Map集和
Map<K,V>
java.util 包下
特点
- Map与Collection并列存在。用于保存具有映射关系的数据:key-value
- Map 中的 key 和 value 都可以是任何引用类型的数据
- Map 中的 key 用Set来存放,不允许重复,即同一个Map 对象所对应的类,须重写hashCode()和equals()方法
- 常用String类作为Map的“键”
- key 和 value 之间存在单向一对一关系,即通过指定的key 总能找到唯一的、确定的 value
- Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中,HashMap是 Map 接口使用频率最高的实现类
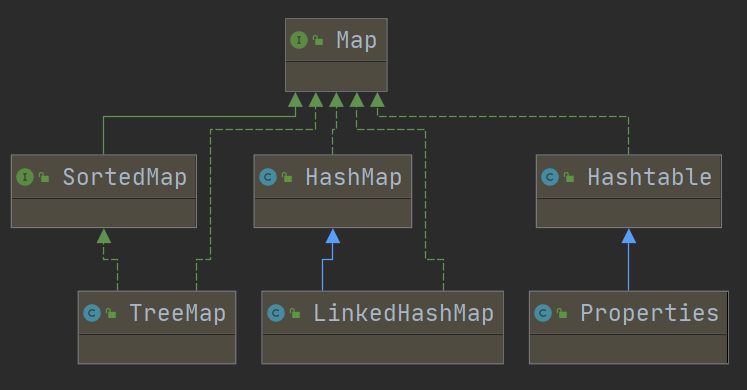
继承树
常用方法
添加修改删除操作
Object put(Object key,Object value):将指定key-value添加到(或修改)当前map对象中
void putAll(Map m):将m中的所有key-value对存放到当前map中
Object remove(Object key):移除指定key的key-value对,并返回value
void clear():清空当前map中的所有数据
default V replace(K key, V value) 只有当目标映射到某个值时,才能替换指定键的条目。
元素查询操作
Object get(Object key):获取指定key对应的value
boolean containsKey(Object key):是否包含指定的key
boolean containsValue(Object value):是否包含指定的value
int size():返回map中key-value对的个数
boolean isEmpty():判断当前map是否为空
boolean equals(Object obj):判断当前map和参数对象obj是否相等
int size() 返回此地图中键值映射的数量。
元素视图操作方法
Set keySet():返回所有key构成的Set集合
Collection values():返回所有value构成的Collection集合
Set entrySet():返回所有key-value对构成的Set集合
entrySet
- Map的内部类
- Map.entrySet方法返回地图的集合视图,其元素属于此类。 获取对映射条目的引用的唯一方法是从该集合视图的迭代器。 这些Map.Entry对象仅在迭代期间有效; 更正式地,如果在迭代器返回条目之后修改了后备映射,则映射条目的行为是未定义的,除了通过映射条目上的setValue操作
方法
static <K,V> Comparator<Map.Entry<K,V>> comparingByKey(Comparator<? super K> cmp) 返回一个比较器,比较Map.Entry按键使用给定的Comparator 。
boolean equals(Object o) 将指定的对象与此条目进行比较以获得相等性。
K getKey() 返回与此条目相对应的键。
V getValue() 返回与此条目相对应的值。
V setValue(V value) 用指定的值替换与该条目相对应的值(可选操作)。
HashMap
java.util 包下
特点
- HashMap是 Map 接口使用频率最高的实现类。
- 允许使用null键和null值,与HashSet一样,不保证映射的顺序。
- 所有的key构成的集合是Set:无序的、不可重复的。所以,key所在的类要重写:equals()和hashCode()
- 所有的value构成的集合是Collection:无序的、可以重复的。所以,value所在的类要重写:equals()
- 一个key-value构成一个entry
- 所有的entry构成的集合是Set:无序的、不可重复的
- HashMap 判断两个 key 相等的标准是:两个 key 通过 equals() 方法返回 true, hashCode 值也相等。
- HashMap 判断两个 value相等的标准是:两个 value 通过 equals() 方法返回 true。
- 线程不安全
HashMap 的重要常量
- DEFAULT_INITIAL_CAPACITY : HashMap的默认容量,16
- MAXIMUM_CAPACITY : HashMap的最大支持容量,2^30
- DEFAULT_LOAD_FACTOR:HashMap的默认加载因子
- TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树
- UNTREEIFY_THRESHOLD:Bucket中红黑树存储的Node小于该默认值,转化为链表
- MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量。(当桶中Node的数量大到需要变红黑树时,若hash表容量小于- - - - MIN_TREEIFY_CAPACITY时,此时应执行resize扩容操作这个- MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。)
- table:存储元素的数组,总是2的n次幂
- entrySet:存储具体元素的集
- size:HashMap中存储的键值对的数量
- modCount:HashMap扩容和结构改变的次数。
- threshold:扩容的临界值,=容量*填充因子
- loadFactor:填充因子
存储结构
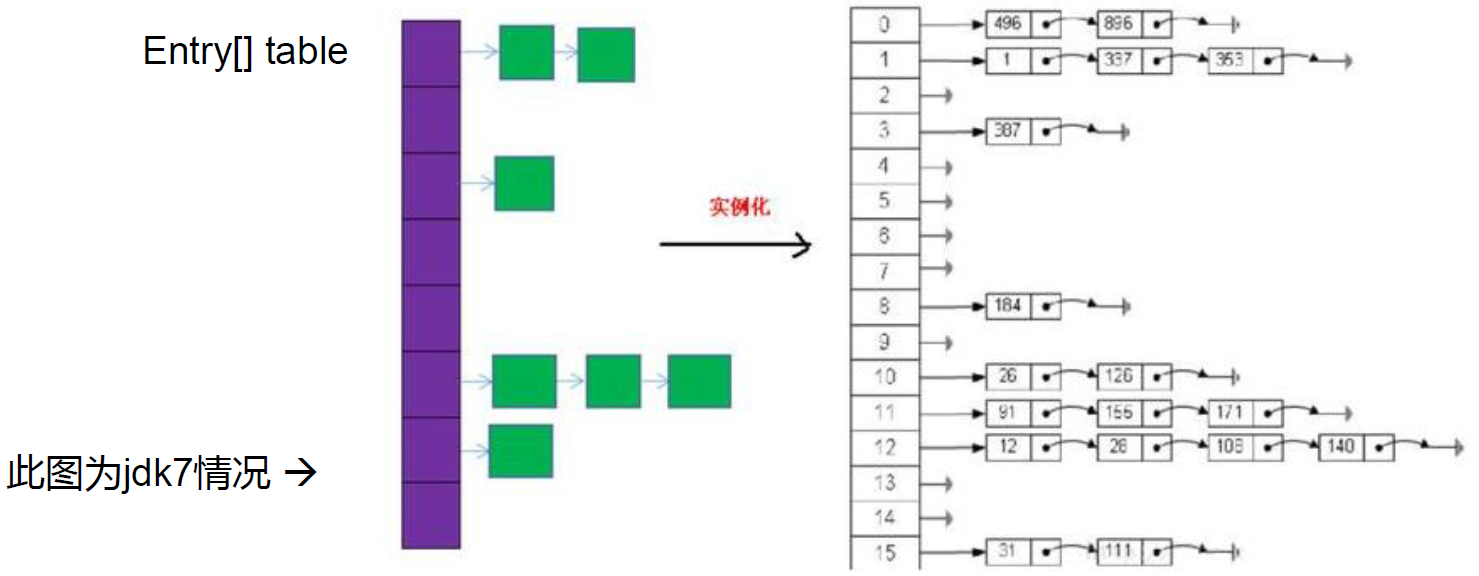
- JDK 7及以前版本:HashMap是数组+链表结构(即为链地址法)
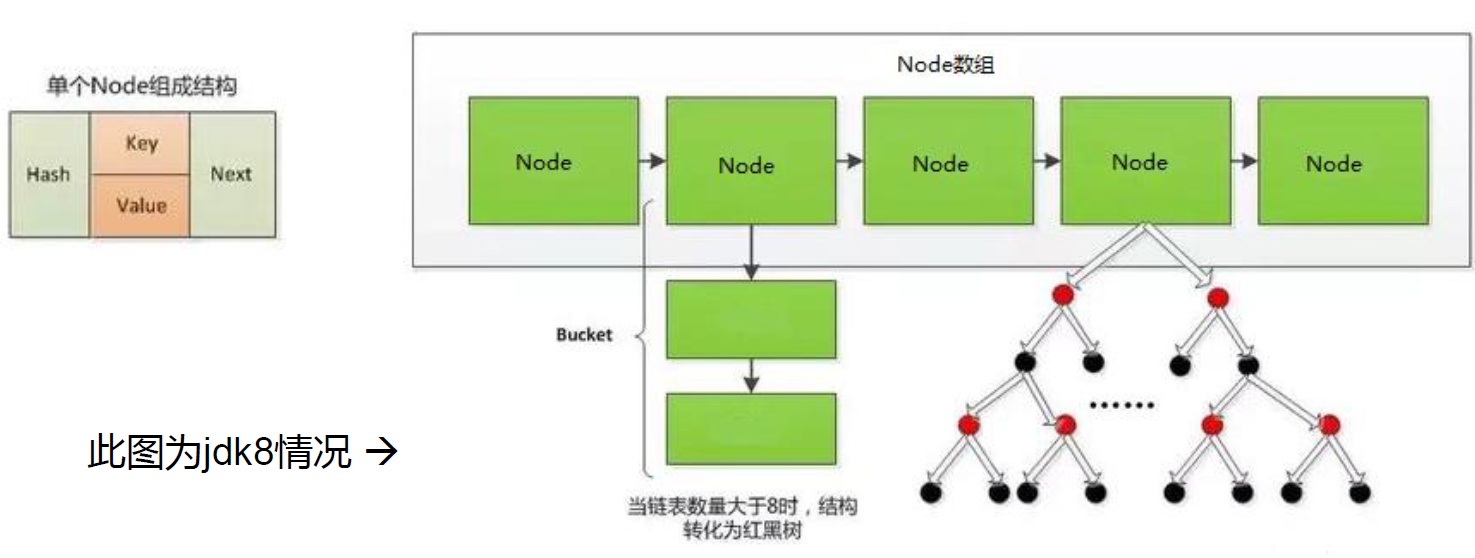
- JDK 8版本发布以后:HashMap是数组+链表+红黑树实现。
jdk1.8
- HashMap的内部存储结构其实是数组+链表+树的结合。当实例化一个HashMap时,会初始化initialCapacity和loadFactor,在put第一对映射关系时,系统会创建一个长度为initialCapacity的Node数组,这个长度在哈希表中被称为容量(Capacity),在这个数组中可以存放元素的位置我们称之为 “桶”(bucket),每个bucket都有自己的索引,系统可以根据索引快速的查找bucket中的元素。
- 每个bucket中存储一个元素,即一个Node对象,但每一个Node对象可以带一个引用变量next,用于指向下一个元素,因此,在一个桶中,就有可能生成一个Node链。也可能是一个一个TreeNode对象,每一个TreeNode对象可以有两个叶子结点left和right,因此,在一个桶中,就有可能生成一个TreeNode树。而新添加的元素作为链表的last,或树的叶子结点。
- 那么HashMap什么时候进行扩容和树形化呢?
- 当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)loadFactor 时 , 就会进行数组扩容, loadFactor 的默认 值(DEFAULT_LOAD_FACTOR)为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小(DEFAULT_INITIAL_CAPACITY)为16,那么当HashMap中元素个数超过160.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
- 当HashMap中的其中一个链的对象个数如果达到了8个,此时如果capacity没有达到64,那么HashMap会先扩容解决,如果已经达到了64,那么这个链会变成树,结点类型由Node变成TreeNode类型。当然,如果当映射关系被移除后,下次resize方法时判断树的结点个数低于6个,也会把树再转为链表。
- 关于映射关系的key是否可以修改?answer:不要修改
- 映射关系存储到HashMap中会存储key的hash值,这样就不用在每次查找时重新计算每一个Entry或Node(TreeNode)的hash值了,因此如果已经put到Map中的映射关系,再修改key的属性,而这个属性又参与hashcode值的计算,那么会导致匹配不上
总结
JDK1.8相较于之前的变化:
- HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组
- 当首次调用map.put()时,再创建长度为16的数组
- 数组为Node类型,在jdk7中称为Entry类型
- 形成链表结构时,新添加的key-value对在链表的尾部(七上八下)
- 当数组指定索引位置的链表长度>8时,且map中的数组的长度> 64时,此索引位置上的所有key-value对使用红黑树进行存储。
面试题
- 面试题:负载因子值的大小,对HashMap有什么影响
- 负载因子的大小决定了HashMap的数据密度。
- 负载因子越大密度越大,发生碰撞的几率越高,数组中的链表越容易长,造成查询或插入时的比较次数增多,性能会下降。
- 负载因子越小,就越容易触发扩容,数据密度也越小,意味着发生碰撞的几率越小,数组中的链表也就越短,查询和插入时比较的次数也越小,性能会更高。但是会浪费一定的内容空间。而且经常扩容也会影响性能,建议初始化预设大一点的空间。
- 按照其他语言的参考及研究经验,会考虑将负载因子设置为0.7~0.75,此时平均检索长度接近于常数。
HashMap存储自定义类型键值
- 当给HashMap存储自定义对象时,如果自定义对象作为key存在,这是要保证对象的唯一性,必须重写对象的hashCode和equals方法
- 如果要保证map中存储元素的顺序。主要体现在key值上,可以使用 java.util.LinkedHashMap集合来存放
LinkedHashMap
java.util 包下
- 描述
- HashMap保证对元素的唯一,并且查询速度相对比较快,但是对成对元素存放进去无法保证顺序,既要保证有序,又要保证速度就使用它。
- java.util.LinkedHashMap<K,V> extends HashMap<K,V>
- 在HashMap存储结构的基础上,使用了一对双向链表来记录添加元素的顺序
- 与LinkedHashSet类似,LinkedHashMap 可以维护 Map 的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致
- 线程不安全
HashMap 和 LinkedMap的内部类
- HashMap
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
- LinkedHashMap
static class Entry<K, V> extends HashMap.Node<K, V> {
LinkedHashMap.Entry<K, V> before, after;
Entry(int hash, K key, V value, HashMap.Node<K, V> next) {
super(hash, key, value, next);
}
}
TreeMap
java.util
描述
- TreeMap存储 Key-Value 对时,需要根据 key-value 对进行排序。 TreeMap 可以保证所有的 Key-Value 对处于有有序状态。
- TreeSet底层使用红黑树结构存储数据
- TreeMap 的 Key 的排序:
- 自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClasssCastException
- 定制排序:创建 TreeMap 时,传入一个 Comparator 对象,该对象负责对TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key 实现Comparable 接口
- TreeMap判断两个key相等的标准:两个key通过compareTo()方法或者compare()方法返回0。
- 线程不安全
HashTable
java.util
描述
- Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V> ...
- Hashtable是个古老的 Map 实现类,JDK1.0就提供了。不同于HashMap, Hashtable是线程安全的。
- Hashtable实现原理和HashMap相同,功能相同。底层都使用哈希表结构,查询速度快,很多情况下可以互用。
- 默认容量11,如果加载因子大于 0.75则扩容原来的数组的2倍加1
// 新数组的容量=旧数组长度2+1
int newCapacity = (oldCapacity << 1) + 1; - 与HashMap不同,Hashtable 不允许使用 null 作为 key 和 value
- 与HashMap一样,Hashtable 也不能保证其中 Key-Value 对的顺序
- Hashtable判断两个key相等、两个value相等的标准,与HashMap一致。
- (了解) Hashtable和 Vector集合一样,在jdk1.2版本后被更先进的集合(HashMap,ArrayList)取代了 Hashtable有一个子类 Properties依然活跃在历史的舞台上, Properties集合是一个唯一一个和IO流相结合的集合
方法
boolean contains(Object value) 测试此映射表中是否存在与指定值关联的键。
boolean containsKey(Object key) 测试指定对象是否为此哈希表中的键。
boolean containsValue(Object value) 如果此 Hashtable 将一个或多个键映射到此值,则返回 true。
HashMap于Hashtable的区别
- 继承的父类不同
- HashMap继承 AbstractMap类.
- Hashtable继承 Dictionary类,Dictionary是一个废弃的类. 但二者都实现了Map接口。
- HashMap线程不安全,HashTable线程安全
- 包含的contains方法不同
- HashMap没有contains方法,而包括containsValue和containsKey方法
- Hashtable则保留了contains方法,效果同containsValue,好包括containsValue和conatinsKey方法。
- 是否允许null值
- HashMap;集合可以存储null key值,null value值
- Hashtable集合;不可以存储null值,null键,否则报空指针
- 计算hash值方式不同
- HashTable直接使用对象的hashCode。
- 而HashMap重新计算hash值。
- 扩容方式不同
- HashMap 哈希扩容必须要求为原容量的2倍,而且一定是2的幂次倍扩容结果,而且每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入;
- Hashtable扩容为原容量2倍加1;
- 存储方式
- HashMap:
jdk7底层结构只:数组+链表。jdk8中底层结构:数组+链表+红黑树。
形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。 - HashTable中, 都是以链表方式存储。
- HashMap:
- 遍历方式不同
- Hashtable,HashMap都是用了iterator,由于历史原因,Hashtable还是用Enumeration方式。
- 底层数据结构
- Hashtable;底层是以哈希表,是一个线程安全的集合,是单线程的集合,查询速度慢
- HashMap;底层是哈希表,是一个线程不安全的集合,是多线程的集合,查询速度快
Properties
java.util
描述
- Properties 类是 Hashtable 的子类,该对象用于处理属性文件
- Xxx.properties 为Java 语言常见的配置文件,如数据库的配置 jdbc.properties
- 由于属性文件里的 key、value 都是字符串类型,所以 Properties 里的 key和 value 都是字符串类型
- 存取数据时,建议使用setProperty(String key,String value)方法和getProperty(String key)方法
方法
Object setProperty(String key, String value) 调用 Hashtable方法 put 。
Object get(Object key) 返回指定键映射到的值,如果此映射不包含键的映射,则返回 null 。
void load(InputStream inStream) 从输入字节流读取属性列表(键和元素对)。
Map集和的更多相关文章
- Java集合—Set集和Map集
一.Set集合 1.概述 Set集合无序的.不可重复的元素(无序是指索引) Set集合不按照特定的方法进行排序,只是将元素放在集合中. 下面介绍一下Set集合的HashSet和TreeSet两个实现类 ...
- Project Euler 103:Special subset sums: optimum 特殊的子集和:最优解
Special subset sums: optimum Let S(A) represent the sum of elements in set A of size n. We shall cal ...
- 使用map端连接结合分布式缓存机制实现Join算法
前面我们介绍了MapReduce中的Join算法,我们提到了可以通过map端连接或reduce端连接实现join算法,在文章中,我们只给出了reduce端连接的例子,下面我们说说使用map端连接结合分 ...
- ceph之crush map
编辑crush map: 1.获取crush map: 2.反编译crush map: 3.至少编辑一个设备,桶, 规则: 4.重新编译crush map: 5.重新注入crush map: 获取cr ...
- es6重点笔记:Symbol,Set,Map,Proxy,Reflect
一,Symbol 原始数据类型,不是对象,它是JavaScript第七种数据类型,表示独一无二的值.Symbol是通过Symbol函数生成的: let s = Symbol(); typeof s / ...
- [TensorFlow 团队] TensorFlow 数据集和估算器介绍
发布人:TensorFlow 团队 原文链接:http://developers.googleblog.cn/2017/09/tensorflow.html TensorFlow 1.3 引入了两个重 ...
- 带你深入理解STL之Set和Map
在上一篇博客带你深入理解STL之RBTree中,讲到了STL中关于红黑树的实现,理解起来比较复杂,正所谓前人种树,后人乘凉,RBTree把树都种好了,接下来就该set和map这类关联式容器来" ...
- 机器学习入门-贝叶斯中文新闻分类任务 1. .map(做标签数字替换) 2.CountVectorizer(词频向量映射) 3.TfidfVectorizer(TFDIF向量映射) 4.MultinomialNB()贝叶斯模型构建
1.map做一个标签的数字替换 2.vec = CountVectorizer(lowercase=False, max_features=4000) # 从sklean.extract_featu ...
- scala编程第17章学习笔记(2)——集和映射
默认情况下在使用“Set”或“Map”的时候,获得的都是不可变对象.如果需要的是可变版本,需要先写明引用. 如果同一个源文件中既要用到可变版本,也要用到不可变版本的集合或映射,方法之一是引用包含了可变 ...
随机推荐
- 得到、微信、美团、爱奇艺APP组件化架构实践
一.背景 随着项目逐渐扩展,业务功能越来越多,代码量越来越多,开发人员数量也越来越多.此过程中,你是否有过以下烦恼? 项目模块多且复杂,编译一次要5分钟甚至10分钟?太慢不能忍? 改了一行代码 或只调 ...
- Create Shortcut to Get Jar File Meta Information
You have to get meta information of cobertura.jar with command "unzip -q -c cobertura.jar META- ...
- Shell-14-常用命令和工具
常用命令 有人说 Shell 脚本是命令堆积的一个文件, 按顺序去执行 还有人说想学好 Shell 脚本,要把 Linux 上各种常见的命令或工具掌握了,这些说法都没错 Shell 语言本身在语法结构 ...
- 客户端连接mysql数据库反应慢
远程客户端连接MysqL数据库太慢解决方案 局域网客户端访问mysql 连接慢问题解决 编辑mysql配置文件 # vi my.conf [mysqld] skip-name-resolve 重启my ...
- 【笔记】初探KNN算法(3)
KNN算法(3) 测试算法的目的就是为了帮助我们选择一个更好的模型 训练数据集,测试数据集方面 一般来说,我们训练得到的模型直接在真实的环境中使用 这就导致了一些问题 如果模型很差,未经改进就应用在现 ...
- C# CS0050 可访问性不一致: 返回类型 错误
今天学习C#代码过程中,遇到可访问性不一致的错误: 严重性 代码 说明 项目 文件 行 禁止显示状态错误 CS0050 可访问性不一致: 返回类型"Transaction"的可访问 ...
- 那些shellcode免杀总结
首发先知: https://xz.aliyun.com/t/7170 自己还是想把一些shellcode免杀的技巧通过白话文.傻瓜式的文章把技巧讲清楚.希望更多和我一样web狗也能动手做到免杀的实现. ...
- noip 模拟 6
果然考试一多就改不过来了 考试经过 上来看题,T1似乎是一个计数题,但看见1e9的数据范围就觉得不可做,拿了20部分分匆忙跑路 T2是个图论题,不过一看统计种类就发现是自己不会的东西,瞄准30分冲了一 ...
- 题解—P2218 [HAOI2007]覆盖问题
一道不错的题,主要就是一个思路点,想到就行了,想不到就一直卡着. 看完题解之后发现挺简单,实际上自己挣扎半天也咩有想到. 一开始想类比成一维之后贪心,后来被同机房大佬 \(hack\) 掉了. sol ...
- 如果服务器数据更新了,CDN的数据是怎么及时更新的
A:cdn一般用来存静态资源.拿网站来说,当用户访问网站时静态资源从cdn加载.cdn向后段源服务器请求资源并缓存,这个请求过程是周期性的,自动的,称为回源. 当你更新了一个文件,现在正巧还没到cdn ...