从网络通信的演进过程彻底搞懂Redis高性能通信的原理(全网最详细,建议收藏)
我们一直说Redis的性能很快,那为什么快?Redis为了达到性能最大化,做了哪些方面的优化呢?
在深度解析Redis的数据结构
这篇文章中,其实从数据结构上分析了Redis性能高的一方面原因。
在目前的k-v数据库的技术选型中,Redis几乎是首选的用来实现高性能缓存的方案,它的性能有多快呢?
根据官方的基准测试数据,一台普通硬件配置的Linux机器上运行单个Redis实例,处理简单命令(O(n)或者O(logn)),QPS可以达到8W,如果使用pipeline批处理功能,QPS最高可以达到10W。
Redis 为什么那么快
Redis的高性能主要依赖于几个方面。
- C语言实现,C语言在一定程度上还是比Java语言性能要高一些,因为C语言不需要经过JVM进行翻译。
- 纯内存I/O,内存I/O比磁盘I/O性能更快
- I/O多路复用,基于epoll的I/O多路复用技术,实现高吞吐网络I/O
- 单线程模型,单线程无法利用到多核CPU,但是在Redis中,性能瓶颈并不是在计算上,而是在I/O能力,所以单线程能够满足高并发的要求。 从另一个层面来说,单线程可以避免多线程的频繁上下文切换以及同步锁机制带来的性能开销。
下面我们分别从上述几个方面进行展开说明,先来看网络I/O的多路复用模型。
从请求处理开始分析
当我们在客户端向Redis Server发送一条指令,并且得到Redis回复的整个过程中,Redis做了什么呢?
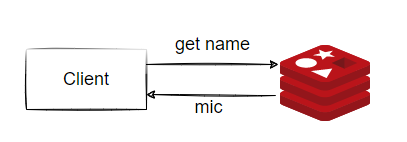
图4-1
要处理命令,则redis必须完整地接收客户端的请求,并将命令解析出来,再将结果读出来,通过网络回写到客户端。整个工序分为以下几个部分:
- 接收,通过TCP接收到命令,可能会历经多次TCP包、ack、IO操作
- 解析,将命令取出来
- 执行,到对应的地方将value读出来
- 返回,将value通过TCP返回给客户端,如果value较大,则IO负荷会更重
其中解析和执行是纯cpu/内存操作,而接收和返回主要是IO操作,首先我们先来看通信的过程。
网络IO的通信原理
同样,我也画了一幅图来描述网络数据的传输流程
首先,对于TCP通信来说,每个TCP Socket的内核中都有一个发送缓冲区和一个接收缓冲区
接收缓冲区把数据缓存到内核,若应用进程一直没有调用Socket的read方法进行读取,那么该数据会一直被缓存在接收缓冲区内。不管进程是否读取Socket,对端发来的数据都会经过内核接收并缓存到Socket的内核接收缓冲区。
read所要做的工作,就是把内核接收缓冲区中的数据复制到应用层用户的Buffer里。
进程调用Socket的send发送数据的时候,一般情况下是将数据从应用层用户的Buffer里复制到Socket的内核发送缓冲区,然后send就会在上层返回。换句话说,send返回时,数据不一定会被发送到对端。
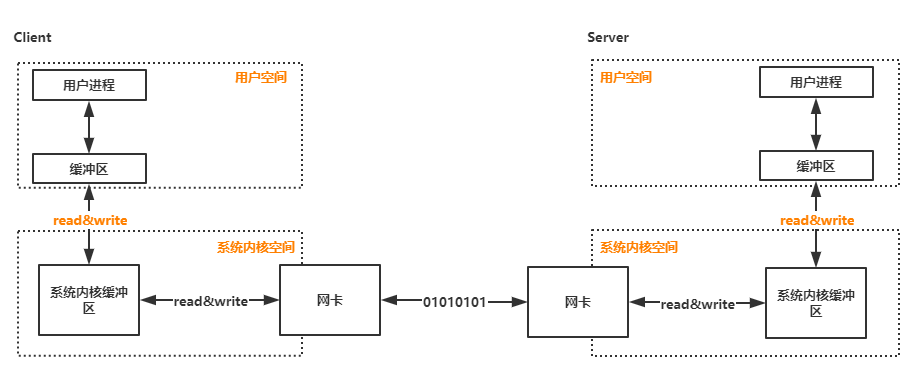
网卡中的缓冲区既不属于内核空间,也不属于用户空间。它属于硬件缓冲,允许网卡与操作系统之间有个缓冲;
内核缓冲区在内核空间,在内存中,用于内核程序,做为读自或写往硬件的数据缓冲区;
用户缓冲区在用户空间,在内存中,用于用户程序,做为读自或写往硬件的数据缓冲区
网卡芯片收到网络数据会以中断的方式通知CPU,我有数据了,存在我的硬件缓冲里了,来读我啊。
CPU收到这个中断信号后,会调用相应的驱动接口函数从网卡的硬件缓冲里把数据读到内核缓冲区,正常情况下会向上传递给TCP/IP模块一层一层的处理。
NIO多路复用机制
Redis的通信采用的是多路复用机制,什么是多路复用机制呢?
由于Redis是C语言实现,为了简化大家的理解,我们采用Java语言来描述这个过程。
在理解多路复用之前,我们先来了解一下BIO。
BIO模型
在Java中,如果要实现网络通信,我们会采用Socket套接字来完成。
Socket这不是一个协议,而是一个通信模型。其实它最初是BSD发明的,主要用来一台电脑的两个进程间通信,然后把它用到了两台电脑的进程间通信。所以,可以把它简单理解为进程间通信,不是什么高级的东西。主要做的事情不就是:
A发包:发请求包给某个已经绑定的端口(所以我们经常会访问这样的地址182.13.15.16:1235,1235就是端口);收到B的允许;然后正式发送;发送完了,告诉B要断开链接;收到断开允许,马上断开,然后发送已经断开信息给B。
B收包:绑定端口和IP;然后在这个端口监听;接收到A的请求,发允许给A,并做好接收准备,主要就是清理缓存等待接收新数据;然后正式接收;接受到断开请求,允许断开;确认断开后,继续监听其它请求。
可见,Socket其实就是I/O操作,Socket并不仅限于网络通信,在网络通信中,它涵盖了网络层、传输层、会话层、表示层、应用层——其实这都不需要记,因为Socket通信时候用到了IP和端口,仅这两个就表明了它用到了网络层和传输层;而且它无视多台电脑通信的系统差别,所以它涉及了表示层;一般Socket都是基于一个应用程序的,所以会涉及到会话层和应用层。
构建基础的BIO通信模型
BIOServerSocket
public class BIOServerSocket {
//先定义一个端口号,这个端口的值是可以自己调整的。
static final int DEFAULT_PORT=8080;
public static void main(String[] args) throws IOException {
//先定义一个端口号,这个端口的值是可以自己调整的。
//在服务器端,我们需要使用ServerSocket,所以我们先声明一个ServerSocket变量
ServerSocket serverSocket=null;
//接下来,我们需要绑定监听端口, 那我们怎么做呢?只需要创建使用serverSocket实例
//ServerSocket有很多构造重载,在这里,我们把前边定义的端口传入,表示当前
//ServerSocket监听的端口是8080
serverSocket=new ServerSocket(DEFAULT_PORT);
System.out.println("启动服务,监听端口:"+DEFAULT_PORT);
//回顾一下前面我们讲的内容,接下来我们就需要开始等待客户端的连接了。
//所以我们要使用的是accept这个函数,并且当accept方法获得一个客户端请求时,会返回
//一个socket对象, 这个socket对象让服务器可以用来和客户端通信的一个端点。
//开始等待客户端连接,如果没有客户端连接,就会一直阻塞在这个位置
Socket socket=serverSocket.accept();
//很可能有多个客户端来发起连接,为了区分客户端,咱们可以输出客户端的端口号
System.out.println("客户端:"+socket.getPort()+"已连接");
//一旦有客户端连接过来,我们就可以用到IO来获得客户端传过来的数据。
//使用InputStream来获得客户端的输入数据
//bufferedReader大家还记得吧,他维护了一个缓冲区可以减少数据源读取的频率
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(socket.getInputStream()));
String clientStr=bufferedReader.readLine(); //读取一行信息
System.out.println("客户端发了一段消息:"+clientStr);
//服务端收到数据以后,可以给到客户端一个回复。这里咱们用到BufferedWriter
BufferedWriter bufferedWriter=new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("我已经收到你的消息了\n");
bufferedWriter.flush(); //清空缓冲区触发消息发送
}
}
BIOClientSocket
public class BIOClientSocket {
static final int DEFAULT_PORT=8080;
public static void main(String[] args) throws IOException {
//在客户端这边,咱们使用socket来连接到指定的ip和端口
Socket socket=new Socket("localhost",8080);
//使用BufferedWriter,像服务器端写入一个消息
BufferedWriter bufferedWriter=new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("我是客户端Client-01\n");
bufferedWriter.flush();
BufferedReader bufferedReader=new BufferedReader(new InputStreamReader(socket.getInputStream()));
String serverStr=bufferedReader.readLine(); //通过bufferedReader读取服务端返回的消息
System.out.println("服务端返回的消息:"+serverStr);
}
}
上述代码构建了一个简单的BIO通信模型,也就是服务端建立一个监听,客户端向服务端发送一个消息,实现简单的网络通信,那BIO有什么弊端呢?
我们通过对BIOServerSocket进行改造,关注case1和case2部分。
- case1: 增加了while循环,实现重复监听
- case2: 当服务端收到客户端的请求后,不直接返回,而是等待20s。
public class BIOServerSocket {
//先定义一个端口号,这个端口的值是可以自己调整的。
static final int DEFAULT_PORT=8080;
public static void main(String[] args) throws IOException, InterruptedException {
ServerSocket serverSocket=null;
serverSocket=new ServerSocket(DEFAULT_PORT);
System.out.println("启动服务,监听端口:"+DEFAULT_PORT);
while(true) { //case1: 增加循环,允许循环接收请求
Socket socket = serverSocket.accept();
System.out.println("客户端:" + socket.getPort() + "已连接");
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String clientStr = bufferedReader.readLine(); //读取一行信息
System.out.println("客户端发了一段消息:" + clientStr);
Thread.sleep(20000); //case2: 修改:增加等待时间
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("我已经收到你的消息了\n");
bufferedWriter.flush(); //清空缓冲区触发消息发送
}
}
}
接着,把BIOClientSocket复制两份(client1、client2),同时向BIOServerSocket发起请求。
运行后看到的现象应该是: client1先发送请求到Server端,由于Server端等待20s才返回,导致client2的请求一直被阻塞。
这个情况会导致一个问题,如果服务端在同一个时刻只能处理一个客户端的连接,而如果一个网站同时有1000个用户访问,那么剩下的999个用户都需要等待,而这个等待的耗时取决于前面的请求的处理时长,如图4-2所示。
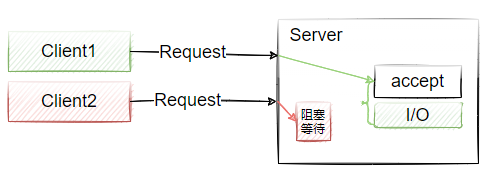
图4-2
基于多线程优化BIO
为了让服务端能够同时处理更多的客户端连接,避免因为某个客户端连接阻塞导致后续请求被阻塞,于是引入多线程技术,代码如下。
ServerSocket
public static void main(String[] args) throws IOException, InterruptedException {
final int DEFAULT_PORT=8080;
ServerSocket serverSocket=null;
serverSocket=new ServerSocket(DEFAULT_PORT);
System.out.println("启动服务,监听端口:"+DEFAULT_PORT);
ExecutorService executorService= Executors.newFixedThreadPool(5);
while(true) {
Socket socket = serverSocket.accept();
executorService.submit(new SocketThread(socket));
}
}
SocketThread
public class SocketThread implements Runnable{
Socket socket;
public SocketThread(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
System.out.println("客户端:" + socket.getPort() + "已连接");
try {
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String clientStr = null; //读取一行信息
clientStr = bufferedReader.readLine();
System.out.println("客户端发了一段消息:" + clientStr);
Thread.sleep(20000);
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
bufferedWriter.write("我已经收到你的消息了\n");
bufferedWriter.flush(); //清空缓冲区触发消息发送
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
如图4-3所示,当引入了多线程之后,每个客户端的链接(Socket),我们可以直接给到线程池去执行,而由于这个过程是异步的,所以并不会同步阻塞影响后续链接的监听,因此在一定程度上可以提升服务端链接的处理数量。
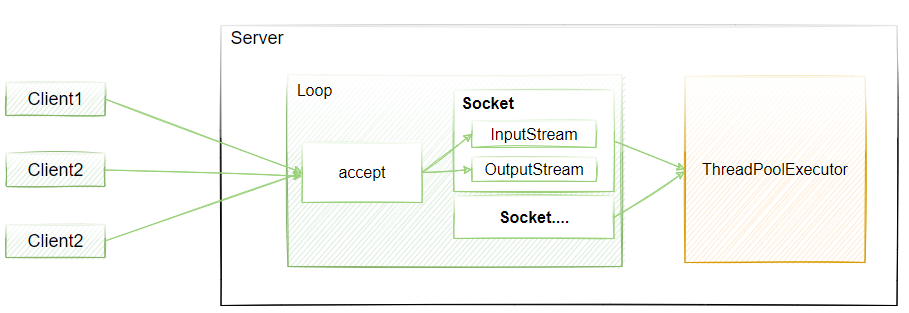
图4-3
NIO非阻塞IO
使用多线程的方式来解决这个问题,仍然有一个缺点,线程的数量取决于硬件配置,所以线程数量是有限的,如果请求量比较大的时候,线程本身会收到限制从而并发量也不会太高。那怎么办呢,我们可以采用非阻塞IO。
NIO 从JDK1.4 提出的,本意是New IO,它的出现为了弥补原本IO的不足,提供了更高效的方式,提出一个通道(channel)的概念,在IO中它始终以流的形式对数据的传输和接受,下面我们演示一下NIO的使用。
NioServerSocket
public class NioServerSocket {
public static void main(String[] args) {
try {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(8080));
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept();
if (socketChannel != null) {
//读取数据
ByteBuffer buffer = ByteBuffer.allocate(1024);
socketChannel.read(buffer);
System.out.println(new String(buffer.array()));
//写出数据
Thread.sleep(10000); //阻塞一段时间
//当数据读取到缓冲区之后,接下来就需要把缓冲区的数据写出到通道,而在写出之前必须要调用flip方法,实际上就是重置一个有效字节范围,然后把这个数据接触到通道。
buffer.flip();
socketChannel.write(buffer);//写出数据
} else {
Thread.sleep(1000);
System.out.println("连接未就绪");
}
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
NioClientSocket
public class NioClientSocket {
public static void main(String[] args) {
try {
SocketChannel socketChannel= SocketChannel.open();
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress("localhost",8080));
if(socketChannel.isConnectionPending()){
socketChannel.finishConnect();
}
ByteBuffer byteBuffer= ByteBuffer.allocate(1024);
byteBuffer.put("Hello I'M SocketChannel Client".getBytes());
byteBuffer.flip();
socketChannel.write(byteBuffer);
//读取服务端数据
byteBuffer.clear();
while(true) {
int i = socketChannel.read(byteBuffer);
if (i > 0) {
System.out.println("收到服务端的数据:" + new String(byteBuffer.array()));
} else {
System.out.println("服务端数据未准备好");
Thread.sleep(1000);
}
}
} catch (IOException | InterruptedException e) {
e.printStackTrace();
}
}
}
所谓的NIO(非阻塞IO),其实就是取消了IO阻塞和连接阻塞,当服务端不存在阻塞的时候,就可以不断轮询处理客户端的请求,如图4-4所示,表示NIO下的运行流程。
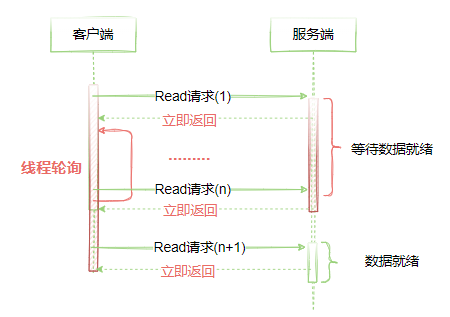
图4-4
上述这种NIO的使用方式,仍然存在一个问题,就是客户端或者服务端需要通过一个线程不断轮询才能获得结果,而这个轮询过程中会浪费线程资源。
多路复用IO
大家站在全局的角度再思考一下整个过程,有哪些地方可以优化呢?
我们回到NIOClientSocket中下面这段代码,当客户端通过read方法去读取服务端返回的数据时,如果此时服务端数据未准备好,对于客户端来说就是一次无效的轮询。
我们能不能够设计成,当客户端调用read方法之后,不仅仅不阻塞,同时也不需要轮询。而是等到服务端的数据就绪之后, 告诉客户端。然后客户端再去读取服务端返回的数据呢?
就像点外卖一样,我们在网上下单之后,继续做其他事情,等到外卖到了公司,外卖小哥主动打电话告诉你,你直接去前台取餐即可。
while(true) {
int i = socketChannel.read(byteBuffer);
if (i > 0) {
System.out.println("收到服务端的数据:" + new String(byteBuffer.array()));
} else {
System.out.println("服务端数据未准备好");
Thread.sleep(1000);
}
}
所以为了优化这个问题,引入了多路复用机制。
I/O多路复用的本质是通过一种机制(系统内核缓冲I/O数据),让单个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作
什么是fd:在linux中,内核把所有的外部设备都当成是一个文件来操作,对一个文件的读写会调用内核提供的系统命令,返回一个fd(文件描述符)。而对于一个socket的读写也会有相应的文件描述符,成为socketfd。
常见的IO多路复用方式有【select、poll、epoll】,都是Linux API提供的IO复用方式,那么接下来重点讲一下select、和epoll这两个模型
select:进程可以通过把一个或者多个fd传递给select系统调用,进程会阻塞在select操作上,这样select可以帮我们检测多个fd是否处于就绪状态,这个模式有两个缺点
- 由于他能够同时监听多个文件描述符,假如说有1000个,这个时候如果其中一个fd 处于就绪状态了,那么当前进程需要线性轮询所有的fd,也就是监听的fd越多,性能开销越大。
- 同时,select在单个进程中能打开的fd是有限制的,默认是1024,对于那些需要支持单机上万的TCP连接来说确实有点少
epoll:linux还提供了epoll的系统调用,epoll是基于事件驱动方式来代替顺序扫描,因此性能相对来说更高,主要原理是,当被监听的fd中,有fd就绪时,会告知当前进程具体哪一个fd就绪,那么当前进程只需要去从指定的fd上读取数据即可,另外,epoll所能支持的fd上线是操作系统的最大文件句柄,这个数字要远远大于1024
【由于epoll能够通过事件告知应用进程哪个fd是可读的,所以我们也称这种IO为异步非阻塞IO,当然它是伪异步的,因为它还需要去把数据从内核同步复制到用户空间中,真正的异步非阻塞,应该是数据已经完全准备好了,我只需要从用户空间读就行】
I/O多路复用的好处是可以通过把多个I/O的阻塞复用到同一个select的阻塞上,从而使得系统在单线程的情况下可以同时处理多个客户端请求。它的最大优势是系统开销小,并且不需要创建新的进程或者线程,降低了系统的资源开销,它的整体实现思想如图4-5所示。
客户端请求到服务端后,此时客户端在传输数据过程中,为了避免Server端在read客户端数据过程中阻塞,服务端会把该请求注册到Selector复路器上,服务端此时不需要等待,只需要启动一个线程,通过selector.select()阻塞轮询复路器上就绪的channel即可,也就是说,如果某个客户端连接数据传输完成,那么select()方法会返回就绪的channel,然后执行相关的处理即可。
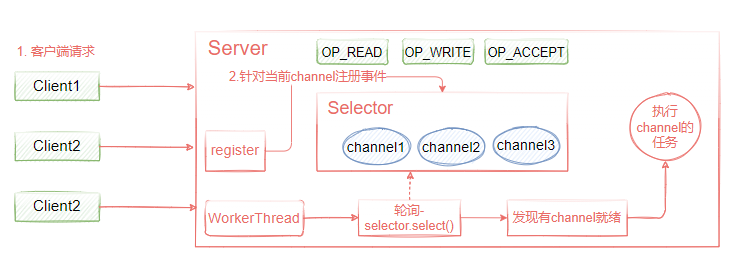
图4-5
NIOServer的实现如下
测试访问的时候,直接在cmd中通过telnet连接NIOServer,便可发送信息。
public class NIOServer implements Runnable{
Selector selector;
ServerSocketChannel serverSocketChannel;
public NIOServer(int port) throws IOException {
selector=Selector.open(); //多路复用器
serverSocketChannel=ServerSocketChannel.open();
//绑定监听端口
serverSocketChannel.socket().bind(new InetSocketAddress(port));
serverSocketChannel.configureBlocking(false);//非阻塞配置
//针对serverSocketChannel注册一个ACCEPT连接监听事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
}
@Override
public void run() {
while(!Thread.interrupted()){
try {
selector.select(); //阻塞等待事件就绪
Set selected=selector.selectedKeys(); //得到事件列表
Iterator it=selected.iterator();
while(it.hasNext()){
dispatch((SelectionKey) it.next()); //分发事件
it.remove(); //移除当前时间
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private void dispatch(SelectionKey key) throws IOException {
if(key.isAcceptable()){ //如果是客户端的连接事件,则需要针对该连接注册读写事件
register(key);
}else if(key.isReadable()){
read(key);
}else if(key.isWritable()){
write(key);
}
}
private void register(SelectionKey key) throws IOException {
//得到事件对应的连接
ServerSocketChannel server=(ServerSocketChannel)key.channel();
SocketChannel channel=server.accept(); //获得客户端的链接
channel.configureBlocking(false);
//把当前客户端连接注册到selector上,注册事件为READ,
// 也就是当前channel可读时,就会触发事件,然后读取客户端的数据
channel.register(this.selector,SelectionKey.OP_READ);
}
private void read(SelectionKey key) throws IOException {
SocketChannel channel=(SocketChannel)key.channel();
ByteBuffer byteBuffer= ByteBuffer.allocate(1024);
channel.read(byteBuffer); //把数据从channel读取到缓冲区
System.out.println("server receive msg:"+new String(byteBuffer.array()));
}
private void write(SelectionKey key) throws IOException {
SocketChannel channel=(SocketChannel)key.channel();
//写一个信息给到客户端
channel.write(ByteBuffer.wrap("hello Client,I'm NIO Server\r\n".getBytes()));
}
public static void main(String[] args) throws IOException {
NIOServer server=new NIOServer(8888);
new Thread(server).start();
}
}
事实上NIO已经解决了上述BIO暴露的下面两个问题:
- 同步阻塞IO,读写阻塞,线程等待时间过长。
- 在制定线程策略的时候,只能根据CPU的数目来限定可用线程资源,不能根据连接并发数目来制定,也就是连接有限制。否则很难保证对客户端请求的高效和公平。
到这里为止,通过NIO的多路复用机制,解决了IO阻塞导致客户端连接处理受限的问题,服务端只需要一个线程就可以维护多个客户端,并且客户端的某个连接如果准备就绪时,会通过事件机制告诉应用程序某个channel可用,应用程序通过select方法选出就绪的channel进行处理。
单线程Reactor 模型(高性能I/O设计模式)
了解了NIO多路复用后,就有必要再和大家说一下Reactor多路复用高性能I/O设计模式,Reactor本质上就是基于NIO多路复用机制提出的一个高性能IO设计模式,它的核心思想是把响应IO事件和业务处理进行分离,通过一个或者多个线程来处理IO事件,然后将就绪得到事件分发到业务处理handlers线程去异步非阻塞处理,如图4-6所示。
Reactor模型有三个重要的组件:
- Reactor :将I/O事件发派给对应的Handler
- Acceptor :处理客户端连接请求
- Handlers :执行非阻塞读/写
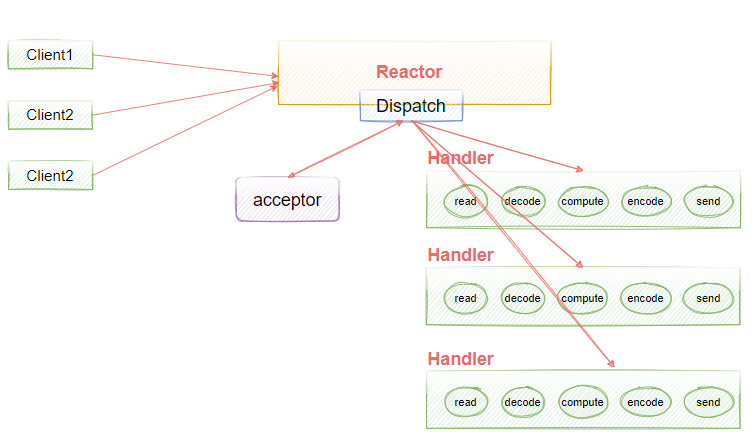
图4-6
下面演示一个单线程的Reactor模型。
Reactor
Reactor 负责响应IO事件,一旦发生,广播发送给相应的Handler去处理。
public class Reactor implements Runnable{
private final Selector selector;
private final ServerSocketChannel serverSocketChannel;
public Reactor(int port) throws IOException {
//创建选择器
selector= Selector.open();
//创建NIO-Server
serverSocketChannel=ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress(port));
serverSocketChannel.configureBlocking(false);
SelectionKey key=serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
// 绑定一个附加对象
key.attach(new Acceptor(selector,serverSocketChannel));
}
@Override
public void run() {
while(!Thread.interrupted()){
try {
selector.select(); //阻塞等待就绪事件
Set selectionKeys=selector.selectedKeys();
Iterator it=selectionKeys.iterator();
while(it.hasNext()){
dispatch((SelectionKey) it.next());
it.remove();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void dispatch(SelectionKey key){
//调用之前注册时附加的对象,也就是attach附加的acceptor
Runnable r=(Runnable)key.attachment();
if(r!=null){
r.run();
}
}
public static void main(String[] args) throws IOException {
new Thread(new Reactor(8888)).start();
}
}
Acceptor
public class Acceptor implements Runnable{
private Selector selector;
private ServerSocketChannel serverSocketChannel;
public Acceptor(Selector selector, ServerSocketChannel serverSocketChannel) {
this.selector = selector;
this.serverSocketChannel = serverSocketChannel;
}
@Override
public void run() {
SocketChannel channel;
try {
channel=serverSocketChannel.accept();
System.out.println(channel.getRemoteAddress()+": 收到一个客户端连接");
channel.configureBlocking(false);
//当channel连接中数据就绪时,调用DispatchHandler来处理channel
//巧妙使用了SocketChannel的attach功能,将Hanlder和可能会发生事件的channel链接在一起,当发生事件时,可以立即触发相应链接的Handler。
channel.register(selector, SelectionKey.OP_READ,new DispatchHandler(channel));
} catch (IOException e) {
e.printStackTrace();
}
}
}
Handler
public class DispatchHandler implements Runnable{
private SocketChannel channel;
public DispatchHandler(SocketChannel channel) {
this.channel = channel;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"---handler"); //case: 打印当前线程名称,证明I/O是同一个线程来处理。
ByteBuffer buffer=ByteBuffer.allocate(1024);
int len=0,total=0;
String msg="";
try {
do {
len = channel.read(buffer);
if (len > 0) {
total += len;
msg += new String(buffer.array());
}
buffer.clear();
} while (len > buffer.capacity());
System.out.println(channel.getRemoteAddress()+":Server Receive msg:"+msg);
}catch (Exception e){
e.printStackTrace();
if(channel!=null){
try {
channel.close();
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
}
}
演示方式,通过window的cmd窗口,使用telnet 192.168.1.102 8888 连接到Server端进行数据通信;也可以通过下面这样一个客户端程序来访问。
ReactorClient
public class ReactorClient {
private static Selector selector;
public static void main(String[] args) throws IOException {
selector=Selector.open();
//创建一个连接通道连接指定的server
SocketChannel socketChannel= SocketChannel.open();
socketChannel.configureBlocking(false);
socketChannel.connect(new InetSocketAddress("192.168.1.102",8888));
socketChannel.register(selector, SelectionKey.OP_CONNECT);
while(true){
selector.select();
Set<SelectionKey> selectionKeys=selector.selectedKeys();
Iterator<SelectionKey> iterator=selectionKeys.iterator();
while(iterator.hasNext()){
SelectionKey key=iterator.next();
iterator.remove();
if(key.isConnectable()){
handleConnection(key);
}else if(key.isReadable()){
handleRead(key);
}
}
}
}
private static void handleConnection(SelectionKey key) throws IOException {
SocketChannel socketChannel=(SocketChannel)key.channel();
if(socketChannel.isConnectionPending()){
socketChannel.finishConnect();
}
socketChannel.configureBlocking(false);
while(true) {
Scanner in = new Scanner(System.in);
String msg = in.nextLine();
socketChannel.write(ByteBuffer.wrap(msg.getBytes()));
socketChannel.register(selector,SelectionKey.OP_READ);
}
}
private static void handleRead(SelectionKey key) throws IOException {
SocketChannel channel=(SocketChannel)key.channel();
ByteBuffer byteBuffer=ByteBuffer.allocate(1024);
channel.read(byteBuffer);
System.out.println("client receive msg:"+new String(byteBuffer.array()));
}
}
这是最基本的单Reactor单线程模型(整体的I/O操作是由同一个线程完成的)。
其中Reactor线程,负责多路分离套接字,有新连接到来触发connect 事件之后,交由Acceptor进行处理,有IO读写事件之后交给hanlder 处理。
Acceptor主要任务就是构建handler ,在获取到和client相关的SocketChannel之后 ,绑定到相应的hanlder上,对应的SocketChannel有读写事件之后,基于racotor 分发,hanlder就可以处理了(所有的IO事件都绑定到selector上,有Reactor分发)
Reactor 模式本质上指的是使用 I/O 多路复用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O)的模式。
多线程单Reactor模型
单线程Reactor这种实现方式有存在着缺点,从实例代码中可以看出,handler的执行是串行的,如果其中一个handler处理线程阻塞将导致其他的业务处理阻塞。由于handler和reactor在同一个线程中的执行,这也将导致新的无法接收新的请求,我们做一个小实验:
- 在上述Reactor代码的DispatchHandler的run方法中,增加一个Thread.sleep()。
- 打开多个客户端窗口连接到Reactor Server端,其中一个窗口发送一个信息后被阻塞,另外一个窗口再发信息时由于前面的请求阻塞导致后续请求无法被处理。
为了解决这种问题,有人提出使用多线程的方式来处理业务,也就是在业务处理的地方加入线程池异步处理,将reactor和handler在不同的线程来执行,如图4-7所示。
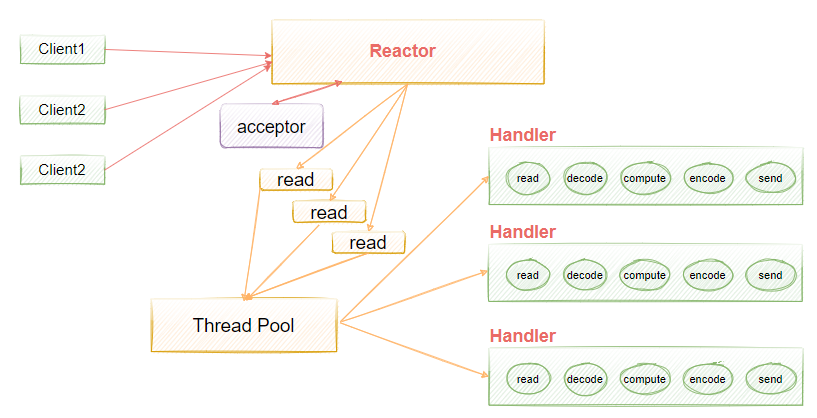
图4-7
多线程改造-MultiDispatchHandler
我们直接将4.2.5小节中的Reactor单线程模型改成多线程,其实我们就是把IO阻塞的问题通过异步的方式做了优化,代码如下,
public class MultiDispatchHandler implements Runnable{
private SocketChannel channel;
public MultiDispatchHandler(SocketChannel channel) {
this.channel = channel;
}
private static Executor executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() << 1);
@Override
public void run() {
processor();
}
private void processor(){
executor.execute(new ReaderHandler(channel));
}
public static class ReaderHandler implements Runnable{
private SocketChannel channel;
public ReaderHandler(SocketChannel socketChannel) {
this.channel = socketChannel;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"---handler"); //case: 打印当前线程名称,证明I/O是同一个线程来处理。
ByteBuffer buffer= ByteBuffer.allocate(1024);
int len=0;
String msg="";
try {
do {
len = channel.read(buffer);
if (len > 0) {
msg += new String(buffer.array());
}
buffer.clear();
} while (len > buffer.capacity());
if(len>0) {
System.out.println(channel.getRemoteAddress() + ":Server Receive msg:" + msg);
}
}catch (Exception e){
e.printStackTrace();
if(channel!=null){
try {
channel.close();
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
}
}
}
Acceptor
public class Acceptor implements Runnable{
private Selector selector;
private ServerSocketChannel serverSocketChannel;
public Acceptor(Selector selector, ServerSocketChannel serverSocketChannel) {
this.selector = selector;
this.serverSocketChannel = serverSocketChannel;
}
@Override
public void run() {
SocketChannel channel;
try {
channel=serverSocketChannel.accept();
System.out.println(channel.getRemoteAddress()+": 收到一个客户端连接");
channel.configureBlocking(false);
//当channel连接中数据就绪时,调用DispatchHandler来处理channel
//巧妙使用了SocketChannel的attach功能,将Hanlder和可能会发生事件的channel链接在一起,当发生事件时,可以立即触发相应链接的Handler。
channel.register(selector, SelectionKey.OP_READ,new MultiDispatchHandler(channel));
} catch (IOException e) {
e.printStackTrace();
}
}
}
多线程Reactor总结
在多线程Reactor模型中,添加了一个工作者线程池,并将非I/O操作从Reactor线程中移出转交给工作者线程池来执行。这样能够提高Reactor线程的I/O响应,不至于因为一些耗时的业务逻辑而延迟对后面I/O请求的处理。
多Reactor多线程模式(主从多Reactor模型)
在多线程单Reactor模型中,我们发现所有的I/O操作是由一个Reactor来完成,而Reactor运行在单个线程中,它需要处理包括Accept()/read()/write/connect操作,对于小容量的场景,影响不大。但是对于高负载、大并发或大数据量的应用场景时,容易成为瓶颈,主要原因如下:
- 一个NIO线程同时处理成百上千的链路,性能上无法支撑,即便NIO线程的CPU负荷达到100%,也无法满足海量消息的读取和发送;
- 当NIO线程负载过重之后,处理速度将变慢,这会导致大量客户端连接超时,超时之后往往会进行重发,这更加重了NIO线程的负载,最终会导致大量消息积压和处理超时,成为系统的性能瓶颈;
所以,我们还可以更进一步优化,引入多Reactor多线程模式,如图4-8所示,Main Reactor负责接收客户端的连接请求,然后把接收到的请求传递给SubReactor(其中subReactor可以有多个),具体的业务IO处理由SubReactor完成。
Multiple Reactors 模式通常也可以等同于 Master-Workers 模式,比如 Nginx 和 Memcached 等就是采用这种多线程模型,虽然不同的项目实现细节略有区别,但总体来说模式是一致的。
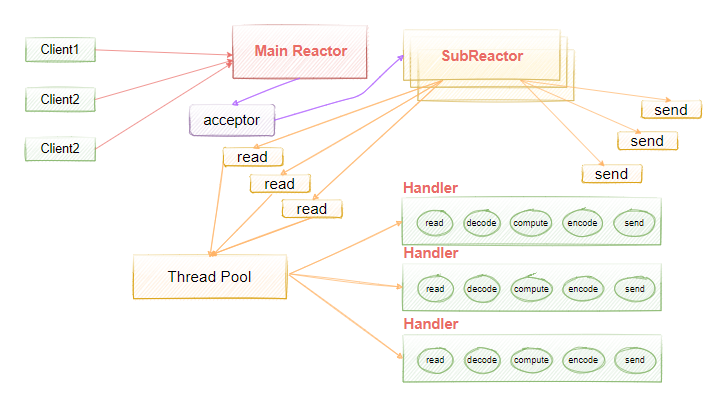
图4-8
Acceptor,请求接收者,在实践时其职责类似服务器,并不真正负责连接请求的建立,而只将其请求委托 Main Reactor 线程池来实现,起到一个转发的作用。
Main Reactor,主 Reactor 线程组,主要负责连接事件,并将IO读写请求转发到 SubReactor 线程池。
Sub Reactor,Main Reactor 通常监听客户端连接后会将通道的读写转发到 Sub Reactor 线程池中一个线程(负载均衡),负责数据的读写。在 NIO 中 通常注册通道的读(OP_READ)、写事件(OP_WRITE)。
MultiplyReactor
public class MultiplyReactor {
public static void main(String[] args) throws IOException {
MultiplyReactor mr = new MultiplyReactor(8888);
mr.start();
}
private static final int POOL_SIZE = Runtime.getRuntime().availableProcessors();
// Reactor(Selector) 线程池,其中一个线程被 mainReactor 使用,剩余线程都被 subReactor 使用
static Executor mainReactorExecutor = Executors.newFixedThreadPool(POOL_SIZE);
// 主 Reactor,接收连接,把 SocketChannel 注册到从 Reactor 上
private Reactor mainReactor;
private int port;
public MultiplyReactor(int port) {
try {
this.port = port;
mainReactor = new Reactor();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 启动主从 Reactor,初始化并注册 Acceptor 到主 Reactor
*/
public void start() throws IOException {
new Acceptor(mainReactor.getSelector(), port); // 将 ServerSocketChannel 注册到 mainReactor
mainReactorExecutor.execute(mainReactor); //使用线程池来处理main Reactor的连接请求
}
}
Reactor
public class Reactor implements Runnable{
private ConcurrentLinkedQueue<AsyncHandler> events=new ConcurrentLinkedQueue<>();
private final Selector selector;
public Reactor() throws IOException {
this.selector = Selector.open();
}
public Selector getSelector(){
return selector;
}
@Override
public void run() {
try {
while (!Thread.interrupted()) {
AsyncHandler handler;
while ((handler = events.poll()) != null) {
handler.getChannel().configureBlocking(false);
SelectionKey sk=handler.getChannel().register(selector, SelectionKey.OP_READ);
sk.attach(handler);
handler.setSk(sk);
}
selector.select(); //阻塞
Set<SelectionKey> selectionKeys=selector.selectedKeys();
Iterator<SelectionKey> it=selectionKeys.iterator();
while(it.hasNext()){
SelectionKey key=it.next();
//获取attach方法传入的附加对象
Runnable runnable=(Runnable)key.attachment();
if(runnable!=null){
runnable.run();
}
it.remove();
}
}
}catch (Exception e){
e.printStackTrace();
}
}
public void register(AsyncHandler asyncHandler){
events.offer(asyncHandler);
selector.wakeup();
}
}
Acceptor
public class Acceptor implements Runnable{
final Selector sel;
final ServerSocketChannel serverSocket;
int handleNext = 0;
private final int POOL_SIZE=Runtime.getRuntime().availableProcessors();
private Executor subReactorExecutor= Executors.newFixedThreadPool(POOL_SIZE);
private Reactor[] subReactors=new Reactor[POOL_SIZE-1];
public Acceptor(Selector sel, int port) throws IOException {
this.sel = sel;
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port)); // 绑定端口
// 设置成非阻塞模式
serverSocket.configureBlocking(false);
// 注册到 选择器 并设置处理 socket 连接事件
serverSocket.register(sel, SelectionKey.OP_ACCEPT,this);
init();
System.out.println("mainReactor-" + "Acceptor: Listening on port: " + port);
}
public void init() throws IOException {
for (int i = 0; i < subReactors.length; i++) {
subReactors[i]=new Reactor();
subReactorExecutor.execute(subReactors[i]);
}
}
@Override
public synchronized void run() {
try {
// 接收连接,非阻塞模式下,没有连接直接返回 null
SocketChannel sc = serverSocket.accept();
if (sc != null) {
// 把提示发到界面
sc.write(ByteBuffer.wrap("Multiply Reactor Pattern Example\r\nreactor> ".getBytes()));
System.out.println(Thread.currentThread().getName()+":Main-Reactor-Acceptor: " + sc.socket().getLocalSocketAddress() +" 注册到 subReactor-" + handleNext);
// 如何解决呢,直接调用 wakeup,有可能还没有注册成功又阻塞了。这是一个多线程同步的问题,可以借助队列进行处理
Reactor subReactor = subReactors[handleNext];
subReactor.register(new AsyncHandler(sc));
if(++handleNext == subReactors.length) {
handleNext = 0;
}
}
} catch (Exception ex) {
ex.printStackTrace();
}
}
}
AsyncHandler
public class AsyncHandler implements Runnable{
private SocketChannel channel;
private SelectionKey sk;
ByteBuffer inputBuffer=ByteBuffer.allocate(1024);
ByteBuffer outputBuffer=ByteBuffer.allocate(1024);
StringBuilder builder=new StringBuilder(); //存储客户端的完整消息
public AsyncHandler(SocketChannel channel){
this.channel=channel;
}
public SocketChannel getChannel() {
return channel;
}
public void setSk(SelectionKey sk) {
this.sk = sk;
}
@Override
public void run() {
try {
if (sk.isReadable()) {
read();
} else if (sk.isWritable()) {
write();
}
}catch (Exception e){
try {
this.sk.channel().close();
} catch (IOException ioException) {
ioException.printStackTrace();
}
}
}
protected void read() throws IOException {
inputBuffer.clear();
int n=channel.read(inputBuffer);
if(inputBufferComplete(n)){
System.out.println(Thread.currentThread().getName()+":Server端收到客户端的请求消息:"+builder.toString());
outputBuffer.put(builder.toString().getBytes(StandardCharsets.UTF_8));
this.sk.interestOps(SelectionKey.OP_WRITE); //更改服务的逻辑状态以及处理的事件类型
}
}
private boolean inputBufferComplete(int bytes) throws EOFException {
if(bytes>0){
inputBuffer.flip(); //转化成读取模式
while(inputBuffer.hasRemaining()){ //判断缓冲区中是否还有元素
byte ch=inputBuffer.get(); //得到输入的字符
if(ch==3){ //表示Ctrl+c 关闭连接
throw new EOFException();
}else if(ch=='\r'||ch=='\n'){ //表示换行符
return true;
}else{
builder.append((char)ch); //拼接读取到的数据
}
}
}else if(bytes==-1){
throw new EOFException(); //客户端关闭了连接
}
return false;
}
private void write() throws IOException {
int written=-1;
outputBuffer.flip(); //转化为读模式,判断是否有数据需要发送
if(outputBuffer.hasRemaining()){
written=channel.write(outputBuffer); //把数据写回客户端
}
outputBuffer.clear();
builder.delete(0,builder.length());
if(written<=0){ //表示客户端没有输信息
this.sk.channel().close();
}else{
channel.write(ByteBuffer.wrap("\r\nreactor>".getBytes()));
this.sk.interestOps(SelectionKey.OP_READ);
}
}
}
关注[跟着Mic学架构]公众号,获取更多精品原创

从网络通信的演进过程彻底搞懂Redis高性能通信的原理(全网最详细,建议收藏)的更多相关文章
- 一文教你快速搞懂速度曲线规划之S形曲线(超详细+图文+推导+附件代码)
本文介绍了运动控制终的S曲线,通过matlab和C语言实现并进行仿真:本文篇幅较长,请自备茶水: 请帮忙点个赞
- 搞懂Redis RDB和AOF持久化及工作原理
前言 因为Redis的数据都储存在内存中,当进程退出时,所有数据都将丢失.为了保证数据安全,Redis支持RDB和AOF两种持久化机制有效避免数据丢失问题.RDB可以看作在某一时刻Redis的快照(s ...
- 这一次搞懂Spring的XML解析原理
前言 Spring已经是我们Java Web开发必不可少的一个框架,其大大简化了我们的开发,提高了开发者的效率.同时,其源码对于开发者来说也是宝藏,从中我们可以学习到非常优秀的设计思想以及优雅的命名规 ...
- 【Kubernetes】两篇文章 搞懂 K8s 的 fannel 网络原理
近期公司的flannel网络很不稳定,花时间研究了下并且保证云端自动部署的网络能够正常work. 1.网络拓扑 拓扑如下:(点开看大图) 容器网卡通过docker0桥接到flannel0网卡,而每个 ...
- 搞懂Redis复制原理
前言 与大多数db一样,Redis也提供了复制机制,以满足故障恢复和负载均衡等需求.复制也是Redis高可用的基础,哨兵和集群都是建立在复制基础上实现高可用的.复制不仅提高了整个系统的容错能力,还可以 ...
- 一文教你快速搞懂速度曲线规划之T形曲线(超详细+图文+推导+附件代码)
运动控制中常用的T速度曲线规划的原理和程序实现,最后给出了测试结果: 如果本文帮到了您,请帮忙点个赞
- 这一次搞懂Spring的Bean实例化原理
文章目录 前言 正文 环境准备 两个重要的Processor 注册BeanPostProcessor对象 Bean对象的创建 createBeanInstance addSingletonFactor ...
- 彻底搞懂Redis主从复制原理及实战
欢迎关注公众号:「码农富哥」,致力于分享后端技术 (高并发架构,分布式集群系统,消息队列中间件,网络,微服务,Linux, TCP/IP, HTTP, MySQL, Redis), Python 等 ...
- 【干货!!】三句话搞懂 Redis 缓存穿透、击穿、雪崩
前言 如何有效的理解并且区分 Reids 穿透.击穿和雪崩之间的区别,一直以来都挺困扰我的.特别是穿透和击穿,过一段时间就稀里糊涂的分不清了. 为了有效的帮助笔者自己,以及拥有同样烦恼的朋友们区分这三 ...
随机推荐
- roslaunch保存的log文件没有打印的ERROR信息
最近调试,发现roslaunch启动的节点,log文件中没有ERROR信息. 经过一番查证发现,INFO和WARN是保存在log文件中,ERROR直接打印在terminal 参考: https://g ...
- configparser读
#-*-coding:utf-8-*-__author__ = "logan.xu"import configparserconf = configparser.ConfigPar ...
- MySQL高可用主从复制部署
原文转自:https://www.cnblogs.com/itzgr/p/10233932.html作者:木二 目录 一 基础环境 二 实际部署 2.1 安装MySQL 2.2 初始化MySQL 2. ...
- 教你用multipass快速搭建k8s集群
目录 前言 一.multipass快速入门 安装 使用 二.使用multipass搭建k8s集群 创建3台虚拟机 安装master节点 安装node节点 测试k8s集群 三.其他问题 不能拉取镜像:报 ...
- Android手机 自动批量发朋友圈
做了各种对比之后,还是这个微商工具最好用
- Jetpack Compose学习(3)——图标(Icon) 按钮(Button) 输入框(TextField) 的使用
原文地址: Jetpack Compose学习(3)--图标(Icon) 按钮(Button) 输入框(TextField) 的使用 | Stars-One的杂货小窝 本篇分别对常用的组件:图标(Ic ...
- java 线程基础篇,看这一篇就够了。
前言: Java三大基础框架:集合,线程,io基本是开发必用,面试必问的核心内容,今天我们讲讲线程. 想要把线程理解透彻,这需要具备很多方面的知识和经验,本篇主要是关于线程基础包括线程状态和常用方法. ...
- noip模拟35
A. 玩游戏 考场做法用双指针向两侧更新,当左段点左移一位时,如果右端点不满足条件,则跳回肯定满足的位置.复杂度玄学 题解做法是类似最长子段和,如果有一个区间和为负,则维护的指针跳过去即可 B. 排列 ...
- Docker入门之image篇
基本概念 Image 镜像:只读模板 Container 容器:从镜像创建的运行实例 Repository 仓库:集中存放镜像文件的场所.分为公开仓库(Public)和私有仓库(Private)两种形 ...
- C# List集合类常用操作 (一)
所有操作基于以下类 class Employees { public int Id { get; set; } public string Name { get; set; } public stri ...