linux设备驱动程序--串行通信驱动框架分析
linux 串行通信接口驱动框架
在学习linux内核驱动时,不论是看linux相关的书籍,又或者是直接看linux的源码,总是能在linux中看到各种各样的框架,linux内核极其庞杂,linux各种框架理解起来并不容易,如果直接硬着头皮死记硬背,意义也不大。
博主学习东西一直秉持着追本溯源的态度,要弄清一个东西是怎么样的,如果能够了解它的发展,了解它为什么会变成这样,理解起来就非常简单了。抓住主干,沿着线头就可以将整个框架慢慢梳理清楚。
从i2c开始
在嵌入式中,不管是单片机还是单板机,i2c作为板级通信协议是非常受欢迎的,尤其是在传感器的使用领域,其主从结构加上对硬件资源的低要求,稳稳地占据着主导地位。
我们就以i2c协议为例,聊一聊linux内核中串行通信接口框架。
(注:在这篇文章只讨论大致框架,并不涉及具体细节,linux内核驱动部分的框架分得很细,无法全部覆盖,但求建立一个大体的概念)
单片机中的i2c
每个MCU基本上都会集成硬件i2c控制器,在单片机编程中,对于操作硬件i2c控制器,我们只需要操作一些相应的寄存器即可实现数据的收发。
那如果没有硬件i2c控制器或者i2c控制器不够用呢?
事情也不麻烦,我们可以使用两个gpio来软件模拟i2c协议,代码不过几十行,虽然i2c协议本身有一定的复杂性,但是如果仅仅是实现通信,在单片机上还是非常简单的。
单片机中实现i2c程序
我们不妨回想一下,在单片机中编写一个i2c驱动程序的流程:
以sht31(这是一个常用的i2c接口的温湿度传感器)为例,刚入行的新手程序员可能这样写主机程序(伪代码):
int sht31_read_temprature(){ //读取温度值实现函数
设置i2c写寄存器,发送i2c器件地址
设置i2c写寄存器,发送i2c寄存器地址
设置i2c读
temperature = 读取目标器件发回的数据
return temperature;
}
int sht31_read_humidity(){ //读取湿度值实现函数
设置i2c写寄存器,发送i2c器件地址
设置i2c写寄存器,发送i2c寄存器地址
设置i2c读
humidity = 读取目标器件发回的数据
return humidity;
}
....
程序优化
每次读写函数都对硬件i2c的寄存器进行设置,很显然,这样的代码有很多重复的部分,我们可以将重复的读写部分提取出来作为公共函数,写成这样:
array sht31_read_data(sht31数据寄存器地址){
设置i2c写寄存器,发送i2c器件地址
设置i2c写寄存器,发送i2c寄存器地址
设置i2c读
return 读取目标器件发回的数据;
}
所以,上例中的读温湿度就可以写成这样:
array sht31_read_temprature(){
return sht31_read_data(sht31温度数据寄存器地址);
}
array sht31_read_humidity(){
return sht31_read_data(sht31湿度数据寄存器地址);
}
...
经过这一步优化,这个驱动程序就变成了两层:
- i2c硬件操作部分,比如i2c与设备的读写,在同一平台上,硬件读写的寄存器操作都是一致的。
- 设备的操作函数,不同的设备有不同的寄存器,对于存储设备而言就是存取数据,对于传感器而言就是读写传感器数据,需要读写设备时,直接调用第一步中的接口,传入不同的参数。
可以明显看到的是,第一步中的i2c操作函数部分可以被抽象出来。
这就是软件的分层
如果你仔细看了上面的示例,基本上就理解了软件分层是什么概念,它其实就是不断地将公共的部分和重复代码提取出来,将其作为一个统一的模块,向外提供访问的接口。
从宏观上来看程序就被分成了两部分,由于是调用与被调用的关系,所以层次结构可以更明显地体现他们之间的关系。
分层的好处
最直观地看过去,软件分层第一个好处就是节省代码空间,代码量更少,层次更清晰,对于代码的可读性和后期的维护都是非常大的好处。
将相关的数据和操作封装成一个模块,对外提供接口,屏蔽实现细节,便于移植和协作,因为在移植和修改时,只需要修改当前模块的代码,保持对外接口不变即可,减少了移植和维护成本。
举个例子:在上述的代码中,如果将sht31换成其他i2c设备,我只需要修改设备的操作函数部分,而i2c的读写部分可以复用.又或者同样的设备,切换成了spi协议通信,那么,设备的操作函数部分可以不用修改,只需要将i2c硬件读写换成spi硬件读写。
程序的再次优化
在程序的第一次优化中,i2c被抽象出两层:i2c硬件读写层和i2c的应用层(暂且这么命名吧),读写层只负责读写数据,而应用层则根据不同设备进行不同的读写操作,调用读写层接口。
划分成读写层和驱动层之后,在空间上和程序复用性上已经走了一大步。
但是在之后的开发中又发现一个问题:对于单个的厂商而言,生产的设备往往具有高度相似的寄存器操作方式,比如对于我们常用的sht3x(温湿度传感器)而言,这些系列的传感器设备之间的不同仅仅是测量范围、测量精度的不同,其他的寄存器配置其实是一样的,有经验的程序员就想到可以抽象出这样一个统一接口来针对所有这些同系列设备:
sht3x_init(int sht3x_type,int measurement_range,int resolution){
switch(sht3x_type){
case sht31:
set_measurement_range(sht31,measurement_range);
set_resolution(sht31,resolution);
break;
case sht35:
set_measurement_range(sht35,measurement_range);
set_resolution(sht35,resolution);
break;
case ...
}
}
仅仅是在设置的时候设置不同的测量范围和精度,而其他的设置,数据读写部分都是完全相同的。
对于这些同系列的设备,我们同样可以抽象出一个驱动层,以sht3x为例,同系列设备的操作变成这样:
- i2c硬件读写层。
- sht3x的公共操作函数,通过调用上层接口实现初始化、设置温度阈值等函数。
- 具体设备的操作函数,对于sht31而言,通过传入sht31的参数,调用上层接口来读写sht31中的数据,需要传入的参数主要是i2c地址,设置精度等sht3x系列之间的差异化部分。
这样,对于sht3x而言,用户在使用这一类设备的时候就只需要简单地调用诸如sht3x_init(u8 i2c_addr),sht3x_set_resolution(u8 resolution)这一类的函数即可完成设备的操作,通过传入不同的参数执行不同的操作。
这里贴上一个图来加深理解:

到这里,对于一个单片机上的i2c设备而言,基本上已经有了比较好的层次结构:
- i2c硬件读写层
- 驱动层(主要是解决同系列设备驱动重复的寄存器操作问题)
- 设备层(应用程序调用上一层接口实现具体的设备读写)
将上述分层的1.2步集成到系统中,用户只需要调用相应接口直接就可以操作到设备,对用户来说简化了操作流程,对系统来说节省了程序空间。
到这里,这一份i2c程序就已经比较完善了,当需要添加sht3x设备时,只需要在设备层添加即可。
当需要添加其他i2c设备时,则需要提供驱动层和设备层的实现而复用硬件读写层。
当需要将sht3x驱动程序移植到另一个平台时,只需要修改i2c硬件读写层,因为平台之间的i2c读写操作可能不一致,驱动层和设备层不需要修改。
整个分层的思想就是复用。大大节省了调试时间,在debug的时候也能很方便地定位是哪一部分出了问题,同时可以将程序发布给其他用户,其他用户根据需要可以很方便地进行裁剪移植,避免浪费过多时间在同一件事情上。
再看看linux中的i2c
在单片机上可以碰到的问题,在linux系统上同样能碰到,单片机上运行的程序一般而言不会太庞大,驱动部分更是所占甚微,所以设备驱动程序的好坏并不会太过于影响程序的执行效率。
但是在linux中,有时需要集成大量的驱动设备到系统中,同时内核代码是多人维护的模式,所以也必须采用驱动分层的模式来提高内存使用效率,降低程序耦合性。
那么,在linux中是否也是像单片机中一样分为i2c硬件读写层、驱动层、设备层即可呢?
其实大致的思想是一样的:将硬件读写抽象成一层,将同系列产品驱动抽象成一层,将具体设备的添加抽象成顶层,但是具体实现完全不一样。
与单片机中程序不一样的是:linux中内核空间和用户空间是区分开来的,驱动程序将会被加载到内核中,提供接口给用户进行操作。
从单片机切换到linux的第一种解决方案
不难想到的解决方案是:分层模型不变,将上述分层中的设备层改为由驱动层直接在用户空间注册文件接口,用户程序通过用户文件对设备进行操作。
于是,分层模型变成了这样:
- i2c硬件读写层
- 驱动层(主要是解决同系列设备驱动重复问题,同时在用户空间注册用户接口以供访问)
- 应用层(相对于内核而言,等于单片机分层中的设备层,应用程序通过操作文件调用上一层接口实现具体的设备读写)
问题就这样得到解决。
用户在操作用户空间文件接口的时候,依次地通过文件接口传递目标设备的资源对设备进行初始化,各种设置,然后读写即可,对于sht3x而言,这些资源包括i2c地址、精度、阈值等等。
但是,这样的做法的缺陷是:
- 提高了驱动程序和应用开发的耦合性,同时驱动程序不具有独立性和安全性,程序的可移植性也很差。
- 同时,此时的驱动层对应的是同系列设备,注册到用户空间的接口会更加抽象,用户需要对驱动程序进行二次开发.
想一想,当用户需要使用sht31时,用户还得去阅读sht31的datasheet来查看并设置各种参数,这样驱动和用户程序不分离完全不符合高内聚低耦合的程序思想。
最理想的状态自然是:
- 驱动程序本身和驱动程序需要的资源由内核统一管理,这样才能提高驱动和管理资源的独立性,并且拥有较好的额可移植性和安全性,提供尽量简单的操作接口给用户空间。
- 用户空间只需要直接使用驱动,而不需要对驱动程序进行二次开发。
第二种解决方案
既然驱动部分无法针对单一设备,而是针对诸如sht3x这一类设备,那我们为每个单一设备添加一份描述设备信息来提供资源(i2c地址等),比如sht31、sht35分别提供一份设备描述信息,而一个驱动程序可以对应多份设备描述信息。
当需要使用某个具体设备比如sht31时,再将sht31的设备描述信息和sht3x的驱动程序结合起来,生成一个完整的sht31设备驱动程序,并在用户空间注册sht31文件接口,这样文件接口就可以针对具体的设备而实现具体的操作功能,用户可以通过简单的参数选择而直接使用。
同时将设备描述信息同时注册到内核中,由内核统一管理,提高了驱动和资源管理的独立性和安全性,同时移植性能较好。
这样,在分层模型中,我们将设备描述信息(设备资源)部分和驱动程序放置在同一层,驱动模型就变成了这样:
- i2c硬件读写层
- 驱动部分(提供系列设备的公共驱动部分)-------设备部分(提供单一设备的资源,驱动程序获取资源进行相应配置,与驱动层为一对多的关系),统称为驱动层
- 应用层(通过上层提供的接口对设备进行访问)
这样的分层有个好处,在第二层驱动层中,直接实现了每个单一设备的程序,对应用层提供简便的访问接口,这样在用户层不用再进行复杂的设置,就可以直接对设备进行读写。
它的分层是这样的:
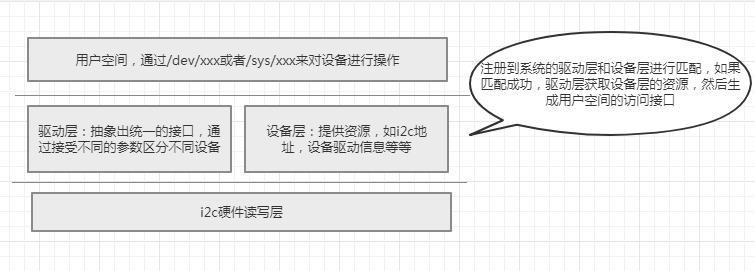
i2c硬件读写层
linux i2c设备驱动程序中的硬件读写层由struct i2c_adapter来描述,它的内容是这样的:
struct i2c_adapter {
...
const struct i2c_algorithm algo; / the algorithm to access the bus */
void *algo_data;
int nr;
char name[48];
...
};
其中struct i2c_algorithm *algo结构体中master_xfer函数指针指向i2c的硬件读写函数,我们可以简单地认为一个struct i2c_adapter结构体描述一个硬件i2c控制器。在驱动编写的过程中,这一层的实现由系统提供。驱动编写者只需要调用i2c_get_adapter()接口来获取相应的adapter.
驱动层(中间层,包含设备部分和驱动部分)
linux总线机制
在上面的分层讨论中可知:驱动层由驱动部分和设备部分组成,驱动部分由struct i2c_driver描述,而设备部分由struct i2c_device部分组成。
这两部分虽然被我们分在同一层,但是这是相互独立的,当添加进一个device或者driver,会根据某些条件寻找匹配的driver或者device,那这一部分匹配谁来做呢?
这就不得不提到linux中的总线机制,i2c总线担任了这个衔接的角色,诚然,i2c总线也属于总线的一种,i2c总线在系统启动时被注册到系统中,管理i2c设备。
我们先来看看描述总线的结构体:
struct bus_type {
....
const char *name;
int (*match)(struct device *dev, struct device_driver *drv);
int (*uevent)(struct device *dev, struct kobj_uevent_env *env);
int (*probe)(struct device *dev);
int (*remove)(struct device *dev);
void (*shutdown)(struct device *dev);
int (*online)(struct device *dev);
int (*offline)(struct device *dev);
int (*suspend)(struct device *dev, pm_message_t state);
int (*resume)(struct device *dev);
struct subsys_private *p;
};
struct subsys_private {
...
struct klist klist_devices;
struct klist klist_drivers;
unsigned int drivers_autoprobe:1;
...
};
这个结构体描述了linux中各种各样的sub bus,比如spi,i2c,platform bus,可以看到,这个结构体中有一系列的函数,在struct subsys_private结构体定义的指针p中,有struct klist klist_devices和struct klist klist_drivers这两项。
当我们向i2c bus注册一个driver时,这个driver被添加到klist_drivers这个链表中,当向i2c bus注册一个device时,这个device被添加到klist_devices这个链表中。
每有一个添加行为,都将调用总线的match函数,遍历两个链表,为新添加的device或者driver寻找对应的匹配,一旦匹配上,就调用probe函数,在probe函数中执行设备的初始化和创建用户操作接口。
应用层
在总线的(或者驱动部分的)probe函数被执行时,在/dev目录下创建对应的文件,例如/dev/sht3x,用户程序通过读写/dev/sht3x文件来操作设备。
同时,也可以在/sys目录下生成相应的操作文件来操作设备,应用层直接面对用户,所以接口理应是简单易用的。
驱动开发者的工作
一般来说,如果只是开发i2c驱动,而不需要为新的芯片移植驱动的话,我们只需要在驱动层做相应的工作,并向应用层提供接口。i2c硬件读写层已经集成在系统中。
抽象化仍在进行中
上文中提到,当驱动开发者想要开发驱动时,在驱动层编写一个driver部分,添加到i2c总线中,同时编写一个device部分,添加到i2c总线中。
driver部分主要包含了所有的操作接口,而device部分提供相应的资源。
但是,随着设备的增长,同时由于device部分总是静态定义在文件中,导致这一部分占用的内核空间越来越大,而且,最主要的问题时,对于资源来说,大多都是一些重复的定义:比如时钟、定时器、引脚中断、i2c地址等同类型资源。
按照一贯的风格,对于大量的重复定义,我们必须对其进行抽象化,于是linus一怒之下对其进行大刀阔斧的整改,于是设备树横空出世,是的,设备树就是针对各种总线(i2c bus,platform bus等等)的device资源部分进行整合。
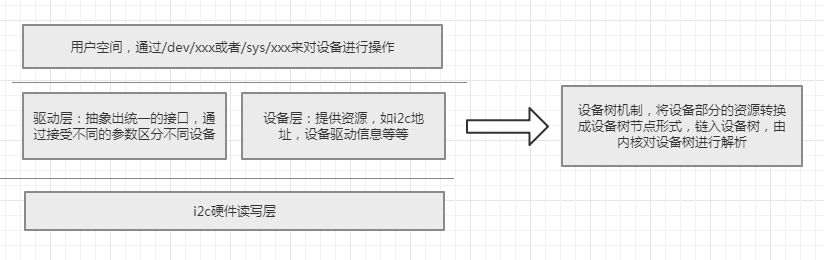
将设备部分的静态描述转换成设备树的形式,由内核在加载时进行解析,这样节省了大量的空间。
如果有兴趣可以看看博主的设备树解析篇:linux设备树解析--从dtb格式开始
小结
总的来说,分层即是一种抽象,将重复部分的代码不断地提取出来作为一个独立的模块,因为模块之间是调用与被调用的关系,所以看起来就是一种层次结构。
高内聚,低耦合,这是程序设计界的六字箴言。
不管是linux还是其他操作系统,又或者是其他应用程序,将程序模块化都是一种很好的编程习惯,linux内核的层次结构也是这种思想的产物。
这篇文章只是简单地分析了linux分层机制的由来,从原理上理解为什么会有这样的层次结构,事实上,由于linux系统的复杂性,linux的驱动框架并非这么简单地分成三个部分,博主只是抽去了大部分细节,展现了最粗犷的框架。
接下来,博主还会带你走进linux内核代码,剖析整个i2c框架的函数调用流程。
好了,关于linux驱动框架的讨论就到此为止啦,如果朋友们对于这个有什么疑问或者发现有文章中有什么错误,欢迎留言
原创博客,转载请注明出处!
祝各位早日实现项目丛中过,bug不沾身.
linux设备驱动程序--串行通信驱动框架分析的更多相关文章
- linux设备驱动程序-i2c(2)-adapter和设备树的解析
linux设备驱动程序-i2c(2)-adapter和设备树的解析 (注: 基于beagle bone green开发板,linux4.14内核版本) 在本系列linux内核i2c框架的前两篇,分别讲 ...
- linux设备驱动程序-i2c(1):i2c总线的添加与实现
linux设备驱动程序-i2c(1):i2c总线的添加与实现 (基于4.14内核版本) 在上一章节linux设备驱动程序-i2c(0)-i2c设备驱动源码实现中,我们演示了i2c设备驱动程序的源码实现 ...
- Linux USB驱动框架分析 【转】
转自:http://blog.chinaunix.net/uid-11848011-id-96188.html 初次接触与OS相关的设备驱动编写,感觉还挺有意思的,为了不至于忘掉看过的东西,笔记跟总结 ...
- Linux USB驱动框架分析【转】
转自:http://blog.csdn.net/jeffade/article/details/7701431 Linux USB驱动框架分析(一) 初次接触和OS相关的设备驱动编写,感觉还挺有意思的 ...
- Linux USB驱动框架分析(2)【转】
转自:http://blog.chinaunix.net/uid-23046336-id-3243543.html 看了http://blog.chinaunix.net/uid-11848011 ...
- linux驱动基础系列--linux spi驱动框架分析
前言 主要是想对Linux 下spi驱动框架有一个整体的把控,因此会忽略某些细节,同时里面涉及到的一些驱动基础,比如平台驱动.设备模型等也不进行详细说明原理.如果有任何错误地方,请指出,谢谢! spi ...
- 【原创】Linux PCI驱动框架分析(二)
背 景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本 ...
- linux设备驱动程序该添加哪些头文件以及驱动常用头文件介绍(转)
原文链接:http://blog.chinaunix.net/uid-22609852-id-3506475.html 驱动常用头文件介绍 #include <linux/***.h> 是 ...
- linux驱动基础系列--linux spi驱动框架分析(续)
前言 这篇文章是对linux驱动基础系列--linux spi驱动框架分析的补充,主要是添加了最新的linux内核里设备树相关内容. spi设备树相关信息 如之前的文章里所述,控制器的device和s ...
随机推荐
- yandex 图片自动下载
yandex 图片自动下载命令行程序 一个在 yandex 上搜索图片并下载到本地的 node cli 程序. 使用帮助: $0 <搜索关键词> [-t=超时(默认 1000)] [-r ...
- SpringBoot示例教程(一)MySQL与Mybatis基础用法
示例需求 在Springboot2框架中,使用Mysql和Mybatis功能:1. Mysql+Datasource集成2. Mybatis+XML用法详解 数据库准备 采用了Oracle中的scot ...
- centos7如何将docker容器配置成开机自启动
docker 服务器开机自启动: 1.systemctl is-enabled docker.service 检查服务是否开机启动 2.systemctl enable docker.service ...
- JS增删改查localStorage实现搜索历史功能
<script type="text/javascript"> var referrerPath = "@ViewBag.ReferrerPath" ...
- linux CC攻击解决方法
linux CC攻击1 由于不断的请求接口 导致带宽不足 然后不断的运行mysql语句 造成cpu饱和 这个时候服务器重负不堪 导致运行代码暖慢 导致入侵 一般采取的方法http://newmirac ...
- java中参数" ..."的用法和意思
public static void executebindParam(PreparedStatement pstmt,Object ...os){ int len = os.length; try ...
- 【Tyvj2046】掷骰子
好水一道题 掷骰子Description Rainbow和Freda通过一次偶然的机会来到了魔界.魔界的大门上赫然写着:小盆友们,欢迎来到魔界~!乃们需要解决这样一个问题才能进入哦lala~有N枚骰子 ...
- 快速排序(Quick Sort)C语言
已知数组 src 如下: [5, 3, 7, 6, 4, 1, 0, 2, 9, 10, 8] 快速排序1 在数组 src[low, high] 中,取 src[low] 作为 关键字(key) . ...
- B站动态转发抽奖脚本+教程
运行python脚本需要的条件: 1.连通的网络 2.已安装Python2并配置环境变量 3.Python脚本源码 环境搭建: 网络就不用我说了("'▽'") 那么下面我们来安装 ...
- Go基础编程实践(七)—— 并发
同时运行多个函数 观察常规代码和并发代码的输出顺序. // 常规代码,顺序执行,依次输出 package main import ( "fmt" "time" ...