爬虫的正则表达式re模块
爬虫一共就四个主要步骤:
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
对于down下了的数据是全部的网页,这些数据很庞大并且很混乱,大部分的东西无用的,因此需要将过滤和匹配出来。
那么对于文本的过滤或者规则的匹配,最强大的就是正则表达式,是Python爬虫世界里必不可少的神兵利器。
什么是正则表达式
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式匹配规则
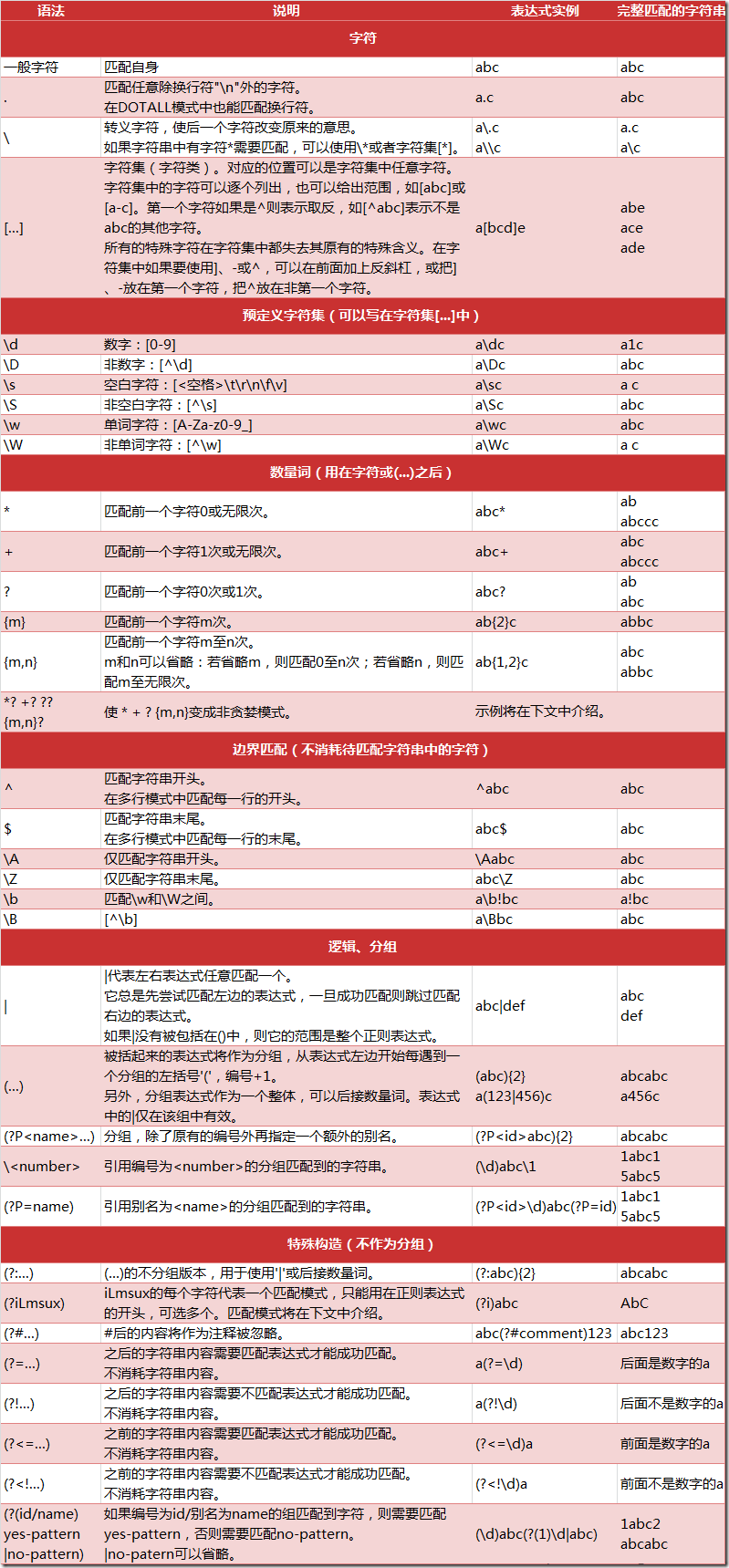
Python 的 re 模块
在 Python 中,可以使用内置的 re 模块来使用正则表达式。
需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以使用原始字符串,只需加一个 r 前缀,示例:
r'chuanzhiboke\t\.\tpython'
re 模块的一般使用步骤如下:
使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。- 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
import re # 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
在上面,已将一个正则表达式编译成 Pattern 对象,接下来,就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从任何位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
>>> import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字 >>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None >>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None >>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0> >>> m.group(0) # 可省略 0
''
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
再看看一个例子:
>>> import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web') >>> print m # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8> >>> m.group(0) # 返回匹配成功的整个子串
'Hello World' >>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11) >>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello' >>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5) >>> m.group(2) # 返回第二个分组匹配成功的子串
'World' >>> m.span(2) # 返回第二个分组匹配成功的子串
(6, 11) >>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World') >>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
如:
>>> import re
>>> pattern = re.compile('\d+')
>>> m = pattern.search('one12twothree34four') # 这里如果使用 match 方法则不匹配
>>> m
<_sre.SRE_Match object at 0x10cc03ac0>
>>> m.group()
''
>>> m = pattern.search('one12twothree34four', 10, 30) # 指定字符串区间
>>> m
<_sre.SRE_Match object at 0x10cc03b28>
>>> m.group()
''
>>> m.span()
(13, 15)
再如:
# -*- coding: utf-8 -*- import re
# 将正则表达式编译成 Pattern 对象
pattern = re.compile(r'\d+')
# 使用 search() 查找匹配的子串,不存在匹配的子串时将返回 None
# 这里使用 match() 无法成功匹配
m = pattern.search('hello 123456 789')
if m:
# 使用 Match 获得分组信息
print 'matching string:',m.group()
# 起始位置和结束位置
print 'position:',m.span()
执行结果:
matching string: 123456
position: (6, 12)
findall 方法
上面的 match 和 search 方法都是一次匹配,只要找到了一个匹配的结果就返回。然而,在大多数时候,需要搜索整个字符串,获得所有匹配的结果。
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
看看例子:
import re
pattern = re.compile(r'\d+') # 查找数字 result1 = pattern.findall('hello 123456 789')
result2 = pattern.findall('one1two2three3four4', 0, 10) print result1
print result2
执行结果:
['', '']
['', '']
如:
# re_test.py import re #re模块提供一个方法叫compile模块,提供我们输入一个匹配的规则
#然后返回一个pattern实例,我们根据这个规则去匹配字符串
pattern = re.compile(r'\d+\.\d*') #通过partten.findall()方法就能够全部匹配到我们得到的字符串
result = pattern.findall("123.141593, 'bigcat', 232312, 3.15") #findall 以 列表形式 返回全部能匹配的子串给result
for item in result:
print item
运行结果:
123.141593
3.15
finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
如:
# -*- coding: utf-8 -*- import re
pattern = re.compile(r'\d+') result_iter1 = pattern.finditer('hello 123456 789')
result_iter2 = pattern.finditer('one1two2three3four4', 0, 10) print type(result_iter1)
print type(result_iter2) print 'result1...'
for m1 in result_iter1: # m1 是 Match 对象
print 'matching string: {}, position: {}'.format(m1.group(), m1.span()) print 'result2...'
for m2 in result_iter2:
print 'matching string: {}, position: {}'.format(m2.group(), m2.span())
执行结果:
<type 'callable-iterator'>
<type 'callable-iterator'>
result1...
matching string: 123456, position: (6, 12)
matching string: 789, position: (13, 16)
result2...
matching string: 1, position: (3, 4)
matching string: 2, position: (7, 8)
split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
如:
import re
p = re.compile(r'[\s\,\;]+')
print p.split('a,b;; c d')
执行结果:
['a', 'b', 'c', 'd']
sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
如:
import re
p = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9]
s = 'hello 123, hello 456' print p.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456'
print p.sub(r'\2 \1', s) # 引用分组 def func(m):
return 'hi' + ' ' + m.group(2) print p.sub(func, s)
print p.sub(func, s, 1) # 最多替换一次
执行结果:
hello world, hello world
123 hello, 456 hello
hi 123, hi 456
hi 123, hello 456
匹配中文
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = u'你好,hello,世界' 中的中文提取出来,可以这么做:
import re title = u'你好,hello,世界'
pattern = re.compile(ur'[\u4e00-\u9fa5]+')
result = pattern.findall(title) print result
注意到,我们在正则表达式前面加上了两个前缀 ur,其中 r 表示使用原始字符串,u 表示是 unicode 字符串。
执行结果:
[u'\u4f60\u597d', u'\u4e16\u754c']
注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
示例一 : 源字符串:abbbc
- 使用贪婪的数量词的正则表达式
ab*,匹配结果: abbb。*决定了尽可能多匹配 b,所以a后面所有的 b 都出现了。
- 使用非贪婪的数量词的正则表达式
ab*?,匹配结果: a。即使前面有
*,但是?决定了尽可能少匹配 b,所以没有 b。
示例二 : 源字符串:aa<div>test1</div>bb<div>test2</div>cc
使用贪婪的数量词的正则表达式:
<div>.*</div>匹配结果:
<div>test1</div>bb<div>test2</div>
这里采用的是贪婪模式。在匹配到第一个“
</div>”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串。匹配到第二个“</div>”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“<div>test1</div>bb<div>test2</div>”
使用非贪婪的数量词的正则表达式:
<div>.*?</div>匹配结果:
<div>test1</div>
正则表达式二采用的是非贪婪模式,在匹配到第一个“
</div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“<div>test1</div>”。
爬虫的正则表达式re模块的更多相关文章
- 爬虫之正则表达式re模块
为什么要学正则表达式 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网站去搜索) 爬 (将所有的网站的内容全部爬下来) 取 (去掉对我们没用处的数据) 处理数据(按照我们想要的 ...
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python 正则表达式re模块
#####################总结############## 优点: 灵活, 功能性强, 逻辑性强. 缺点: 上手难,旦上手, 会爱上这个东西 ...
- 【网络爬虫入门03】爬虫解析利器beautifulSoup模块的基本应用
[网络爬虫入门03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.B ...
- python基础之正则表达式 re模块
内容梗概: 1. 正则表达式 2. re模块的使⽤ 3. 一堆练习正则表达式是对字符串串操作的一种逻辑公式. 我们一般使用正则表达式对字符串进行匹配和过滤.使用正则的优缺点: 优点: 灵活,功能性强, ...
- python 3.x 爬虫基础---正则表达式
python 3.x 爬虫基础 python 3.x 爬虫基础---http headers详解 python 3.x 爬虫基础---Urllib详解 python 3.x 爬虫基础---Requer ...
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- python正则表达式Re模块备忘录
title: python正则表达式Re模块备忘录 date: 2019/1/31 18:17:08 toc: true --- python正则表达式Re模块备忘录 备忘录 python中的数量词为 ...
随机推荐
- synchronized的使用方法和作用域
文章地址:https://mp.weixin.qq.com/s?__biz=MzI4NTEzMjc5Mw==&mid=2650554746&idx=1&sn=8e45e741c ...
- beta版本——第五次冲刺
第五次冲刺 (1)SCRUM部分☁️ 成员描述: 姓名 李星晨 完成了哪个任务 界面优化 花了多少时间 2h 还剩余多少时间 2h 遇到什么困难 没有 这两天解决的进度 2/2 后续两天的计划 完成文 ...
- beta版本——第二次冲刺
第二次冲刺 (1)SCRUM部分☁️ 成员描述: 姓名 唐财伟 完成了哪个任务 搭建Nginx 花了多少时间 3h 还剩余多少时间 0h 遇到什么困难 解决端口冲突,启动报错等问题 这两天解决的进度 ...
- Python爬虫爬企查查数据
因为制作B2b网站需要,需要入库企业信息数据.所以目光锁定企查查数据,废话不多说,开干! #-*- coding-8 -*- import requests import lxml import sy ...
- 互联网UV,PU,TopN统计
1. UV.PV.TopN概念 1.1 UV(unique visitor) 即独立访客数 指访问某个站点或点击某个网页的不同IP地址的人数.在同一天内,UV只记录第一次进入网站的具有独立IP的访问者 ...
- 数据分析 - Numpy
简介 Numpy是高性能科学计算和数据分析的基础包.它也是pandas等其他数据分析的工具的基础,基本所有数据分析的包都用过它.NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库 ...
- 题解 UVa10791
题目大意 多组数据,每组数据给出一个正整数 \(n\),请求出一组数 \(a_1\cdots a_m\),满足 \(LCM_{k=1}^ma_k=n\) 且 \(\sum_{k=1}^ma_k\) 最 ...
- python的next()函数
next(iterobject,defalt)函数的第一个参数是一个可迭代对象,第二个参数可以不写.不写的时候,如果可迭代对象的元素取出完毕,会返回StopIteration.如果第二个参数写一个其他 ...
- 目标检测的mAp
众多目标检测的知识中,都提到了mAp一值,那么这个东西到底是什么呢: 我们在评价一个目标检测算法的"好坏"程度的时候,往往采用的是pascal voc 2012的评价标准mAP.目 ...
- PDB文件会影响性能吗?
有人问了这样的问题:"我工作的公司正极力反对用生成的调试信息构建发布模式二进制文件,这也是我注册该类的原因之一.他们担心演示会受到影响.我的问题是,在发布模式下生成符号的最佳命令行参数是什么 ...