Sqoop2 将hdfs中的数据导出到MySQL
1.进入sqoop2终端:
[root@master /]# sqoop2

2.为客户端配置服务器:
sqoop:000> set server --host master --port 12000 --webapp sqoop

3.查看服务器配置:
sqoop:000> show version --all

4. 查看sqoop的所有连接:
sqoop 所有的连接固定为四个,如下:
sqoop:000> show connector

5.创建hdfs的link:
sqoop:000> create link --cid 3
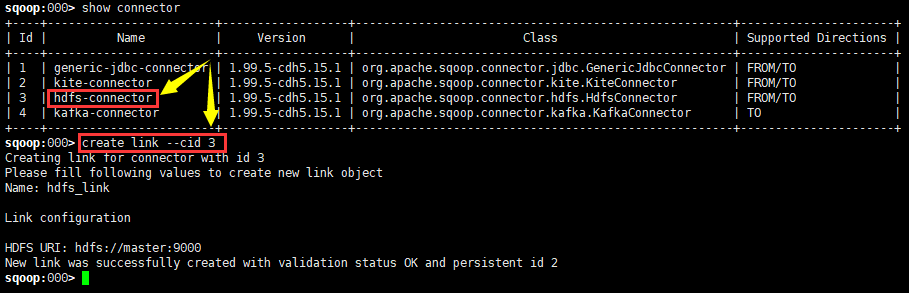
sqoop:> create link --cid
Creating link for connector with id
Please fill following values to create new link object
Name: hdfs_link Link configuration HDFS URI: hdfs://master:8020 // 这个地方一定要和hdfs中的地址对应
New link was successfully created with validation status OK and persistent id
5.创建MySQL的Link
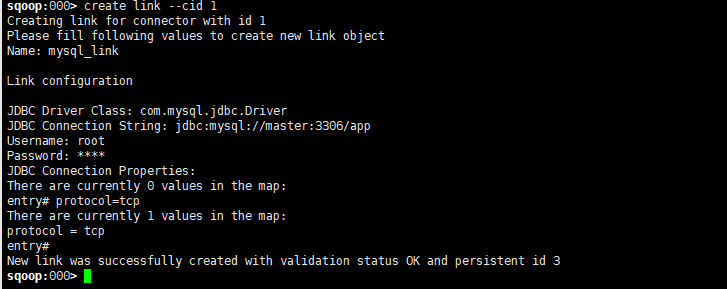
sqoop:> create link --cid
Creating link for connector with id
Please fill following values to create new link object
Name: mysql_link Link configuration JDBC Driver Class: com.mysql.jdbc.Driver
JDBC Connection String: jdbc:mysql://master:3306/app
Username: root
Password: ****
JDBC Connection Properties:
There are currently values in the map:
entry# protocol=tcp
There are currently values in the map:
protocol = tcp
entry#
New link was successfully created with validation status OK and persistent id
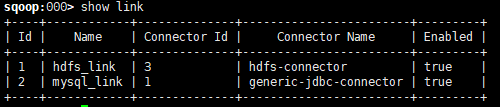
6.查看当前的所有link
sqoop:000> show link
7.创建job
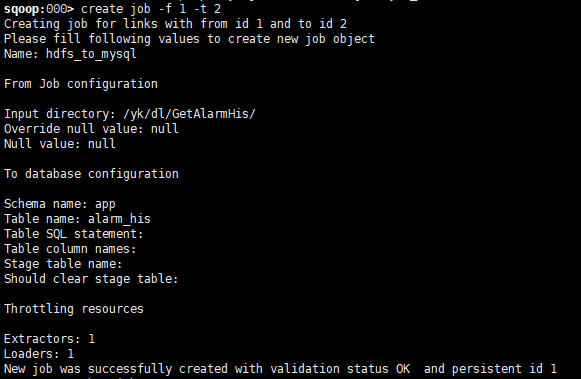
sqoop:> create job -f -t
Creating job for links with from id and to id
Please fill following values to create new job object
Name: hdfs_to_mysql From Job configuration Input directory: /yk/dl/GetAlarmHis/
Override null value: null
Null value: null To database configuration Schema name: app
Table name: alarm_his
Table SQL statement:
Table column names:
Stage table name:
Should clear stage table: Throttling resources Extractors:
Loaders:
New job was successfully created with validation status OK and persistent id
Name:一个标示符,自己指定即可。
Schema Name:指定Database或Schema的名字,在MySQL中,Schema同Database类似,具体什么区别没有深究过,但官网描述在创建时差不多。这里指定数据库名字为db_ez即可,本例的数据库。
Table Name:本例使用的数据库表为tb_forhadoop,自己指定导出的表。多表的情况请自行查看官方文档。
SQL Statement:填了schema name和table name就不可以填sql statement。sql语句中必须包含${CONDITIONS}字样,一般是where 1=1 and ${CONDITIONS}
Partition column: 在填写了sql statement的情况下,必须填写,用以对数据分区,一般为可唯一标识记录的数字型字段。
Partition column nullable:
Boundary query:
Last value:
后面需要配置数据目的地各项值:
Null alue:大概说的是如果有空值用什么覆盖
File format:指定在HDFS中的数据文件是什么文件格式,这里使用TEXT_FILE,即最简单的文本文件。
Compression codec:用于指定使用什么压缩算法进行导出数据文件压缩,我指定NONE,这个也可以使用自定义的压缩算法CUSTOM,用Java实现相应的接口。
Custom codec:这个就是指定的custom压缩算法,本例选择NONE,所以直接回车过去。
Output directory:指定存储在HDFS文件系统中的路径,这里必须指定一个存在的路径,或者存在但路劲下是空的,貌似这样才能成功。
Append mode:用于指定是否是在已存在导出文件的情况下将新数据追加到数据文件中。
Extractors:大概是etl执行次数,比如填2,那么hdfs的输出中数据将会重复2次…依次类推
Loaders:决定了最后执行的reduce数量(可见下面的源码MapreduceSubmissionEngine.submit方法)
8.查看job
sqoop:000> show job

9.启动job
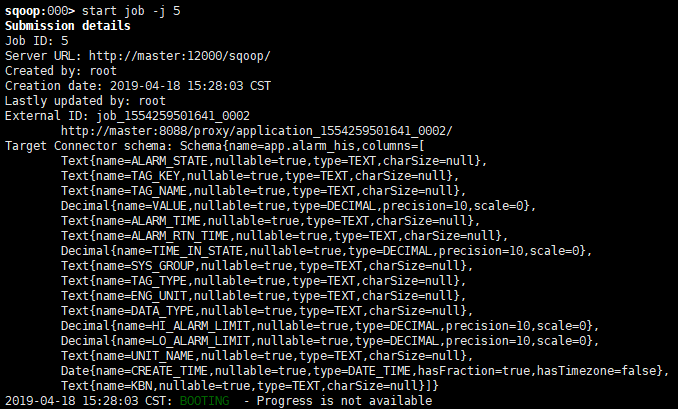
sqoop:001> show link 显示所有链接
sqoop:001> create link --cid 1 创建连接
sqoop:000> delete link --lid 1 删除link
sqoop:001> show job 显示所有job
sqoop:001> create job --f 2 --t 1 创建job ( 从link 2 向link 1导入数据)
sqoop:000> start job --jid 1 启动job
sqoop:000> status job --jid 1 查看导入状态
sqoop:000> delete job --jid 1 删除job
在sqoop客户端设置查看job详情:
set option --name verbose --value true
https://blog.csdn.net/wdr2003/article/details/80964588
教程:https://www.2cto.com/database/201411/356011.html
Sqoop2 将hdfs中的数据导出到MySQL的更多相关文章
- 《sqoop实现hdfs中的数据导出至mysql数据库》
报错Access denied for user 'root'@'localhost' (using password: YES) 参考一 参考二 登陆mysql时,root密码的修改 参考帖子h ...
- 使用JDBC+POI把Excel中的数据导出到MySQL
POI是Apache的一套读MS文档的API,用它还是可以比较方便的读取Office文档的.目前支持Word,Excel,PowerPoint生成的文档,还有Visio和Publisher的. htt ...
- 使用OpenXml把Excel中的数据导出到DataSet中
public class OpenXmlHelper { /// <summary> /// 读取Excel数据到DataSet中,默认读取所有Sheet中的数据 /// </sum ...
- 机房收费系统——在VB中将MSHFlexGrid控件中的数据导出到Excel
机房收费系统中,好多查询的窗体都包含同一个功能:将数据库中查询到的数据显示在MSHFlexGrid控件中,然后再把MSHFlexGrid控件中的数据导出到Excel表格中. 虽然之前做过学生信息管理系 ...
- Qt中将QTableView中的数据导出为Excel文件
如果你在做一个报表类的程序,可能将内容导出为Excel文件是一项必须的功能.之前使用MFC的时候我就写过一个类,用于将grid中的数据导出为Excel文件.在使用了QtSql模块后,我很容易的将这个类 ...
- 将Datagridview中的数据导出至Excel中
首先添加一个模块ImportToExcel,并添加引用 然后导入命名空间: Imports Microsoft.Office.Interop Imports System.Da ...
- Linux启动kettle及linux和windows中kettle往hdfs中写数据(3)
在xmanager中的xshell运行进入图形化界面 sh spoon.sh 新建一个job
- hbase使用MapReduce操作4(实现将 HDFS 中的数据写入到 HBase 表中)
实现将 HDFS 中的数据写入到 HBase 表中 Runner类 package com.yjsj.hbase_mr2; import com.yjsj.hbase_mr2.ReadFruitFro ...
- java程序向hdfs中追加数据,异常以及解决方案
今天在学习hdfs时,遇到问题,就是在向hdfs中追加数据总是报错,在经过好几个小时的努力之下终于将他搞定 解决方案如下:在hadoop的hdfs-sit.xml中添加一下三项 <propert ...
随机推荐
- 织梦个人空间中调用ip,会员类型,邮箱,金币,会员积分
织梦个人空间中调用.用户昵称,最后登录,会员等级 ,会员头衔,会员积分,空间访问,邮箱地址 ,金币数量,会员组的有效期天数 ,升级会员组的时间 ,用户的等级,用户的性别 ,会员的类型,ip 第一步确定 ...
- 无向图的割点和桥 tarjan 模板
#include <bits/stdc++.h> using namespace std; const int MAXN = 20005; const int MAXM = 100005; ...
- C# 调用 C++ Dll 类型转换的方式 全
摘要:C#引用C++ Dll 所有类型转换的方式 //C++中的DLL函数原型为 //extern "C" __declspec(dllexport ...
- learning AWT Jrame
import java.awt.*; public class FrameTest { public static void main(String[] args) { var f = new Fra ...
- suds
Suds: 是一个轻量级的SOAP客户端 pip install suds 可以访问webservice 选择公网的Webservice,http://www.webxml.com.cn/webser ...
- RookeyFrame 隐藏 首次加载菜单 的伸缩动画
一进入系统,然后点击菜单“系统管理”,会看到展开的“系统设置”菜单,又缩回去了,每次都会有(处女座看到就想改). 隐藏这个动画的JS:jquery.easyui.min.js,这个JS里面有个方法“_ ...
- mysqli扩展和持久化连接
mysqli扩展的持久化连接在PHP5.3中被引入.支持已经存在于PDO MYSQL 和ext/mysql中. 持久化连接背后的思想是客户端进程和数据库之间的连接可以通过一个客户端进程来保持重用, 而 ...
- http2 3
HTTP 2 推荐阅读:https://segmentfault.com/a/1190000011172823?utm_source=tag-newest 进来支持 HTTP 2 的网站越来愈多了,这 ...
- PreTranslateMessage中有调用模态对话框的解决方法
原文:https://blog.csdn.net/guoguojune/article/details/45332511 dlg.DoModal()截住了界面消息,所以返回时原来的pMsg的内容已经更 ...
- [内网渗透]MS14-068复现(CVE-2014-6324)
0x01 简介 在做域渗透测试时,当我们拿到了一个普通域成员的账号后,想继续对该域进行渗透,拿到域控服务器权限.如果域控服务器存在MS14_068漏洞,并且未打补丁,那么我们就可以利用MS14_068 ...