Flink Sql 之 Calcite Volcano优化器(源码解析)
Calcite作为大数据领域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型项目的sql解析
同时想要深入研究Flink sql源码的话calcite也是必备技能之一,非常值得学习
我们内部也通过它在做自研的sql引擎,通过一套sql支持关联查询任意多个异构数据源(eg : mysql表join上 hbase表在做一个聚合计算)
因为calcite功能比较多,本文主要还是从calcite重要的主流程源码入手,主要侧重在VolcanoPlanner的优化器上
梳理一下Calcite SQL执行的几个阶段

总结下来就是
1. 通过Parser解析器将传入的sql解析成一颗词法树,SqlNode作为树的节点
2. 做词法的校验Validate,类型校验,元数据校验等等
3. 将校验好的SqlNode树转换成对应的关系代数表达式,也是一颗树,RelNode作为节点
4. 将RelNode关系代数表达式树,通过内置的两种优化器Volcano , Hep 优化关系代数表达式得到最优逻辑代数的一颗树,也是RelNode
5. 最优的逻辑代数表达式(RelNode),会被转换成对应的可执行的物理执行计划(转换逻辑根据框架有所不同),像Flink就转成他的Operator去运行
来详细的看下每个阶段
1. Sql语句解析成语法树阶段(SQL - > SqlNode)
这一个阶段其实不是calcite实现的,而是calcite自己定义了一套sql语法分析规则模板,通过javaCC这个框架去实现的
拉代码来看下
源码中那个Parser.jj就是calcite核心的语法模板了,比如说我们要为flink sql添加什么语法比如count window就要修改这里
其中定义了是什么sql token 如何返回sqlNode的具体逻辑
看个例子
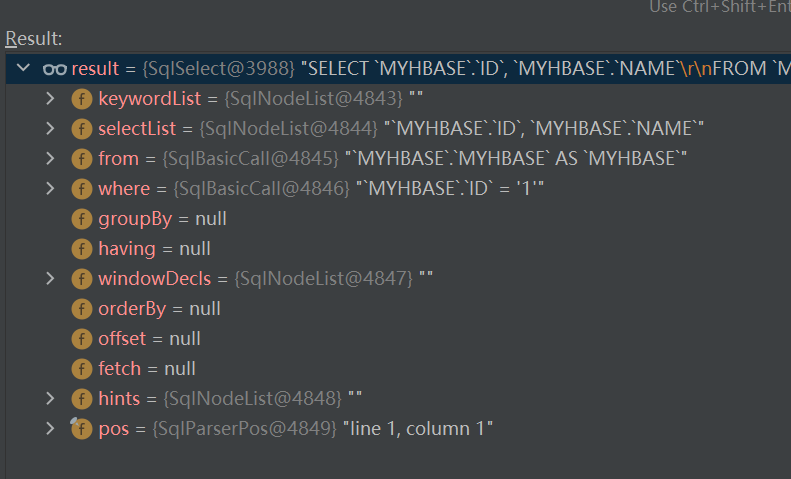
"select ID,NAME from MYHBASE.MYHBASE where ID = '1' "
就会被解析成这样一颗sqlNode树
这里就不赘述了,javacc 可以参考官网(https://javacc.github.io/javacc/)
2 . 语法校验validator阶段
这里通过校验器去校验,这里不展开了,不是重点
3. 将sqlNode转成relNode的逻辑表达式树(sqlNode - > relNode)
这里calcite有默认的sql2rel转换器org.apache.calcite.sql2rel.SqlToRelConverter
这里也先不展开了
4. 逻辑关系代数树优化(relNode - > relNode)
这里是中重点中的重点!!!为什么有那么多框架选择Calcite就是因为它的sql优化
通过3阶段我们得到了一个relNode树,但这里这颗树并不是最优解,而calcite通过自身的两种优化器planner得到一个优化后的best树
这里才是整个calcite的核心,calcite提供的两种优化器
HepPlanner规则优化器(简单理解为定义许多规则Rule,只要能符合优化规则的树节点的就按规则转换,得到一颗规则优化后的树,这个比较简单)
VolcanPanner代价优化器(基于代价cost,树会根据rule一直迭代,不停计算更新root relnode节点的代价值,来找到最优的树)
先来看下
select ID,NAME from a where ID = '1'
这样sql转换而来的一颗RelNode树长什么样子
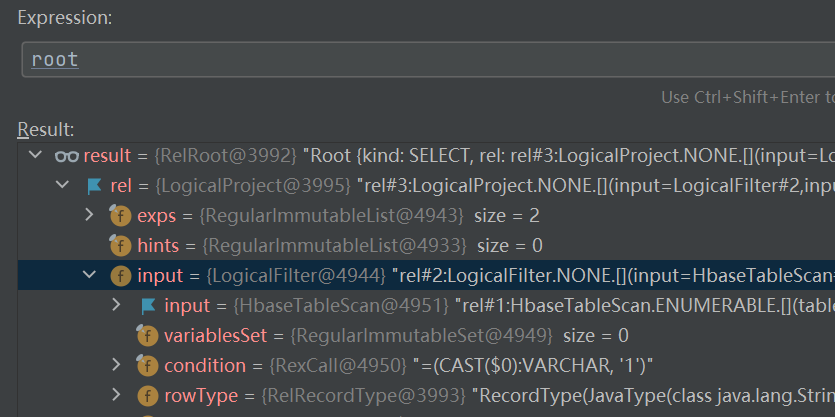
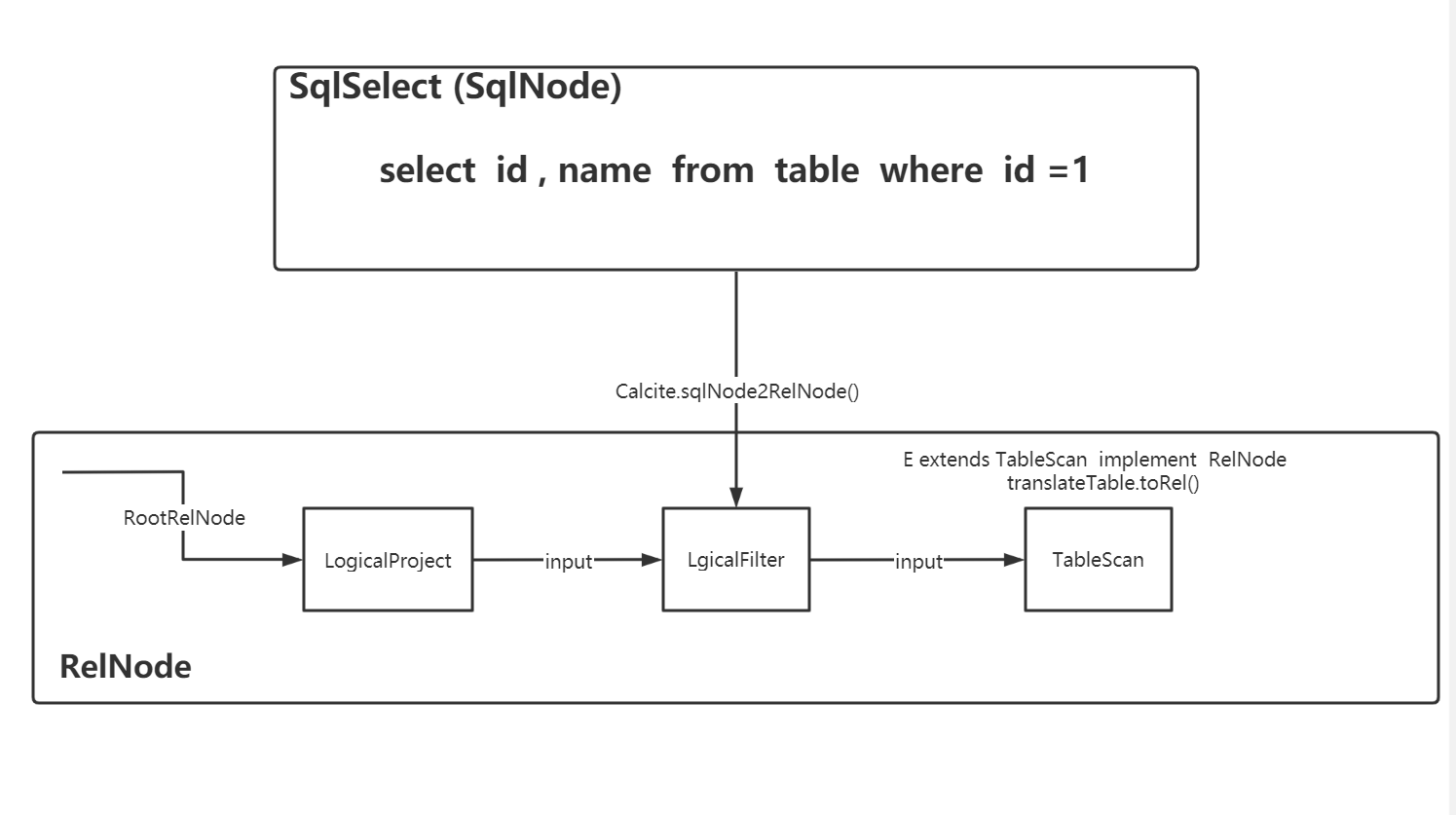
可以看到很多节点都是以Logical命名的,因为这是3阶段通过calcite默认的转化器(SqlToRelConverter)转换而来的逻辑节点,逻辑节点是没有物理属性的也无法运行的
接下来进入calcite的代价cost优化器VolcanoPlanner进行优化

返回的就是代价最优的解
进去calcite的optimize方法
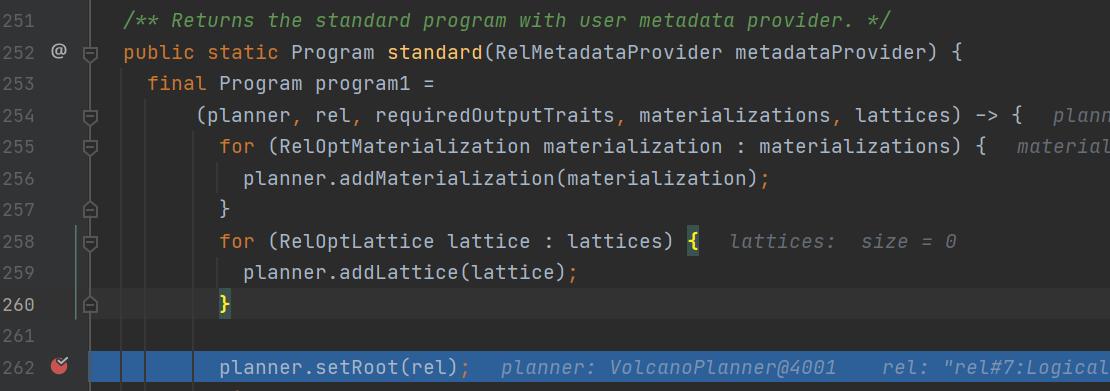
首先calcite会将我们上一阶段得到的relNode设置到我们代价Volcano优化器的root里去
在其中 org.apache.calcite.plan.volcano.VolcanoPlanner.registerImpl() 方法中
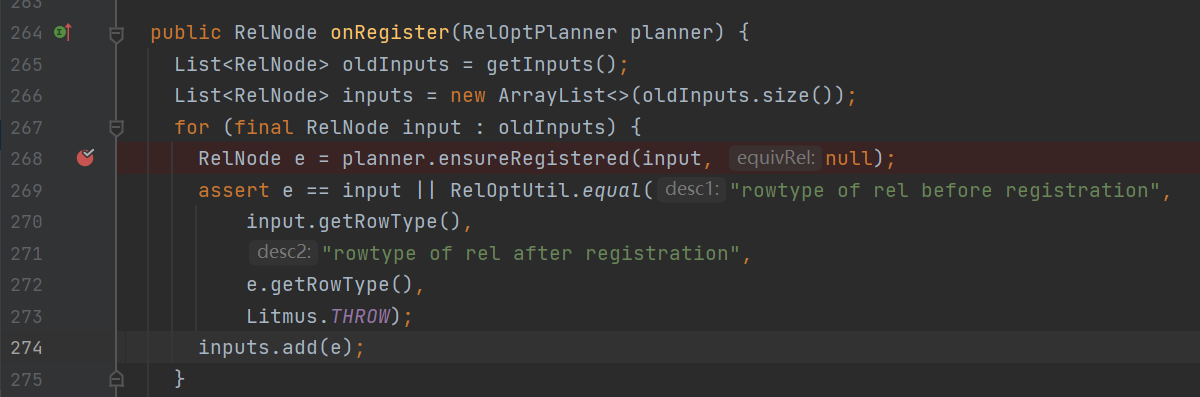
断点的地方在register的过程中会先将relnode的input先注册
在ensureRestered方法中
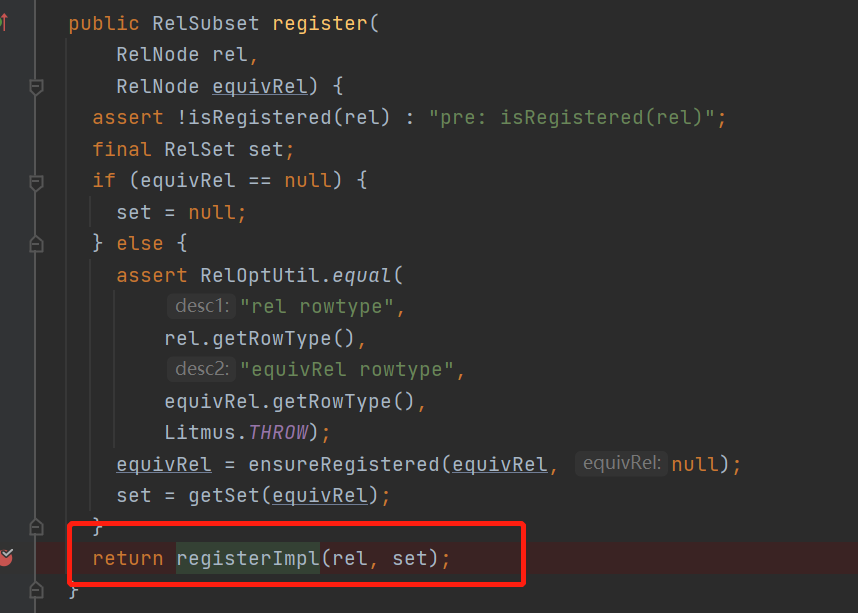
可以看到有绕回了registerImpl()方法
也就是树的子节点深度遍历先注册
接下来看一下注册过程
既然是深度遍历回到刚才看的VolcanoPlanner.registerImpl()方法中看下onRegister()方法之后做了什么

可以看到要触发规则了,这里就要穿插一个概念,calcite中的Rule

从类描述中我们可以知道,规则可以将一个表达式转换成另一个,什么意思呢,来看下有哪些抽象方法
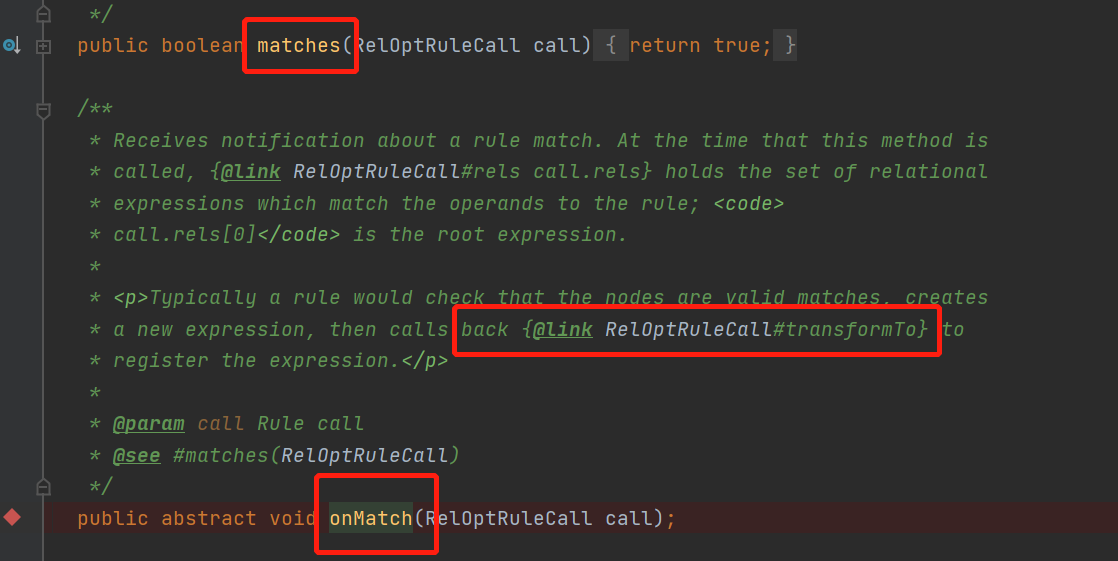
什么意思呢?归纳起来就是两个核心方法
matches()返回当前的relnode是否能匹配上此规则rule
onMatch () 当匹配上此规则时,这个方法会被调用,在其中可以调用transformTo()方法,这个方法的作用就是将一个relNode转换成另一个relNode
规则就是整个calcite的核心了,其实所有的sql优化都是由对应的rule组成的,将sql的优化逻辑实现为对应的rule让对应的relNode树节点做对应的转换来得到最优的best执行计划
ok回到我们的主流程上,继续上面的volcanoPlanner.fireRule()方法看看如何触发规则的
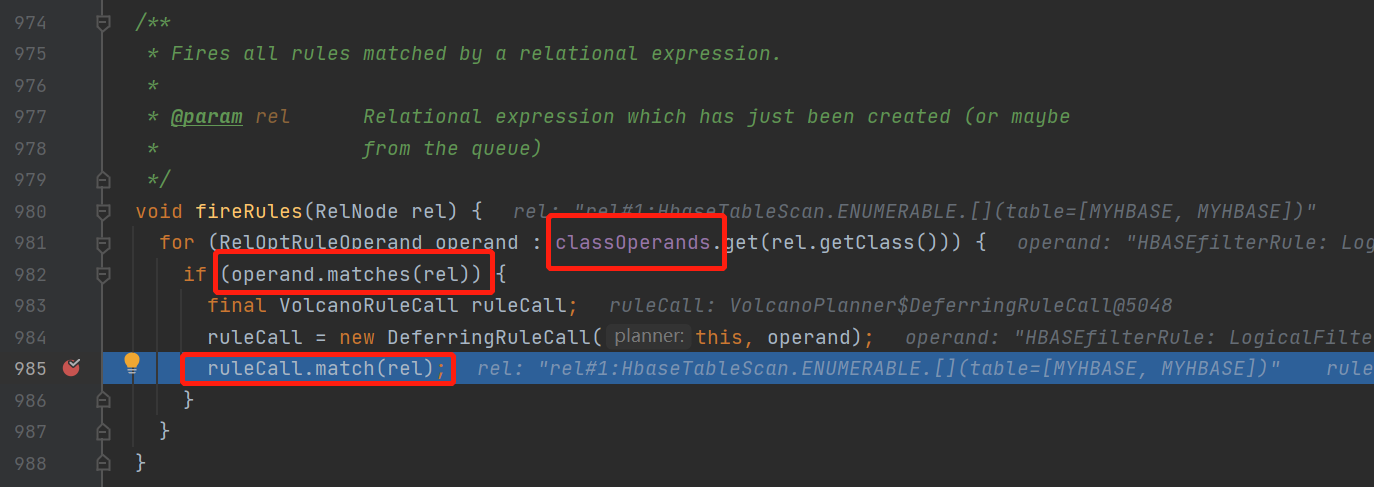
这里逻辑是比较简单的,就是当relnode满足rule就调用volcanoRuleCall的match()方法
但是有个地方需要注意,这里的classOperands这里包含了relNode以及所有可能匹配上这个relnode的规则的映射关系,并且可以向上也可以向下
具体是什么意思呢?
假设我有一个LogicFilter的RelNode,然后定义了两个规则
RuleA
operand(Logicalfilter.class, operand(TableScan.class))
RuleB
operand(Logicalproject.class, operand(Logicalfilter.class))
那这两个rule都会进入这个可能匹配上的映射关系classOperands里面去
当匹配上rule以后,接着来继续看代码
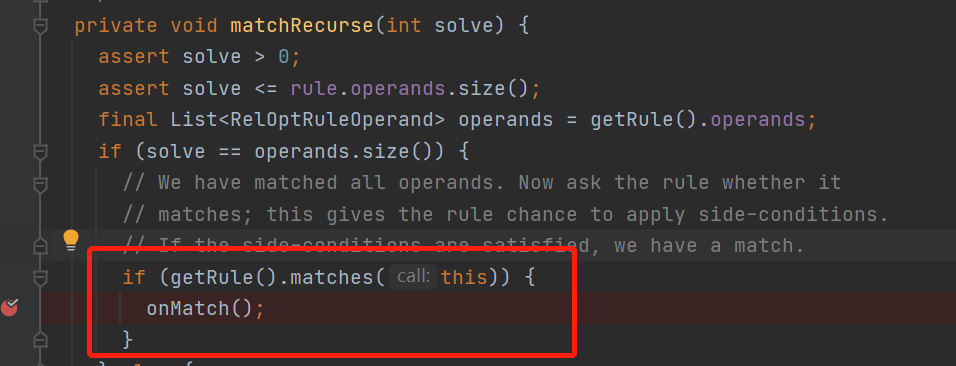
然后走到了volcanoPlanner.DeferringRuleCall的onMatch中
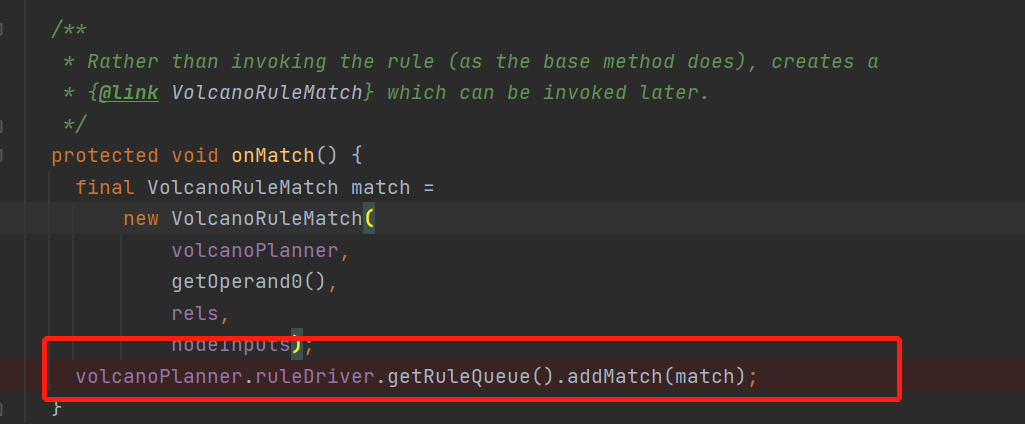
这里就是把这个rule的加入到了IterativeRuleDriver中的ruleQueue,这个队列就是专门用来存放已经匹配上的rule的,不难发现这些匹配上的rule只是存在队列里面,但还没有执行这些规则
那多久会执行呢?
回到主流程当我们setRoot里的所有relnode子节点都register以后
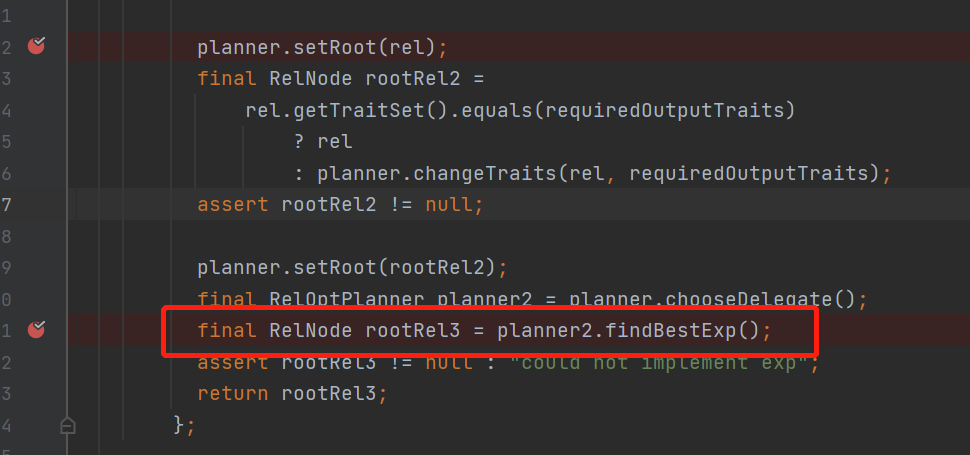
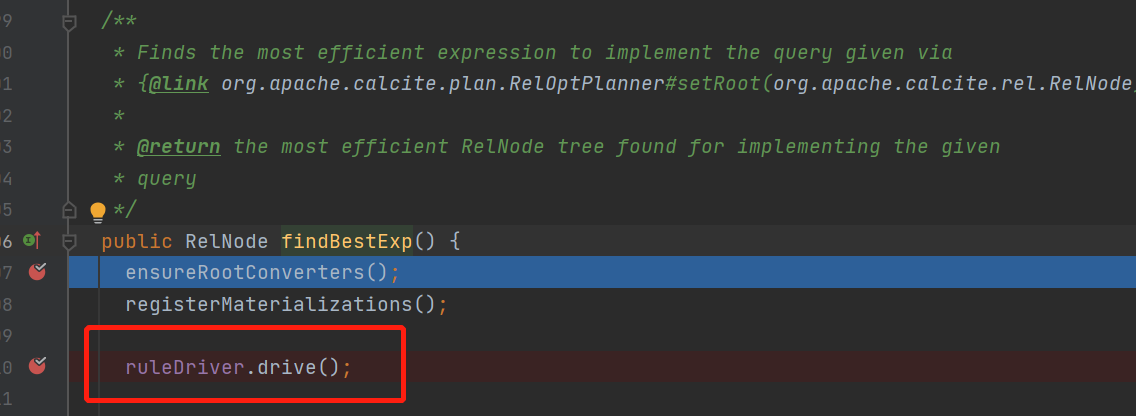
会走具体planner的findBestExp()方法,从名字可以看出来找到最优的表达式
这里要提前说一下,claicte的优化原理是,它假定如果一个表达式最优,那它的局部也是最优的,那当前relNode的best我们也就只用关心,从
1.子节点的所有best加起来
2. 自己能匹配上的所有规则,以及剩下部位的best加起来
从中比较得到的就是当前relnode的最优解了
引用个图
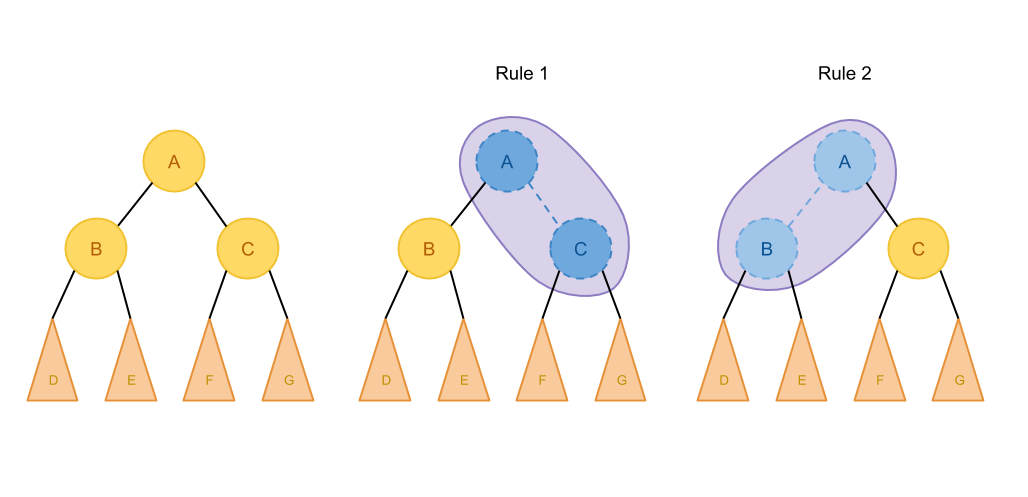
如果A只能匹配这两种规则,那我们枚举求最优解的时候就只用考虑这几张情况
关于原理不太了解的可以看看这篇 https://io-meter.com/2018/11/01/sql-query-optimization-volcano/
接着看findBestexp()
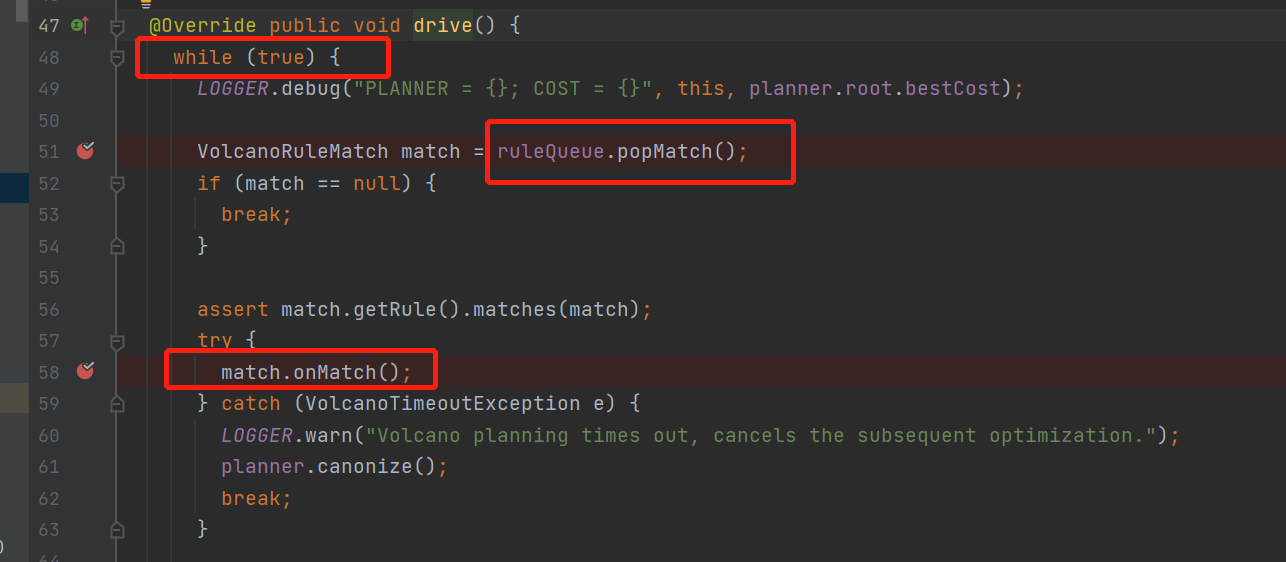
这里就是整个优化寻找最优解bestExp的主loop了
不停的从queue中拿rule, 运行rule,直到所有rule都执行完才退出
没错这里的这个queue就是前面说到的,当默认的relnode注册进来的时候会把能匹配上的rule放这queue里面去
这里自然就有个疑问, 前面说到rule运行的时候会改变relNode节点,也就是添加relndoe的等价节点,
那这里树的结构变化会导致,之前不能匹配上的rule改变树的结构后就能匹配上,那这里能匹配上的rule不就漏了,那就接着看rule的onMatch()中用于转换等价节点的方法transformTo()

其中转换的新节点,在transformTo方法中又会执行register

也就是说新来的节点也会走一遍,默认relNode注册的流程,当新节点注册成等价节点会有新的规则匹配上的时候,又会将此rule加入rulequeu中等待下一次执行rule了
另外当这个relnode节点会被规则rule转换时,生成的新relnode会被设置加入到这个relnode的等价节点中去
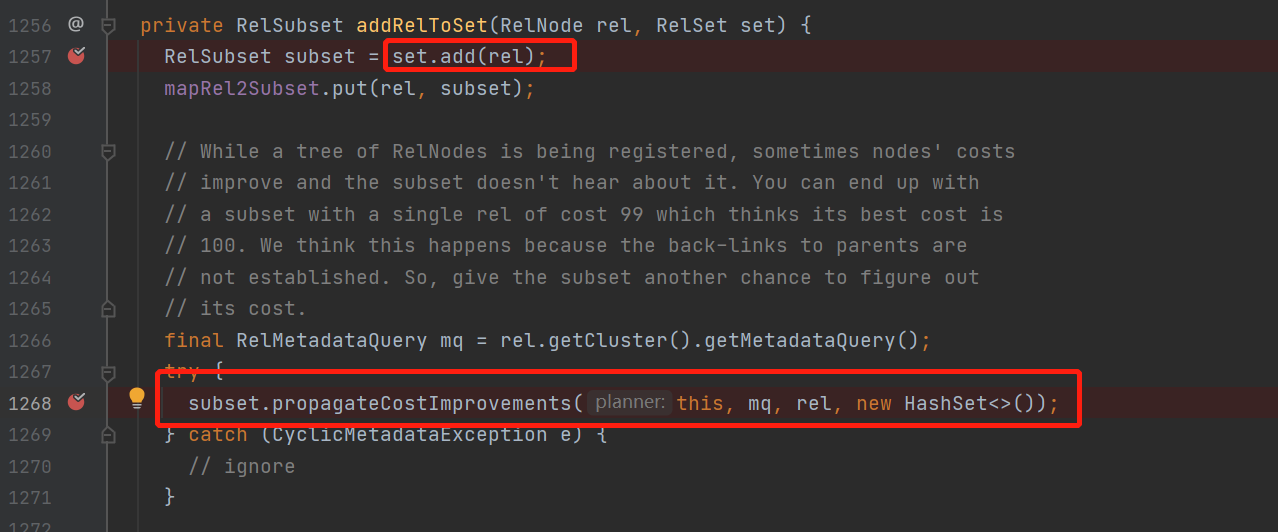
加入等价节点,并且在propagateCostImprovement方法中
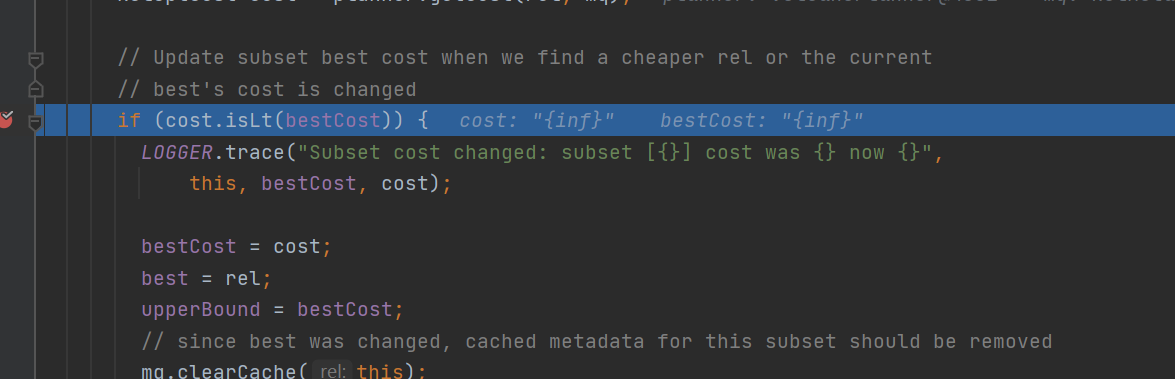
计算当前等价节点会不会使,当前relnode的cost代价下降,如果下降了,那就更新当前relnode的bestcost并且向上冒泡修改父relnode的最优bestCost
while true 一直触发拉取ruleQueue中的rule,直到rule为空
然后rule会添加新的等价节点
新的等价节点如果更优cost,更新整棵树的best Relnode
新的等价节点relnode会匹配上新的规则,新的rule加入到rulequeue中
进入下一次循环,直到没有rule可以匹配上,这样bestexp就可以返回优化后的最优的relnode了
之后就是根据这个最优的relnode,不同的框架翻译成自己的api
calciet终于说完,,之后就可以开始解析flink sql的源码了
Flink Sql 之 Calcite Volcano优化器(源码解析)的更多相关文章
- Flink sql 之 join 与 StreamPhysicalJoinRule (源码解析)
源码分析基于flink1.14 Join是flink中最常用的操作之一,但是如果滥用的话会有很多的性能问题,了解一下Flink源码的实现原理是非常有必要的 本文的join主要是指flink sql的R ...
- MYSQL 优化器 源码解析
http://www.unofficialmysqlguide.com/introduction.html https://dev.mysql.com/doc/refman/8.0/en/explai ...
- Java生鲜电商平台-SpringCloud微服务架构中网络请求性能优化与源码解析
Java生鲜电商平台-SpringCloud微服务架构中网络请求性能优化与源码解析 说明:Java生鲜电商平台中,由于服务进行了拆分,很多的业务服务导致了请求的网络延迟与性能消耗,对应的这些问题,我们 ...
- springMVC 拦截器源码解析
前言:这两天学习了代理模式,自然想到了 springmvc 的 aop 使用的就是动态代理,拦截器使用的就是 jdk 的动态代理.今天看了看源码,记录一下.转载请注明出处:https://www.cn ...
- RestFramework之序列化器源码解析
一.源码解析之序列化: 1.当视图类进行实例化序列化类做了如下操作: #ModelSerializer继承Serializer再继承BaseSerializer(此类定义实例化方法) #在BaseSe ...
- Flink sql 之 微批处理与MiniBatchIntervalInferRule (源码分析)
本文源码基于flink1.14 平台用户在使用我们的flinkSql时经常会开启minaBatch来优化状态读写 所以从源码的角度具体解读一下miniBatch的原理 先看一下flinksql是如何触 ...
- DRF之解析器源码解析
解析器 RESTful一种API的命名风格,主要因为前后端分离开发出现前后端分离: 用户访问静态文件的服务器,数据全部由ajax请求给到 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己 ...
- Struts2 源码分析-----拦截器源码解析 --- ParametersInterceptor
ParametersInterceptor拦截器其主要功能是把ActionContext中的请求参数设置到ValueStack中,如果栈顶是当前Action则把请求参数设置到了Action中,如果栈顶 ...
- [源码解析] PyTorch 分布式(14) --使用 Distributed Autograd 和 Distributed Optimizer
[源码解析] PyTorch 分布式(14) --使用 Distributed Autograd 和 Distributed Optimizer 目录 [源码解析] PyTorch 分布式(14) - ...
随机推荐
- Python3-sqlalchemy-orm 创建关联表带外键并插入数据
#-*-coding:utf-8-*- #__author__ = "logan.xu" import sqlalchemy from sqlalchemy import crea ...
- JavaScript高级程序设计学习笔记之事件
1.事件流 事件流描述的是从页面中接收事件的顺序. 事件冒泡 IE的事件流叫做事件冒泡(event bubbling),即事件开始时由最具体的元素(文档中嵌套层次最深的那个节点)接收,然后逐级向上传播 ...
- golang 模板 html/template与text/template
html模板生成: html/template包实现了数据驱动的模板,用于生成可对抗代码注入的安全HTML输出.它提供了和text/template包相同的接口,Go语言中输出HTML的场景都应使用t ...
- JS 根据id实现局部打印
// 打印初审收费清单 getOrderCostBille(){ var head_str = "<html><head><title> ...
- [考试总结]noip模拟40
最近真的是爆炸啊... 到现在还是有不少没改出来.... 所以先写一下 \(T1\) 的题解.... 送花 我们移动右端点,之后我们用线段树维护全局最大值. 之后还要记录上次的位置和上上次的位置. 之 ...
- QT之ARM平台的移植
在开发板中运行QT程序的基本条件是具备QT环境,那么QT的移植尤为重要,接下载我将和小伙伴们一起学习QT的移植. 一.准备材料 tslib源码 qt-everywhere-src-5.12.9.t ...
- MongoDB(6)- BSON 数据类型
BSON BSON是一种二进制序列化格式,用于在 MongoDB 中存储文档和进行远程过程调用 跟 JSON 的数据结构很像,但是支持更丰富的数据类型 数据类型 数据类型 序号 别名 备注 Doubl ...
- Identity角色管理一(准备工作)
因角色管理需要有用户才能进行(需要将用户从角色中添加,删除)故角色管理代码依托用户管理 只需在Startup服务中添加角色管理即可完成 public void ConfigureServices(IS ...
- .Net 如何修改 HttpHeaders 中的 Content-Disposition
最近在看一些.Net5的内容,于是就想将之前Spring写的一个项目迁移到.Net上来看看. 不得不说.Net这几年发展的确实挺好的,超快的启动速度,极佳的性能让它一点不比Java差,但确实在国内生态 ...
- Python - 虚拟环境 venv
什么是虚拟环境 这是 Python 3.3 的新特性:https://www.python.org/dev/peps/pep-0405/ 假设自己电脑主机的 Python 环境称为系统环境,而默认情况 ...