Python爬虫系列:五、正则表达式
1.了解正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式是用来匹配字符串非常强大的工具,在其他编程语言中同样有正则表达式的概念,Python同样不例外,利用了正则表达式,我们想要从返回的页面内容提取出我们想要的内容就易如反掌了。
正则表达式的大致匹配过程是:
1.依次拿出表达式和文本中的字符比较,
2.如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
3.如果表达式中有量词或边界,这个过程会稍微有一些不同。
2.正则表达式的语法规则
请自行百度,有更详细的讲解。
3.Python Re模块
(1)re.match(pattern, string[, flags])
Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
属性:
1.string: 匹配时使用的文本。
2.re: 匹配时使用的Pattern对象。
3.pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
4.endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
5.lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
6.lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。方法:
1.group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
2.groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
3.groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
4.start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
5.end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
6.span([group]):
返回(start(group), end(group))。
7.expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;但\10将被认为是第10个分组,如果你想表达\1之后是字符’0’,只能使用\g0。
下面我们用一个例子来体会一下

(2)re.search(pattern, string[, flags])
search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。

(3)re.split(pattern, string[, maxsplit])
按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
(4)re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。

(5)re.finditer(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
(6)re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串。
当repl是一个字符串时,可以使用\id或\g、\g引用分组,但不能使用编号0。
当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
(7)re.subn(pattern, repl, string[, count])
返回 (sub(repl, string[, count]), 替换次数)。
5.Python Re模块的另一种使用方式
在上面我们介绍了7个工具方法,例如match,search等等,不过调用方式都是 re.match,re.search的方式,其实还有另外一种调用方式,可以通过pattern.match,pattern.search调用,这样调用便不用将pattern作为第一个参数传入了,大家想怎样调用皆可。
函数API列表
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
split(string[, maxsplit]) | re.split(pattern, string[, maxsplit])
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
finditer(string[, pos[, endpos]]) | re.finditer(pattern, string[, flags])
sub(repl, string[, count]) | re.sub(pattern, repl, string[, count])
subn(repl, string[, count]) |re.sub(pattern, repl, string[, count])
下面放出本文源代码
import re pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!' print(re.subn(pattern,r'\2 \1', s)) def func(m):
return m.group(1).title() + ' ' + m.group(2).title() print(re.subn(pattern,func, s)) ### output ###
# ('say i, world hello!', 2)
# ('I Say, Hello World!', 2) '''
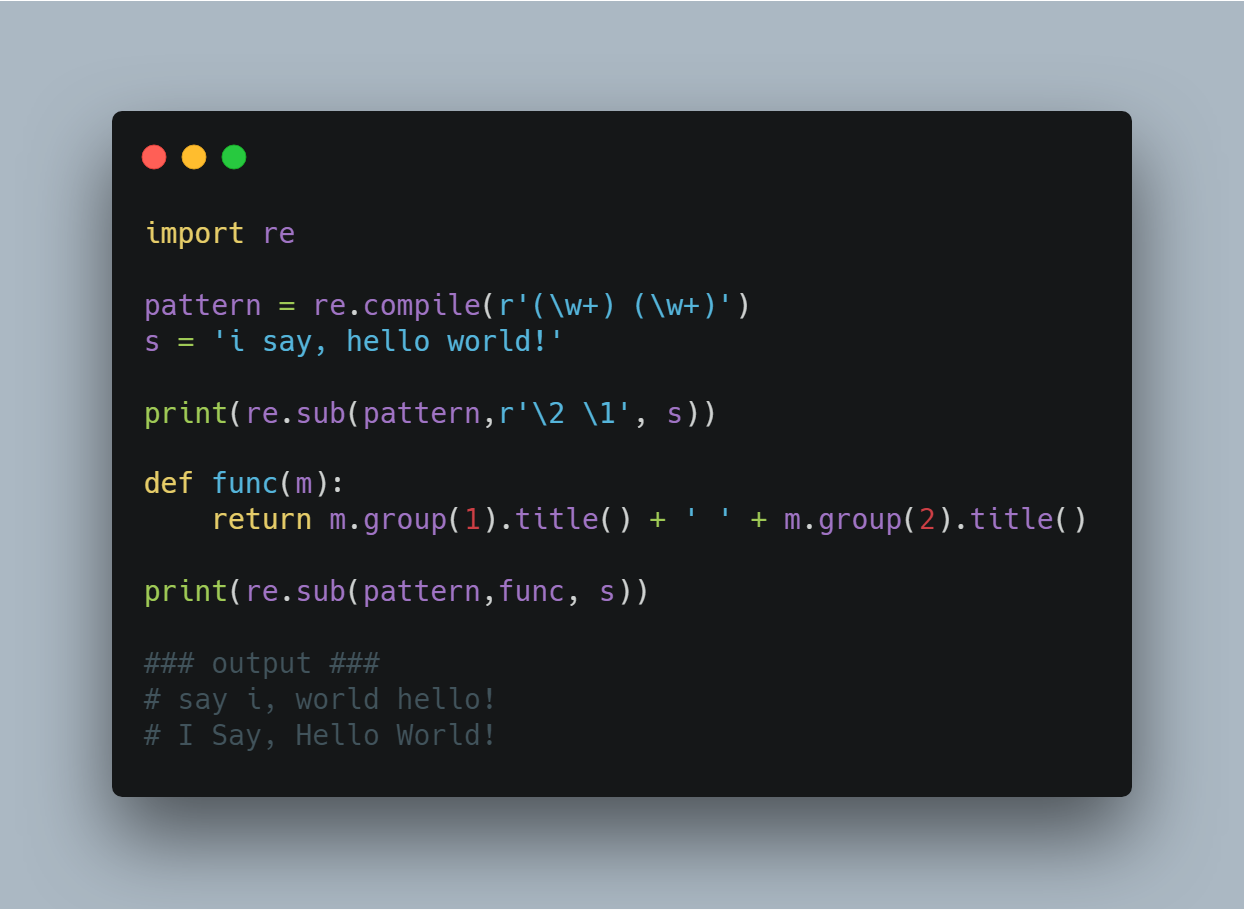
import re pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world!' print(re.sub(pattern,r'\2 \1', s)) def func(m):
return m.group(1).title() + ' ' + m.group(2).title() print(re.sub(pattern,func, s)) ### output ###
# say i, world hello!
# I Say, Hello World!
'''
'''
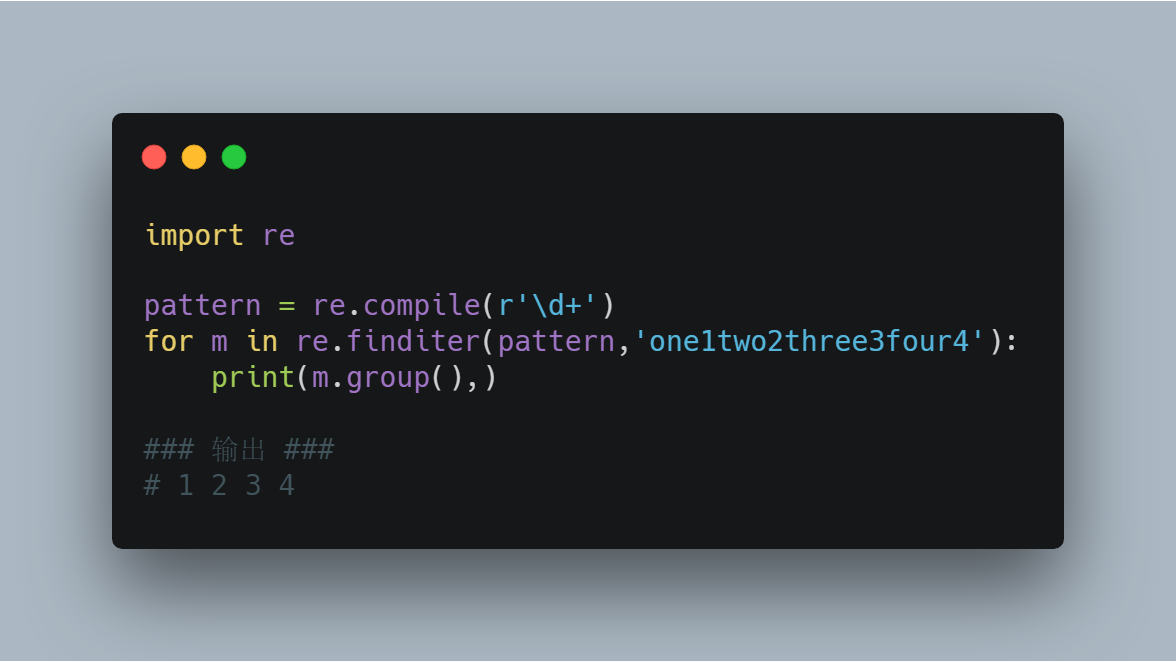
import re pattern = re.compile(r'\d+')
for m in re.finditer(pattern,'one1two2three3four4'):
print(m.group(),) ### 输出 ###
# 1 2 3 4
''' '''
import re pattern = re.compile(r'\d+')
print(re.findall(pattern,'one1two2three3four4')) ### 输出 ###
# ['1', '2', '3', '4'] '''
'''
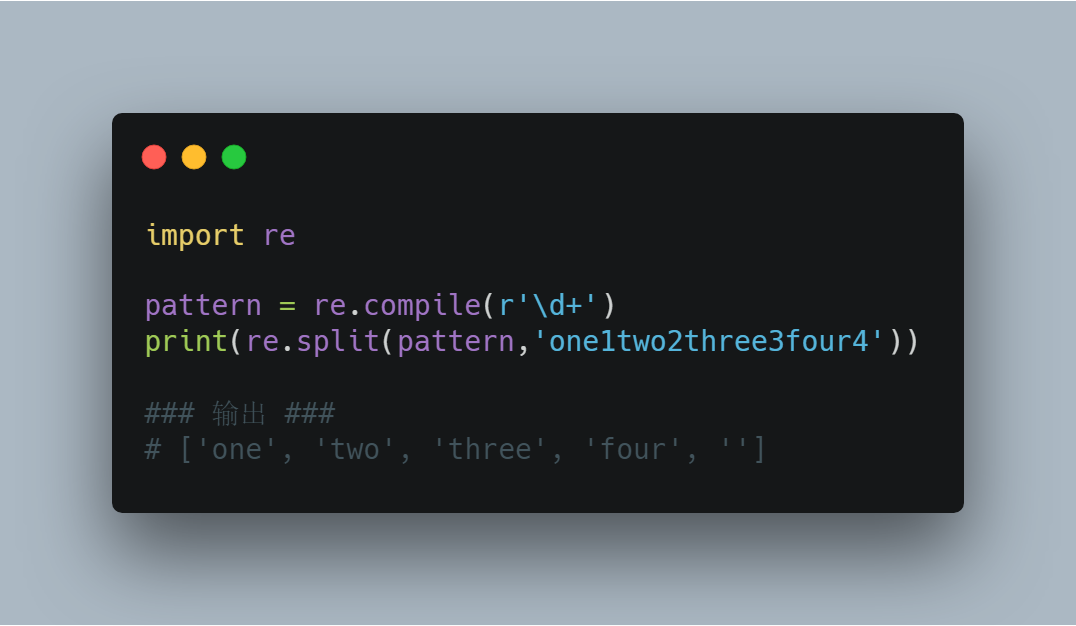
import re pattern = re.compile(r'\d+')
print(re.split(pattern,'one1two2three3four4')) ### 输出 ###
# ['one', 'two', 'three', 'four', '']
'''
'''
# -*- coding: utf-8 -*-
#导入re模块
import re # 将正则表达式编译成Pattern对象
pattern = re.compile(r'world')
# 使用search()查找匹配的子串,不存在能匹配的子串时将返回None
# 这个例子中使用match()无法成功匹配
match = re.search(pattern,'hello world!')
if match:
# 使用Match获得分组信息
print(match.group())
### 输出 ###
# world
''' '''
# -*- coding: utf-8 -*-
#一个简单的match实例 import re
# 匹配如下内容:单词+空格+单词+任意字符
m = re.match(r'(\w+) (\w+)(?P<sign>.*)', 'hello world!') print("m.string:", m.string)
print("m.re:", m.re)
print("m.pos:", m.pos)
print("m.endpos:", m.endpos)
print("m.lastindex:", m.lastindex)
print("m.lastgroup:", m.lastgroup)
print("m.group():", m.group())
print("m.group(1,2):", m.group(1, 2))
print("m.groups():", m.groups())
print("m.groupdict():", m.groupdict())
print("m.start(2):", m.start(2))
print("m.end(2):", m.end(2))
print("m.span(2):", m.span(2))
print(r"m.expand(r'\g \g\g'):", m.expand(r'\2 \1\3')) ### output ###
# m.string: hello world!
# m.re:
# m.pos: 0
# m.endpos: 12
# m.lastindex: 3
# m.lastgroup: sign
# m.group(1,2): ('hello', 'world')
# m.groups(): ('hello', 'world', '!')
# m.groupdict(): {'sign': '!'}
# m.start(2): 6
# m.end(2): 11
# m.span(2): (6, 11)
# m.expand(r'\2 \1\3'): world hello!
'''
'''
# -*- coding: utf-8 -*- #导入re模块
import re # 将正则表达式编译成Pattern对象,注意hello前面的r的意思是“原生字符串”
pattern = re.compile(r'hello') # 使用re.match匹配文本,获得匹配结果,无法匹配时将返回None
result1 = re.match(pattern,'hello')
result2 = re.match(pattern,'helloo 113!')
result3 = re.match(pattern,'helo 222!')
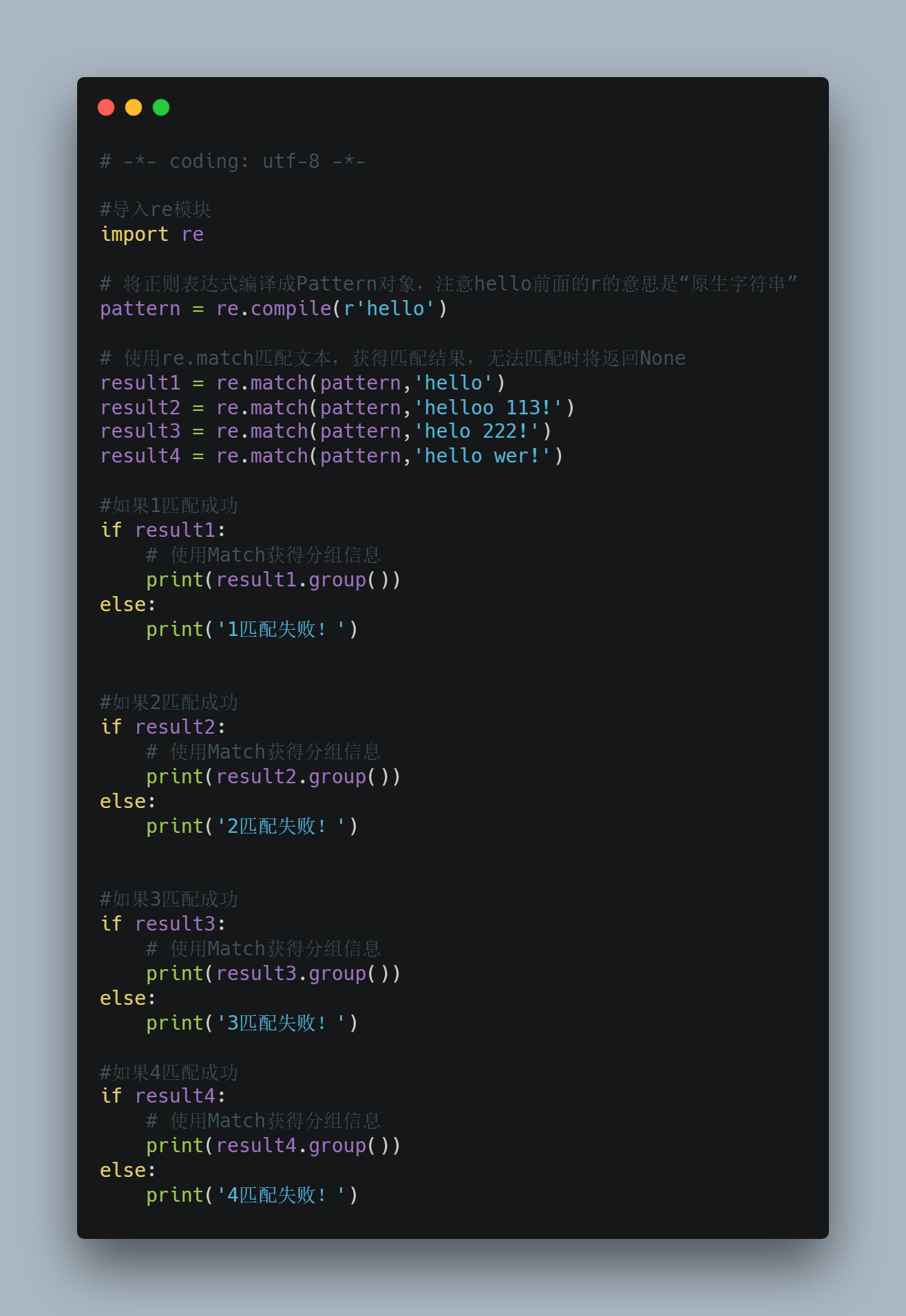
result4 = re.match(pattern,'hello wer!') #如果1匹配成功
if result1:
# 使用Match获得分组信息
print(result1.group())
else:
print('1匹配失败!') #如果2匹配成功
if result2:
# 使用Match获得分组信息
print(result2.group())
else:
print('2匹配失败!') #如果3匹配成功
if result3:
# 使用Match获得分组信息
print(result3.group())
else:
print('3匹配失败!') #如果4匹配成功
if result4:
# 使用Match获得分组信息
print(result4.group())
else:
print('4匹配失败!')
'''
Python爬虫系列:五、正则表达式的更多相关文章
- 爬虫系列(五) re的基本使用
1.简介 究竟什么是正则表达式 (Regular Expression) 呢?可以用下面的一句话简单概括: 正则表达式是一组特殊的 字符序列,由一些事先定义好的字符以及这些字符的组合形成,常常用于 匹 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- python爬虫之re正则表达式库
python爬虫之re正则表达式库 正则表达式是用来简洁表达一组字符串的表达式. 编译:将符合正则表达式语法的字符串转换成正则表达式特征 操作符 说明 实例 . 表示任何单个字符 [ ] 字符集,对单 ...
- Python爬虫进阶五之多线程的用法
前言 我们之前写的爬虫都是单个线程的?这怎么够?一旦一个地方卡到不动了,那不就永远等待下去了?为此我们可以使用多线程或者多进程来处理. 首先声明一点! 多线程和多进程是不一样的!一个是 thread ...
- Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 转 Python爬虫入门五之URLError异常处理
静觅 » Python爬虫入门五之URLError异常处理 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中, ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- python 爬虫系列教程方法总结及推荐
爬虫,是我学习的比较多的,也是比较了解的.打算写一个系列教程,网上搜罗一下,感觉别人写的已经很好了,我没必要重复造轮子了. 爬虫不过就是访问一个页面然后用一些匹配方式把自己需要的东西摘出来. 而访问页 ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
随机推荐
- linux tomcat 文件切割
修改bin目录下catalina.sh if [ -z "$CATALINA_OUT" ] ; then CATALINA_OUT="$CATALINA_BASE&quo ...
- mysql时间和本地时间相差13个小时的问题
首先需要查看mysql的当前时区,用time_zone参数 mysql> show variables like '%time_zone%'; +------------------+----- ...
- linux里安装使用svn
1.安装 sudo apt-get install subversion 2.checkout工程 svn checkout svn://192.168.0.3/测试工具 /home/testtool ...
- python 使用 elasticsearch 常用方法(检索)
#记录es查询等方法 #清楚数据 curl -XDELETE http://xx.xx.xx.xx:9200/test6 #初始化数据 curl -H "Content-Type: appl ...
- Airflow使用指南
1.只执行单个任务 将downstream和recursive按钮的点击状态取消,然后点击clear,最后点击run
- [Golang] http.Post导致goroutine泄漏
记录一个用http.Post的问题 if _, err := http.Post("http://127.0.0.1:8080", "", nil); nil ...
- 在日志中记录Java异常信息的正确姿势
遇到的问题 今天遇到一个线上的BUG,在执行表单提交时失败,但是从程序日志中看不到任何异常信息. 在Review源代码时发现,当catch到异常时只是输出了e.getMessage(),如下所示: l ...
- [LeetCode] 641.Design Circular Deque 设计环形双向队列
Design your implementation of the circular double-ended queue (deque). Your implementation should su ...
- Spring的@Autowired和@Resource注入
@Autowired的原理 Spring@Autowired注解与自动装配 @Autowired 与@Resource的区别(详细) spring不但支持自己定义的@Autowired注解,还支持几个 ...
- 关闭正在执行的事务 Kill
.模拟资源锁定 --开始事务BEGIN TRANSACTION--更新数据update Table_1 set FuncName=FuncName--等待1分钟WAITFOR DELAY '01:00 ...