NN入门
参考资料:https://blog.csdn.net/kwame211/article/details/77337166, 仅作为个人学习笔记。人工智能的底层模型是"神经网络"(neural network)。
1、感知器
历史上,科学家一直希望模拟人的大脑,造出可以思考的机器。人为什么能够思考?科学家发现,原因在于人体的神经网络。见上章图
- 外部刺激通过神经末梢,转化为电信号,转导到神经细胞(又叫神经元)。
- 无数神经元构成神经中枢。
- 神经中枢综合各种信号,做出判断。
- 人体根据神经中枢的指令,对外部刺激做出反应。
既然思考的基础是神经元,如果能够"人造神经元"(artificial neuron),就能组成人工神经网络,模拟思考。上个世纪六十年代,提出了最早的"人造神经元"模型,叫做"感知器"(perceptron),直到今天还在用。
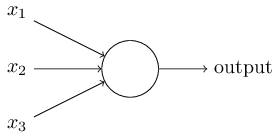
上图的圆圈就代表一个感知器。它接受多个输入(x1,x2,x3...),产生一个输出(output),好比神经末梢感受各种外部环境的变化,最后产生电信号。
为了简化模型,我们约定每种输入只有两种可能:1 或 0。如果所有输入都是1,表示各种条件都成立,输出就是1;如果所有输入都是0,表示条件都不成立,输出就是0。
2、感知器示例
城里正在举办一年一度的游戏动漫展览,小明拿不定主意,周末要不要去参观。他决定考虑三个因素:
- 天气:周末是否晴天?
- 同伴:能否找到人一起去?
- 价格:门票是否可承受?
这就构成一个感知器。上面三个因素就是外部输入,最后的决定就是感知器的输出。如果三个因素都是 Yes(使用1表示),输出就是1(去参观);如果都是 No(使用0表示),输出就是0(不去参观)。
3、权重和阈值
看到这里,你肯定会问:如果某些因素成立,另一些因素不成立,输出是什么?比如,周末是好天气,门票也不贵,但是小明找不到同伴,他还要不要去参观呢?
现实中,各种因素很少具有同等重要性:某些因素是决定性因素,另一些因素是次要因素。因此,可以给这些因素指定权重(weight),代表它们不同的重要性。
- 天气:权重为8
- 同伴:权重为4
- 价格:权重为4
上面的权重表示,天气是决定性因素,同伴和价格都是次要因素。
如果三个因素都为1,它们乘以权重的总和就是 8 + 4 + 4 = 16。如果天气和价格因素为1,同伴因素为0,总和就变为 8 + 0 + 4 = 12。
这时,还需要指定一个阈值(threshold)。如果总和大于阈值,感知器输出1,否则输出0。假定阈值为8,那么 12 > 8,小明决定去参观。阈值的高低代表了意愿的强烈,阈值越低就表示越想去,越高就越不想去。
上面的决策过程,使用数学表达如下:
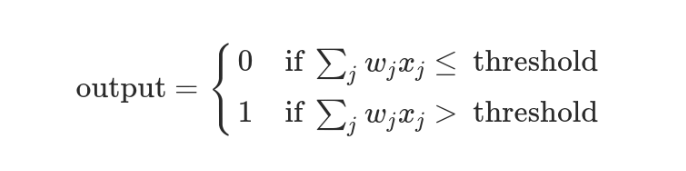
上面公式中,x表示各种外部因素,w表示对应的权重。
4、决策模型
单个的感知器构成了一个简单的决策模型,已经可以拿来用了。真实世界中,实际的决策模型则要复杂得多,是由多个感知器组成的多层网络。
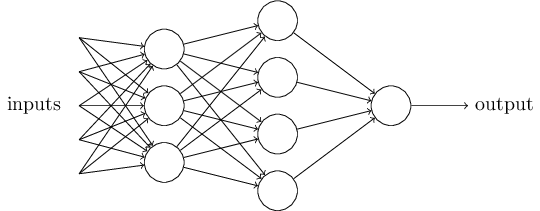
上图中,底层感知器接收外部输入,做出判断以后,再发出信号,作为上层感知器的输入,直至得到最后的结果。(注意:感知器的输出依然只有一个,但是可以发送给多个目标。)
这张图里,信号都是单向的,即下层感知器的输出总是上层感知器的输入。现实中,有可能发生循环传递,即 A 传给 B,B 传给 C,C 又传给 A,这称为"递归神经网络"(recurrent neural network)
5、矢量化
为了方便后面的讨论,需要对上面的模型进行一些数学处理:
- 外部因素 x1、x2、x3 写成矢量 ,简写为 x
- 权重 w1、w2、w3 也写成矢量 (w1, w2, w3),简写为 w
- 定义运算 w⋅x = ∑ wx,即 w 和 x 的点运算,等于因素与权重的乘积之和
- 定义 b 等于负的阈值 b = -threshold
感知器模型就变成了下面这样:
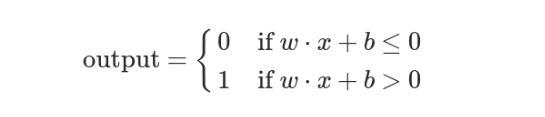
6、神经网络的运作过程
一个神经网络的搭建,需要满足三个条件:
- 输入和输出
- 权重(w)和阈值(b)
- 多层感知器的结构
也就是说,需要事先画出第4小节出现的那张图。
其中,最困难的部分就是确定权重(w)和阈值(b)。目前为止,这两个值都是主观给出的,但现实中很难估计它们的值,必需有一种方法,可以找出答案。
这种方法就是试错法。其他参数都不变,w(或b)的微小变动,记作Δw(或Δb),然后观察输出有什么变化。不断重复这个过程,直至得到对应最精确输出的那组w和b,就是我们要的值。这个过程称为模型的训练。
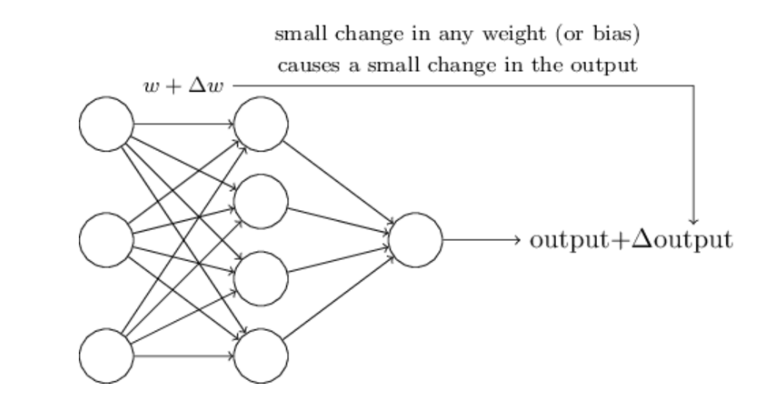
因此,神经网络的运作过程如下:
- 确定输入和输出
- 找到一种或多种算法,可以从输入得到输出
- 找到一组已知答案的数据集,用来训练模型,估算w和b
- 一旦新的数据产生,输入模型,就可以得到结果,同时对w和b进行校正
可以看到,整个过程需要海量计算。所以,神经网络直到最近这几年才有实用价值,而且一般的 CPU 还不行,要使用专门为机器学习定制的 GPU 来计算
7、神经网络的例子
通过车牌自动识别的例子,来解释神经网络:

所谓"车牌自动识别",就是高速公路的探头拍下车牌照片,计算机识别出照片里的数字。
这个例子里面,车牌照片就是输入,车牌号码就是输出,照片的清晰度可以设置权重(w)。然后,找到一种或多种图像比对算法,作为感知器。算法的得到结果是一个概率,比如75%的概率可以确定是数字1。这就需要设置一个阈值(b)(比如85%的可信度),低于这个门槛结果就无效。
一组已经识别好的车牌照片,作为训练集数据,输入模型。不断调整各种参数,直至找到正确率最高的参数组合。以后拿到新照片,就可以直接给出结果了。
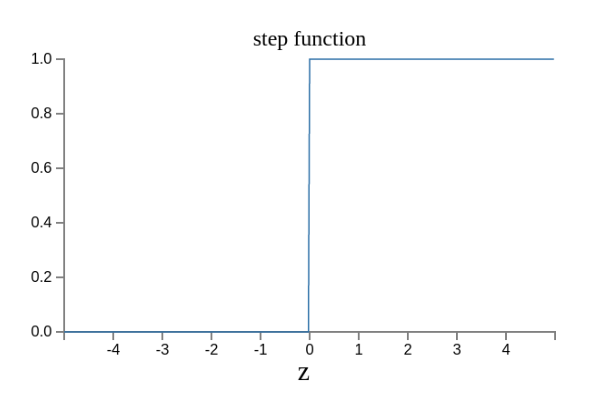
8、输出的连续性
上面的模型有一个问题没有解决,按照假设,输出只有两种结果:0和1。但是,模型要求w或b的微小变化,会引发输出的变化。如果只输出0和1,未免也太不敏感了,无法保证训练的正确性,因此必须将"输出"改造成一个连续性函数。这就需要进行一点简单的数学改造。
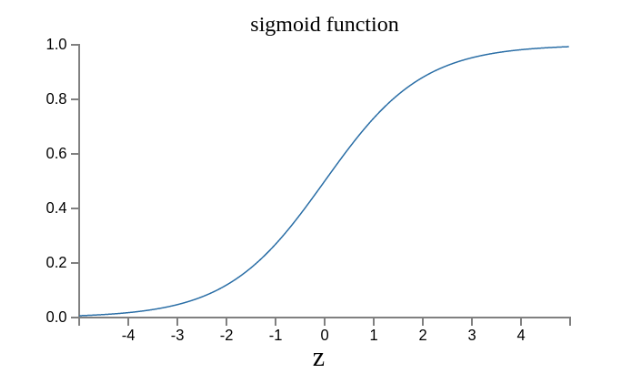
- 首先,将感知器的计算结果wx + b记为z; 即:z = wx + b
- 然后,计算下面的式子,将结果记为σ(z);即:σ(z) = 1 / (1 + e^(-z))
这是因为如果z趋向正无穷z → +∞(表示感知器强烈匹配),那么σ(z) → 1;如果z趋向负无穷z → -∞(表示感知器强烈不匹配),那么σ(z) → 0。也就是说,只要使用σ(z)当作输出结果,那么输出就会变成一个连续性函数
原来的输出曲线是下面这样
现在变成了这样
实际上,还可以证明Δσ满足下面的公式:
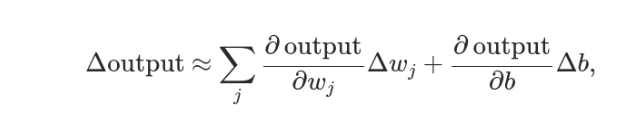
NN入门的更多相关文章
- NN入门,手把手教你用Numpy手撕NN(一)
前言 这是一篇包含极少数学推导的NN入门文章 大概从今年4月份起就想着学一学NN,但是无奈平时时间不多,而且空闲时间都拿去做比赛或是看动漫去了,所以一拖再拖,直到这8月份才正式开始NN的学习. 这篇文 ...
- NN入门,手把手教你用Numpy手撕NN(2)
这是一篇包含较少数学推导的NN入门文章 上篇文章中简单介绍了如何手撕一个NN,但其中仍有可以改进的地方,将在这篇文章中进行完善. 误差反向传播 之前的NN计算梯度是利用数值微分法,虽容易实现,但是计算 ...
- NN入门,手把手教你用Numpy手撕NN(三)
NN入门,手把手教你用Numpy手撕NN(3) 这是一篇包含极少数学的CNN入门文章 上篇文章中简单介绍了NN的反向传播,并利用反向传播实现了一个简单的NN,在这篇文章中将介绍一下CNN. CNN C ...
- tf入门-池化函数 tf.nn.max_pool 的介绍
转载自此大神 http://blog.csdn.net/mao_xiao_feng/article/details/53453926 max pooling是CNN当中的最大值池化操作,其实用法和卷积 ...
- tf入门-tf.nn.conv2d是怎样实现卷积的?
转自:https://blog.csdn.net/mao_xiao_feng/article/details/78004522 实验环境:tensorflow版本1.2.0,python2.7 介绍 ...
- 15、ASP.NET MVC入门到精通——MVC-路由
本系列目录:ASP.NET MVC4入门到精通系列目录汇总 Routing(路由) – URL url 作为广泛使用的Web用户接口,需要被重视 好的Url应该满足如下条件: URL应为获取某种资源提 ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark入门实战系列--6.SparkSQL(上)--SparkSQL简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .SparkSQL的发展历程 1.1 Hive and Shark SparkSQL的前身是 ...
- Spark入门实战系列--6.SparkSQL(中)--深入了解SparkSQL运行计划及调优
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1.1 运行环境说明 1.1.1 硬软件环境 线程,主频2.2G,10G内存 l 虚拟软 ...
随机推荐
- meta设置与去除默认样式--移动端开发整理笔记(一)
视口设置: <meta name="viewport" content="width=device-width,user-scalable=no,initial-s ...
- CSS布局对齐的小技巧
类似以上这种对齐怎么做? 很简单,上面是的污水开始的位置是由于被"能源种类"顶着,下面没有字怎么办?最差的办法就是用margin-left,因为在不同的机器上,可能会出现兼容性问题 ...
- Stuts 文件上传
Stuts 文件上传 三种上传方案 1.上传到tomcat服务器 上传图片的存放位置与tomcat服务器的耦合度太高 2.上传到指定文件目录,添加服务器与真实目录的映射 ...
- Django ORM性能优化 和 图片验证码
一,ORM性能相关 1. 关联外键, 只拿一次数据 all_users = models.User.objects.all().values('name', 'age', 'role__name') ...
- MybatisPlus使用代码生成器遇到的小问题
MyBatisPlus 在3.0.3版本之前使用代码生成器因为存在默认依赖,所以不需要其他的依赖,项目中使用的是3.0.1的版本,所以不用添加其他依赖,添加之后反倒是会报错,实际上MP官网上已经说明了 ...
- 常用war包插件
<build> <resources> <resource> <directory>src/main/java</directory> &l ...
- leetcode-19:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
/** * Definition for singly-linked list. * public class ListNode { * int val; * ListNode next; * Lis ...
- linux 操作文件夹
创建文件夹[mkdir] 一.mkdir命令使用权限 所有用户都可以在终端使用 mkdir 命令在拥有权限的文件夹创建文件夹或目录. 二.mkdir命令使用格式 格式:mkdir [选项] DirNa ...
- StringTable
首先看这样一个面试题 // StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容 public ...
- Union 与 Union All 区别(抄的W3C School的,抄一遍就记住了!)
Union ,UnionAll 俩都是用来合并两个或以上的查询结果集: Union操作符 :select语句中必须有相同的数列 (相等数量的列,不同结果集同一列的数据类型一致,列的顺序必须相同): u ...