搭建Hadoop集群 (一)
上面讲了如何搭建Hadoop的Standalone和Pseudo-Distributed Mode(搭建单节点Hadoop应用环境), 现在我们来搭建一个Fully-Distributed Mode的Hadoop Cluster.
环境
虚拟机: VirtualBox 5
Server操作系统: CentOS-6.7-x86_64-LiveCD
Hadoop版本: 2.6.2
安装Linux虚拟机
安装虚拟机, 这里一共安装3台, hostname分别取名: master, slave1, slave2. 虚拟机网络采用Bridged Adapter.
master扮演NameNode和ResourceManager的角色. 如果你的硬件条件允许, 也可以单独为ResourceManager使用一台虚拟机, 组成masters虚拟机群.
slave则被用作DataNode和NodeManager.
创建hadoop专用账户
按照正常步骤安装系统, LiveCD版本可以在安装过程中, 直接创建新用户, 用户名设为hm, 作为hadoop的专用账户.
或者使用命令行新建hadoop用户和组, 并设置密码:
- [root@localhost /]# groupadd hadoop
[root@localhost /]# useradd -s /bin/bash -d /home/hm -m hm -g hadoop
[root@localhost /]# passwd hm
为hm添加sudoer权限
- [root@localhost /]# chmod u+w /etc/sudoers
[root@localhost /]# vi /etc/sudoers
[root@localhost /]# chmod u-w /etc/sudoers
在sudoers中修改:
- ## Allow root to run any commands anywhere
- root ALL=(ALL) ALL
- hm ALL=(ALL) ALL
- :x 保存退出
[root@localhost /]# chmod u-w /etc/sudoers
[root@localhost /]# reboot
修改HostName
以master机器为例:
- [hm@localhost ~]$ sudo vi /etc/hosts
为你的hostname映射正确的ip (ip根据你的ifconfig结果来定)
- 192.168.1.105 master
192.168.1.106 slave1
192.168.1.107 slave2
再把network中的hostname改成master
- [hm@master ~]$ sudo vi /etc/sysconfig/network
重启生效.
安装VirtualBox Guest Additions增强包(Optional - 推荐)
方便后续操作. (主机-虚机之间文件拖拽, 鼠标集成, 共享剪贴板等等)
首先确认Internet访问正常
如果你的网络有防火墙, 去左上角菜单中, System->Preferences->Network Proxy中设置.
同时, 把master, slave1, slave2加入到proxy的Ignored Hosts里面.
最后, 修改yum配置使得它能从网上下载安装包和相关依赖.
打开Terminal:
- [hm@master ~]# sudo vi /etc/yum.conf
添加: (无需用户名密码的话, 最后两行省略)
- # The proxy server - proxy server:port number
- proxy=http://yourproxy.yourdomain.com:yourport
- # The account details for yum connections
- proxy_username=yourusername
- proxy_password=yourpassword
安装VirtualBox增强包
点击Devices->Insert Guest Additions CD Image.. 双击光盘运行安装.
如果遇到安装Failed:
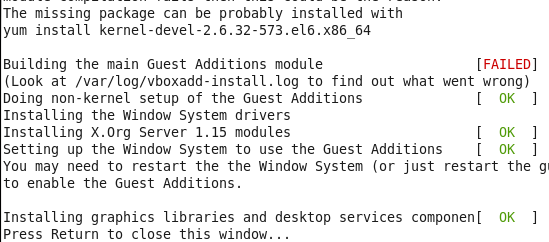
安装kernel-devel package(安装增强包需要用到它): 该package包含内核开发环境所需的内核头文件, 以及编译它们所需的Makefile. (CentOS6.7 LiveCD版, 以及某些RH发行版, 默认无附带)
- [hm@master ~]# sudo yum install kernel-devel-2.6.32-573.el6.x86_64 gcc
再次尝试安装增强包, 应该就能成功. (如果提示OpenGL Support Module Failed, 可忽略)
点击Devices->Shared ClipBoard和Drag and Drop, 设置成Bidirectional.
重启虚拟机. 则可以和主机共享剪贴板, 并且可以相互拖拽文件.
安装配置SSH和JAVA
安装软件包
首先确认是否已经有安装: (其中openssh-server只要确保master上有即可)
- [hm@master ~]$ rpm -qa | grep ssh
- [hm@master ~]$ rpm -qa | grep jdk
可以看到openssh的server和client都已经安装, 因此只需要安装jdk即可. (hadoop查看守护进程需要用到jdk里的jps命令, 需要openjdk的devel版本, 或者sun jdk)
- [hm@master ~]$ yum search openjdk
[hm@master ~]$ sudo yum install java-1.7.0-openjdk-devel.x86_64
查看一下安装目录, 记下来将来配置hdfs要用.
- [hm@master ~]$ rpm -ql java-1.7.0-openjdk-devel-1.7.0.95-2.6.4.0.el6_7.x86_64
得到jdk的绝对安装路径: /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.95.x86_64
Optional - 克隆创建slave1和slave2
先Power Off master虚拟机, 右键点选它, clone.
由于我们要让三台虚拟机在同一个网段运行, 推荐勾选Reinitialize the MAC address of all network cards. 如果不幸遇到网卡找不到或者不匹配, 需自己手动修改/etc/sysconfig/network-scripts/ifcfg-eth*. 具体自行谷歌.
Full Clone, 成功后启动slave虚拟机.
修改hosts和network两个文件, 参考上文.
这时输入ping master, ping slave1之类的命令, 应该相互可以通讯. (别忘记将slave的信息放入master的hosts文件中)
- 192.168.1.105 master
192.168.1.106 slave1
192.168.1.107 slave2
在master上启动SSH Server
检查ssh server的进程是否启动
- [hm@master ~]$ ps -e|grep sshd
如果没有, 手动启动该进程
- [hm@master ~]$ sudo /etc/init.d/sshd start
Optional - 设置sshd开机启动
先检查当前设置
- [hm@master ~]$ chkconfig --list sshd
- sshd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
设成开机启动
- [hm@master ~]$ sudo chkconfig sshd on
再次检查可以看到2-5项都变成on了.
设置master和slave1, slave2之间免密码SSH登录
单机免密码登录
主要目的是看看ssh是否正常工作
- [hm@master ~]$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[hm@master ~]$ cat .ssh/id_dsa.pub >> .ssh/authorized_keys
[hm@master ~]$ ssh localhost
成功登录后, 输入exit退出当前ssh登录. 以后再输入ssh localhost就可以直接无密码登录. 如果再次登录还需要密码, 尝试把authorized_keys权限改为600.
master免密码SSH登录slave
登录slave1, 把master的公钥拷贝到slave的authorized_keys中.
- [hm@slave1 ~]$ scp hm@master:~/.ssh/id_dsa.pub .ssh/master_dsa.pub
- [hm@slave1 ~]$ cat .ssh/master_dsa.pub >> .ssh/authorized_keys
用hm账户登录master, 输入ssh slave1, 首次连接后, 之后即可无密码访问slave1. 同理为slave2配置免密码访问.
到此, master-slave结构的虚拟机集群搭建完毕, 接下来开始安装Hadoop, 参见 搭建Hadoop集群 (二)
搭建Hadoop集群 (一)的更多相关文章
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- virtualbox 虚拟3台虚拟机搭建hadoop集群
用了这么久的hadoop,只会使用streaming接口跑任务,各种调优还不熟练,自定义inputformat , outputformat, partitioner 还不会写,于是干脆从头开始,自己 ...
- 搭建Hadoop集群 (三)
通过 搭建Hadoop集群 (二), 我们已经可以顺利运行自带的wordcount程序. 下面学习如何创建自己的Java应用, 放到Hadoop集群上运行, 并且可以通过debug来调试. 有多少种D ...
- 搭建Hadoop集群 (二)
前面的步骤请看 搭建Hadoop集群 (一) 安装Hadoop 解压安装 登录master, 下载解压hadoop 2.6.2压缩包到/home/hm/文件夹. (也可以从主机拖拽或者psftp压缩 ...
- Linux下搭建Hadoop集群
本文地址: 1.前言 本文描述的是如何使用3台Hadoop节点搭建一个集群.本文中,使用的是三个Ubuntu虚拟机,并没有使用三台物理机.在使用物理机搭建Hadoop集群的时候,也可以参考本文.首先这 ...
- Hadoop入门进阶步步高(五)-搭建Hadoop集群
五.搭建Hadoop集群 上面的步骤,确认了单机能够运行Hadoop的伪分布运行,真正的分布式运行无非也就是多几台slave机器而已,配置方面的有一点点差别,配置起来就很easy了. 1.准备三台se ...
- Linux 搭建Hadoop集群 成功
内容基于(自己的真是操作步骤编写) Linux 搭建Hadoop集群---Jdk配置 Linux 搭建Hadoop集群 ---SSH免密登陆 一:下载安装 Hadoop 1.1:下载指定的Hadoop ...
- 阿里云搭建hadoop集群服务器,内网、外网访问问题(详解。。。)
这个问题花费了我将近两天的时间,经过多次试错和尝试,现在想分享给大家来解决此问题避免大家入坑,以前都是在局域网上搭建的hadoop集群,并且是局域网访问的,没遇见此问题. 因为阿里云上搭建的hadoo ...
- 虚拟机搭建Hadoop集群
安装包准备 操作系统:ubuntu-16.04.3-desktop-amd64.iso 软件包:VirtualBox 安装包:hadoop-3.0.0.tar.gz,jdk-8u161-linux-x ...
随机推荐
- 查询最小未使用ID的SQL查询
--每个都加一,以此来找出最小的未用ID SELECT Min(T1.ID)+1 FROM dbo.TestTable T1 -- 不用查询已经存在的ID WHERE (T1.ID+1) NOT IN ...
- 此操作只能由 SQL Server 中拥有配置数据库读取权限的用户在已加入到某个服务器场的计算机上执行
错误提示:此操作只能由 SQL Server 中拥有配置数据库读取权限的用户在已加入到某个服务器场的计算机上执行.若要将此服务器连接到服务器场,请使用 SharePoint 产品配置向导,该向导可从 ...
- 20141112 WinForm子窗口标签页
(一)标签页 先看看效果: 代码: public partial class 标签页 : Form { string s = ""; public 标签页() { Initiali ...
- SQL Server执行计划那些事儿(2)——查找和扫描
接下来的文章是记录自己曾经的盲点,同时也透漏了自己的发展历程(可能发展也算不上,只能说是瞎混).当然,一些盲点也在工作和探究过程中慢慢有些眉目,现在也愿意发扬博客园的奉献精神,拿出来和大家分享一下. ...
- MJExtension
MJExtension 长话短说下面我们通过一个列子来看下怎么使用 1. 先把框架拉进去你的项目 2. 首先我这次用到的json最外层是一个字典,根据数据的模型我们可以把这个归类为字典中有数组,数组中 ...
- Django Url编码问题
Django Url编码问题 最近在学习Django,写一个blog程序练练手手.对于一个才开始接触web开发的来说,难免会遇到一些问题. 有一个这样的模板: {%for k,v in cat ...
- [一个经典的多线程同步问题]解决方案三:互斥量Mutex
本篇通过互斥量来解决线程的同步,学习其中的一些知识. 互斥量也是一个内核对象,它用来确保一个线程独占一个资源的访问.互斥量与关键段的行为非常相似,并且互斥量可以用于不同进程中的线程互斥访问资源.使用互 ...
- Android minHeight/Width,maxHeight/Width
在layout文件中,设置IamgeView的最大(最小)高度(宽度)时,需要同时设置android:adjustViewBounds="true",这样设置才会生效.在代码中设置 ...
- You have not agreed to the Xcode license.
You have not agreed to the Xcode license. Before running the installer again please agree to the lic ...
- chrome实现全浏览器跨域ajax请求
如图,在chrome快捷方式上打开属性栏,在‘目标’栏加上后缀--disable-web-security --user-data-dir.即可实现在此浏览器上所有网页的跨域请求.