基于sinc的音频重采样(二):实现
上篇(基于sinc的音频重采样(一):原理)讲了基于sinc方法的重采样原理,并给出了数学表达式,如下:
 (1)
(1)
本文讲如何基于这个数学表达式来做软件实现。软件实现的细节很多,这里主要讲核心部分。函数srcUD()和filterUD()就是实现的主要函数(这两个函数是在源码基础上作了一定的改动,核心思想没变)。srcUD()是实现一帧中点的重采样,一个点一个点的做。filterUD()被srcUD()调用。数学表达式就体现在函数filterUD()里。粗看肯定会懵,怎么也跟上面的数学表达式联系不起来。下面就讲讲实现细节,让代码和数学表达式联系起来。
先看函数srcUD( ),下图是其实现,是将一帧中原采样点的值转换成新的采样率下的值,图中对输入参数的意思已做了解释。
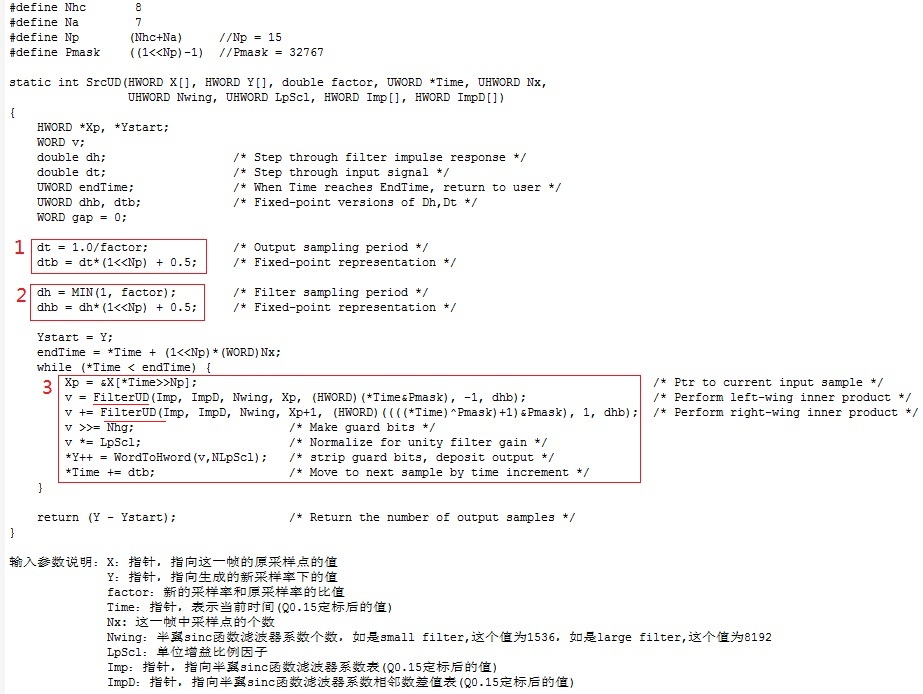
主要看3个细节。标1的红框处是算新的采样率下两个点之间的采样间隔。设定Tx为原采样率下的采样间隔,Ty为新的采样率下的采样间隔,factor = Tx / Ty,所以 Ty = Tx / factor。软件实现时对采样间隔做归一化处理,设定Tx = 1,即原采样点x(n)的采样间隔归一化到1,则新采样点y(m)的采样间隔为Ty = 1/factor。把采样间隔用Q0.15的定标表示,所以原采样率下的采样间隔为32768,新的采样率下的采样间隔是dtb = dt *(1 << Np) +0.5 (加上0.5是做四舍五入)。标2的红框处是算数学表达式1中的D。D = A = min(1, factor) = 代码中的dh,同dtb,再用Q0.15定标就是dhb。标3的红框处是具体算生成的新采样率下的点的值。这一帧开始时间是*Time,原采样率下采样点间隔已归一化为1,定标后变成了32768,帧内有Nx个点,所以这帧的结束时间是endTime = *Time + (1<<Np)*(WORD)Nx。每生成一个新的采样率下的点后时间就会向后移动一个新的采样率下的采样间隔(即dtb)开始算新的采样点的值,直到时间超过了endTime。算每个新的采样点时先要找到它对应的数学表达式中的x(Km),即对时间取整,代码中就是Xp = &X[*Time>>Np],这里Xp就是对应的x(Km)。(*Time&Pmask) 就是算Δm。算重采样后的一个新产生的点的值时,先算左翼(left wing)的值,再算右翼(right wing)的值,然后两个值相加就得到了这个新的采样点的值了。关于左右半翼,下文算sinc函数值时会讲。算左右半翼值的函数是一样的,即filterUD()。先看看怎么把算左右半翼的值用一个函数表示的。回到上面的数学表达式1,假设sinc函数左右都取hend个过零点,上式就变成了
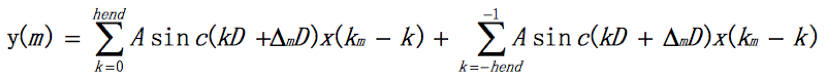
可以看出把计算变成了两部分相加,前半部分是左翼,后半部分是右翼,即:
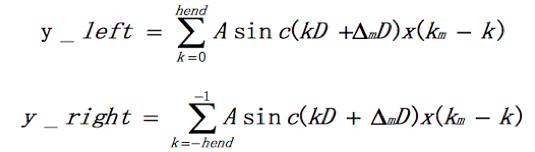
所以y(m) = y_left + y_right。着重看右翼。令i=k+1,则
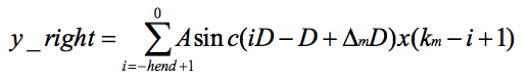
再令i = -i,则
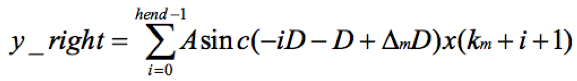
由于sinc函数是偶对称函数,即sinc(-x) = sinc(x)。所以上式变成
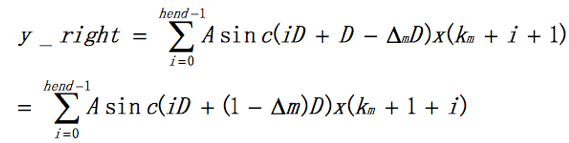
为了公式统一,令 Δ′m= 1 - Δm,i=k,则

再看y_left的表达式:

可以看出计算左右两翼的表达式统一了,只是传给函数的参数有差异。
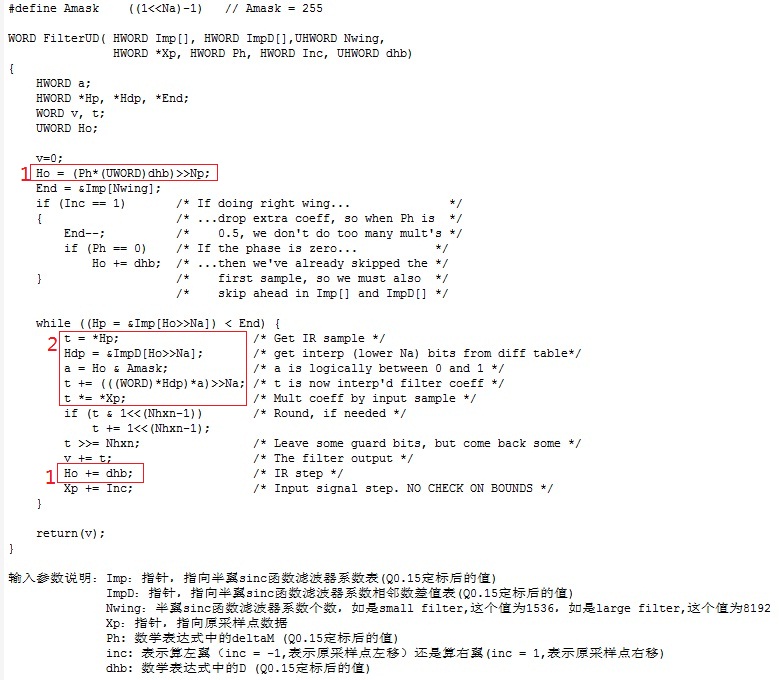
再来看函数filterUD( ),下图是其实现,是生成新的采样率下的一个点的半翼的值,图中对输入参数的意思已做了解释。
再看上面的数学表达式1。在式子中,有变量Km和Δm,当新旧采样率以及m确定时它们就是已知变量,在原理篇中讲过它们的求法。y(m)是A、sinc((k+Δm)D)和x(km - k)的乘累加,A和x(km - k)均很容易得到,唯独sinc((k+Δm)D)需要计算求出。下面看怎么求sinc((k+Δm)D)。
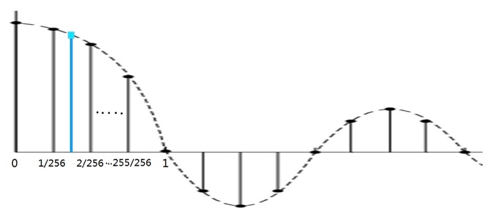
为了减少计算量,求sinc函数值通常采用查表的方法,即先做好表,使用时根据索引查表得到函数值。sinc函数是连续的,计算机处理时要先变成离散的。sinc函数是偶函数,关于Y轴对称,右半轴(或叫右翼,right wing)的值得到了,左半轴(或叫左翼,left wing)的值也就得到了。这样也就减小了表的大小(表的大小减为一半)。在右翼中,对每个过零点之间做256次采样,就得到了sinc函数值的离散表示。以从0到第一个过零点为例,256均分X轴从0到1的函数值,如下图:

可以根据原理篇中sinc函数的表达式算出每个采用点上的函数值,具体如下:

类似的可以算出右轴的每两个过零点之间的样本的函数值。如果截断后右翼共有6个过零点,则表中共有1536(1536 = 256 * 6)个值,分别为(1,0.99997458,0999989969, ........),把这些值叫做sinc函数滤波器系数。开源实现中分small filter和large filter两个表,两个表中过零点之间均是256采样,但small filter是6个过零点,表中共1536个值,而large filter是32个过零点,表中共8192个值。由于用了更多的sinc函数值和原采用率下的样本值,large filter的效果更好,同时运算量也大好多。具体使用时需要评估用哪个表。
sinc函数的表做好了,但是sinc((k+Δm)D)中的(k+Δm)D有可能不落在那些离散的样本上,即(k+Δm)D不等于1/256、2/256等,而是落在两个样点之间,例如落在1/256和2/256之间的蓝点,如下图:
这时的sinc函数值怎么求呢?软件实现中用了线性插值法。线性插值是一种针对一维数据的插值方法,它根据一维数据序列中需要插值的点的左右邻近两个数据点来进行数值的估计。它是根据到这两个点的距离来分配它们的比重的。如下图:
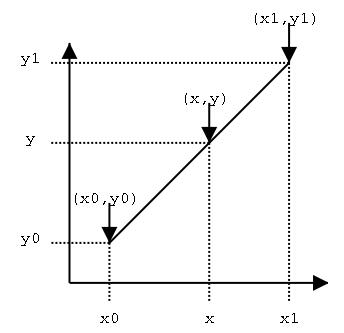
已知点(x0,y0)、(x1,y1),如果在x处插值,则y的值可用下式求出:
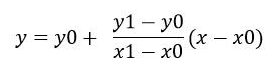 (2)
(2)
这样sinc函数值就求出来了。
算sinc函数值的表是浮点的,为了减少运算时的load,需要将浮点数定点化,即用Q格式表示。用Q0.15给表做定点化,表就变成了(32767,32766,……..),即代码中的数组Imp(实现中也把两个相邻的样本的Y值的差(即2式中的y1-y0)做成了表,即数组ImpD。这样处理减少了运算,属于典型的用空间换时间)。相应的其他浮点数的值也要做定点化,如Δm。sinc的横轴值x也要做定点化,也是用的Q0.15,这样第一个过零点的值定点化后就变为了32768。sinc函数两个过零点之间共256个样本,所以样本的间隔是128(32768 / 256 = 128),即2式中的x1-x0的值。x除以128(即右移7位)就可算出落在哪两个样本之间。x & 128表示与相邻左样本的距离,即2式中的x-x0的值。y0也是定点化后的值,根据2式,落在两个样本之间的sinc的定点化后的值也就得到了。
现在看代码中的实现细节。标1的红框处是算Δm*D(Ho = (Ph*(UWORD)dhb)>>Np)以及每次加上D后的值(Ho += dhb)。不管是算左翼还是右翼的值,从表达式看出k都是从0开始,所以sinc(k*D + Δm*D)的第一个值是sinc(Δm*D),即k=0时的值Ho。后面经过一个原采样点,即k加1,Ho就会加上D(即dhb)得到一个新的k*D + Δm*D。标2的红框处,Ho>>Na(即Ho右移7位)可知落在哪两个sinc样本之间,*Hp = Imp[Ho>>Na]表示左边的样本的值,即表达式2中的y0的值。同样*Hdp = ImpD[Ho>>Na]表示左右两边样本的差值,即表达式2中的y1-y0的值。a = Ho & Amask 表示与相邻左样本的距离,即x-x0。上面说过定标后两个样本之间的间隔是128,即x1-x0的值是128,代码中表现出来就是右移7位(>>Na)。所以(*Hdp)*a)>>Na就表示(y1-y0)*(x-x0)/(x1-x0)。t = *Hp表示想要求的值左边的样本,即y0,因而t += (((WORD)*Hdp)*a)>>Na就是实现了表达式2,sinc函数值就求出来了。再乘以相对应的原采样点(即t *= *Xp)就得到了sinc(k*D + Δm*D)*x(km -k)的值。算好一个值后Ho会加上D,原采样点也会左移或右移一个,从而算下一个值,直到sinc样本的结束处。把这些算好的值加起来就是半翼的值了,再把左右半翼的值加起来就得到了新采样率下的一个点的值了。
把函数srcUD()和filterUD()搞明白了基于sinc重采样的软件实现就好理解了。
基于sinc的音频重采样(二):实现的更多相关文章
- 基于sinc的音频重采样(一):原理
我在前面的文章<音频开源代码中重采样算法的评估与选择>中说过sinc方法是较好的音频重采样方法,缺点是运算量大.https://ccrma.stanford.edu/~jos/resamp ...
- 基于傅里叶变换的音频重采样算法 (附完整c代码)
前面有提到音频采样算法: WebRTC 音频采样算法 附完整C++示例代码 简洁明了的插值音频重采样算法例子 (附完整C代码) 近段时间有不少朋友给我写过邮件,说了一些他们使用的情况和问题. 坦白讲, ...
- FFmpeg(11)-基于FFmpeg进行音频重采样(swr_init(), swr_convert())
一.包含头文件和库文件 修改CMakeLists # swresample add_library(swresample SHARED IMPORTED) set_target_properties( ...
- 简洁明了的插值音频重采样算法例子 (附完整C代码)
近一段时间在图像算法以及音频算法之间来回游走. 经常有一些需求,需要将音频进行采样转码处理. 现有的知名开源库,诸如: webrtc , sox等, 代码阅读起来实在闹心. 而音频重采样其实也就是插值 ...
- 基于RNN的音频降噪算法 (附完整C代码)
前几天无意间看到一个项目rnnoise. 项目地址: https://github.com/xiph/rnnoise 基于RNN的音频降噪算法. 采用的是 GRU/LSTM 模型. 阅读下训练代码,可 ...
- FFmpeg进行视频帧提取&音频重采样-Process.waitFor()引发的阻塞超时
由于产品需要对视频做一系列的解析操作,利用FFmpeg命令来完成视频的音频提取.第一帧提取作为封面图片.音频重采样.字幕压缩等功能: 前一篇文章已经记录了FFmpeg在JAVA中的使用-音频提取&am ...
- FFMpeg音频重采样和视频格式转
一.视频像素和尺寸转换函数 1.sws_getContext : 像素格式上下文 --------------->多副图像(多路视频)进行转换同时显示 2.struct SwsContext ...
- 最简单的基于FFMPEG的音频编码器(PCM编码为AAC)
http://blog.csdn.net/leixiaohua1020/article/details/25430449 本文介绍一个最简单的基于FFMPEG的音频编码器.该编码器实现了PCM音频采样 ...
- Linux -- 基于zookeeper的java api(二)
Linux -- 基于zookeeper的java api(二) 写一个关于基于集群的zookeeper的自定义实现HA 基于客户端和监控器:使用监控的方法查看每个注册过的节点的状态来做出操作. Wa ...
随机推荐
- 详解支付体系颠覆者NGK公链:如何通过呼叫河马智能合约加速转账?
纵观全球加密货币市场,至今为止,全球已经发行的加密货币以及数字代币的数量已经超过了7000种,且未来还将会有更多的加密货币或数字代币出现.在众多加密货币项目中,投资者很难在众多的项目里甄别项目的好坏以 ...
- 不使用的大对象为什么要手动设置null,真的有效吗?
本文转载自不使用的大对象为什么要手动设置null,真的有效吗? 导语 在我们开发过程中,对于大的对象使用过后,为了help gc ,我们会手动将大对象置为null,背后的原理是什么,是不是最佳的实践. ...
- 别再人云亦云了!!!你真的搞懂了RDD、DF、DS的区别吗?
几年前,包括最近,我看了各种书籍.教程.官网.但是真正能够把RDD.DataFrame.DataSet解释得清楚一点的.论据多一点少之又少,甚至有的人号称Spark专家,但在这一块根本说不清楚.还有国 ...
- react新手入坑
1.vscode保存react项目的时候由于js-css-html插件格式化代码导致react代码缩进错误 解决方法:禁用js-css-html插件 2.react和vue不同,react方法的定义需 ...
- yum install valgrind.x86_64
Reference: https://cloudlinux.zendesk.com/hc/en-us/articles/115004075294-Fix-rpmdb-Thread-died-in-Be ...
- 基于docker搭建jenkins
一.概述 Jenkins 的前身是 Hudson 是一个可扩展的持续集成引擎.Jenkins 是一款开源 CI&CD 软件,用于自动化各种任务,包括构建.测试和部署软件.Jenkins 支持各 ...
- MySql_176. 第二高的薪水 + limit + distinct + null
MySql_176. 第二高的薪水 LeetCode_MySql_176 题目描述 题解分析 代码实现 # Write your MySQL query statement below select( ...
- 记离线部署docker,以及docker下部署zabbix
一.离线安装docker 下载地址:https://download.docker.com/linux/static/stable/x86_64/ 上传软件并解压 [root@localhost op ...
- 通达OA任意文件上传+文件包含GetShell/包含日志文件Getshell
0x01 简介 通达OA采用基于WEB的企业计算,主HTTP服务器采用了世界上最先进的Apache服务器,性能稳定可靠.数据存取集中控制,避免了数据泄漏的可能.提供数据备份工具,保护系统数据安全.多级 ...
- python获取到本机的公网IP
5行代码获取到本机的公网IP from urllib.request import urlopen import re text = str(urlopen("http://txt.go.s ...