大数据学习(13)—— HBase入门
从这一篇起,开始介绍HBase相关知识。还是一样,大数据的学习,获取官网知识很重要。官网看这里Apache HBase
HBase简介
Apache HBase is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
上面是官网的介绍。从介绍里可以看出,HBase是Apache的顶级项目,可以称为Hadoop的数据库,是一个分布式、可扩展的大数据存储。
HBase跟传统关系型数据库的定位非常不同,它能存储包含十亿级别的行和百万级别的列的表,就算性能强如oracle,在这个规模面前也要歇菜。HBase的理论基础是google的论文Bigtable,这是奠定大数据基础的三篇google论文之一。
泼一盆冷水
准确地讲,HBase更像是一个数据存储,而不是数据库,因为它缺少很多传统关系型数据库的特征。当然,它也不适用于解决所有问题。如果想使用HBase,那么得满足下面几个条件:
- 首先,你要有足够大的数据量。十亿往上走的数据量,比较适合使用HBase。要是只有几百万条记录,那不如用传统关系型数据库,因为这点数据量太小了,只会使用到HBase集群的一个节点,其他节点都是闲置。
- 其次,确保你的代码不需要使用传统关系型数据库提供的任何特性依然可以运行。基于关系型数据库开发的应用不可能仅仅替换一下驱动,就能移植到HBase里,这得重新设计。
- 最后,你还得有足够的服务器。即便是HBase用来存储数据的HDFS,它需要的三副本和NameNode至少要占用5台服务器,更不用说HBase还有自己的组件需要部署了。
虽然HBase在笔记本电脑上也能运行,但那只能作为开发环境,生产环境就不要想了。
HBase架构
不废话,先上图。
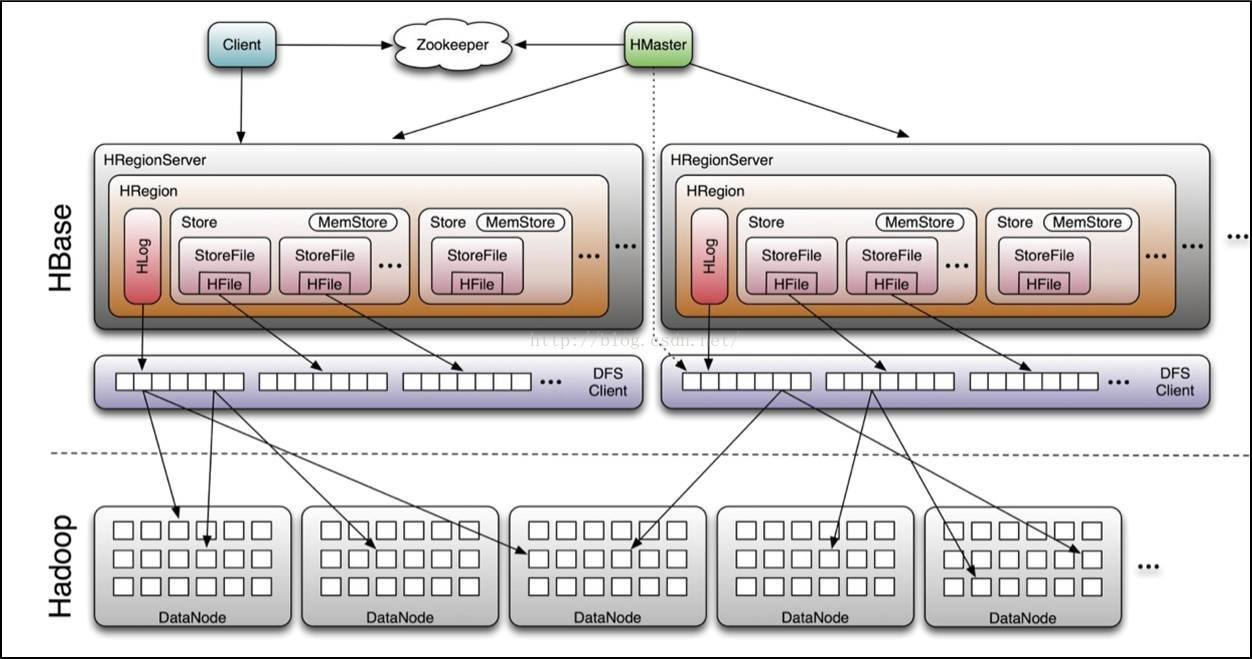
从图片里可以看到虚线以上是HBase的组件和角色,虚线以下是HDFS。再看看官网里关于架构描述的目录Architecture

我把几种主要的角色具体做啥事介绍一下。
Zookeeper
一般来说,zookeeper起到高可用选主的作用,但是在HBase架构里,它还负责存储元数据,官方原话——hbase:meta is stored in ZooKeeper。
Client
HBase客户端首先去查询zookeeper中的元数据信息,找到存储所需数据的Region。这里先要明确一些概念,Region相当于关系型数据库中的表,Store相当于列族(列族是HBase管理的最小单元,包含多个相关的列)。
定位到需要的Region后,Client直接连接到对应的RegionServer而不是通过Master来完成读写请求。这些信息会缓存到客户端,随后的请求就不会再有查找的过程了。但是当RegionServer宕机或者是Master根据负载均衡策略来调整region的时候,客户端需要重新通过元数据来决定访问哪个region。
Master
HMaster是Master Server的实现,真的,你启动Master的时候,用jps查看进程,进程名就是HMaster。Master负责监控集群中所有的ReginServer实例,它为元数据变化提供操作接口。在一个分布式集群中,Master往往运行在NameNode节点上。
RegionServer
HRegionServer是RegionServer的实现,不信你用jps看看。它负责管理和服务regions。在一个分布式集群中,RegionServer运行在DataNode节点上。
Regions
Regions存储表的数据,一张表的数据可以分散在多个region中。每个region包含多个用来存储列族的Store。它的结构树长这样:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)HBase数据模型
HBase的数据存储在表里,它也有行和列。这个说法是参照关系型数据库的结构来讲的,这不是一个合适的类比。但这个说法有助于理解HBase是一个多维表格。
Table
HBase的表包含多条记录。
Row
HBase的一行记录包含行键、列名以及与之相关的值。每行记录按照行键的字典序排序。正因为如此,行键的设计就非常重要。设计行键的时候,要尽量保证相关的记录它们的行键近似,这样查询的时候可以利用范围查询。通常的行键模式,使用网站的域名,域名的几个单词要倒着排,这样的好处是,不同的域名不会排在一起。
Column
HBase中的列包含列族和列名,中间用冒号分割。我用中文举个例子,像这样,个人信息:学历,个人信息:姓名。这个例子里,个人信息是列族,学历、姓名、性别、专业这些相关的字段是列名。
Column Family
列族把一系列的字段和值组合起来,这个做法基于性能原因的考虑。每个列族都有一些存储属性,比方说字段的值要不要放在缓存里、数据如何压缩、行键怎么编码等等。每行记录都包含相同的列族,尽管有些列族里啥也没存。
Column Qualifier
列的修饰符,我们可以称之为列名,它是列族之下的具体索引,用来获取某个特定的值。列名和列族之间用冒号分割。列族是在定义表的时候就确定下来了,但是每条记录的列名可变,甚至非常不同。
cells
它是存储数据的最小单位。在HBase中,唯一确定一个单元格,需要行键+时间戳+列族+列名,它里面存放的是无格式的字节数组,如下图。
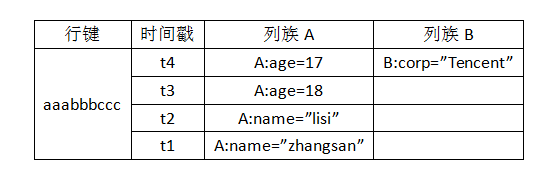
这个时间戳有4个值,以关系型数据库的观点来看,它有4条记录。但在HBase中,它实际上是一条记录,是同一个行键不同版本的值。
Timestamp
在写入一个值的时候,同时会写入一个时间戳,它是区分同一个版本数据的标识。默认情况下,时间戳反映了写数据时RegionServer的时刻,你也可以指定一个不同值的时间戳。
大数据学习(13)—— HBase入门的更多相关文章
- 大数据学习笔记——HBase使用bulkload导入数据
HBase使用bulkload批量导入数据 HBase可使用put命令向一张已经建好了的表中插入数据,然而,当遇到数据量非常大的情况,一条一条的进行插入效率将会大大降低,因此本篇博客将会整理提高批量导 ...
- 《OD大数据实战》HBase入门实战
官方参考文档:http://abloz.com/hbase/book.html#shell_tricks 1.2.3. Shell 练习 用shell连接你的HBase $ ./bin/hbase s ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- 大数据学习(16)—— HBase环境搭建和基本操作
部署规划 HBase全称叫Hadoop Database,它的数据存储在HDFS上.我们的实验环境依然基于上个主题Hive的配置,参考大数据学习(11)-- Hive元数据服务模式搭建. 在此基础上, ...
- 大数据学习系列之五 ----- Hive整合HBase图文详解
引言 在上一篇 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机) 和之前的大数据学习系列之二 ----- HBase环境搭建(单机) 中成功搭建了Hive和HBase的环 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习系列之—HBASE
hadoop生态系统 zookeeper负责协调 hbase必须依赖zookeeper flume 日志工具 sqoop 负责 hdfs dbms 数据转换 数据到关系型数据库转换 大数据学习群119 ...
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
随机推荐
- 如何编写shell脚本
1.首先创建一个目录 vi hello.sh 2.编写shell第一行 #!/bin/bash (为了声明是shell脚本,第一行都要这么写) 3.可以添加注释 #the first p ...
- 使用Spring Data JPA 访问 Mysql 数据库-配置项
jpa操作数据库 注意:数据库采用的是本机数据库,下面是建表语句及初始化数据: SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------- ...
- Unity 异步加载 进度条
当我们进行游戏开发时,时常会进行场景切换,如果下个场景较大,切换时就会出现卡顿现象,甚至看起来像是"死机",非常影响用户体验,我们这时就可以运用异步加载,在界面上显示加载的进度条以 ...
- 第5章:资源编排(YAML)
5.1 编写YAML注意事项 YAML 是一种简洁的非标记语言. 语法格式: 缩进表示层级关系 不支持制表符"tab"缩进,使用空格缩进 通常开头缩进 2 个空格 字符后缩进 1 ...
- AcWing 1275. 最大数
#include<bits/stdc++.h> #define N 1000100 using namespace std; struct node { int l,r; int data ...
- MySql:MySql忘记密码怎么修改?
1. 关闭正在运行的MySQL服务2. 打开DOS窗口,转到mysql\bin目录3. 输入mysqld --skip-grant-tables 回车 --skip-grant-table ...
- linux学习之路第六天(文件目录类第二部分)
文件目录类 1.cat指令 作用:查看文件内容,是以只读的方式打开. 基本语法 cat [选项] 要查看的文件 常用选项 -n; 使用细节: cat只能浏览文件,而不能修改文件,通常会和more一起使 ...
- vim程序编辑器---常用操作整理
vim程序编辑器---常用操作整理 移动光标方法 o 在光标行的下一行,进入编辑模式 $ 移动到光标这行,最末尾的地方 G(大写) 移动到文件最末行 :set nu 文件显示行数 :set non ...
- Socket 编程介绍
Socket 编程发展 Linux Socket 编程领域,为了处理大量连接请求场景,需要使用非阻塞 I/O 和复用.select.poll 和 epoll 是 Linux API 提供的 I/O 复 ...
- Mysql学生课程表SQL面试集合
现有如下2个表,根据要求写出SQL语句. student表:编号(sid),姓名(sname),性别(sex) course表:编号(sid),科目(subject),成绩(score) 问题1:查 ...