Spark(五十二):Spark Scheduler模块之DAGScheduler流程
导入
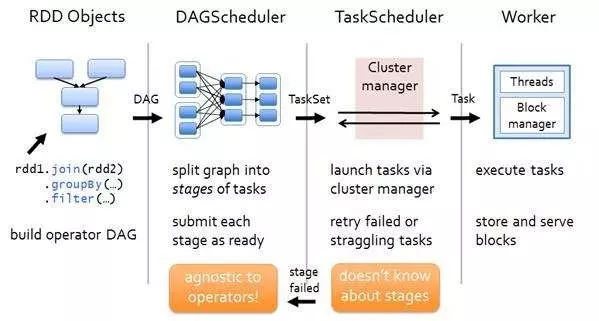
从一个Job运行过程中来看DAGScheduler是运行在Driver端的,其工作流程如下图:
图中涉及到的词汇概念:
1. RDD——Resillient Distributed Dataset 弹性分布式数据集。
2. Operation——作用于RDD的各种操作分为transformation和action。
3. Job——作业,一个JOB包含多个RDD及作用于相应RDD上的各种operation。
4. Stage——一个作业分为多个阶段。
5. Partition——数据分区, 一个RDD中的数据可以分成多个不同的区。
6. DAG——Directed Acycle graph,有向无环图,反应RDD之间的依赖关系。
7. Narrow dependency——窄依赖,子RDD依赖于父RDD中固定的data partition。
8. Wide Dependency——宽依赖,子RDD对父RDD中的所有data partition都有依赖。
9. Caching Managenment——缓存管理,对RDD的中间计算结果进行缓存管理以加快整体的处理速度。
在Driver端,运行一个job时,涉及到DAGSheduler的流程如下:
1)调用applicaiton_jar.jar(应用程序入口函数),应用程序的运行过程依赖SparkContext,且需要初始化SparkContext sc,通过sc就可以创建RDD了(因为RDD是调用sc来创建的);
2)初始化SparkContext过程中会初始化DAGScheduler,并调用SparkContext.createTaskScheduler(this, master, deployMode)来初始化TaskScheduler、ShedulerBackend;
3)应用程序实际上是执行的RDD的transform或者action函数,当RDD#action函数触发时,实际上这样的action函数内部会调用sc.submitJob(...)方法,在SparkContext#submitJob(...)方法内部会根据action创建ResultStage,并找到其依赖的所有ShuffleMapStage。stage之间按照顺序执行,待前一个stage执行完成成功,才能执行下一个stage,所有stage执行成功后,该job才算执行完成。
4)stage实际上可以看作为TaskSet,它实际上代表的就是一个独立的Task集合,DAGScheduler将调用TaskScheduler来对TaskSet进行作业调度;
5)TaskScheduler调度过程是将task序列化通过RPC传递给Executor,Executor上会使用TaskRunner来运行task;
6)TaskScheduler上task如果运行失败,TaskScheduler会重试处理;同样在stage失败后,DAGScheduler也会触发stage重试处理。需要注意:这里如果stage失败,对当前stage重算,而不是从上一个stage开始,这样也是DAG划分stage的原因。
Spark任务Scheduler实现
Spark任务调用主要实现类包含三个角色:
1)org.apache.spark.scheduler.DAGScheduler
2)org.apache.spark.scheduler.SchedulerBackend
3)org.apache.spark.scheduler.TaskScheduler
TaskScheduler是一个trait,它的作用是从DAGScheduler接收不同的Stage的任务,并向Executor提交这些任务(并为执行特别慢的任务启动备份任务)。TaskScheduler是实现多种任务调度器的集成,TaskSchedulerImpl是唯一的实现。
TaskSchedulerImpl类使用时,必选先调用TaskSchedulerImpl#initialize(backend: SchedulerBackend),TaskSchedulerImpl#start(),然后才可以调用TaskSchedulerImpl#submitTasks(taskSet: TaskSet)来提交任务,从initialize(backend: SchedulerBackend)的参数上可以看出,TaskSchedulerImpl使用过程中需要依赖SchedulerBackend。
实际上,上边提到的TaskScheduler向Executor提交任务需要依赖于SchedulerBackend。
SchedulerBackend也是一个trait,每个SchedulerBackend都会对应一个唯一的TaskScheduler。SchedulerBackend的作用是分配当前可用的资源,为Task分配计算资源(Executor),并在分配的Executor上启动Task。SchedulerBackend的最基本实现类是:CoarseGrainedSchedulerBackend,继承了CoarseGrainedSchedulerBackend的类包含:StandaloneSchedulerBackend、YarnSchedulerBackend,而YarnSchedulerBackend子类包含:YarnClientSchedulerBackend、YarnClusterSchedulerBackend。另外mesos、kubernetes也都包含CoarseGrainedSchedulerBackend的子类:MesosCoarseGrainedSchedulerBackend、KubernetesClusterSchedulerBackend等。
TaskSchedulerImpl在以下几种场景下调用TaskSchedulerImpl#reviveOffers:
1)有新任务提交时;
2)有任务执行失败时;
3)计算节点(Executor)不可用时;
4)某些任务执行过慢而需要重新分配资源时。
DAGScheduler源码分析
DAGScheduler功能:
1)最高层的调度层,实现了stage-oriented(面向阶段)调度。DAGScheduler为每个作业计算出一个描述stages的DAG,跟踪哪些RDD和stage输出实现,并找到运行作业的最小计划。然后,它将stages封装为TaskSets提交给在集群上运行它们的底层TaskScheduler实现(TaskScheduler唯一实现类是TaskSchedulerImpl)。任务集包含完全独立的一组任务,这些任务可以根据群集中已经存在的数据(例如,前几个阶段的映射输出文件)立即运行,但如果此数据不可用,它可能会失败。
2)Spark stages 是将RDD图在Shuffle边界处断开来创建的。具有“窄(narrow)”依赖关系的RDD操作(如map()和filter())在每个阶段中被流水线连接到一组任务中,但是具有shuffle依赖关系的操作需要多个阶段(一个阶段写入一组映射输出文件,另一个阶段在屏障后读取这些文件)。最后,每个阶段将只具有对其他阶段的shuffle依赖,并且可以在其中计算多个操作。这些操作的实际管道化发生在各种RDD的rdd.compute()函数中。
3)除了划分stages的DAG之外,DAGScheduler还根据当前缓存状态确定运行每个task的首选位置,并将这些位置传递给底层TaskScheduler(任务调度器)。此外,它还处理由于shuffle输出文件丢失而导致的故障,在这种情况下,可能需要重新提交旧stages。在内部TaskScheduler会处理stage中不是由shuffle文件丢失引起的失败,它会在取消整个stage之前对每个任务重试几次。
4)要从故障中恢复,同一阶段可能需要多次运行,这称为“attempts”。如果 TaskScheduler 报告某个任务由于前一阶段的映射输出文件丢失而失败,则DAGScheduler将重新提交该丢失的阶段。这是通过具有FetchFailed的CompletionEvent或ExecutorLost事件检测到的。DAGScheduler将等待一小段时间来查看其他节点或任务是否失败,然后为计算丢失任务的任何丢失阶段重新提交TaskSets(任务集)。作为这个过程的一部分,我们可能还必须为以前清理stage objects的旧(已完成)stage创建stage objects。由于stage的旧“attempts”中的任务可能仍在运行,因此必须小心映射在正确的stage对象中接收到的任何事件。
查看此代码时,有几个关键概念:
-Jobs:(由[ActiveJob]表示)是提交给调度程序的顶级工作项。例如,当用户调用诸如count()之类的操作时,作业将通过sc.submitJob()方法提交。每个作业可能需要执行多个阶段来构建中间数据。
-Stages:Stage是一组任务(TaskSet),用于计算作业中的中间结果,其中每个任务在同一个RDD的分区上计算相同的函数。
Stage在shuffle边界处分离,这会引入一个屏障(我们必须等待上一阶段完成获取输出)。
有两种类型的Stage(阶段):【ResultStage】(对于执行操作的最后阶段);【ShuffleMapStage】(为shuffle写入映射输出文件)。
如果这些作业重用同一个RDD,则Stage(阶段)通常在多个作业之间共享。
-Tasks:是单独的工作单元,每个工作单元发送到一台机器。
-Cache tracking: DagScheduler会找出缓存哪些RDD以避免重新计算它们,同样会记住哪些shuffle map stage已经生成了输出文件,以避免重复shuffle的映射端。
-Preferred locations:DAGScheduler还根据其底层RDD的首选位置,或缓存或无序处理数据的位置,计算在阶段中运行每个任务的位置。
-Cleanup:当依赖于它们的正在运行的作业完成时,所有数据结构都会被清除,以防止长时间运行的应用程序中发生内存泄漏。
DAGScheduler构造函数
private[spark] class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging { def this(sc: SparkContext, taskScheduler: TaskScheduler) = {
this(
sc,
taskScheduler,
sc.listenerBus,
sc.env.mapOutputTracker.asInstanceOf[MapOutputTrackerMaster],
sc.env.blockManager.master,
sc.env)
} def this(sc: SparkContext) = this(sc, sc.taskScheduler)
DAGScheduler的构造函数参数解释:
√)sc: SparkContext:当前SparkContext对象,就是applicaiton_jar.jar的main函数调用时初始化的SparkContext对象,而DAGScheduler在SparkContext初始化时初始化的SarpkContext的属性。
√)taskScheduler: TaskScheduler:和DAGScheduler、SchedulerBackend都是在SparkContext初始化时初始化的SparkContext的属性,因此该参数从当前sc内置的taskScheduler获取。
√)listenerBus: LiveListenerBus:异步处理事件的对象,从sc中获取。https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/scheduler/LiveListenerBus.scala
√)mapOutputTracker: MapOutputTrackerMaster:运行在Driver端管理shuffle map task的输出,从sc属性env:SparkEnv的mapOutputTracker属性获取。https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/MapOutputTracker.scala
1)用于跟踪阶段的映射输出位置的Driver-side类。
2)DAGScheduler使用这个类来(取消)注册映射输出状态,并查找用于执行位置感知的减少任务调度的统计信息。
3)ShuffleMapStage使用MapOutputTrackerMaster类跟踪可用/丢失的输出,以确定需要运行哪些任务。
√)blockManagerMaster: BlockManagerMaster:运行在Driver端,管理整个Job的Block信息,从sc中env.blockManager.master获取。https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/storage/BlockManagerMaster.scala
√)env: SparkEnv:Spark的运行环境,从sc的env属性获取。
DAGScheduler属性
在DAGScheduler的源代码中,定义了很多属性,这些属性在DAGScheduler初始化时被初始化。
private[spark] val metricsSource: DAGSchedulerSource = new DAGSchedulerSource(this) private[scheduler] val nextJobId = new AtomicInteger(0)
private[scheduler] def numTotalJobs: Int = nextJobId.get()
private val nextStageId = new AtomicInteger(0) private[scheduler] val jobIdToStageIds = new HashMap[Int, HashSet[Int]]
private[scheduler] val stageIdToStage = new HashMap[Int, Stage]
/**
* Mapping from shuffle dependency ID to the ShuffleMapStage that will generate the data for
* that dependency. Only includes stages that are part of currently running job (when the job(s)
* that require the shuffle stage complete, the mapping will be removed, and the only record of
* the shuffle data will be in the MapOutputTracker).
*/
private[scheduler] val shuffleIdToMapStage = new HashMap[Int, ShuffleMapStage]
private[scheduler] val jobIdToActiveJob = new HashMap[Int, ActiveJob] // Stages we need to run whose parents aren't done
private[scheduler] val waitingStages = new HashSet[Stage] // Stages we are running right now
private[scheduler] val runningStages = new HashSet[Stage] // Stages that must be resubmitted due to fetch failures
private[scheduler] val failedStages = new HashSet[Stage] private[scheduler] val activeJobs = new HashSet[ActiveJob] /**
* Contains the locations that each RDD's partitions are cached on. This map's keys are RDD ids
* and its values are arrays indexed by partition numbers. Each array value is the set of
* locations where that RDD partition is cached.
*
* All accesses to this map should be guarded by synchronizing on it (see SPARK-4454).
*/
private val cacheLocs = new HashMap[Int, IndexedSeq[Seq[TaskLocation]]] // For tracking failed nodes, we use the MapOutputTracker's epoch number, which is sent with
// every task. When we detect a node failing, we note the current epoch number and failed
// executor, increment it for new tasks, and use this to ignore stray ShuffleMapTask results.
//
// TODO: Garbage collect information about failure epochs when we know there are no more
// stray messages to detect.
private val failedEpoch = new HashMap[String, Long] private [scheduler] val outputCommitCoordinator = env.outputCommitCoordinator // A closure serializer that we reuse.
// This is only safe because DAGScheduler runs in a single thread.
private val closureSerializer = SparkEnv.get.closureSerializer.newInstance() /** If enabled, FetchFailed will not cause stage retry, in order to surface the problem. */
private val disallowStageRetryForTest = sc.getConf.getBoolean("spark.test.noStageRetry", false) /**
* Whether to unregister all the outputs on the host in condition that we receive a FetchFailure,
* this is set default to false, which means, we only unregister the outputs related to the exact
* executor(instead of the host) on a FetchFailure.
*/
private[scheduler] val unRegisterOutputOnHostOnFetchFailure =
sc.getConf.get(config.UNREGISTER_OUTPUT_ON_HOST_ON_FETCH_FAILURE) /**
* Number of consecutive stage attempts allowed before a stage is aborted.
*/
private[scheduler] val maxConsecutiveStageAttempts =
sc.getConf.getInt("spark.stage.maxConsecutiveAttempts",
DAGScheduler.DEFAULT_MAX_CONSECUTIVE_STAGE_ATTEMPTS) /**
* Number of max concurrent tasks check failures for each barrier job.
*/
private[scheduler] val barrierJobIdToNumTasksCheckFailures = new ConcurrentHashMap[Int, Int] /**
* Time in seconds to wait between a max concurrent tasks check failure and the next check.
*/
private val timeIntervalNumTasksCheck = sc.getConf
.get(config.BARRIER_MAX_CONCURRENT_TASKS_CHECK_INTERVAL) /**
* Max number of max concurrent tasks check failures allowed for a job before fail the job
* submission.
*/
private val maxFailureNumTasksCheck = sc.getConf
.get(config.BARRIER_MAX_CONCURRENT_TASKS_CHECK_MAX_FAILURES) private val messageScheduler =
ThreadUtils.newDaemonSingleThreadScheduledExecutor("dag-scheduler-message") private[spark] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
√)metricsSource: DAGSchedulerSource:metrics system的Source角色,内注册了failedStages、runningStages、waitingStages、allJobs、activeJobs这些度量监控。https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/scheduler/DAGSchedulerSource.scala
√)nextJobId:AtomicInteger:生成jobId
√)numTotalJobs: Int:总的job数
√)nextStageId:AtomicInteger:下一个StageId
√)jobIdToStageIds:HashMap[Int, HashSet[Int]]:记录某个job与其包含的所有stageId的映射
√)stageIdToStage:HashMap[Int, Stage]:记录stageId与Stage的映射
√)shuffleIdToMapStage:HashMap[Int, ShuffleMapStage]:记录每一个shuffle对应的ShuffleMapStage,key为shuffleId。
√)jobIdToActiveJob:HashMap[Int, ActiveJob]:记录处于Active状态的Job,key为jobId,value为ActiveJob类型的对象。
√)waitingStages:HashSet[Stage]:等待运行的stage,一般这些是在登台Parent Stage运行完成才能开始。
√)runningStages:HashSet[Stage]:处于Running状态的stage
√)failedStages:HashSet[Stage]:处于Failed状态的stage,失败原因因为fetch failures的stage,并等待重新提交。
√)activeJobs:HashSet[ActiveJob]:处于Active状态的job列表
√)cacheLocs:HashMap[Int, IndexedSeq[Seq[TaskLocation]]]:维护着RDD的partitions 的 location信息。Map的key是rdd的id,value是rdd对应的partition编号索引的数组。每个数组值都是缓存该rdd partition的location set集合
√)failedEpoch:HashMap[String, Long]:对于跟踪失败的节点,我们使用MapOutputTracker的epoch编号,它与每个任务一起发送。当我们检测到一个节点失败时,我们记录到当前的epoch编号和失败的执行器,为新任务增加它,并使用它忽略杂散的ShuffleMapTask结果。
√)outputCommitCoordinator:env.outputCommitCoordinator:输出提交协调器
√)closureSerializer:JavaSerializer:重用的闭包序列化程序。它是安全的,因为DagScheduler在单个线程中运行。
√)disallowStageRetryForTest:Boolean:变量“spark.test.noStageRetry”,如果启用,FetchFailed将不会导致阶段重试,以显示问题。
√)unRegisterOutputOnHostOnFetchFailure:Boolean:是否在接收到FetchFailure的情况下注销主机上的所有输出,这将设置为默认值false,这意味着在FetchFailure时,我们只注销与确切的执行器(而不是主机)相关的输出。
√)maxConsecutiveStageAttempts:Int:变量“spark.stage.maxConsecutiveAttempts”,中止stage之前允许的连续stage尝试次数。
√)barrierJobIdToNumTasksCheckFailures:ConcurrentHashMap[Int, Int]:每个屏障作业的最大并发任务检查失败数。
√)timeIntervalNumTasksCheck:Int:在最大并发任务检查失败和下一次检查之间等待的时间(秒)。
√)maxFailureNumTasksCheck:Int:作业提交失败前允许的最大并发任务检查失败数。
√)messageScheduler:ScheduledExecutorService:dag-scheduler-message线程池调度器(调度的线程内部通过eventProcessLoop来实现: ResubmitFailedStages/JobSubmitted )
√)eventProcessLoop:DAGSchedulerEventProcessLoop:DAGSchedulerEventProcessLoop类定义在DAGScheduler类文件下,集成了EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") 。
- EventLoop实际上内置了一个用来存储消息的队列,对外提供了post方法用来接收消息存放到队列中,一个消费队列中消息的线程,消费线程以死循环方式获取队列中消息,当获取到消息后调用 onReceive(msg)进行消息处理。
- DAGSchedulerEventProcessLoop的构造函数接收dagScheduler: DAGScheduler,在onReceive方法中会根据消息类型调用dagScheduler的不同方法进行消息处理。
- DAGScheduler与EventLoop之间配合工作图:
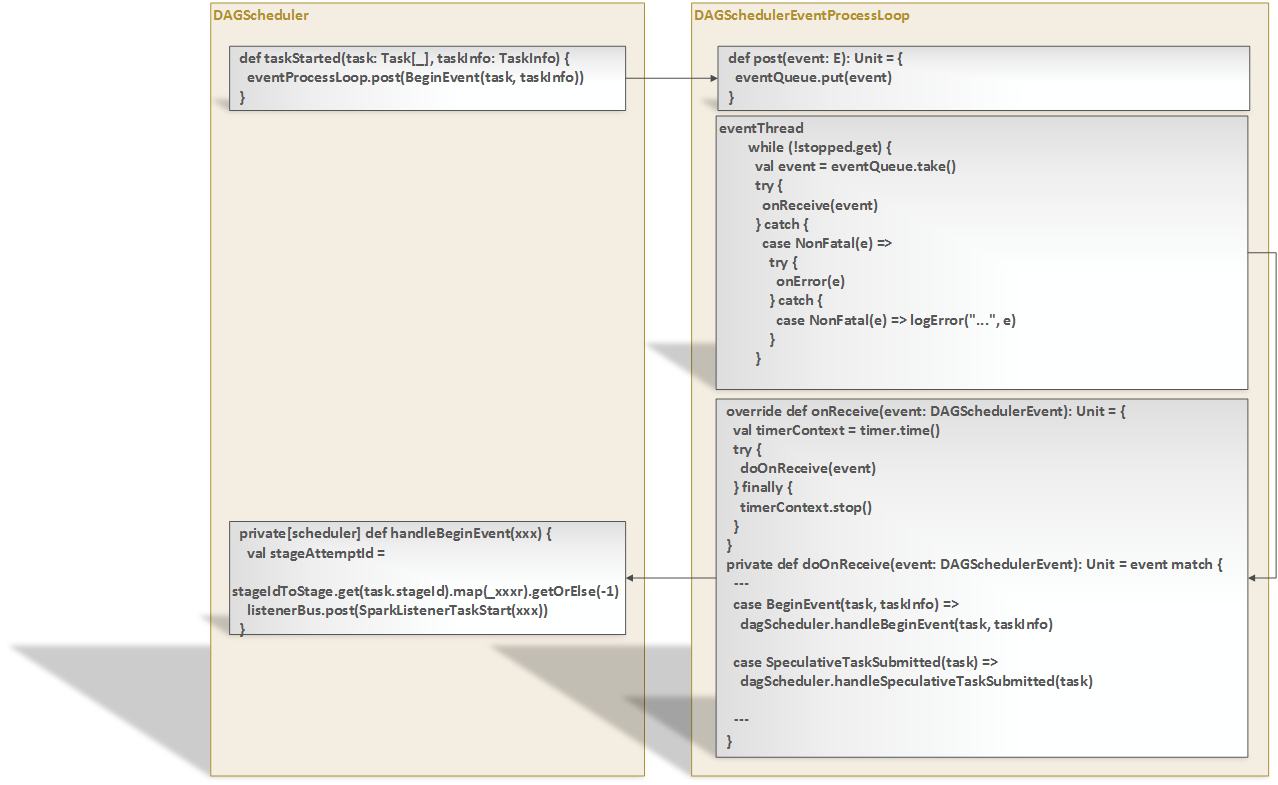
在DAGScheduler类的属性中定义eventProcessLoop:DAGSchedulerEventProcessLoop成员变量,DAGScheduler类初始化过程中会初始化变量eventProcessLoop = new DAGSchedulerEventProcessLoop(this),初始化最后一步是调用eventProcessLoop.start()来启动该事件循环处理。
接下来我们来分析eventProcessLoop的相关定义以及它的工作方式:
EventLoop定义:
EventLoop是个消息异步处理策略抽象类:
/**
* An event loop to receive events from the caller and process all events in the event thread. It
* will start an exclusive event thread to process all events.
*
* Note: The event queue will grow indefinitely. So subclasses should make sure `onReceive` can
* handle events in time to avoid the potential OOM.
*/
private[spark] abstract class EventLoop[E](name: String) extends Logging { private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() private val stopped = new AtomicBoolean(false) // Exposed for testing.
private[spark] val eventThread = new Thread(name) {
setDaemon(true) override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
} } def start(): Unit = {
if (stopped.get) {
throw new IllegalStateException(name + " has already been stopped")
}
// Call onStart before starting the event thread to make sure it happens before onReceive
onStart()
eventThread.start()
} def stop(): Unit = {
if (stopped.compareAndSet(false, true)) {
eventThread.interrupt()
var onStopCalled = false
try {
eventThread.join()
// Call onStop after the event thread exits to make sure onReceive happens before onStop
onStopCalled = true
onStop()
} catch {
case ie: InterruptedException =>
Thread.currentThread().interrupt()
if (!onStopCalled) {
// ie is thrown from `eventThread.join()`. Otherwise, we should not call `onStop` since
// it's already called.
onStop()
}
}
} else {
// Keep quiet to allow calling `stop` multiple times.
}
} /**
* Put the event into the event queue. The event thread will process it later.
*/
def post(event: E): Unit = {
eventQueue.put(event)
} /**
* Return if the event thread has already been started but not yet stopped.
*/
def isActive: Boolean = eventThread.isAlive /**
* Invoked when `start()` is called but before the event thread starts.
*/
protected def onStart(): Unit = {} /**
* Invoked when `stop()` is called and the event thread exits.
*/
protected def onStop(): Unit = {} /**
* Invoked in the event thread when polling events from the event queue.
*
* Note: Should avoid calling blocking actions in `onReceive`, or the event thread will be blocked
* and cannot process events in time. If you want to call some blocking actions, run them in
* another thread.
*/
protected def onReceive(event: E): Unit /**
* Invoked if `onReceive` throws any non fatal error. Any non fatal error thrown from `onError`
* will be ignored.
*/
protected def onError(e: Throwable): Unit }
1)内置了一个消息队列eventQueue: BlockingQueue[E],配合实现消息存储、消息消费使用;
2)对外开放了接收消息的post方法:接收到外部消息并存入队列,等待被消费;
3)内置了一个消费线程eventThread,消费线程以阻塞死循环方式消费队列中的消息,消费处理接口函数是onReceive(event: E),消费异常函数接口onError(e: Throwable);
4)还提供了消费线程启动方法start,在调用线程启动方法:eventThread.start()之前,需要调用onStart()为启动做准备接口函数;
5)还提供了消费线程停止方法stop,在调用线程停止方法:eventThread.interrupt&eventThread.join()之后,需要调用onStop()做补充接口函数。
DAGSchedulerEventProcessLoop定义:
顾名思义,DAGSchedulerEvent事件循环处理。
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging { private[this] val timer = dagScheduler.metricsSource.messageProcessingTimer /**
* The main event loop of the DAG scheduler.
*/
override def onReceive(event: DAGSchedulerEvent): Unit = {
val timerContext = timer.time()
try {
doOnReceive(event)
} finally {
timerContext.stop()
}
} private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties) case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason) case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason) case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId) case AllJobsCancelled =>
dagScheduler.doCancelAllJobs() case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host) case ExecutorLost(execId, reason) =>
val workerLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, workerLost) case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message) case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo) case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task) case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo) case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion) case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception) case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
} override def onError(e: Throwable): Unit = {
logError("DAGSchedulerEventProcessLoop failed; shutting down SparkContext", e)
try {
dagScheduler.doCancelAllJobs()
} catch {
case t: Throwable => logError("DAGScheduler failed to cancel all jobs.", t)
}
dagScheduler.sc.stopInNewThread()
} override def onStop(): Unit = {
// Cancel any active jobs in postStop hook
dagScheduler.cleanUpAfterSchedulerStop()
}
}
1)DAGSchedulerEventProcessLoop继承了EventLoop抽象类(其实EventLoop也是泛型类,这里泛型类型为DAGSchedulerEvent),并在构造函数中传递了DAGScheduler类对象;
2)对外提供了DAGSchedulerEvent接收DAGSchedulerEvent事件,并将接收到DAGSchedulerEvent事件存储到队列中;
3)在内部阻塞死循环方式去从队列中获取DAGSchedulerEvent事件,获取到后并处理它[调用onReceive(event: DAGSchedulerEvent)方法];
4)onReceive方式内部调用了私有方法doOnReceive(event),在doOnReceive方法中会根据event类型不同去调用dagScheduler的不同handleXxx方法(真正事件处理最后还归结于DAGScheduler中);
5)DAGSchedulerEvent是一个接口类,它的实现类包含:https://github.com/apache/spark/blob/branch-2.4/core/src/main/scala/org/apache/spark/scheduler/DAGSchedulerEvent.scala
JobSubmitted:已提交作业(RDD)
MapStageSubmitted:已提交MapStage
StageCancelled:已取消Stage
JobCancelled:已取消Job
JobGroupCancelled:已取消JobGroup
AllJobsCancelled:已取消所有Job
BeginEvent:开始Event
GettingResultEvent:获取结果Event
CompletionEvent:完成Event
ExecutorAdded:已添加Executor
ExecutorLost:Executor丢失
WorkerRemoved:已被移除Worker
TaskSetFailed:已除失败TaskSet
ResubmitFailedStages:重新提交已失败的Stages
SpeculativeTaskSubmitted:已提交推测性Task
DAGScheduler的生命周期
那么下边将会结合代码对DAGScheduler整个生命周期进行介绍,DAGScheduler的生命周期:
1)初始化DAGScheduler
2)根据RDD DAG划分Stages
3)对Stage进行调度、Stage容错
1)DAGScheduler之初始化
当一个spark application代码被提交yanr上时,比如yarn-cluster方式提交,通过SparkSubmit->YarnClusterApplication类中运行的是Client中run方法,Client#run()->ApplicationMaster#userClassThread用来执行application main的线程,当执行applicatin main函数时,会先初始化SparkContext对象,在初始化SparkContext过程会初始化DAGScheduler:
@volatile private var _dagScheduler: DAGScheduler = _
。。。
private[spark] def dagScheduler: DAGScheduler = _dagScheduler
private[spark] def dagScheduler_=(ds: DAGScheduler): Unit = {
_dagScheduler = ds
}
。。。
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet) // start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
在DAGScheduler初始化过程中会初始化DAGScheduler变量eventProcessLoop = new DAGSchedulerEventProcessLoop(this),初始化最后一步是调用eventProcessLoop.start()来启动该事件循环处理。
2)DAGScheduler之根据RDD DAG划分Stages
application jar的代码[RDD(Spark Core),注意Dataset、DataFrame、sparkSession.sql("select ...")经过catalyst代码解析会将代码转化为RDD,
SparkSQL底层依然是RDD]最终是RDD计算,RDD计算分为两类:transform、action。
Each RDD has 2 sets of parallel operations: transformation and action.(1)Transformation:Return a MappedRDD[U] by applying function f to each element
map(func)
filter(func)
flatMap(func)
mapPartitions(func)
mapPartitionsWithIndex(func)
sample(withReplacement, fraction, seed)
union(otherDataset)
intersection(otherDataset)
distinct([numTasks]))
groupByKey([numTasks])
reduceByKey(func, [numTasks])
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
sortByKey([ascending], [numTasks])
join(otherDataset, [numTasks])
cogroup(otherDataset, [numTasks])
cartesian(otherDataset)
pipe(command, [envVars])
coalesce(numPartitions)
repartition(numPartitions)
repartitionAndSortWithinPartitions(partitioner)
(2)Action:Return T by reducing the elements using specified commutative and associative binary operator
reduce(func)
collect()
count()
first()
take(n)
takeOrdered(n, [ordering])
saveAsTextFile(path)
saveAsSequenceFile(path)
saveAsObjectFile(path)
countByKey()
foreach(func)
在applicaiton jar代码开始执行时,当遇到action操作时,就会调用sc.runJob(...)。下边以WordCount为例来展开RDD DAG图划分Stage流程:
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val wordFile = "E:\\personOrder.csv"
val conf = new SparkConf().setMaster("local[1,1]").setAppName("wordcount");
val sc = new SparkContext(conf)
val input = sc.textFile(wordFile, 2).cache()
val lines = input.flatMap(line => line.split("[,|-]"))
val count = lines.map(word => (word, 1)).reduceByKey { case (x, y) => x + y }
count.foreach(println)
}
}
当application jar的main被调用,代码执行到count.foreach(println)时,RDD#foreach底层实现如下:
/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
}
SparkContext#runJob用来提交job的方法
在RDD中的一组给定partitions上运行函数,并将结果传递给给定的处理程序函数。这是Spark中所有操作的主要入口点。
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like `first()`
* @param resultHandler callback to pass each result to
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
参数解析:
1)rdd:要在其上运行任务的目标RDD
2)func:在RDD的每个分区上运行的函数
3)partitions:要运行的分区集;某些作业可能不希望在目标RDD的所有分区上进行计算,例如对于“first()”之类的操作。`。生成方式:{0 until rdd.partitions.length}
RDD#first方法实现:
/**
* Return the first element in this RDD.
*/
def first(): T = withScope {
take(1) match {
case Array(t) => t
case _ => throw new UnsupportedOperationException("empty collection")
}
}
从上边代码我们看出RDD#first内部是调用RDD#take(num)方法,那么我们来查看RDD#take方法:
/**
* Take the first num elements of the RDD. It works by first scanning one partition, and use the
* results from that partition to estimate the number of additional partitions needed to satisfy
* the limit.
*
* @note This method should only be used if the resulting array is expected to be small, as
* all the data is loaded into the driver's memory.
*
* @note Due to complications in the internal implementation, this method will raise
* an exception if called on an RDD of `Nothing` or `Null`.
*/
def take(num: Int): Array[T] = withScope {
val scaleUpFactor = Math.max(conf.getInt("spark.rdd.limit.scaleUpFactor", 4), 2)
if (num == 0) {
new Array[T](0)
} else {
val buf = new ArrayBuffer[T]
val totalParts = this.partitions.length
var partsScanned = 0
while (buf.size < num && partsScanned < totalParts) {
// The number of partitions to try in this iteration. It is ok for this number to be
// greater than totalParts because we actually cap it at totalParts in runJob.
var numPartsToTry = 1L
val left = num - buf.size
if (partsScanned > 0) {
// If we didn't find any rows after the previous iteration, quadruple and retry.
// Otherwise, interpolate the number of partitions we need to try, but overestimate
// it by 50%. We also cap the estimation in the end.
if (buf.isEmpty) {
numPartsToTry = partsScanned * scaleUpFactor
} else {
// As left > 0, numPartsToTry is always >= 1
numPartsToTry = Math.ceil(1.5 * left * partsScanned / buf.size).toInt
numPartsToTry = Math.min(numPartsToTry, partsScanned * scaleUpFactor)
}
} val p = partsScanned.until(math.min(partsScanned + numPartsToTry, totalParts).toInt)
val res = sc.runJob(this, (it: Iterator[T]) => it.take(left).toArray, p) res.foreach(buf ++= _.take(num - buf.size))
partsScanned += p.size
} buf.toArray
}
}
取RDD的num个元素。它内部实现:首先扫描一个分区,然后使用该分区的结果来估计是否满足num个元素结果,不满足则尝试从下一个分区中获取,依次循环处理知道取够num个元素。
@注意:只有当结果数组很小时才应使用此方法,因为所有数据都加载到驱动程序的内存中。
@注意:由于内部实现的复杂性,如果对“Nothing”或“null”的RDD调用此方法,则会引发异常。
4)resultHandler:回调函数,以将每个分区结果传递给Xxx,
比如:
/**
* Run a function on a given set of partitions in an RDD and return the results as an array.
* The function that is run against each partition additionally takes `TaskContext` argument.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like `first()`
* @return in-memory collection with a result of the job (each collection element will contain
* a result from one partition)
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U] = {
val results = new Array[U](partitions.size)
runJob[T, U](rdd, func, partitions, (index, res) => results(index) = res)
results
}
上边代码中:resultHadnler是:(index, res) => results(index) = res;将每个partittion中计算结果,赋值给results[partition index],最终并返回results结果集。
DAGScheduler#runJob方法:
在SparkContext#runJob方法内部会调用dagScheduler.runJob(xxx)方法,也就是将stage划分和任务提交分配了dagScheduler来处理,来看下DAGScheduler#runJob代码:
/**
* Run an action job on the given RDD and pass all the results to the resultHandler function as
* they arrive.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like first()
* @param callSite where in the user program this job was called
* @param resultHandler callback to pass each result to
* @param properties scheduler properties to attach to this job, e.g. fair scheduler pool name
*
* @note Throws `Exception` when the job fails
*/
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
runJob方法的解释:对给定的RDD运行操作作业,并在结果到达时将所有结果传递给resultHandler函数。
参数解析:
1)rdd:要在其上运行任务的参数RDD目标RDD
2)func:在RDD的每个分区上运行的函数
3)partitions:要运行的分区的集;某些作业可能不希望在目标RDD的所有分区上进行计算,例如,对于first()之类的操作。
4)callSite:在用户程序中调用此作业的位置
5)resultHandler:回调函数,以将每个分区结果传递给Xxx
6)properties:要附加到此作业的scheduler属性,例如fair scheduler pool name
注意:在作业失败时引发“Exception”
DAGScheduler#runJob内部实现分析:
1)调用DAGScheduler#submitJob(...)方法提交作业,并接收返回值waiter。
2)使用ThreadUtils.awaitRedy(...)来等待waiter处理完成,实际上这里是阻塞等待Job结束;
3)根据waiter完成后返回值作相应响应:Success,打印:‘Job x finished:xxx’;Failure,打印:‘Job x failed:xxx’,并抛出异常。
DAGScheduler#submitJob(...)方法
/**
* Submit an action job to the scheduler.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like first()
* @param callSite where in the user program this job was called
* @param resultHandler callback to pass each result to
* @param properties scheduler properties to attach to this job, e.g. fair scheduler pool name
*
* @return a JobWaiter object that can be used to block until the job finishes executing
* or can be used to cancel the job.
*
* @throws IllegalArgumentException when partitions ids are illegal
*/
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
} val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
} assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
DAGScheduler#submitJob(...)方法内部实现:
第一步:封装一个JobWaiter对象;
第二步:将JobWaiter对象赋值给JobSubmitted的listener属性,并将JobSubmitted(DAGSchedulerEvent事件)对象传递给eventProcessLoop事件循环处理器。eventProcessLoop内部事件消息处理线程将会接收JobSubmitted事件,并调用dagScheduler.handleJobSubmitted(...)方法来处理事件;
第三步:返回JobWaiter对象。
DAGScheduler#handleJobSubmitted(...)方法:
需要说明:该方法是被eventProcessLoop:DAGSchedulerEventProcessLoop下的事件处理线程(获取到JobSubmitted事件后)调用的,因此该方法与主线程不是同一个线程下执行的。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: BarrierJobSlotsNumberCheckFailed =>
logWarning(s"The job $jobId requires to run a barrier stage that requires more slots " +
"than the total number of slots in the cluster currently.")
// If jobId doesn't exist in the map, Scala coverts its value null to 0: Int automatically.
val numCheckFailures = barrierJobIdToNumTasksCheckFailures.compute(jobId,
new BiFunction[Int, Int, Int] {
override def apply(key: Int, value: Int): Int = value + 1
})
if (numCheckFailures <= maxFailureNumTasksCheck) {
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(JobSubmitted(jobId, finalRDD, func,
partitions, callSite, listener, properties))
},
timeIntervalNumTasksCheck,
TimeUnit.SECONDS
)
return
} else {
// Job failed, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
listener.jobFailed(e)
return
} case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
// Job submitted, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId) val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage)) val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
当Job提交后,JobSubmitted事件会被eventProcessLoop捕获到,然后进入本方法中。开始处理Job,并执行Stage的划分。
Stage的划分:
Stage的划分过程中,会涉及到宽依赖和窄依赖的概念,宽依赖是Stage的分界线,连续的窄依赖都属于同一Stage。
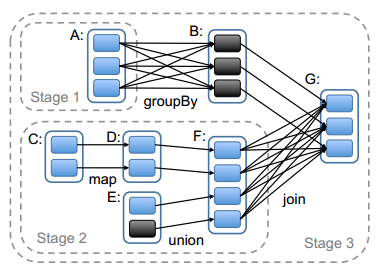
比如上图中,在RDD G处调用了Action操作,在划分Stage时,会从G开始逆向分析,G依赖于B和F,其中对B是窄依赖,对F是宽依赖,所以F和G不能算在同一个Stage中,即在F和G之间会有一个Stage分界线。上图中还有一处宽依赖在A和B之间,所以这里还会分出一个Stage。最终形成了3个Stage,由于Stage1和Stage2是相互独立的,所以可以并发执行,等Stage1和Stage2准备就绪后,Stage3才能开始执行。
Stage有两个类型,最后的Stage为ResultStage类型,除此之外的Stage都是ShuffleMapStage类型。
Stage类定义:
private[scheduler] abstract class Stage(
val id: Int,
val rdd: RDD[_],
val numTasks: Int,
val parents: List[Stage],
val firstJobId: Int,
val callSite: CallSite)
extends Logging { val numPartitions = rdd.partitions.length /** Set of jobs that this stage belongs to. */
val jobIds = new HashSet[Int] /** The ID to use for the next new attempt for this stage. */
private var nextAttemptId: Int = 0 val name: String = callSite.shortForm
val details: String = callSite.longForm /**
* Pointer to the [[StageInfo]] object for the most recent attempt. This needs to be initialized
* here, before any attempts have actually been created, because the DAGScheduler uses this
* StageInfo to tell SparkListeners when a job starts (which happens before any stage attempts
* have been created).
*/
private var _latestInfo: StageInfo = StageInfo.fromStage(this, nextAttemptId) /**
* Set of stage attempt IDs that have failed. We keep track of these failures in order to avoid
* endless retries if a stage keeps failing.
* We keep track of each attempt ID that has failed to avoid recording duplicate failures if
* multiple tasks from the same stage attempt fail (SPARK-5945).
*/
val failedAttemptIds = new HashSet[Int] private[scheduler] def clearFailures() : Unit = {
failedAttemptIds.clear()
} /** Creates a new attempt for this stage by creating a new StageInfo with a new attempt ID. */
def makeNewStageAttempt(
numPartitionsToCompute: Int,
taskLocalityPreferences: Seq[Seq[TaskLocation]] = Seq.empty): Unit = {
val metrics = new TaskMetrics
metrics.register(rdd.sparkContext)
_latestInfo = StageInfo.fromStage(
this, nextAttemptId, Some(numPartitionsToCompute), metrics, taskLocalityPreferences)
nextAttemptId += 1
} /** Returns the StageInfo for the most recent attempt for this stage. */
def latestInfo: StageInfo = _latestInfo override final def hashCode(): Int = id override final def equals(other: Any): Boolean = other match {
case stage: Stage => stage != null && stage.id == id
case _ => false
} /** Returns the sequence of partition ids that are missing (i.e. needs to be computed). */
def findMissingPartitions(): Seq[Int]
}
Stage的RDD参数只有一个RDD, final RDD, 而不是一系列的RDD。
因为在一个stage中的所有RDD都是map, partition不会有任何改变, 只是在data依次执行不同的map function所以对于TaskScheduler而言, 一个RDD的状况就可以代表这个stage。
Stage是一组并行任务,所有这些任务都在计算需要作为一部分运行的相同函数
在Spark Job中,所有任务都具有相同的shuffle依赖项。每个任务的DAG运行由调度程序在发生shuffle的边界处分为多个stages,然后DagScheduler以拓扑顺序运行这些阶段。
每个stage都可以是shuffle map stage,在这种情况下,任务的结果将输入到其他阶段或结果阶段,在这种情况下,其任务直接计算Spark action(例如count()、save()等)在RDD上运行函数。对于shuffle map stages,我们还跟踪每个输出分区所在的节点。
每个stage也有一个FirstJobID,用于标识第一个提交阶段的作业。当使用FIFO调度时,这允许首先计算早期作业的阶段,或者在失败时更快地恢复。
最后,由于故障恢复,一个stage可以在多次尝试中重新执行。在这种情况下,stage对象将跟踪要传递给侦听器(listeners)或Web UI的多个StageInfo对象。
最新版本将通过LatestInfo访问。
@id 唯一阶段ID
@rdd 这个阶段运行的RDD:对于shuffle map stage,是我们运行映射任务的RDD,而对于结果阶段,是我们运行操作的目标RDD
@tasks 阶段中任务的总数;结果阶段可能不需要计算所有分区,例如first()、lookup()和take()。
@parents 此阶段依赖的阶段列表(通过shuffle dependencies)。
@firstJobId 此阶段所属的第一个作业的ID,用于FIFO调度。
@callSite 与此阶段关联的用户程序中的调用站点位置:创建目标RDD的位置、shuffle map stage的位置或调用结果阶段的action的位置。
1)DAGScheduler#handleJobSubmitted(...)方法之createResultStage
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: BarrierJobSlotsNumberCheckFailed =>
logWarning(s"The job $jobId requires to run a barrier stage that requires more slots " +
"than the total number of slots in the cluster currently.")
// If jobId doesn't exist in the map, Scala coverts its value null to 0: Int automatically.
val numCheckFailures = barrierJobIdToNumTasksCheckFailures.compute(jobId,
new BiFunction[Int, Int, Int] {
override def apply(key: Int, value: Int): Int = value + 1
})
if (numCheckFailures <= maxFailureNumTasksCheck) {
messageScheduler.schedule(
new Runnable {
override def run(): Unit = eventProcessLoop.post(JobSubmitted(jobId, finalRDD, func,
partitions, callSite, listener, properties))
},
timeIntervalNumTasksCheck,
TimeUnit.SECONDS
)
return
} else {
// Job failed, clear internal data.
barrierJobIdToNumTasksCheckFailures.remove(jobId)
listener.jobFailed(e)
return
} case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
上边这段代码是 DAGScheduler#handleJobSubmitted 中划分Stage的主要实现代码。前面提到了Stage的划分是从最后一个Stage开始逆推的,每遇到一个宽依赖处,就分裂成另外一个Stage,依此类推直到Stage划分完毕为止。并且,只有最后一个Stage的类型是ResultStage类型。
因此,finalStage的类型是:ResultStage。
2)DAGScheduler#createResultStage(...)
/**
* Create a ResultStage associated with the provided jobId.
*/
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size)
// 获取当前Stage的parent Stage,这个方法是划分Stage的核心实现
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
// 创建当前最后的ResultStage
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
// 将ResultStage与stageId相关联
stageIdToStage(id) = stage
// 更新该job中包含的stage
updateJobIdStageIdMaps(jobId, stage)
// 返回ResultStage
stage
}
上边3个check解释:
1)checkBarrierStageWithDynamicAllocation(rdd):不支持在启用动态资源分配的情况下运行屏障阶段,这将导致一些混乱的行为(例如,在启用动态资源分配的情况下,我们可能会获得一些执行者(但不足以在屏障阶段启动所有任务),并在以后释放它们执行器空闲时间到期,然后重新获取)。如果在启用动态资源分配的情况下运行屏障阶段,将在作业提交时执行检查并快速失败。
2)checkBarrierStageWithNumSlots(rdd):检查屏障阶段是否需要比当前活动插槽总数更多的插槽(以便能够一起启动屏障阶段中的所有任务)。如果尝试提交一个比当前总数需要更多插槽的屏障阶段,则提前检查失败。如果检查连续失败,超过作业的配置数量,则当前作业提交失败。
3)checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size):检查以确保我们不使用不支持的RDD链模式启动屏障阶段。不支持以下模式:
1.与生成的RDD具有不同分区数的祖先RDD(例如union()/coalesce()/first()/take()/PartitionPruningRDD);
2.第二步。依赖多个屏障RDD的RDD(如barrierRdd1.zip(barrierRdd2))。
3)DAGScheduler#getOrCreateParentStages(...)
获取或创建给定RDD的parentStage列表。将使用提供的firstJobId创建新阶段。
/**
* Get or create the list of parent stages for a given RDD. The new Stages will be created with
* the provided firstJobId.
*/
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
这个方法主要是为当前的RDD向前探索,找到宽依赖处划分出parentStage。
4)DAGScheduler#getShuffleDependencies(...)
采用的是深度优先遍历找到Action算子的父依赖中的宽依赖
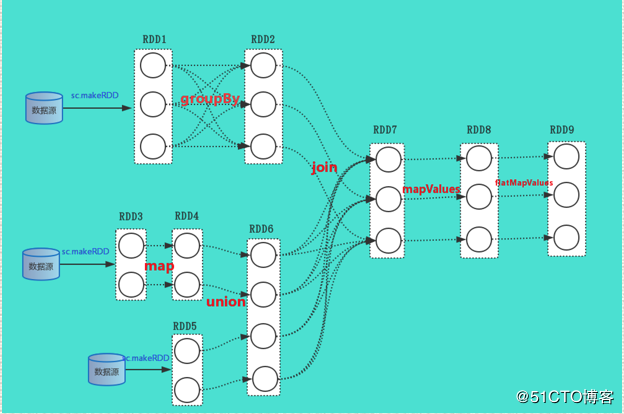
这个是最主要的方法,要看懂这个方法,其实后面的就好理解,最好结合这例子上面给出的RDD逻辑依赖图,比较容易看出来,根据上面的RDD逻辑依赖图,其返回的ShuffleDependency就是RDD2和RDD1,RDD7和RDD6的依赖。
如果存在A<-B<-C,这两个都是shuffle依赖,那么对于C其只返回B的shuffle依赖,而不会返回A
/**
* Returns shuffle dependencies that are immediate parents of the given RDD.
*
* This function will not return more distant ancestors.
* For example, if C has a shuffle dependency on B which has a shuffle dependency on A:
* A <-- B <-- C calling this function with rdd C will only return the B <-- C dependency.
*
* This function is scheduler-visible for the purpose of unit testing.
*/
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
//用来存放依赖
val parents = new HashSet[ShuffleDependency[_, _, _]]
//遍历过的RDD放入这个里面
val visited = new HashSet[RDD[_]] //创建一个待遍历RDD的栈结构
val waitingForVisit = new ArrayStack[RDD[_]]
//压入finalRDD,逻辑图中的RDD9
waitingForVisit.push(rdd) //循环遍历这个栈结构
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop() // 如果RDD没有被遍历过,则执行if内部的代码
if (!visited(toVisit)) {
//然后把其放入已经遍历队列中
visited += toVisit
//得到依赖,我们知道依赖中存放的有父RDD的对象
toVisit.dependencies.foreach {
//如果这个依赖是shuffle依赖,则放入返回队列中
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
//如果不是shuffle依赖,把其父RDD压入待访问栈中,从而进行循环
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
5)DAGScheduler#getOrCreateShuffleMapStage(...)
如果shuffleIdToMapStage中存在shuffle,则获取shuffle map stage。否则,如果shuffle map stage不存在,该方法将创建shuffle map stage以及任何丢失的parent shuffle map stage。
/**
* Gets a shuffle map stage if one exists in shuffleIdToMapStage. Otherwise, if the
* shuffle map stage doesn't already exist, this method will create the shuffle map stage in
* addition to any missing ancestor shuffle map stages.
*/
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage case None =>
// Create stages for all missing ancestor shuffle dependencies.
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// Even though getMissingAncestorShuffleDependencies only returns shuffle dependencies
// that were not already in shuffleIdToMapStage, it's possible that by the time we
// get to a particular dependency in the foreach loop, it's been added to
// shuffleIdToMapStage by the stage creation process for an earlier dependency. See
// SPARK-13902 for more information.
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// Finally, create a stage for the given shuffle dependency.
createShuffleMapStage(shuffleDep, firstJobId)
}
}
6)DAGScheduler#createShuffleMapStage(...)
创建一个ShuffleMapStage,它生成给定的shuffle依赖项的分区。如果先前运行的stage生成了相同的shuffle 数据,则此函数将复制先前shuffle 中仍然可用的输出位置,以避免不必要地重新生成数据。
/**
* Creates a ShuffleMapStage that generates the given shuffle dependency's partitions. If a
* previously run stage generated the same shuffle data, this function will copy the output
* locations that are still available from the previous shuffle to avoid unnecessarily
* regenerating data.
*/
def createShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
checkBarrierStageWithDynamicAllocation(rdd)
checkBarrierStageWithNumSlots(rdd)
checkBarrierStageWithRDDChainPattern(rdd, rdd.getNumPartitions)
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker) stageIdToStage(id) = stage
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage) if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
通过上面的源代码分析,结合RDD的逻辑执行图,我们可以看出,这个job拥有三个Stage,一个ResultStage,两个ShuffleMapStage,一个ShuffleMapStage中的RDD是RDD1,另一个stage中的RDD是RDD6,从而,以上完成了RDD到Stage的切分工作。当切分完成后在handleJobSubmitted这个方法的最后,调用提交stage的方法。
3)DAGScheduler之对Stage进行调度、容错
回顾下任务提交流程,一个application.jar执行流程中什么时候开始进行stage提交:
1)DAGScheduler初始化:当一个spark application代码被提交yanr上时,比如yarn-cluster方式提交,通过SparkSubmit->YarnClusterApplication类中运行的是Client中run方法,Client#run()->ApplicationMaster#userClassThread用来执行application main的线程,当执行applicatin main函数时,会先初始化SparkContext对象,在初始化SparkContext过程会初始化DAGScheduler:
2)当执行application jar的代码RDD(Spark Core)时,当遇到rdd的action操作时,就会调用:
--> SparkContext#runJob用来提交job的方法
--> DAGScheduler#runJob方法
--> DAGScheduler#submitJob(...)方法,提交给eventProcessLoop
--> eventProcessLoop内部事件处理器会调用DAGScheduler#handleJobSubmitted(...)方法;
3)在DAGScheduler#handleJobSubmitted(...)方法中,会调用“finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)”生成stage;submitStage(finalStage)用来提交stage。
下面,让我看下stage提交具体代码执行流程:
1)DAGScheduler#handleJobSubmitted(...)方法之submitStage(finalStage)
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
。。。。。。 val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage)) val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
2)DAGScheduler#submitStage方法
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获取该stage未提交的父stages,并按stage id从小到大排序
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// 若无未提交的父stage, 则提交该stage对应的tasks
submitMissingTasks(stage, jobId.get)
} else {
// 若存在未提交的父stage, 依次提交所有父stage (若父stage也存在未提交的父stage, 则提交之, 依次类推); 并把该stage添加到等待stage队列中
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
提交Stage,首先递归提交无父Stage的Stage。
1)若无未提交的父stage, 则提交该stage对应的tasks;
2)若存在未提交的父stage, 依次提交所有父stage (若父stage也存在未提交的父stage, 则提交之, 依次类推); 并把该stage添加到等待stage队列中
3)DAGScheduler#getMissingParentStages方法
getMissingParentStages与DAGScheduler划分stage中介绍的getOrCreateParentStages有点像,但不同的是不再需要划分stage,并对每个stage的状态做了判断,源码及注释如下:
// 以参数stage为起点,向前遍历所有stage,判断stage是否为未提交,若使则加入missing中
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage] // 未提交的stage
val visited = new HashSet[RDD[_]] // 存储已经被访问到得RDD
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new ArrayStack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd
val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)
if (rddHasUncachedPartitions) {
for (dep <- rdd.dependencies) {
dep match {
// 若为宽依赖,生成新的stage
case shufDep: ShuffleDependency[_, _, _] =>
// 这里调用getShuffleMapStage不像在getParentStages时需要划分stage,而是直接根据shufDep.shuffleId获取对应的ShuffleMapStage
val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId)
if (!mapStage.isAvailable) { // 若stage得状态为available则为未提交stage
missing += mapStage
}
// 若为窄依赖,那就属于同一个stage。并将依赖的RDD放入waitingForVisit中,以能够在下面的while中继续向上visit,直至遍历了整个DAG图
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
missing.toList
}
上边提到在调用submitStage中讲到,submitStage先调用getMissingParentStages来获取参数missing是否有未提交的父stages,若有,则依次递归(按stage id从小到大排列,也就是stage是从后往前提交的)提交父stages,并将missing加入到waitingStages: HashSet[Stage]中。对于要依次提交的父stage,也是如此。
若missing存在未提交的父stages,则先提交父stages;那么,如果missing没有未提交的父stage呢(比如,包含从HDFS读取数据生成HadoopRDD的那个stage是没有父stage的)?
这时会调用submitMissingTasks(stage, jobId.get),参数就是missing及其对应的jobId.get。这个函数便是将stage与taskSet对应起来,然后DAGScheduler将taskSet提交给TaskScheduler去执行的实施者。
4)DAGScheduler#submitMissingTasks方法
/** Called when stage's parents are available and we can now do its task. */
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")") // Step1: 得到RDD中需要计算的partition
//< 首先得到RDD中需要计算的partition
//< 对于Shuffle类型的stage,需要判断stage中是否缓存了该结果;
//< 对于Result类型的Final Stage,则判断计算Job中该partition是否已经计算完成
//< 这么做的原因是,stage中某个task执行失败其他执行成功地时候就需要找出这个失败的task对应要计算的partition而不是要计算所有partition
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions() // Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties runningStages += stage
// SparkListenerStageSubmitted should be posted before testing whether tasks are
// serializable. If tasks are not serializable, a SparkListenerStageCompleted event
// will be posted, which should always come after a corresponding SparkListenerStageSubmitted
// event.
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
} stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq) // If there are tasks to execute, record the submission time of the stage. Otherwise,
// post the even without the submission time, which indicates that this stage was
// skipped.
if (partitionsToCompute.nonEmpty) {
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
}
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties)) // Step2: 序列化task的binary
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
// the serialized copy of the RDD and for each task we will deserialize it, which means each
// task gets a different copy of the RDD. This provides stronger isolation between tasks that
// might modify state of objects referenced in their closures. This is necessary in Hadoop
// where the JobConf/Configuration object is not thread-safe.
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes and partitions are both effected by the checkpoint status. We need
// this synchronization in case another concurrent job is checkpointing this RDD, so we get a
// consistent view of both variables.
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
//< 对于ShuffleMapTask,将rdd及其依赖关系序列化;在Executor执行task之前会反序列化
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
//< 对于ResultTask,对rdd及要在每个partition上执行的func
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
} partitions = stage.rdd.partitions
} taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage // Abort execution
return
case e: Throwable =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage // Abort execution
return
}
// Step3: 为每个需要计算的partiton生成一个task
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
//< RDD对应的partition
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId, stage.rdd.isBarrier())
} case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId,
stage.rdd.isBarrier())
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
} // Step4: 提交tasks
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None) stage match {
case stage: ShuffleMapStage =>
logDebug(s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})")
markMapStageJobsAsFinished(stage)
case stage : ResultStage =>
logDebug(s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})")
}
submitWaitingChildStages(stage)
}
}
- Step1: 得到RDD中需要计算的partition
对于Shuffle类型的stage,需要判断stage中是否缓存了该结果;对于Result类型的Final Stage,则判断计算Job中该partition是否已经计算完成。这么做(没有直接提交全部tasks)的原因是,stage中某个task执行失败其他执行成功的时候就需要找出这个失败的task对应要计算的partition而不是要计算所有partition
- Step2: 序列化task的binary
Executor可以通过广播变量得到它。每个task运行的时候首先会反序列化
- Step3: 为每个需要计算的partiton生成一个task
ShuffleMapStage对应的task全是ShuffleMapTask; ResultStage对应的全是ResultTask。task继承Serializable,要确保task是可序列化的。
- Step4: 提交tasks
先用tasks来初始化一个TaskSet对象,再调用TaskScheduler.submitTasks提交
参考:
1)《Spark运行机制之DAG原理》
2)《Spark Scheduler模块详解-DAGScheduler实现》
4)《Spark Scheduler模块源码分析之DAGScheduler》
5)《Spark Scheduler模块源码分析之TaskScheduler和SchedulerBackend》
6)《spark DAGScheduler、TaskSchedule、Executor执行task源码分析》
7)《[Spark源码剖析] DAGScheduler提交stage》
Spark(五十二):Spark Scheduler模块之DAGScheduler流程的更多相关文章
- Gradle 1.12用户指南翻译——第五十二章. Maven 插件
本文由CSDN博客貌似掉线翻译,其他章节的翻译请参见:http://blog.csdn.net/column/details/gradle-translation.html翻译项目请关注Github上 ...
- Java进阶(五十二)利用LOG4J生成服务日志
Java进阶(五十二)利用LOG4J生成服务日志 前言 由于论文写作需求,需要进行流程挖掘.前提是需要有真实的事件日志数据.真实的事件日志数据可以用来发现.监控和提升业务流程. 为了获得真实的事件日志 ...
- SQL注入之Sqli-labs系列第五十关,第五十一关,第五十二关,第五十三关(ORDER BY堆叠注入)
0x1第五十关 源码中使用的mysqli_multi_query()函数,而之前使用的是mysqli_query(),区别在于mysqli_multi_query()可以执行多个sql语句,而mysq ...
- 【黑金原创教程】【FPGA那些事儿-驱动篇I 】实验十二:串口模块① — 发送
实验十二:串口模块① — 发送 串口固然是典型的实验,想必许多同学已经作烂,不过笔者还要循例介绍一下.我们知道串口有发送与接收之分,实验十二的实验目的就是实现串口发送,然而不同的是 ... 笔者会用另 ...
- “全栈2019”Java第五十二章:继承与初始化详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- 《手把手教你》系列技巧篇(五十二)-java+ selenium自动化测试-处理面包屑(详细教程)
1.简介 面包屑(Breadcrumb),又称面包屑导航(BreadcrumbNavigation)这个概念来自童话故事"汉赛尔和格莱特",当汉赛尔和格莱特穿过森林时,不小心迷路了 ...
- Bristol大学密码学博士生的五十二个知识点
Bristol大学密码学博士生的五十二个知识点 这个系列,是Bristol大学的密码安全工作组为密码学和信息安全相关的博士准备了52个基本知识点. 原地址:http://bristolcrypto.b ...
- Spark(十二)SparkSQL简单使用
一.SparkSQL的进化之路 1.0以前: Shark 1.1.x开始:SparkSQL(只是测试性的) SQL 1.3.x: SparkSQL(正式版本)+Datafram ...
- Spark(十二)--性能调优篇
一段程序只能完成功能是没有用的,只能能够稳定.高效率地运行才是生成环境所需要的. 本篇记录了Spark各个角度的调优技巧,以备不时之需. 一.配置参数的方式和观察性能的方式 额...从最基本的开始讲, ...
随机推荐
- 转 CentOS 初体验十四:阿里云安装Gitlab
原文 https://blog.csdn.net/zhaoyanjun6/article/details/79144175 非Unix操作系统(Windows) GitLab是专为Unix操作 ...
- javascript_16-对象字面量
JSON与对象字面量相似,仅仅是属性需要使用双引号引号引起. json是描述数据的一种规范 什么是JSON JavaScript Object Notation (JavaScript 对象表示形式) ...
- 用python实现数据库查询数据方法
哈喽,好久没来了,最近搞自动化发现了很多代码弯路,特别分享出来给能用到的朋友 因为公司业务的关系,每做一笔功能冒烟测试,我们就要对很多的数据库表中的字段进行校验,当时我就想反正总是要重复的运行这些SQ ...
- 学习python的日常
今天是开始正式接触python语言的第一天,然后来自前辈的知道开始了在学习过程当中用博客来记录自己的学习历程,以供自己更快地掌握这门编程语言. 大概的总结一下的话,还是按照我的编程的习惯,要学写代码, ...
- zabbix的psk加密结合zabbix_get取值
转载:https://www.xj123.info/7386.html 参考文档:https://www.zabbix.com/documentation/3.0/manpages/zabbix_ge ...
- rest-assured-doc接口自动化测试,数据驱动测试平台
原文:https://github.com/rest-assured/rest-assured/wiki/Usage 本文github地址:https://github.com/RookieTeste ...
- 10分钟学会 linux awk命令
简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再 ...
- 《3+1团队》【Beta】Scrum meeting 3
项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 3+1团队 团队博客地址 https://home.cnblogs.com/u/3-1group ...
- 样条插值法(Java)--在本地执行
该程序主要实现样条插值的目的,为本地执行java文件 该程序包含:样条插值法.读取文件,写入文件,字符型转double型方法等: 适合初学Java的人学习: 首次使用eclipse打jar包,中间很曲 ...
- IDEA 相关设置汇总
1.自动提示.代码补全 有时候希望使用自动补全,因为不偷懒的程序员不是好程序员.但是Idea的默认快捷键是 Ctrl + 空格. 对于安装中文输入法的普通人来说那就是杯具了,你懂的. 修改方法如下: ...