cpu指令重排序的原理
目录:
1.重排序场景
2.追根溯源
3.缓存一致性协议
4.重排序原因
一、重排序场景
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //
flag = true; //
}
Public void reader() {
if (flag) { //
int i = a * a; //
……
}
}
}
当两个线程 A 和 B,A 首先执行writer() 方法,随后 B 线程接着执行 reader() 方法。线程B在执行操作4时,能否看到线程 A 在操作1对共享变量 a 的写入?
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。
二、追根溯源
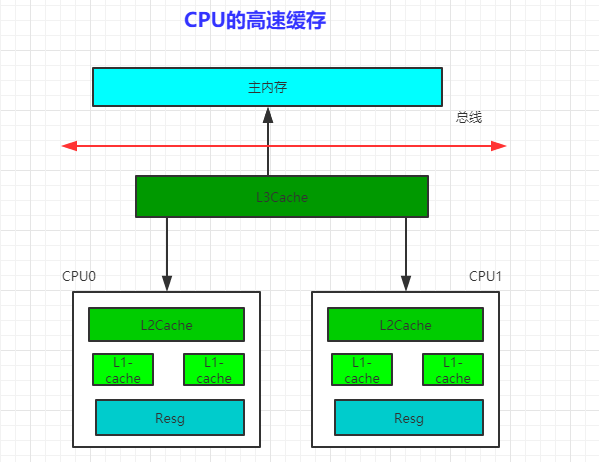
三、缓存一致性协议
据不一致

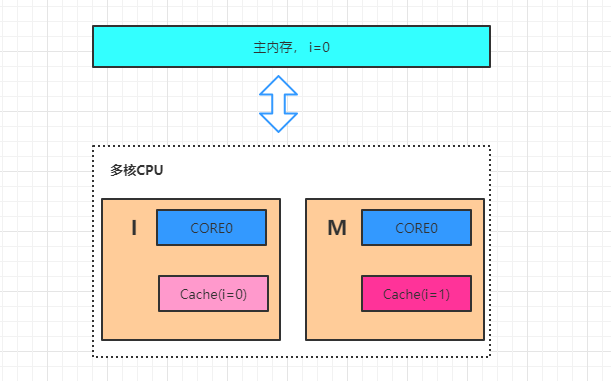
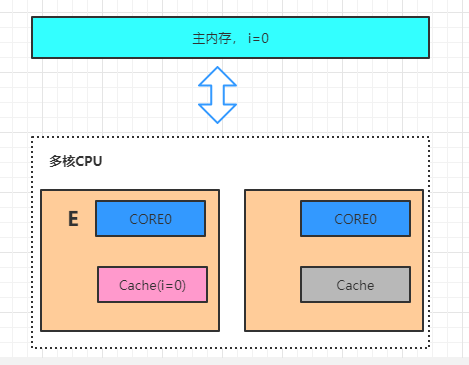
四、重排序原因
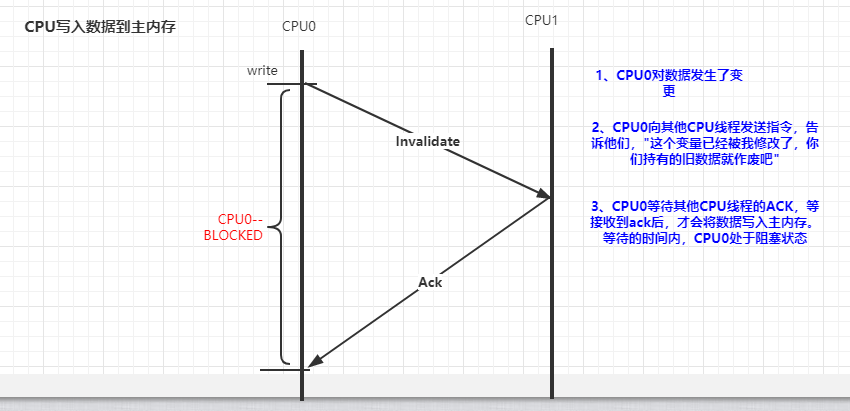
基于上图中的原因,CPU又引入了storeBuffers的缓冲区。CPU0 只需要在写入共享数据时,直接把数据写入到 storebufferes 中,同时发送 invalidate 消息,然后继续去处理其

这个时候,我们再来看上述标题一中的重排序场景。
class ResortDemo {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
当执行1操作时,a的状态从S->M,此时,线程A会先把变更写入到storebuffers,然后发送invalidate去异步通知其他CPU线程,紧接着就执行了下面的2操作。
此时,可能1的变更还在storebuffers中,并未提交到主内存。什么时候会提交到主内存,也不确定。
所以,线程B调用read方法可能会出现,看到了flag的变更,但是看不到a的变更,就出现了重排序的现象。
cpu指令重排序的原理的更多相关文章
- CPU指令重排序与MESI缓存一致性
一.重排序场景 class ResortDemo { int a = 0; boolean flag = false; public void writer() { a = 1; //1 flag = ...
- java高并发核心要点|系列4|CPU内存指令重排序(Memory Reordering)
今天,我们来学习另一个重要的概念. CPU内存指令重排序(Memory Reordering) 什么叫重排序? 重排序的背景 我们知道现代CPU的主频越来越高,与cache的交互次数也越来越多.当CP ...
- Java的多线程机制系列:不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- Java的多线程机制系列:(四)不得不提的volatile及指令重排序(happen-before)
一.不得不提的volatile volatile是个很老的关键字,几乎伴随着JDK的诞生而诞生,我们都知道这个关键字,但又不太清楚什么时候会使用它:我们在JDK及开源框架中随处可见这个关键字,但并发专 ...
- 深入浅出Java并发包—指令重排序
前面大致提到了JDK中的一些个原子类,也提到原子类是并发的基础,更提到所谓的线程安全,其实这些类或者并发包中的这么一些类,都是为了保证系统在运行时是线程安全的,那到底怎么样才算是线程安全呢? Java ...
- JVM并发机制的探讨——内存模型、内存可见性和指令重排序
并发本来就是个有意思的问题,尤其是现在又流行这么一句话:“高帅富加机器,穷矮搓搞优化”. 从这句话可以看到,无论是高帅富还是穷矮搓都需要深入理解并发编程,高帅富加多了机器,需要协调多台机器或者多个CP ...
- 深入浅出 Java Concurrency (4): 原子操作 part 3 指令重排序与happens-before法则
转: http://www.blogjava.net/xylz/archive/2010/07/03/325168.html 在这个小结里面重点讨论原子操作的原理和设计思想. 由于在下一个章节中会谈到 ...
- 轻松学JVM(二)——内存模型、可见性、指令重排序
上一篇我们介绍了JVM的基本运行流程以及内存结构,对JVM有了初步的认识,这篇文章我们将根据JVM的内存模型探索java当中变量的可见性以及不同的java指令在并发时可能发生的指令重排序的情况. 内存 ...
- 【java多线程系列】java内存模型与指令重排序
在多线程编程中,需要处理两个最核心的问题,线程之间如何通信及线程之间如何同步,线程之间通信指的是线程之间通过何种机制交换信息,同步指的是如何控制不同线程之间操作发生的相对顺序.很多读者可能会说这还不简 ...
随机推荐
- 【i.MX6UL/i.MX6ULL开发常见问题】单独编译内核,uboot生成很多文件,具体用哪一个?
[i.MX6UL/i.MX6ULL开发常见问题]2.3单独编译内核,uboot生成很多文件,具体用哪一个? 答:内核编译出来的文件是~/MYiR-imx-Linux/arch/arm/boot/目录下 ...
- 两个数组的交集 II
题纲 给定两个数组,编写一个函数来计算它们的交集. 示例 : 输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4] 输出: [4,9] 说明: 输出结果中每个元素出现的次数 ...
- DB2数据库中DB2字符串类型
DB2字符串是DB2数据库中的基础知识,下面就为您分类介绍DB2字符串,供您参考,如果您对DB2字符串方面刚兴趣的话,不妨一看. DB2字符串是字节序列.DB2字符串包括 CHAR(n) 类型的定长字 ...
- IDEA中安装及配置SVN
1.TortoiseSvn(小乌龟下载地址): https://tortoisesvn.net/downloads.html 2.下载完SVN安装包后,在本机安装SVN(小乌龟),注意安装的时候添加上 ...
- mysql修改字符集问题
mysql字符集问题: 本文主要解决mysql7以下问题:mysql7在默认安装后,关于数据库,表默认保存字符格式为latin1: 可以通过命令:查询当前mysql的编码设置: show variab ...
- C# winform 托盘控件的使用
从工具栏里,把NotifyIcon控件拖到窗体上,并设置属性: 1.visible 设置默认为FALSE: 2.Image 选一张图片为托盘时显示的图样:比如选奥巴马卡通画像: 3.Text 显示: ...
- nodejs puppeteer linux(centos)环境部署以及用puppeteer简单截图
1.安装Node环境 如果有安装Node请忽略第1点 #下载cd /usr/local/srcwget https://nodejs.org/dist/v10.15.3/node-v10.15.3-l ...
- Java开发环境之MongoDB
查看更多Java开发环境配置,请点击<Java开发环境配置大全> 伍章:MongoDB安装教程 1)官网下载MongoDB安装包 https://www.mongodb.com/downl ...
- 《linux就该这么学》课堂笔记02 虚拟机安装使用
这节学习了虚拟机安装RHEL系统,了解了shell.以及命令的格式
- MAC地址IP地址网关地址
MAC地址与IP地址区别 IP地址和MAC地址相同点是它们都唯一,不同的特点主要有: 对于网络上的某一设备,如一台计算机或一台路由器,其IP地址是基于网络拓扑设计出的,同一台设备或计算机上,改动IP地 ...