python 爬虫实例(二)
环境:
OS:Window10
python:3.7
描述
打开下面的网址,之后抓取其中的图片
https://music.163.com/#/artist/album?id=101988&limit=120&offset=0
安装一些库文件
首先看你的网页版本,查看方法,打开【https://sites.google.com/a/chromium.org/chromedriver/downloads】之后显示如下图1,说明你的版本是2.45,
下载对应的版本的驱动下载地址【https://chromedriver.storage.googleapis.com/index.html】如下图2

(图1)

(图2)
上面的包文件下载到本地之后,把bin里面的EXE文件放到你本地安装的Python的【Scripts】文件夹路径下
自己的本地路径【C:\Users\XXXXXXX\AppData\Local\Programs\Python\Python37\Scripts】 整体代码如下
import time import requests
import os from bs4 import BeautifulSoup
from selenium import webdriver class GetMuisc: def __init__(self):
self.init_url = 'http://music.163.com/#/artist/album?id=101988&limit=120&offset=0'
self.folder_path = r"C:\pythonProject\wangyi" def request(self, url):
r = requests.get(url)
return r def mkdir(self, path):
path = path.strip()
isExists = os.path.exists(path) if not isExists:
print('创建名字叫做', path, '的文件夹')
os.makedirs(path)
print('创建成功!')
return True
else:
print(path, '文件夹已经存在了,不再创建')
return False def save_img(self, url, file_name):
print("开始请求图片地址...")
img = self.request(url)
print('开始保存图片')
with(open(file_name, "ab")) as ff:
ff.write(img.content)
print(file_name, '图片保存成功!') # f = open(file_name, "ab")
# f.write(img.content)
# f.close() def get_files(self, path):
pic_name = os.listdir(path)
return pic_name def spider(self):
print("Start!")
driver = webdriver.Chrome()
driver.get(self.init_url)
driver.switch_to.frame("g_iframe")
iframe_html = driver.page_source
driver.close() self.mkdir(self.folder_path)
file_name = self.get_files(self.folder_path)
os.chdir(self.folder_path) idstr = 'm-song-module'
moduleHtml = BeautifulSoup(iframe_html, 'lxml').find(id=idstr)
if moduleHtml is None:
print("标签{}没有找到,请检查是否有问题。".format(idstr))
else:
all_li = moduleHtml.find_all('li')
for li in all_li:
album_img = li.find("img")["src"]
album_name = li.find("p", class_="dec")["title"]
album_date = li.find("span", class_="s-fc3").get_text()
end_pos = album_img.index("?")
album_img_url = album_img[:end_pos] photo_name = album_date + " - " + album_name.replace("/", "").replace(":", ",") + ".jpg"
print(album_img_url, photo_name) if photo_name in file_name:
print('图片已经存在,不再重新下载')
else:
self.save_img(album_img_url, photo_name) album_cover = GetMuisc()
album_cover.spider()
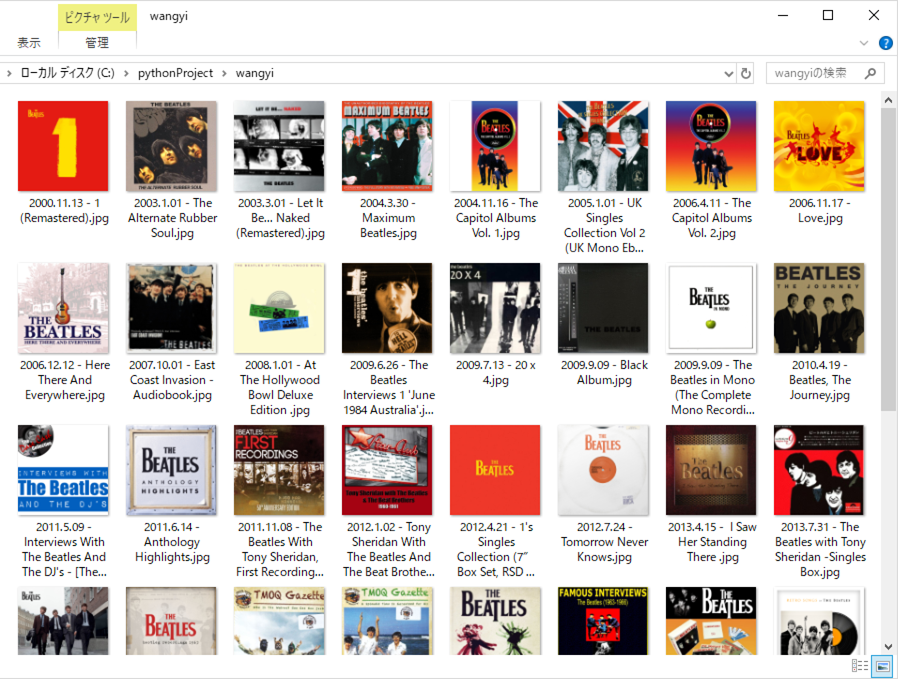
运行效果

python 爬虫实例(二)的更多相关文章
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫利器二之Beautiful Soup的用法
上一节我们介绍了正则表达式,它的内容其实还是蛮多的,如果一个正则匹配稍有差池,那可能程序就处在永久的循环之中,而且有的小伙伴们也对写正则表达式的写法用得不熟练,没关系,我们还有一个更强大的工具,叫Be ...
- 2.Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫入门二之爬虫基础了解
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫入门二之爬虫基础了解
静觅 » Python爬虫入门二之爬虫基础了解 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
随机推荐
- Codevs 1070 普通递归关系(矩阵乘法)
1070 普通递归关系 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 大师 Master 题目描述 Description 考虑以下定义在非负整数n上的递归关系 f(n) = f0 ...
- 10分钟教你用python 30行代码搞定简单手写识别!
欲直接下载代码文件,关注我们的公众号哦!查看历史消息即可! 手写笔记还是电子笔记好呢? 毕业季刚结束,眼瞅着2018级小萌新马上就要来了,老腊肉小编为了咱学弟学妹们的学习,绞尽脑汁准备编一套大学秘籍, ...
- [转] Raspberry Pi 樹莓派使用場合及時機
在買了 Raspberry Pi 後,到底能拿來做什麼事情呢?有幾個想法一起分享 這裡有初學者教學的影片,非常值得一看. http://www.youtube.com/user/Raspberry ...
- 复旦高等代数 II(15级)每周一题
[问题2016S01] 设 $f(x)=x^n+a_{n-1}x^{n-1}+\cdots+a_1x+a_0$ 是整系数首一多项式, 满足: $|a_0|$ 是素数且 $$|a_0|>1+\s ...
- Failed opening libc!的解决方法
方法来源: http://www.cfd-online.com/Forums/fluent/135879-setting-process-affinity-failed-opening-libc.ht ...
- OpenFOAM在原有算例上新建算例(只拷贝0,system,constant)
原视频下载地址: https://yunpan.cn/cMpyBHSEvC7T4 (提取码:dca4)
- git工作总结
一.简单介绍 简介:Git是一个开源的分布式版本控制系统,可以有效.高速地处理项目版本管理. 发展史:CSV -> SVN -> Git 优点:Git速度快.开源.完全分布式管理系统 相关 ...
- CSS(1)
使用CSS的注意点: 1.style标签必须写在head标签的开始标签和结束标签之间(也就是必须和title标签是兄弟关系). 2.style标签中的type属性其实可以不用写,默认就是type=&q ...
- html5的source元素
html5的source元素 一.总结 一句话总结: 主要是解决视频播放时候的浏览器的兼容问题 二.html5的source元素 学习要点 掌握source元素的用法 source元素-解决浏览器额兼 ...
- springboot+vue实现文件上传
https://blog.csdn.net/mqingo/article/details/84869841 技术: 后端:springboot 前端框架:vue 数据库:mysql pom.xml: ...