florence Briggs Th...
6 McCarthy, Mr. Timothy J
11 Bonnell, Miss. Elizabeth
13 Andersson, Mr. Anders Johan
15 Hewlett, Mrs. (Mary D Kingcome)
Name: Name, dtype: object
loc中第一个值表示行选择,第二个值表示列选择。
使用iloc进行选择:
In [25]: titanic.iloc[9:25, 2:5]
Out[25]:
Pclass Name Sex
9 2 Nasser, Mrs. Nicholas (Adele Achem) female
10 3 Sandstrom, Miss. Marguerite Rut female
11 1 Bonnell, Miss. Elizabeth female
12 3 Saundercock, Mr. William Henry male
13 3 Andersson, Mr. Anders Johan male
.. ... ... ...
20 2 Fynney, Mr. Joseph J male
21 2 Beesley, Mr. Lawrence male
22 3 McGowan, Miss. Anna "Annie" female
23 1 Sloper, Mr. William Thompson male
24 3 Palsson, Miss. Torborg Danira female
[16 rows x 3 columns]
使用plots作图
怎么将DF转换成为多样化的图形展示呢?
要想在命令行中使用matplotlib作图,那么需要启动ipython的QT环境:
ipython qtconsole --pylab=inline
直接使用plot来展示一下上面我们读取的乘客信息:
import matplotlib.pyplot as plt
import pandas as pd
titanic = pd.read_excel('titanic.xlsx', sheet_name='passengers')
titanic.plot()
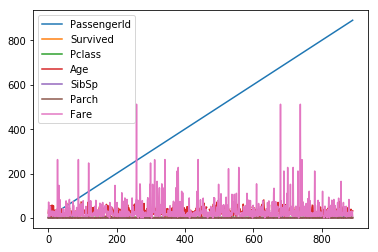
横坐标就是DF中的index,列坐标是各个列的名字。注意上面的列只展示的是数值类型的。
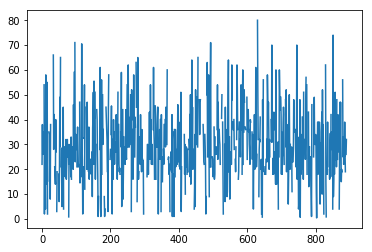
我们只展示age信息:
titanic['Age'].plot()
默认的是柱状图,我们可以转换图形的形式,比如点图:
titanic.plot.scatter(x="PassengerId",y="Age", alpha=0.5)
选择数据中的PassengerId作为x轴,age作为y轴:
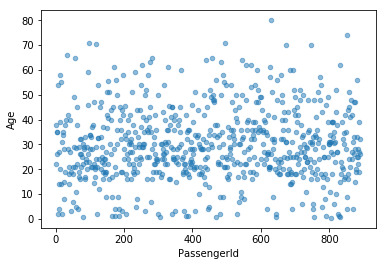
除了散点图,还支持很多其他的图像:
[method_name for method_name in dir(titanic.plot) if not method_name.startswith("_")]
Out[11]:
['area',
'bar',
'barh',
'box',
'density',
'hexbin',
'hist',
'kde',
'line',
'pie',
'scatter']
再看一个box图:
titanic['Age'].plot.box()
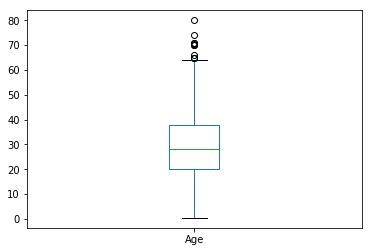
可以看到,乘客的年龄大多集中在20-40岁之间。
还可以将选择的多列分别作图展示:
titanic.plot.area(figsize=(12, 4), subplots=True)
指定特定的列:
titanic[['Age','Pclass']].plot.area(figsize=(12, 4), subplots=True)
还可以先画图,然后填充:
fig, axs = plt.subplots(figsize=(12, 4));
先画一个空的图,然后对其进行填充:
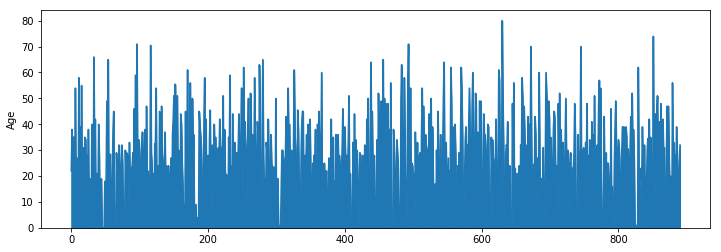
titanic['Age'].plot.area(ax=axs);
axs.set_ylabel("Age");
fig
使用现有的列创建新的列

有时候,我们需要对现有的列进行变换,以得到新的列,比如我们想添加一个Age2列,它的值是Age列+10,则可以这样:
titanic["Age2"]=titanic["Age"]+10;
titanic[["Age","Age2"]].head()
Out[34]:
Age Age2
0 22.0 32.0
1 38.0 48.0
2 26.0 36.0
3 35.0 45.0
4 35.0 45.0
还可以对列进行重命名:
titanic_renamed = titanic.rename(
...: columns={"Age": "Age2",
...: "Pclass": "Pclas2"})
列名转换为小写:
titanic_renamed = titanic_renamed.rename(columns=str.lower)
进行统计
我们来统计下乘客的平均年龄:
titanic["Age"].mean()
Out[35]: 29.69911764705882
选择中位数:
titanic[["Age", "Fare"]].median()
Out[36]:
Age 28.0000
Fare 14.4542
dtype: float64
更多信息:
titanic[["Age", "Fare"]].describe()
Out[37]:
Age Fare
count 714.000000 891.000000
mean 29.699118 32.204208
std 14.526497 49.693429
min 0.420000 0.000000
25% 20.125000 7.910400
50% 28.000000 14.454200
75% 38.000000 31.000000
max 80.000000 512.329200
使用agg指定特定的聚合方法:
titanic.agg({'Age': ['min', 'max', 'median', 'skew'],'Fare': ['min', 'max', 'median', 'mean']})
Out[38]:
Age Fare
max 80.000000 512.329200
mean NaN 32.204208
median 28.000000 14.454200
min 0.420000 0.000000
skew 0.389108 NaN
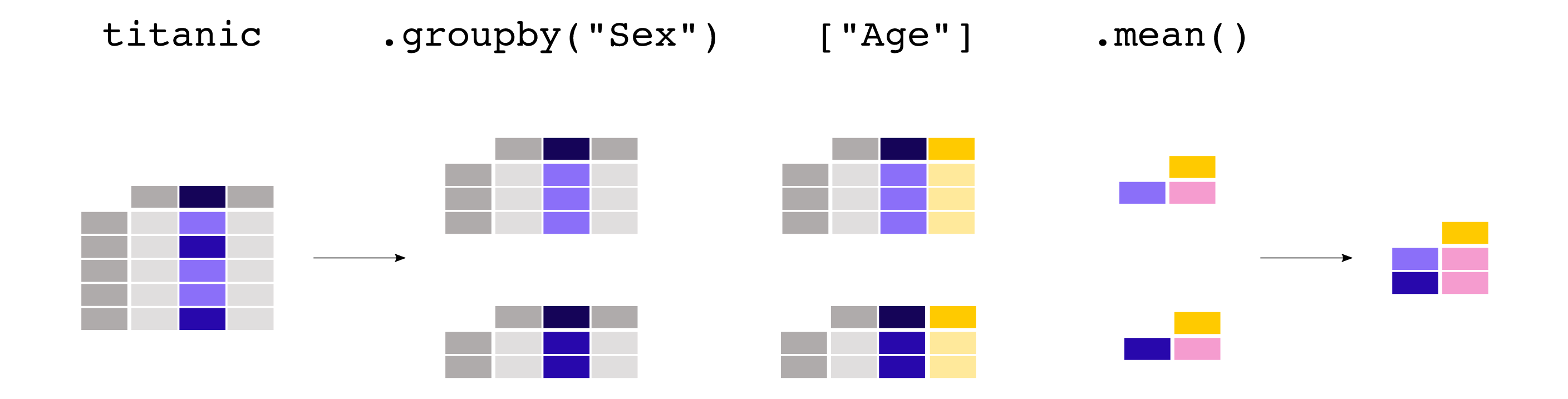
可以使用groupby:
titanic[["Sex", "Age"]].groupby("Sex").mean()
Out[39]:
Age
Sex
female 27.915709
male 30.726645
groupby所有的列:
titanic.groupby("Sex").mean()
Out[40]:
PassengerId Survived Pclass Age SibSp Parch
Sex
female 431.028662 0.742038 2.159236 27.915709 0.694268 0.649682
male 454.147314 0.188908 2.389948 30.726645 0.429809 0.235702
groupby之后还可以选择特定的列:
titanic.groupby("Sex")["Age"].mean()
Out[41]:
Sex
female 27.915709
male 30.726645
Name: Age, dtype: float64
可以分类进行count:
titanic["Pclass"].value_counts()
Out[42]:
3 491
1 216
2 184
Name: Pclass, dtype: int64
上面等同于:
titanic.groupby("Pclass")["Pclass"].count()
DF重组
可以根据某列进行排序:
titanic.sort_values(by="Age").head()
Out[43]:
PassengerId Survived Pclass Name Sex \
803 804 1 3 Thomas, Master. Assad Alexander male
755 756 1 2 Hamalainen, Master. Viljo male
644 645 1 3 Baclini, Miss. Eugenie female
469 470 1 3 Baclini, Miss. Helene Barbara female
78 79 1 2 Caldwell, Master. Alden Gates male
根据多列排序:
titanic.sort_values(by=['Pclass', 'Age'], ascending=False).head()
Out[44]:
PassengerId Survived Pclass Name Sex Age \
851 852 0 3 Svensson, Mr. Johan male 74.0
116 117 0 3 Connors, Mr. Patrick male 70.5
280 281 0 3 Duane, Mr. Frank male 65.0
483 484 1 3 Turkula, Mrs. (Hedwig) female 63.0
326 327 0 3 Nysveen, Mr. Johan Hansen male 61.0
选择特定的行和列数据,下面的例子我们将会选择性别为女性的部分数据:
female=titanic[titanic['Sex']=='female']
female_subset=female[["Age","Pclass","PassengerId","Survived"]].sort_values(["Pclass"]).groupby(["Pclass"]).head(2)
female_subset
Out[58]:
Age Pclass PassengerId Survived
1 38.0 1 2 1
356 22.0 1 357 1
726 30.0 2 727 1
443 28.0 2 444 1
855 18.0 3 856 1
654 18.0 3 655 0
使用pivot可以进行轴的转换:
female_subset.pivot(columns="Pclass", values="Age")
Out[62]:
Pclass 1 2 3
1 38.0 NaN NaN
356 22.0 NaN NaN
443 NaN 28.0 NaN
654 NaN NaN 18.0
726 NaN 30.0 NaN
855 NaN NaN 18.0
female_subset.pivot(columns="Pclass", values="Age").plot()

本文已收录于 http://www.flydean.com/02-python-pandas-advanced/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
Pandas之:Pandas高级教程以铁达尼号真实数据为例的更多相关文章
- Pandas之:Pandas简洁教程
Pandas之:Pandas简洁教程 目录 简介 对象创建 查看数据 选择数据 loc和iloc 布尔索引 处理缺失数据 合并 分组 简介 pandas是建立在Python编程语言之上的一种快速,强大 ...
- 高级教程: 作出动态决策和 Bi-LSTM CRF 重点
动态 VS 静态深度学习工具集 Pytorch 是一个 动态 神经网络工具包. 另一个动态工具包的例子是 Dynet (我之所以提这个是因为使用 Pytorch 和 Dynet 是十分类似的. 如果你 ...
- pandas | 使用pandas进行数据处理——Series篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 上周我们关于Python中科学计算库Numpy的介绍就结束了,今天我们开始介绍一个新的常用的计算工具库,它就是大名鼎鼎的Pandas. Pa ...
- ios cocopods 安装使用及高级教程
CocoaPods简介 每种语言发展到一个阶段,就会出现相应的依赖管理工具,例如Java语言的Maven,nodejs的npm.随着iOS开发者的增多,业界也出现了为iOS程序提供依赖管理的工具,它的 ...
- 【读书笔记】.Net并行编程高级教程(二)-- 任务并行
前面一篇提到例子都是数据并行,但这并不是并行化的唯一形式,在.Net4之前,必须要创建多个线程或者线程池来利用多核技术.现在只需要使用新的Task实例就可以通过更简单的代码解决命令式任务并行问题. 1 ...
- 【读书笔记】.Net并行编程高级教程--Parallel
一直觉得自己对并发了解不够深入,特别是看了<代码整洁之道>觉得自己有必要好好学学并发编程,因为性能也是衡量代码整洁的一大标准.而且在<失控>这本书中也多次提到并发,不管是计算机 ...
- 分享25个新鲜出炉的 Photoshop 高级教程
网络上众多优秀的 Photoshop 实例教程是提高 Photoshop 技能的最佳学习途径.今天,我向大家分享25个新鲜出炉的 Photoshop 高级教程,提高你的设计技巧,制作时尚的图片效果.这 ...
- 展讯NAND Flash高级教程【转】
转自:http://wenku.baidu.com/view/d236e6727fd5360cba1adb9e.html 展讯NAND Flash高级教程
- Net并行编程高级教程--Parallel
Net并行编程高级教程--Parallel 一直觉得自己对并发了解不够深入,特别是看了<代码整洁之道>觉得自己有必要好好学学并发编程,因为性能也是衡量代码整洁的一大标准.而且在<失控 ...
随机推荐
- Erda MSP 系列 - 以服务观测为中心的 APM 系统设计:开篇词
本文首发于 Erda 技术团队知乎账号,更多技术文章可点击 Erda 技术团队 作者:刘浩杨,端点科技 PaaS 技术专家,微服务治理和监控平台负责人,Apache SkyWalking PMC成员 ...
- 13- APP接口测试以及postman使用
postman安装与操作 ---------------------- 接口操作图片 -------------------- 一.postman操作key值:来源于聚合 请求-->聚合-- ...
- Docker 实践搭建php环境
docker 安装 使用官方提供的安装脚本,安装最新版的Docker curl -sSL https://get.docker.com/ | sh 安装完成后,通过如下命令启动Docker的守护进程, ...
- PowerDesigner16安装和使用
安装 安装参考链接:PowerDesigner安装教程 因为这个博主已经操作的很详细了,这边就不做过多的赘述. 使用 新建模型 选择物理模型 调出面板Palette 建表 最终的效果(一般不在数据库层 ...
- 使用docker-compose.yml快速搭建Linux/Mac开发/生产环境
传送门 点击进入Github,https://github.com/ovim/dockerfiles 简单介绍 Dockerfiles 搭建基础公用环境包,方便使用,支持业务不断的提升而需要一些软件的 ...
- 简述MySQL优化
数据库的优化可以从四个方面来优化: 1.结构层: web服务器采用负载均衡服务器,mysql服务器采用主从复制,读写分离 2.储存层: 采用合适的存储引擎,采用三范式 3.设计层: 采用分区分表,索引 ...
- 安装mysql警告: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY
CentOS安装rpm安装MySQL时爆出警告: warning: mysql-community-server-5.7.18-1.el6.x86_64.rpm: Header V3 DSA/SHA1 ...
- 17道APP测试面试题分享带参考答案
一.Android四大组件 Android四大基本组件:Activity.BroadcastReceiver广播接收器.ContentProvider内容提供者.Service服务. Activity ...
- python爬虫——《瓜子网》的广州二手车市场信息
由于多线程爬取数据比单线程的效率要高,尤其对于爬取数据量大的情况,效果更好,所以这次采用多线程进行爬取.具体代码和流程如下: import math import re from concurrent ...
- OPC使用思路