spark——故障排除
故障排除一:控制reduce端缓冲大小以避免OOM
在Shuffle过程,reduce端task并不是等到map端task将其数据全部写入磁盘后再去拉取,而是map端写一点数据,reduce端task就会拉取一小部分数据,然后立即进行后面的聚合、算子函数的使用等操作。
reduce端task能够拉取多少数据,由reduce拉取数据的缓冲区buffer来决定,因为拉取过来的数据都是先放在buffer中,然后再进行后续的处理,buffer的默认大小为48MB。
reduce端task会一边拉取一边计算,不一定每次都会拉满48MB的数据,可能大多数时候拉取一部分数据就处理掉了。
虽然说增大reduce端缓冲区大小可以减少拉取次数,提升Shuffle性能,但是有时map端的数据量非常大,写出的速度非常快,此时reduce端的所有task在拉取的时候,有可能全部达到自己缓冲的最大极限值,即48MB,此时,再加上reduce端执行的聚合函数的代码,可能会创建大量的对象,这可难会导致内存溢出,即OOM。
如果一旦出现reduce端内存溢出的问题,我们可以考虑减小reduce端拉取数据缓冲区的大小,例如减少为12MB。
在实际生产环境中是出现过这种问题的,这是典型的以性能换执行的原理。reduce端拉取数据的缓冲区减小,不容易导致OOM,但是相应的,reudce端的拉取次数增加,造成更多的网络传输开销,造成性能的下降。
注意,要保证任务能够运行,再考虑性能的优化。
故障排除二:JVM GC导致的shuffle文件拉取失败
在Spark作业中,有时会出现shuffle file not found的错误,这是非常常见的一个报错,有时出现这种错误以后,选择重新执行一遍,就不再报出这种错误。
出现上述问题可能的原因是Shuffle操作中,后面stage的task想要去上一个stage的task所在的Executor拉取数据,结果对方正在执行GC,执行GC会导致Executor内所有的工作现场全部停止,比如BlockManager、基于netty的网络通信等,这就会导致后面的task拉取数据拉取了半天都没有拉取到,就会报出shuffle file not found的错误,而第二次再次执行就不会再出现这种错误。
可以通过调整reduce端拉取数据重试次数和reduce端拉取数据时间间隔这两个参数来对Shuffle性能进行调整,增大参数值,使得reduce端拉取数据的重试次数增加,并且每次失败后等待的时间间隔加长。
代码清单4-1 JVM GC导致的shuffle文件拉取失败
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries", "60")
.set("spark.shuffle.io.retryWait", "60s")
故障排除三:解决各种序列化导致的报错
当Spark作业在运行过程中报错,而且报错信息中含有Serializable等类似词汇,那么可能是序列化问题导致的报错。
序列化问题要注意以下三点:
- 作为RDD的元素类型的自定义类,必须是可以序列化的;
- 算子函数里可以使用的外部的自定义变量,必须是可以序列化的;
- 不可以在RDD的元素类型、算子函数里使用第三方的不支持序列化的类型,例如Connection。
故障排除四:解决算子函数返回NULL导致的问题
在一些算子函数里,需要我们有一个返回值,但是在一些情况下我们不希望有返回值,此时我们如果直接返回NULL,会报错,例如Scala.Math(NULL)异常。
如果你遇到某些情况,不希望有返回值,那么可以通过下述方式解决:
- 返回特殊值,不返回NULL,例如“-1”;
2. 在通过算子获取到了一个RDD之后,可以对这个RDD执行filter操作,进行数据过滤,将数值为-1的数据给过滤掉;
3. 在使用完filter算子后,继续调用coalesce算子进行优化。
故障排除五:解决YARN-CLIENT模式导致的网卡流量激增问题
YARN-client模式的运行原理如下图所示:
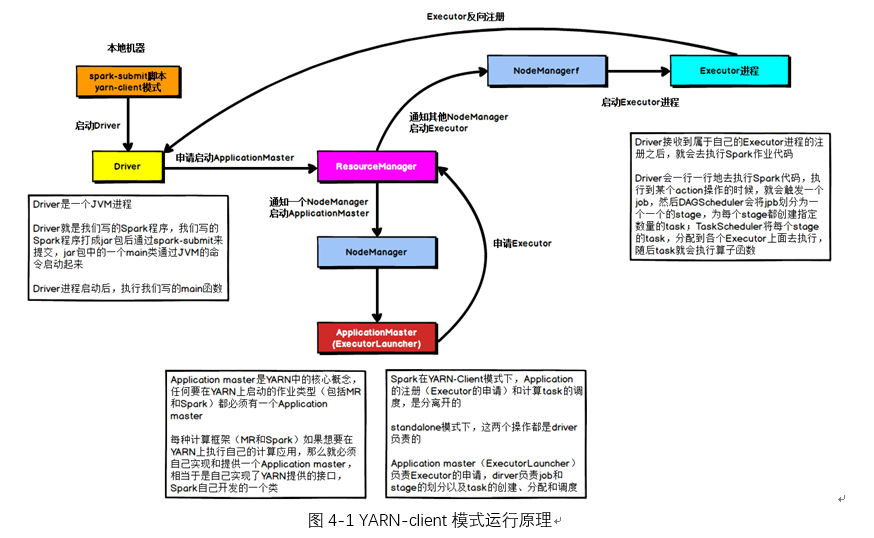
在YARN-client模式下,Driver启动在本地机器上,而Driver负责所有的任务调度,需要与YARN集群上的多个Executor进行频繁的通信。
假设有100个Executor, 1000个task,那么每个Executor分配到10个task,之后,Driver要频繁地跟Executor上运行的1000个task进行通信,通信数据非常多,并且通信品类特别高。这就导致有可能在Spark任务运行过程中,由于频繁大量的网络通讯,本地机器的网卡流量会激增。
注意,YARN-client模式只会在测试环境中使用,而之所以使用YARN-client模式,是由于可以看到详细全面的log信息,通过查看log,可以锁定程序中存在的问题,避免在生产环境下发生故障。
在生产环境下,使用的一定是YARN-cluster模式。在YARN-cluster模式下,就不会造成本地机器网卡流量激增问题,如果YARN-cluster模式下存在网络通信的问题,需要运维团队进行解决。
故障排除六:解决YARN-CLUSTER模式的JVM栈内存溢出无法执行问题
YARN-cluster模式的运行原理如下图所示:
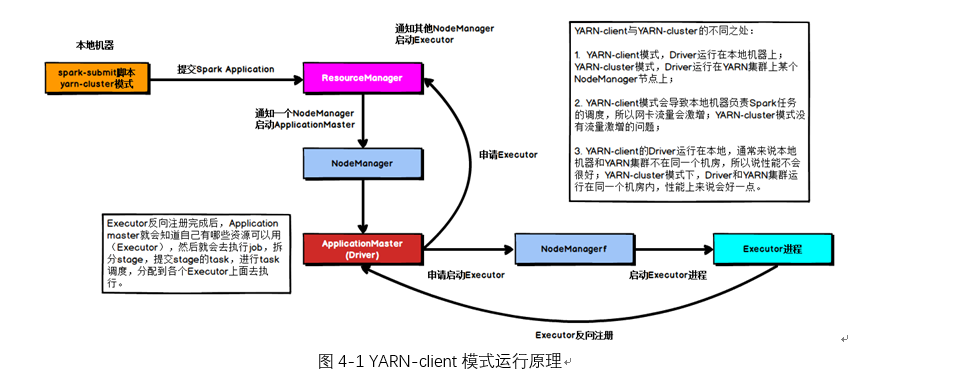
当Spark作业中包含SparkSQL的内容时,可能会碰到YARN-client模式下可以运行,但是YARN-cluster模式下无法提交运行(报出OOM错误)的情况。
YARN-client模式下,Driver是运行在本地机器上的,Spark使用的JVM的PermGen的配置,是本地机器上的spark-class文件,JVM永久代的大小是128MB,这个是没有问题的,但是在YARN-cluster模式下,Driver运行在YARN集群的某个节点上,使用的是没有经过配置的默认设置,PermGen永久代大小为82MB。
SparkSQL的内部要进行很复杂的SQL的语义解析、语法树转换等等,非常复杂,如果sql语句本身就非常复杂,那么很有可能会导致性能的损耗和内存的占用,特别是对PermGen的占用会比较大。
所以,此时如果PermGen的占用好过了82MB,但是又小于128MB,就会出现YARN-client模式下可以运行,YARN-cluster模式下无法运行的情况。
解决上述问题的方法时增加PermGen的容量,需要在spark-submit脚本中对相关参数进行设置,设置方法如代码清单4-2所示。
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"
通过上述方法就设置了Driver永久代的大小,默认为128MB,最大256MB,这样就可以避免上面所说的问题。
故障排除七:解决SparkSQL导致的JVM栈内存溢出
当SparkSQL的sql语句有成百上千的or关键字时,就可能会出现Driver端的JVM栈内存溢出。
JVM栈内存溢出基本上就是由于调用的方法层级过多,产生了大量的,非常深的,超出了JVM栈深度限制的递归。(我们猜测SparkSQL有大量or语句的时候,在解析SQL时,例如转换为语法树或者进行执行计划的生成的时候,对于or的处理是递归,or非常多时,会发生大量的递归)
此时,建议将一条sql语句拆分为多条sql语句来执行,每条sql语句尽量保证100个以内的子句。根据实际的生产环境试验,一条sql语句的or关键字控制在100个以内,通常不会导致JVM栈内存溢出。
故障排除八:持久化与checkpoint的使用
Spark持久化在大部分情况下是没有问题的,但是有时数据可能会丢失,如果数据一旦丢失,就需要对丢失的数据重新进行计算,计算完后再缓存和使用,为了避免数据的丢失,可以选择对这个RDD进行checkpoint,也就是将数据持久化一份到容错的文件系统上(比如HDFS)。
一个RDD缓存并checkpoint后,如果一旦发现缓存丢失,就会优先查看checkpoint数据存不存在,如果有,就会使用checkpoint数据,而不用重新计算。也即是说,checkpoint可以视为cache的保障机制,如果cache失败,就使用checkpoint的数据。
使用checkpoint的优点在于提高了Spark作业的可靠性,一旦缓存出现问题,不需要重新计算数据,缺点在于,checkpoint时需要将数据写入HDFS等文件系统,对性能的消耗较大。
spark——故障排除的更多相关文章
- spark 性能优化 数据倾斜 故障排除
版本:V2.0 第一章 Spark 性能调优 1.1 常规性能调优 1.1.1 常规性能调优一:最优资源配置 Spark性能调优的第一步,就是为任务分配更多的资源,在一定范围 ...
- 理解 OpenStack + Ceph (7): Ceph 的基本操作和常见故障排除方法
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成: (1)安装和部署 (2)Ceph RBD 接口和工具 (3)Ceph 物理和逻辑结构 (4)Ceph 的基础数据结构 ...
- 细化如何安装LNMP + Zabbix 监控安装文档以及故障排除
1.LNMP所需安装包: 上传如下软件包到/soft目录中 mysql- (centos6. 64位自带)也可根据版本自行挑选,前提你了解这个版本 pcre-8.36.tar.gz nginx-.ta ...
- 第十篇 Replication:故障排除
本篇文章是SQL Server Replication系列的第十篇,详细内容请参考原文. 复制故障排除是一项艰巨的任务.在任何复制设置中,都涉及到很多移动部件,而可用的工具并不总是很容易识别问题.Th ...
- 《DevOps故障排除:Linux服务器运维最佳实践》读书笔记
首先,这本书是Linux.CN赠送的,多谢啦~ http://linux.cn/thread-12733-1-1.html http://linux.cn/thread-12754-1-1.html ...
- 利用Ring Buffer在SQL Server 2008中进行连接故障排除
原文:利用Ring Buffer在SQL Server 2008中进行连接故障排除 出自:http://blogs.msdn.com/b/apgcdsd/archive/2011/11/21/ring ...
- JVMTI 中间JNI系列功能,线程安全和故障排除技巧
JVMTI 中间JNI系列功能,线程安全和故障排除技巧 jni functions 在使用 JVMTI 的过程中,有一大系列的函数是在 JVMTI 的文档中 没有提及的,但在实际使用却是很实用的. 这 ...
- android 布局页面文件出错故障排除Exception raised during rendering: java.lang.System.arraycopy([CI[CII)V
今天在看布局文件的时候出现 android 布局页面文件出错故障排除Exception raised during rendering: java.lang.System.arraycopy([CI[ ...
- Linux系统之TroubleShooting(故障排除)(转)
尽管Linux系统非常强大,稳定,但是我们在使用过程当中,如果人为操作不当,仍然会影响系统,甚至可能使得系统无法开机,无法运行服务等等各种问题.那么这篇博文就总结一下一些常见的故障排除方法,但是不可能 ...
随机推荐
- AntDesign vue学习笔记(九)自定义文件上传
第七节时提到,上传文件时实际可能需要传输一个token. 1.查看vue antdesign文档https://vue.ant.design/components/upload-cn/ 2.使用cus ...
- spring 事件使用
1.事件定义 import lombok.Data; import org.springframework.context.ApplicationEvent; /** * 事件定义,这里监听MsgMe ...
- Webstorm关闭ESLint警告
使用Webstorm新创建的VUE项目在npm run dev的时候老是报各种格式问题i:比如多个一个空格?多了一行?分号问题?.....简直是受不鸟... 是因为你使用了eslint,这个是esli ...
- HDU校赛 | 2019 Multi-University Training Contest 4
2019 Multi-University Training Contest 4 http://acm.hdu.edu.cn/contests/contest_show.php?cid=851 100 ...
- SQL Server返回DATETIME类型,年、月、日、时、分、秒、毫秒
SQL Server返回DATETIME类型的年.月.日,有两种方法,如下所示: DECLARE @now DATETIME=GETDATE() --第一种方法 SELECT @now,YEAR(@n ...
- 深入理解TCP/IP传输层
传输层:负责数据能够从发送端传到接收端(只需要关注点对点的传输,中间的传输过程一概不管) UDP和TCP UDP(全双工):1.无连接,2不可靠,3.面向数据报 分别表示UDP源端口号.目的端口号.U ...
- Oracle使用中的常规操作总结
写一篇在使用Oracle过程中一些常用的操作,以便于忘记的时候查看 一.创建用户和给用户赋予权限 create user 用户名 identified by 密码; --12c一下版本 create ...
- Java自学-JDK环境变量配置
JDK环境变量配置 分下载,配置,验证三个步骤进行JDK环境变量配置. 步骤 1 : 首先看配置成功后的效果 点WIN键->运行(或者使用win+r) 输入cmd命令 输入java -versi ...
- 树莓派Raspbian系统密码
树莓派Raspbian系统密码 树莓派Raspbian系统默认登录用户名为pi,该账户默认密码是raspberry(可在raspi-config中修改). 树莓派的Raspbian系统root用户默认 ...
- JavaWeb第一天--HTML
HTML HTML简介 HTML(Hyper TextMarkupLanguage) 超文本标记语言. 超文本: 超越了文本仅仅展示信息的功能范畴,泛指:图片.有样式的文字.超链接. 标记: 标签. ...