SpringCloud升级之路2020.0.x版-18.Eureka的客户端核心设计和配置

本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford

Eureka 客户端配置就是访问 Eureka Server 的客户端相关配置,包括 Eureka Server 地址的配置,拉取服务实例信息相关配置,当前实例注册相关配置和 http 连接相关配置。在 Spring Cloud 中,Eureka 客户端配置以 eureka.client 开头,对应配置类为 EurekaClientConfigBean
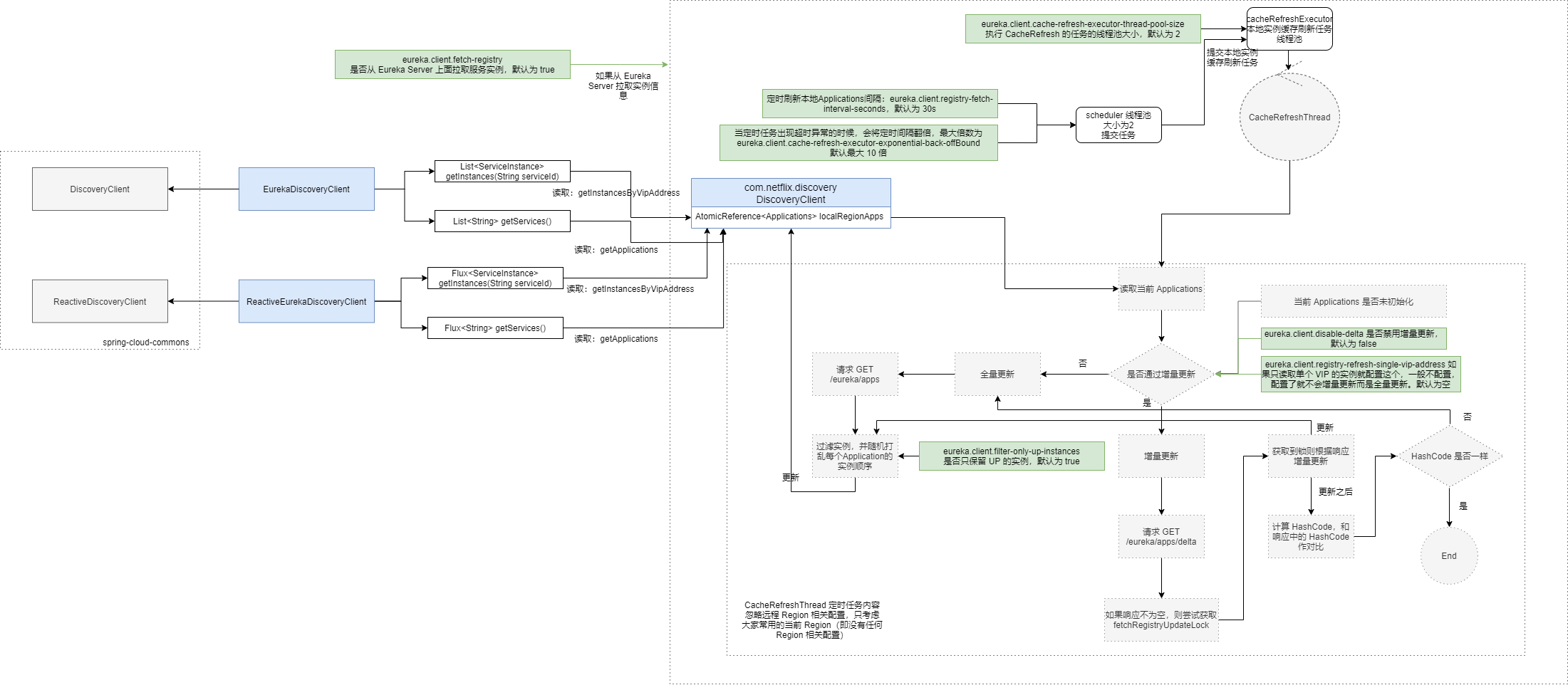
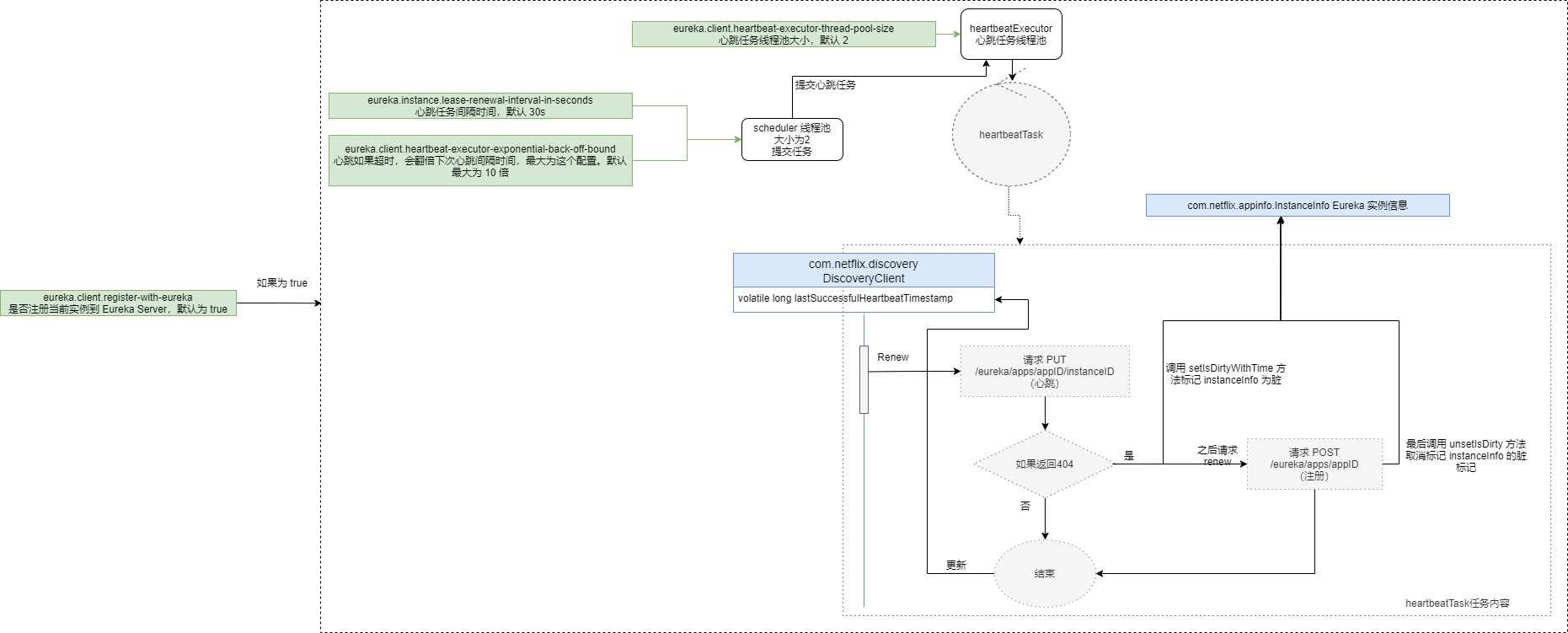
其中,Eureka 客户端有三个比较重要的定时任务,以及相关配置,这里用图的方式给大家展示出来了:
读取服务实例相关流程:
定时检查实例信息以及实例状态并同步到 Eureka Server:

定时心跳相关流程:

可以直接指定 Eureka Server 的地址,并且,这些配置可以动态修改,并且可以配置刷新时间。例如:
eureka:
client:
service-url:
# 默认eureka集群,这里必须是defaultZone,不能用-替换大写,与其他的配置不一样,因为实在EurekaClientConfigBean里面写死的
defaultZone: http://127.0.0.1:8211/eureka/
zone1: http://127.0.0.1:8212/eureka/
zone2: http://127.0.0.1:8213/eureka/
zone3: http://127.0.0.1:8214/eureka/
# 如果上面 eureka server 地址相关配置更新了,多久之后会重新读取感知到
eureka-service-url-poll-interval-seconds: 300
也可以通过 DNS 获取 Eureka Server,例如:
eureka:
client:
# 是否使用 dns 获取,如果指定了则通过下面的 dns 配置获取,而不是上面的 service-url
use-dns-for-fetching-service-urls: true
# dns 配置
# eureka-server-d-n-s-name: eureka.com
# dns 配置的 eureka server 的 port
# eureka-server-port: 80
# dns 配置的 eureka server 的 port 后面的 uri 前缀 context
# eureka-server-u-r-l-context: /eureka
同时,可能有不同的 Eureka Server 部署在不同的可用区域(zone)上,这里也可以配置 Eureka Client 的 zone 配置:
eureka:
client:
# 可用区列表,key 为 region,value 为 zone
availability-zones:
region1: zone1, zone2
region2: zone3
# 所在区域,通过这个读取 availability-zones 获取 zone,然后通过 zone 读取 service-url 获取对应的 eureka url
# 这里的逻辑对应的类是 ConfigClusterResolver 和 ZoneAffinityClusterResolver
region: region1
# 如果设置为 true,则同一个 zone 下的 eureka 会跑到前面优先访问。默认为 true
prefer-same-zone-eureka: true

我们可以配置是否从 Eureka 上面拉取服务实例信息,一般本地测试的时候,可能我们不想使用 Eureka 上面的注册实例的信息,就可以通过这个配置禁用 Eureka Client 从 Eureka 上面获取微服务实例信息。
eureka:
client:
# 是否从 eureka 上面拉取实例
fetch-registry: true
拉取服务实例信息的请求,也是可以配置是拉取压缩信息还是完整信息,以及是否通过增量拉取获取实例信息。Eureka 增量拉取机制实现很简单,就是新注册或者淘汰的实例会放入最近修改队列,队列中的信息会作为增量拉取的响应返回。增量拉取可能会丢失某些实例的更新,但是节省网络流量,在网络不好的情况下可以使用增量拉取。增量拉取中有版本控制,如果版本有差异,还是会通过全量拉取,之后再进行增量拉取。
eureka:
client:
# 是否禁用增量拉取,如果网络条件不好,可以禁用,每次都会拉取全量。增量拉取中有版本控制,如果版本有差异,还是会通过全量拉取,之后再进行增量拉取。
disable-delta: false
# 客户端请求头指定服务端返回的实例信息是压缩的信息还是完整信息,默认是完整信息
# full, compact
client-data-accept: full
# 针对增量拉取,是否每次都日志差异
log-delta-diff: true
拉取后的实例会被保存到本地缓存中,本地缓存具有过期时间:
eureka:
client:
# eureka client 刷新本地缓存时间
# 默认30s
registry-fetch-interval-seconds: 5
# 只保留状态为 UP 的实例,默认为 true
filter-only-up-instances: true
# eureka client 刷新本地缓存(定时拉取 eureka 实例列表)线程池大小,默认为 2
cache-refresh-executor-thread-pool-size: 2
# eureka client 刷新本地缓存(定时拉取 eureka 实例列表)线程池任务最大延迟时间,这个配置是定时拉取任务延迟(registry-fetch-interval-seconds)的倍数,默认 10 倍
cache-refresh-executor-exponential-back-off-bound: 10
同时,在 Spring Cloud 环境中,只要是基于 spring-cloud-commons 的微服务实现(其实所有 Spring Cloud 实现都是基于这个实现的),服务发现的 Client: DiscoveryClient(同步环境) 与 ReactiveDiscoveryClient(异步环境)都是使用的 Composite 的实现,也就是内部有多种服务发现 Client,服务发现按照一定顺序调用每一个服务发现 Client,这里也可以配置 Eureka Client 的顺序。
eureka:
client:
#在spring cloud 环境中,DiscoveryClient 用的其实都是 CompositeDiscoveryClient,这个 CompositeDiscoveryClient 逻辑其实就是多个 DiscoveryClient 共存,先访问一个,没找到就通过下一个寻找
#这个order决定了顺序,默认为 0
order: 0

我们在本地测试的时候,可能不想将本地这个实例注册到 Eureka Server 上面,这也是可以配置的:
eureka:
client:
# 是否将自己注册到 eureka 上面
register-with-eureka: true
同时,Eureka 本身的设计中,Eureka 实例信息以及配置是可以改变的,那么多久会同步到 Eureka Server 上呢?注意这个和心跳请求不一样,这个是可以单独配置的:
eureka:
client:
# 实例信息同定时同步到 Eureka Server 的间隔时间。每隔这么长时间,检查实例信息(即eureka.instance配置信息)是否发生变化,如果发生变化,则同步到 Eureka Server,默认 30s
# 主要检查两类信息,分别是服务地址相关信息,以及服务过期时间与刷新时间配置信息
instance-info-replication-interval-seconds: 30
# 实例信息同定时同步到 Eureka Server 的初始延迟时间,默认 40s
initial-instance-info-replication-interval-seconds: 40
还有一些其他配置我们可能也用的到:
eureka:
client:
# 是否在初始化的时候就注册到 eureka,一般设置为 false,因为实例还不能正常提供服务
should-enforce-registration-at-init: false
# 是否在关闭的时候注销实例,默认为 true
should-unregister-on-shutdown: true
# 是否对于实例状态改变更新进行限流,默认为 true
on-demand-update-status-change: true

Eureka Client 基于 Http 请求获取服务实例信息,这里可以针对 Http 客户端进行配置:
eureka:
client:
# 代理相关配置
# proxy-host:
# proxy-port:
# proxy-user-name:
# proxy-password:
# 是否对于发往 Eureka Server 的 http 请求启用 gzip,目前已经过期了,只要 Eureka Server 启用了 gzip,请求就是 gzip 压缩的
g-zip-content: true
# httpclient 的链接超时,默认 5s
eureka-server-connect-timeout-seconds: 5
# httpclient 的读取超时,默认 5s
eureka-server-read-timeout-seconds: 8
# httpclient 的空闲连接超时,默认 30s
eureka-connection-idle-timeout-seconds: 30
# httpclient 的总连接数量,默认 200
eureka-server-total-connections: 200
# httpclient 的每个 host 的连接数量
eureka-server-total-connections-per-host: 50
# tls 相关配置,默认没有启用
# tls:
# enabled: false
# key-password:
# key-store:
# key-store-password:
# key-store-type:
# trust-store:
# trust-store-password:
# trust-store-type:

我们这一节详细分析了 Eureka 的客户端配置。下一节,我们将开始分析 Eureka Server 相关的配置。
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

SpringCloud升级之路2020.0.x版-18.Eureka的客户端核心设计和配置的更多相关文章
- SpringCloud升级之路2020.0.x版-19.Eureka的服务端设计与配置
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford Eureka Se ...
- SpringCloud升级之路2020.0.x版-16.Eureka架构和核心概念
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford Eureka 目前 ...
- SpringCloud升级之路2020.0.x版-3.Eureka Server 与 API 网关要考虑的问题
本系列为之前系列的整理重启版,随着项目的发展以及项目中的使用,之前系列里面很多东西发生了变化,并且还有一些东西之前系列并没有提到,所以重启这个系列重新整理下,欢迎各位留言交流,谢谢!~ 之前我们提到了 ...
- SpringCloud升级之路2020.0.x版-37. 实现异步的客户端封装配置管理的意义与设计
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 为何需要封装异步 HTTP 客户端 WebClient 对于同步的请求,我们使用 spri ...
- SpringCloud升级之路2020.0.x版-17.Eureka的实例配置
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford 上一节我们提到过, ...
- SpringCloud升级之路2020.0.x版-1.背景
本系列为之前系列的整理重启版,随着项目的发展以及项目中的使用,之前系列里面很多东西发生了变化,并且还有一些东西之前系列并没有提到,所以重启这个系列重新整理下,欢迎各位留言交流,谢谢!~ Spring ...
- SpringCloud升级之路2020.0.x版-41. SpringCloudGateway 基本流程讲解(1)
本系列代码地址:https://github.com/JoJoTec/spring-cloud-parent 接下来,将进入我们升级之路的又一大模块,即网关模块.网关模块我们废弃了已经进入维护状态的 ...
- SpringCloud升级之路2020.0.x版-6.微服务特性相关的依赖说明
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford spring-cl ...
- SpringCloud升级之路2020.0.x版-10.使用Log4j2以及一些核心配置
本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford 我们使用 Log4 ...
随机推荐
- 2013年第四届蓝桥杯C/C++程序设计本科B组省赛 第39级台阶
题目描述: 第39级台阶 小明刚刚看完电影<第39级台阶>,离开电影院的时候,他数了数礼堂前的台阶数,恰好是39级! 站在台阶前,他突然又想着一个问题: 如果我每一步只能迈上1个或2个台阶 ...
- 『心善渊』Selenium3.0基础 — 23、Selenium元素等待
目录 1.什么是元素等待 2.为什么要设置元素等待 3.Selenium中常用的等待方式 4.强制等待 5.隐式等待 (1)隐式等待介绍 (2)示例 6.显式等待 (1)显式等待介绍 (2)语法 (3 ...
- docker挂载数据卷
1.Docker中的数据可以存储在类似于虚拟机磁盘的介质中,在Docker中称为数据卷,简单的理解就是将数据持久化的工具. 2.在使用docker容器的时候,会产生一系列的数据文件,这些数据文件在我们 ...
- Charles使用笔记001
一.抓电脑的请求 Proxy-->勾选Windows Proxy 二.Charles 拦截原理 三.Charles 拦截修改数据 选择一个链接-->右键-->勾选Breakpoint ...
- 一、Java预科学习
1.1.什么是计算机 计算机(computer)俗称电脑,是现代一种用于高速计算的电子计算机器,可以进行数值计算,又可以进行逻辑计算,还具有存储记忆功能.是能够按照程序运行,自动.高速处理海量数据的现 ...
- File类与常用IO流第九章——转换流
第九章.转换流 字节编码和字符集 编码:按照某种规则将字符以二进制存储到计算机中. 解码:将存储在计算机中的二进制数按照某种规则解析显示出来. 字符编码:Character Encoding ,就是一 ...
- 微信小程序云开发-云函数-云函数实现数据的查询、修改和删除功能
一.云函数获取商品信息 1.创建云函数getData,云函数功能:获取商品信息 2.在本地小程序页面调用云函数getData 二.云函数修改商品信息 1.创建云函数updateData,云函数功能: ...
- pytest框架
1.添加日志 import logging logging.debug('This is debug message') logging.info('This is info message') lo ...
- Flask 之linux部署
1.装python > `[root ~]# yum install gcc [root ~]# wget https://www.python.org/ftp/python/3.6.5/Pyt ...
- Python 数值中的下划线是怎么回事?
花下猫语:Python 中下划线的用法令人叹为观止,相信你已在各种文章或教程中见识过了.在 2016 年的 3.6 版本之后,Python 还引入了一种新的语法,使得下划线也可以出现在数值中.这篇翻译 ...