Spark数据倾斜解决方案及shuffle原理
数据倾斜调优与shuffle调优
数据倾斜发生时的现象
1)个别task的执行速度明显慢于绝大多数task(常见情况)
2)spark作业突然报OOM异常(少见情况)
数据倾斜发生的原理
在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。以至于大部分task只需几分钟,而个别task需要几小时,导致整个task作业需要几个小时才能运行完成。而且如果某个task数据量特别大的时候,甚至会导致内存溢出的情况。
定位数据倾斜发生的位置
数据倾斜只会发生在shuffle过程中,因此我们要先确定数据倾斜发生在第几个stage中,我们可以通过Web UI来查看当前运行到了第一个stage,以及该stage中各个task分配的数据量,来确定是不是由数据分配不均导致的数据倾斜。
一旦确定数据倾斜是由数据分配不均导致,下一步就要确定数据倾斜发生在哪一个stage之后,根据代码中的shuffle算子,推算出stage与代码的对应关系,判定数据倾斜发生的位置。
数据倾斜的解决方案
1)使用Hive ETL预处理数据
适用场景:Hive里的源数据本身就不均匀,并且需要对Hive表频繁进行shuffle操作
解决方案:在Hive中预先对数据按照key进行聚合或是和其他表进行join,这样Spark处理的表就不是原来数据不均匀的表了
优点:在Hive中预先完成了数据的聚合操作,Spark中不再需要进行shuffle操作,完全规避了数据倾斜
缺点:只是让数据倾斜的问题提前发生了,预处理的速度还是很慢
2)过滤少数导致倾斜的key
适用场景:确定了导致数据倾斜的key只有少数几个,而且对数据计算本身的影响并不大
解决方案:使用sample算子对RDD进行采样,取出数据量最多的可以,在Spark SQL中使用where子句或是RDD中使用filter算子直接过滤掉这几个key
优点:实现简单,完全规避掉了数据倾斜
缺点:适用场景很少,不常见
3)提高shuffle操作的并行度
适用场景:数据倾斜不可避免,这是处理数据倾斜最简单的一种方案
解决方案:在对RDD执行shuffle算子时,给shuffle算子传入参数,设置shuffle read task的数量。Spark SQL中可以设置参数spark.sql.shuffle.partitions,该值默认是200,但对于很多场景来说比较小。或是在RDD的shuffle算子传入参数,比如reduceByKey(1000)
优点:实现简单,有效减轻数据倾斜带来的影响
缺点:效果有限,通常无法彻底解决数据倾斜的问题
4)两阶段聚合(局部+全局)
适用场景:在Spark SQL中使用group by进行分组或是在RDD中使用reduceByKey等聚合类操作时
解决方案:将原本相同的key通过附加随机前缀的方式,变成多个不同的key,让原本被一个task处理的数据分散到多个task上去做局部聚合。然后去掉随机前缀,做全局聚合。
优点:对于聚合类shuffle操作导致的数据倾斜,通常可以解决问题,将Saprk作业的性能提升数倍
缺点:仅仅适用于聚合类shuffle操作,适用范围较窄
5)将reduce join转为map join
适用场景:在进行join操作时,其中的一个RDD或表数据量较小
解决方案:不适用shuffle类算子的操作,而使用Broadcast变量与map类算子实现join操作,规避掉shuffle类操作。将较小的RDD中的算子通过collect算子拉取到Driver端,然后对其创建一个Broadcast变量。接着对另一个RDD执行map,获取Broadcast变量中的数据,通过比较key是否相同,将两个RDD进行连接
优点:避免了shuffle操作导致的数据倾斜
缺点:仅适用于一个大表和一个小表的情况,使用场景较少
6)采样倾斜key并分拆join操作
适用场景:在进行join操作时,两个RDD或表数据量都比较大,但是其中一个RDD或表数据量中的key比较均匀,另外一个RDD或表中只有少数几个key数据量过大
解决方案:对包含少数几个数据量过大的key的那个RDD,通过sample算子采样出一份样本,统计出数据量较大的几个key,将这几个key打上随机前缀,拆分出来形成一个单独的RDD,另外一个表中对于这几个key进行同样的操作,这两对RDD进行单独join,然后使用union算子进行合并
优点:对于join导致的数据倾斜,并且只是几个key所导致的,这个方案可以有效解决问题
缺点:无法解决导致倾斜的key过多的情况
7)使用随机前缀和扩容RDD进行join
适用场景:RDD中有大量导致数据倾斜的key
解决方案:与方案六相同,但是是对所有的数据打上随机前缀
优点:效果显著,对新跟那个提升效果明显
缺点:因为数据量大幅增加,对内存资源要求较高
总结
大多数Spark作业的性能主要就消耗在了shuffle环节,该环节包含了大量的磁盘IO、序列化、网络传输等操作。因此,想要让作业的性能更高,就要对shuffle过程进行调优。但是shuffle调优只是Spark性能优化的一小部分,最重要的还是在开发阶段,通过调节资源参数,尽量避免shuffle操作来对作业的性能进行优化,千万不要舍本逐末
Shuffle的原理
在Spark的源码中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。而随着Spark的版本的发展,ShuffleManager也在不断迭代,变得越来越先进。
在Spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager。HashShuffleManager有着一个非常严重的弊端,就是会产生大量的中间磁盘文件,进而有大量的磁盘IO操作影响了性能。
在Spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager,相较HashShuffleManager来说,有了一定的改进。主要就在于,每个Task在进行shuffle操作时,虽然也会产生较多的临时磁盘文件,但是最后会将所有的临时文件合并(merge)成一个磁盘文件,因此每个Task就只有一个磁盘文件。在下一个stage的shuffle read task拉取自己的数据时,只要根据索引读取每个磁盘文件中的部分数据即可。
未经优化的HashShuffleManager
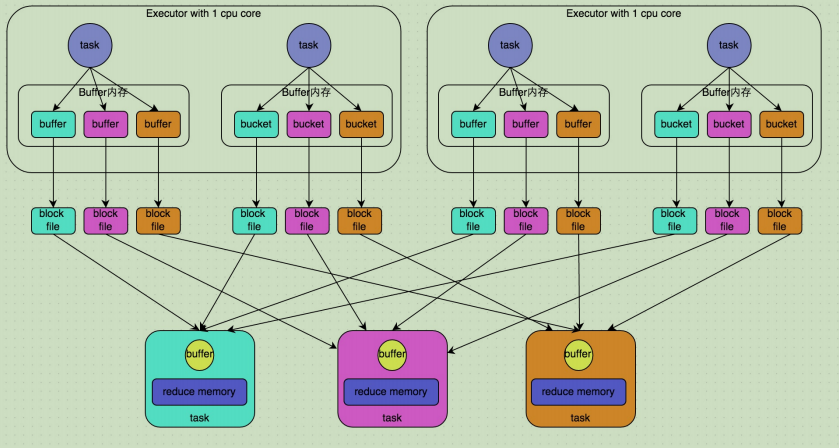
上图说明了未经优化的HashShuffleManager的原理。这里我们先明确一个假设前提:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间 都只能执行一个task线程。
我们先从shuffle write开始说起。shuffle write阶段,主要就是在一个stage结束计算之后,为 了下一个stage可以执行shuffle类的算子(比如reduceByKey),而将每个task处理的数据按key进行“分类”。所谓“分类”,就是对相同的key执行hash算法,从而将相同key都写入同一个磁盘文件中,而每一个磁盘文件都只属于下游stage的一个task。在将数据写入磁盘之前,会先将数据写入内存缓冲中,当内存缓冲填满之后,才会溢写到磁盘文件中去。那么每个执行shuffle write的task,要为下一个stage创建多少个磁盘文件呢?很简单,下一个stage的task有多少个,当前stage的每个task就要创建多少份磁盘文件。因此,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的。
接着我们来说说shuffle read。shuffle read,通常就是一个stage刚开始时要做的事情。此时该stage的每一个task就需要将上一个stage的计算结果中的所有相同key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行key的聚合或连接等操作。由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。shuffle read的拉取过程是一边拉取一边进行聚合的。每个shuffle read task都会有一个自己的buffer缓冲,每次都只能拉取与buffer缓冲相同大小的数据,然后通过内存中的一个Map进行聚合等操作。聚合完一批数据后,再拉取下一批数据,并放到buffer缓冲中进行聚合操作。以此类推,直到最后将所有数据到拉取完,并得到最终的结果。
优化后的HashShuffleManager
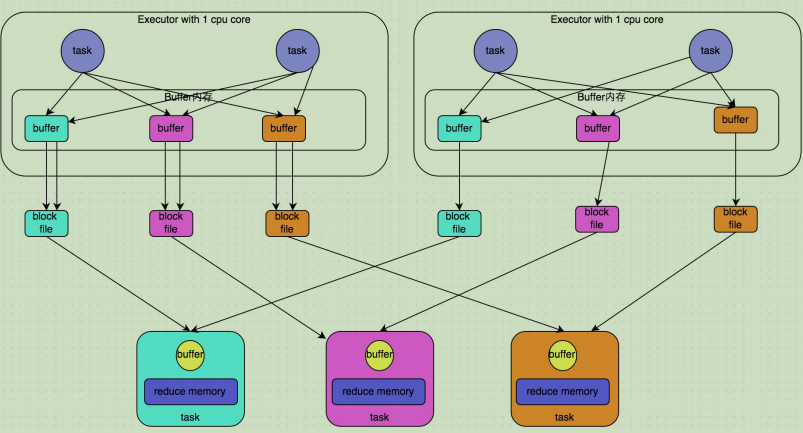
上图说明了优化后的HashShuffleManager的原理。这里说的优化,是指我们可以设置一个参数,spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。通常来说,如果我们使用HashShuffleManager,那么都建议开启这个选项。开启consolidate机制之后,在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概念,每个shuffleFileGroup会对应一批磁盘文件,磁盘文件的数量与下游stage的task数量是相同的,一个Executor上有多少个CPU core,就可以并行执行多少个task。而第一批并行执行的每个task都会创建一个shuffleFileGroup,并将数据写入对应的磁盘文件内。
当Executor的CPU core执行完一批task,接着执行下一批task时,下一批task就会复用之前已 有的shuffleFileGroup,包括其中的磁盘文件。也就是说,此时task会将数据写入已有的磁盘文件中,而不会写入新的磁盘文件中。因此,consolidate机制允许不同的task复用同一批磁盘文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
SortShuffleManager运行原理
SortShuffleManager的运行机制主要分成两种,一种是普通运行机制,另一种是bypass运行机制。当shuffle read task的数量小于等于spark.shuffle.sort.bypassMergeThreshold参数的值时(默认为200),就会启用bypass机制。
普通运行机制
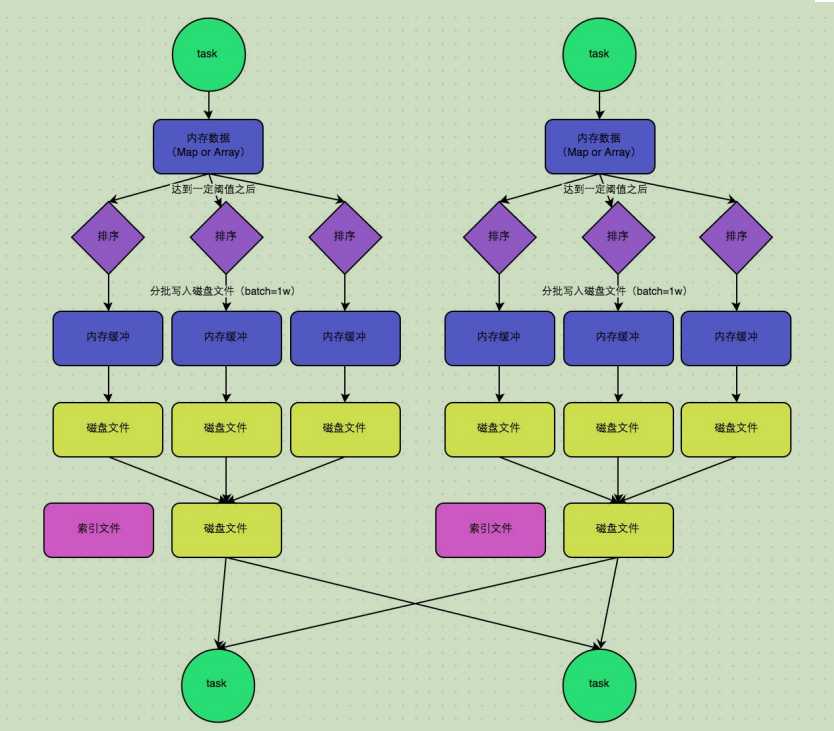
上图说明了普通的SortShuffleManager的原理。在该模式下,数据会先写入一个内存数据结构中,此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数据的形式分批写入磁盘文件。写入磁盘文件是通过Java的BufferedOutputStream实现的。BufferedOutputStream是Java的缓冲输出流,首先会将数据缓冲在内存中,当内存缓冲满溢之后再一次写入磁盘文件中,这样可以减少磁盘IO次数,提升性能。 一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个 临时文件。最后会将之前所有的临时磁盘文件都进行合并,这就是merge过程,此时会将之前所有临时磁盘文件中的数据读取出来,然后依次写入最终的磁盘文件之中。此外,由于一个task就只对应一个磁盘文件,也就意味着该task为下游stage的task准备的数据都在这一个文件中,因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
bypass运行机制
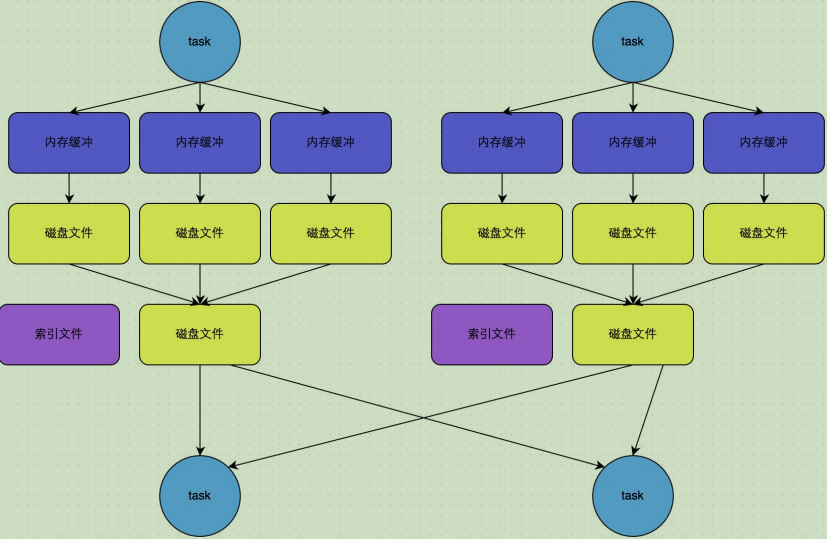
上图说明了bypass SortShuffleManager的原理。bypass运行机制的触发条件如下:* shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold参数的值。* 不是聚合类的shuffle算子(比如reduceByKey)。 此时task会为每个下游task都创建一个临时磁盘文件,并将数据按key进行hash然后根据key的hash值,将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲 写满之后再溢写到磁盘文件的。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并 创建一个单独的索引文件。 该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件,只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的HashShuffleManager来说,shuffle read的性能会更好。 而该机制与普通SortShuffleManager运行机制的不同在于:第一,磁盘写机制不同;第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作,也就节省掉了这部分的性能开销。
shuffle相关参数调优
spark.shuffle.file.buffer
//默认值32k
//该参数用于设置shuffle write task的BufferedOutputStream的buffer缓冲大小。将数据写
到磁盘文件之前,会先写入buffer缓冲中,待缓冲写满之后,才会溢写到磁盘。如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如64k),从而减少shuffle write过程中溢写磁盘文件的次数,也就可以减少磁盘IO次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.reducer.maxSizeInFlight
//默认值48m
//:该参数用于设置shuffle read task的buffer缓冲大小,而这个buffer缓冲决定了每次能够拉取多少数据。如果作业可用的内存资源较为充足的话,可以适当增加这个参数的大小(比如96m),从而减少拉取数据的次数,也就可以减少网络传输的次数,进而提升性能。在实践中发现,合理调节该参数,性能会有1%~5%的提升。
spark.shuffle.io.maxRetries
//默认值3
//shuffle read task从shuffle write task所在节点拉取属于自己的数据时,如果因为网络异常导致拉取失败,是会自动进行重试的。该参数就代表了可以重试的最大次数。如果在指定次数之内拉取还是没有成功,就可能会导致作业执行失败。对于那些包含了特别耗时的shuffle操作的作业,建议增加重试最大次数(比如60次),以避免由于JVM的full gc或者网络不稳定等因素导致的数据拉取失败。在实践中发现,对于针对超大数据量(数十亿~上百亿)的shuffle过程,调节该参数可以大幅度提升稳定性。
spark.shuffle.io.retryWait
//默认值5s
//具体解释同上,该参数代表了每次重试拉取数据的等待间隔,默认是5s。建议加大间隔时长(比如60s),以增加shuffle操作的稳定性。
spark.shuffle.memoryFraction
//默认值0.2
//该参数代表了Executor内存中,分配给shuffle read task进行聚合操作的内存比例,默认是
20%。在资源参数调优中讲解过这个参数。如果内存充足,而且很少使用持久化操作,建议调高这
个比例,给shuffle read的聚合操作更多内存,以避免由于内存不足导致聚合过程中频繁读写磁盘。在实践中发现,合理调节该参数可以将性能提升10%左右。
spark.shuffle.manager
//默认值sort
//该参数用于设置ShuffleManager的类型。Spark 1.5以后,有三个可选项:hash、sort和
tungsten-sort。HashShuffleManager是Spark 1.2以前的默认选项,但是Spark 1.2以及之后的版本默认都是SortShuffleManager了。tungsten-sort与sort类似,但是使用了tungsten计划中的堆外内存管理机制,内存使用效率更高。由于SortShuffleManager默认会对数据进行排序,因此如果你的业务逻辑中需要该排序机制的话,则使用默认的SortShuffleManager就可以;而如果你的业务逻辑不需要对数据进行排序,那么建议参考后面的几个参数调优,通过bypass机制或优化的HashShuffleManager来避免排序操作,同时提供较好的磁盘读写性能。这里要注意的是,tungsten-sort要慎用,因为之前发现了一些相应的bug。
spark.shuffle.sort.bypassMergeThreshold
//默认值200
//当ShuffleManager为SortShuffleManager时,如果shuffle read task的数量小于这个阈值
(默认是200),则shuffle write过程中不会进行排序操作,而是直接按照未经优化的HashShuffleManager的方式去写数据,但是最后会将每个task产生的所有临时磁盘文件都合并成一个文件,并会创建单独的索引文件。当你使用SortShuffleManager时,如果的确不需要排序操作,那么建议将这个参数调大一些,大于shuffle read task的数量。那么此时就会自动启用bypass机制,map-side就不会进行排序了,减少了排序的性能开销。但是这种方式下,依然会产生大量的磁盘文件,因此shuffle write性能有待提高。
spark.shuffle.consolidateFiles
//默认值false
//如果使用HashShuffleManager,该参数有效。如果设置为true,那么就会开启consolidate机制,会大幅度合并shuffle write的输出文件,对于shuffle read task数量特别多的情况下,这种方法可以极大地减少磁盘IO开销,提升性能。如果的确不需要SortShuffleManager的排序机制,那么除了使用bypass机制,还可以尝试将spark.shffle.manager参数手动指定为hash,使用HashShuffleManager,同时开启consolidate机制。在实践中尝试过,发现其性能比开启了bypass机制的SortShuffleManager要高出10%~30%。
摘自:Spark性能优化指南——高级篇 - 美团技术团队
Spark数据倾斜解决方案及shuffle原理的更多相关文章
- Spark数据倾斜解决方案(转)
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/skew/ Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势 发表于 2017 ...
- Spark 数据倾斜
Spark 数据倾斜解决方案 2017年03月29日 17:09:58 阅读数:382 现象 当你的应用程序发生以下情况时你该考虑下数据倾斜的问题了: 绝大多数task都可以愉快的执行,总 ...
- 最完整的数据倾斜解决方案(spark)
一.了解数据倾斜 数据倾斜的原理: 在执行shuffle操作的时候,按照key,来进行values的数据的输出,拉取和聚合.同一个key的values,一定是分配到一个Reduce task进行处理. ...
- spark中数据倾斜解决方案
数据倾斜导致的致命后果: 1 数据倾斜直接会导致一种情况:OOM. 2 运行速度慢,特别慢,非常慢,极端的慢,不可接受的慢. 搞定数据倾斜需要: 1.搞定shuffle 2.搞定业务场景 3 搞定 c ...
- spark完整的数据倾斜解决方案
1.数据倾斜的原理 2.数据倾斜的现象 3.数据倾斜的产生原因与定位 在执行shuffle操作的时候,大家都知道,我们之前讲解过shuffle的原理. 是按照key,来进行values的数据的输出.拉 ...
- 【Spark调优】小表join大表数据倾斜解决方案
[使用场景] 对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个RDD或表的数据量比较小(例如几百MB或者1~2GB),比较适用此方案. [解决方案] ...
- 【Spark调优】大表join大表,少数key导致数据倾斜解决方案
[使用场景] 两个RDD进行join的时候,如果数据量都比较大,那么此时可以sample看下两个RDD中的key分布情况.如果出现数据倾斜,是因为其中某一个RDD中的少数几个key的数据量过大,而另一 ...
- Spark性能优化之道——解决Spark数据倾斜(Data Skew)的N种姿势
原创文章,同步首发自作者个人博客转载请务必在文章开头处注明出处. 摘要 本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitio ...
- spak数据倾斜解决方案
数据倾斜解决方案 数据倾斜的解决,跟之前讲解的性能调优,有一点异曲同工之妙. 性能调优中最有效最直接最简单的方式就是加资源加并行度,并注意RDD架构(复用同一个RDD,加上cache缓存).相对于前面 ...
随机推荐
- 在微信小程序页面间传递数据总结
在微信小程序页面间传递数据 原文链接:https://www.jianshu.com/p/dae1bac5fc75 在开发微信小程序过程之中,遇到这么一些需要在微信小程序页面之间进行数据的传递的情况, ...
- linux高性能服务器编程 (三) --TCP协议详解
第三章 IP协议详解 TCP协议是TCP/IP协议族中的另外一个重要的协议,与IP协议相比,TCP协议更高进应用层.一些重要的socket选项都和TCP协议相关.这一章主要从如下方面学习: 1)TCP ...
- 简单find命令的实现
贴代码: /*实现一个简单的find命令:*//*程序思路:首先,用一个单链表将所需要的信息存储起来:其次根据所传入的参数信息,改变节点的状态(若有这个状态,证明该节点就是我们所需要的)最后将所需要的 ...
- html上传文件限制、前端限制文件类型
<input id="file" type="file" accept=".xls,.xlsx" style="width: ...
- WINDOWS 命令行调用SAS代码 并指定输出路径 示例
ECHO "设置SAS.EXE 路径" SET PATH=D:\Program Files\SASHome\SASFoundation\9.4\SAS.EXE echo " ...
- In Vitro model验证 | Harnessing single-cell genomics to improve the physiological fidelity of organoid-derived cell types
Transcriptional benchmarking of in vitro cells to in vivo with single-cell rna-seq - 简介 Harnessing s ...
- TortoiseSVN is locked in another working copy
TortoiseSVN提交报错 TortoiseSVN is locked in another working copy原因:可能是因为打开了多个commit会话,然后又去修改了提交文件的内容,导致 ...
- H3C/华为交换机配置NTP客户端
H3C clock timezone UTC add ntp-service unicast-server 1.1.1.1 //ntp服务器地址 clock protocol ntp ntp-serv ...
- PHP环境搭建-Windows系统下PHP环境搭建
1.PHP环境搭建的前提是 Apache HTTP Server (Apache 服务器)已经安装部署成功,并可以正常访问到服务器的主页面.Apache HTTP Server 的安装部署已经在上一篇 ...
- webService和Restful
restful是一种架构风格,其核心是面向资源,更简单:而webService底层SOAP协议,主要核心是面向活动:两个都是通过web请求调用接口 RESTful是什么: 首先要了解什么是REST,R ...